06 / 22周一97 条
推文 63资讯 4视频 4产品 7研究 3论文 9播客 0
没有生态的前沿是不稳定的
Satya Nadella:企业护城河不是挑最好的模型,而是让人力资本与 token 资本在「学习闭环」里复利;前沿若无生态、价值不普惠则不稳定。
Agentic 代码审查
写代码变便宜后,瓶颈移到「能否信任代码」,代码审查成了杠杆率最高的技能;附 2026 多家实测数据 + 按「影响半径」分层的实操打法。
Agentic 编程产品的下一站
复盘 2026 智能体编程产品从「编辑器+侧栏/CLI」到「智能体指挥中心」;展望下一站:更薄 harness、主动型智能体、团队协同层、自动验证。
Codex 操控电脑的三种方式
Codex 操控电脑三种方式:Computer Use(@Computer,最广最慢)/ 带登录态的 @Chrome / 应用内隔离 @Browser,三者信任边界不同,配 Appshots 心智模型。
如何为你的 Skills 搭建自我改进循环
Warp 团队实操:用 skill + 云端 agent 搭「自我改进循环」——内层跑技能、外层据用户反馈生成 diff 自动改进 SKILL.md,以 issue 分诊为例。
用 Claude 构建你的第一支 AI Agent 团队(完整课程)
用 Claude 编排「编排者+专才+评审」三角色团队的完整实操课;核心论点是差距不在智能而在编排,五阶段从单体搭到可靠的多智能体团队。
窗口已经关闭
Andrew Curran 观点檄文:断言各国冲上 AI 前沿的窗口已永久关闭,算力与人才死锁集中于中美,开源终将遭全球监管围剿。
选稍微难走的那条路:前海豹突击队员安迪·斯坦普夫谈日常行动与心理韧性
Perplexity CEO 阿拉文德·斯里尼瓦斯:美光会比 Meta 更值钱,出口管制反而帮了中国
智能体编程与专业度的持续回报
Project Fetch 第二阶段:Claude 自主操控机器狗
驾驭 Claude Code:CLAUDE.md 文件、skills、hooks、rules、subagents 等机制全解
认识一下 "Built with Opus 4.7" Claude Code 黑客松的获奖者们
Claude Design 现在能贴合品牌,胜任日常工作
来认识一下 Claude Opus 4.8 Build Day 黑客松的获奖者
集中管理 MCP 连接器的授权
通过 Workload Identity Federation 安全访问 Claude Platform
Claude Code 现已支持 artifacts
最近越来越多关于提示词注入、数据泄露等大模型安全隐患的事件出现。 不少安全工程师想深入研究却无从下手,可以看下 awesome-ai-security 这份开源合集。 包含基础安全知识学习、红队测试工具、提示词注入检测、模型扫描等 AI 安全资源内容。 GitHub:http://github.com/ottosulin/awesome-ai-security 还收录了关于大模型和智能体的安全工具,比如 MCP 协议安全扫描、智能体运行时沙箱、AI 辅助渗透测试框架等。 列表按应用场景做了清晰的模块划分,能帮我们快速检索需要的资料。 资源合集还在持续更新,适合做 AI 应用开发或者安全相关工作的开发者收藏看看。↗

大家似乎忘了,Gemini 本身就是对 PaLM 系列落后到可笑的一种反应。Gemini 意思是「双子」,这是 Google 的王牌——合并 DeepMind 和 Google Brain(按前者的条件)。他们基本上干了「AI-2027 里 CCP」那一套,就是这样。↗
People seem to forget, Gemini itself was a reaction to PaLM series being laughably behind the curve Gemini means "twins", this was Google's trump card, merging DeepMind and Google Brain (on the former's terms). They basically did the AI-2027 CCP thing. That's it
 Jean P.D. Meijer ― 🇪🇺 eu/acc@initjean
Jean P.D. Meijer ― 🇪🇺 eu/acc@initjeanGoogle should just stop with Gemini because this is just humiliating
Google 真该把 Gemini 停了,这也太丢人了。
这就是 Vibe Coding !😂 你敢信这是来自于 chatgpt 的 popup 窗口 https://t.co/uv1zoEtpt4↗

世界杯骗局越来越难辨别
从假门票到克隆网站,AI 正在放大世界杯骗局。球迷还分得清真假吗?
一些电工觉得给数据中心干活是「叛徒」行为
大科技公司正往数据中心建设里砸大钱。随着全国范围内对这些设施的反对声渐起,一些工人开始怀疑这活儿到底值不值得干。
用 tmux 管理终端会话,可以在终端里打开多个对话窗口,即便关掉还能在后台继续。 但现在,经常同时开好几个 Agent 干活,想用 tmux 做终端自动化,得写一堆脚本很麻烦。 于是有位开发者用 Rust 从零写了 rmux,专为 Agent 打造。 通过它我们能让 Claude Code 当总指挥,向 Codex、Gemini CLI 指派任务。 甚至同一个任务让几个 Agent 同时跑,结果谁强谁弱一目了然。 GitHub:https://t.co/qR486Lw8DX 除了敲命令,还能用代码精确驱动终端,思路跟 Playwright 很像。 兼容 90 多条 tmux 命令,配置和插件都能沿用,迁移成本几乎没有。 刚开源不久可能还有些 Bug,想让 Agent 在终端帮我们干活的朋友可以试试。↗
GLM-5.2 - 79.7% DeepSeek V4 - 13.4% Kimi K2.7 - 5.2% MiniMax M3 - 1.7% GLM-5.2 这么强,MiniMax M3 这么惨吗?↗
 meng shao@shao__meng
meng shao@shao__meng看到有人发起的 llm 对比投票 GLM-5.2 vs Gemini 3.5 Flash 对比结果应该很明显,主要是因为 Gemini 3.5 Flash 确实不能打,Google Deepmind 到底怎么了,Gemini 3.0 多模态惊艳后,就一路沉寂下去了。 如果正经对一下最近几个国产 llm 呢?你觉得谁更强?
大概值得一读,好了解一下在这波准 AGI 技术浪潮之前,中国对 AI 抱有怎样的先验认知。↗
Probably worth reading just to get an idea of what priors about AI China had before this wave of pre-AGI technology.
 Antiñanco@homocommunism
Antiñanco@homocommunismIf youre struggling to see AI as anything other than a monstrosity may I suggest this book: there’s a high chance you have completely digested the west’s apocalyptic look on technology and the future of the world. anxiety and fear of AI is not universal. In fact, it’s an outlier
如果你只把 AI 看成一个怪物,我建议读读这本书:很可能你已经完全消化了西方那套对技术、对世界未来的末日论调。对 AI 的焦虑和恐惧并非普世——事实上,它是个异类。

Claude Design 的界面更新了,而Open Design 一个月前就已经改为这种界面 UI 了😎🤣 看来 Claude Design 也很认可我们的设计方向,当然Open Design 的优势很简单:你有什么 agent,就用什么 agent;没有也可以用 AMR 接入最好的模型和 agent。 另外,现在也支持智谱GLM 5.2和 kimi 2.7了,欢迎大家用起来↗
 Open Design@OpenDesignHQ
Open Design@OpenDesignHQOpen Design is already ahead. Claude Design's latest update follows a direction we shipped over a month ago. Glad to see the approach validated. No Claude pro required. Bring your own agent, or use AMR to access the best agents and models. AI Design should be open by default.
Open Design 已经领先了。Claude Design 最新更新走的方向,我们一个多月前就发布了,很高兴看到这套思路被验证。无需 Claude pro,自带 agent,或用 AMR 访问最好的 agent 和模型。AI Design 理应默认开放。

抛开 Sakana 这个具体实现,我把它看作又一个确认:好的编排/脚手架/工作流能把表现较弱的模型推上前沿水平。他们声称这能「更广泛地分发前沿 AI 的红利」,我觉得是对的、值得认真对待。即便一个多 agent 系统消耗的算力跟直接跑一个前沿模型相同甚至更多,被编排起来的可用性和价格……↗
Looking beyond Sakana's particular implementation, I see this as another confirmation that good orchestration/scaffolds/workflows can propel less performing models to frontier levels of performance. Their claim that this could "distribute the benefits of frontier AI more broadly" seems correct to me and is worth taking seriously. Even if the compute consumed by a multi-agent system is the same or greater than just running a frontier model, the availability and price of orchestrated
 elie@eliebakouch
elie@eliebakouchto be clear, this is a closed source orchestrator on top of closed source models. if before you didn't control the models, now you don't even control which ones are used or how much. this is not "AI sovereignty" i've also read the tech report to get an opinion on the technical stuff: fugu (not the ultra version) is basically a classifier that selects which model at each turn is most likely to answer correctly (in other words a router). this leads to -10 points on SWE Bench pro compared to opus,
说清楚:这是一个闭源编排器,架在闭源模型之上。以前你不掌控模型,现在你连用哪些、用多少都不掌控了。这不是什么「AI 主权」。我也读了技术报告:fugu(非 ultra 版)基本上就是个分类器,每一轮挑最可能答对的模型(换句话说就是个 router)。结果是在 SWE Bench pro 上比 opus 低了 10 分。
pufferlib 那哥们把他「LLM 不行」的把戏玩得太过了。各位,千万别在自己那套动机驱动的说辞里迷失。↗
The pufferlib guy is pushing his "LLMs bad" gimmick too far never get lost in your own motivated rhetoric folks
 Apuma@CoachApumaYTube
Apuma@CoachApumaYTubeI tried to ask Joseph once on stream, what's the deal with training 50k param models under 10 sec? What's the end goal? Was it research for more optimal learning methods? IDK, he didn't understand my point and, in turn, did not respond, saying LLMs are too costly. But one does not train LLMs to play Sokoban or any other puzzle game for the sake of playing. The main objective is to surface and reinforce useful skills and reasoning patterns. We want a model to do lookaheads, to plan, to backtrack.
我曾在直播里问过 Joseph:在 10 秒内训练 5 万参数的模型,意义何在?终极目标是什么?是为研究更优的学习方法吗?他没听懂我的点,也没回应,只说 LLM 太贵了。但人训练 LLM 不是为了玩 Sokoban 或别的解谜游戏而玩,主要目标是挖掘并强化有用的技能和推理模式。我们想要模型会前瞻、会规划、会回溯。
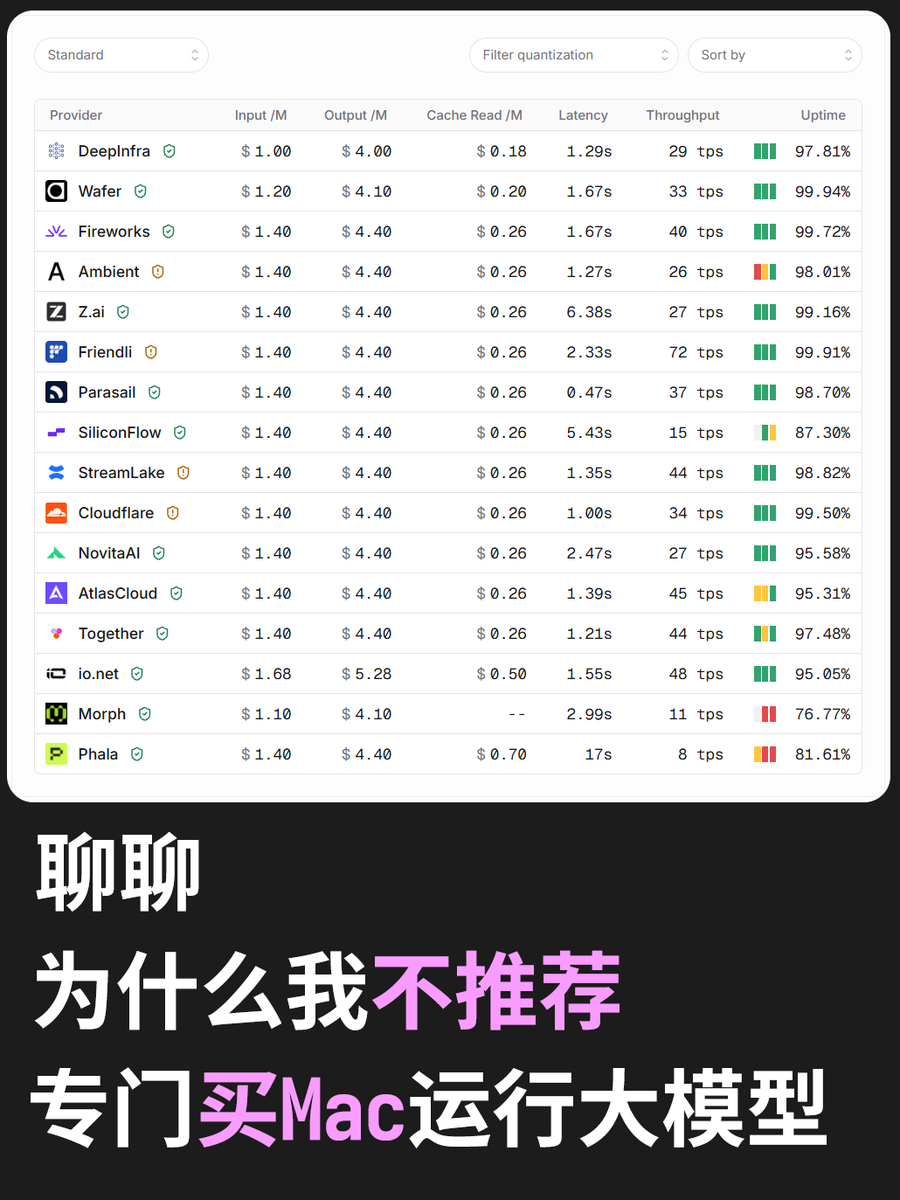
想买Mac运行大模型? 这是劝退贴 其实估算方法很简单, 现在买 MacStudio 哪怕运行 Qwen3.6-27B 4bit 量化版本, 然后开 DFlash 使用Qwen的内置投机解码, 也就飙到 65token/s. 而现在普遍大模型都能跑到 40 token/s. 如果专门买 MacStudio M3 Ultra 96G 运行大模型, 如果把设备售价 (32999) 换算成使用API, 以 GLM-5.2 为例, 每百万token 28块, 一台 MacStudio 的价格大概能买到 32999/28 = 1178M token. 而为了输出这些token, 买到的 MacStudio 运行 Qwen3.6-27B 要持续运行 209天. 也就是说回本周期至少是200天不间断运行. 然后运行模型才是纯赚. 这还是没算电费和不直接买API而是买套餐的情况.而且, 最重要的是这还是在运行一个只有27B的小模型. 如果真的买512G的 MacStudio (108749, 而且好像已经断货了), 然后运行量化版本的 GLM-5.2, 速度就会跌到只有 17↗
疯狂的是,SSI 那个角度其实没那么离谱,这家伙确实发关于 AI/LLM 的内容。美国人真是了不起。 https://t.co/Mmst465vvK↗
the crazy thing is that the SSI angle isn't so far-fetched, this guy does post about AI/LLMs. Americans are really amazing https://t.co/Mmst465vvK
SpatialAvatar-0:通过多阶段重建实现的高质量 4D 头部虚拟形象
0 赞
多轮反思式掩码激发掩码扩散模型的推理能力
0 赞
把示例蒸馏进任务指令:面向真实 B2B 对话的增强型上下文学习
1 赞
GeneralVLA-2:面向机器人规划的几何感知重建与受治理记忆
1 赞
MemSlides:一个用于个性化幻灯片生成、支持多轮局部修订的分层记忆驱动 agent 框架
2 赞
WorldLines:对长程有状态具身 agent 的基准测试与建模
2 赞
GateMem:对多主体共享记忆 agent 中记忆治理的基准测试
4 赞
BrainG3N:用于可控 3D 脑部 MRI 生成的双用途 tokenizer
4 赞
PerceptionDLM:用多模态扩散语言模型实现并行区域感知
40 赞
AI 实验室有两种。一种人见人爱,另一种有客户。↗
There are two types of AI labs. Those that are beloved by everyone, and those that have customers
兄弟们!必须卧槽了… 为了给Cuimao扩大影响力,我添加了日语字幕版本! CuiMao把Fable 5被封杀的真实事件,拍成了一部7分钟的谍战短片,还把Dario和美国国防部长都请进了剧情。 CuiMao用seedance2 + Grok Imagine Video 1.5做的这个短片,讲了Fable 5发布后24小时内发生的事。 Anthropic CEO Dario突然失联,美国国防部长Pete亲自出面审讯,而正在美国度假看世界杯的CuiMao收到了一条来自Dario的神秘取件短信。 验证码、太阳花、自毁录音…… 整个故事把最近真实发生的出口管制事件,包装成了一个有开头、有高潮、有伏笔的完整谍战剧。 结尾甚至暗示Fable 5被封杀背后有更深的“原因”。 日本的朋友们可以直接无障碍欣赏了… 太牛了Z↗
 CuiMao@CuiMao
CuiMao@CuiMaoFable 5发布后的24小时内,Anthropic CEO Dario突然失联,美国国防部长Pete亲自审讯。与此同时,在美国度假观看世界杯的 CuiMao收到一条来自Dario的神秘取件短信。一个验证码,一朵太阳花,一段即将自毁的录音,将揭开 Fable 5 被封杀背后真正的原因。
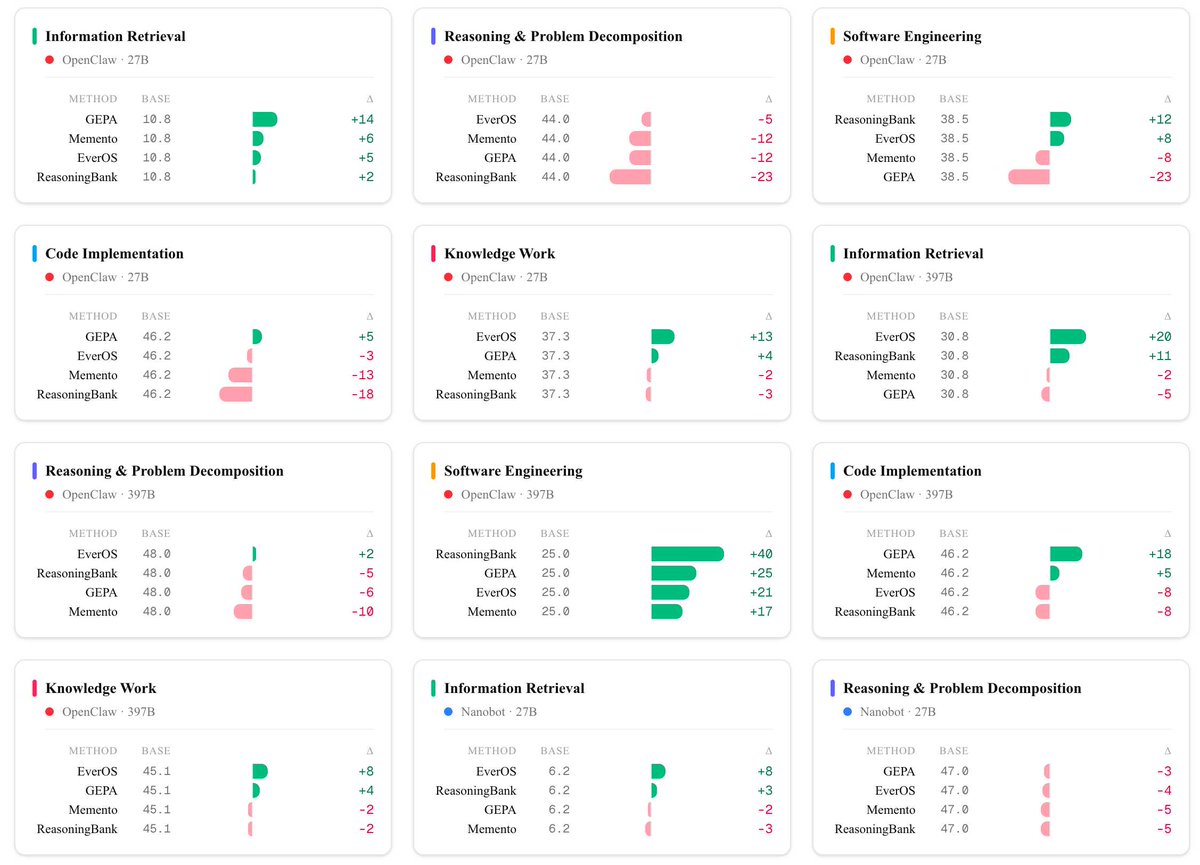
介绍一下我们这个 Benchmark,它专门用来测试 Agent 的自进化能力,非常关键。 今年我们一直在挖掘 self-improving / self-evolving 这个方向,因为我们发现 Agent self-improving 在无数场景下都有实际价值。 在现在爆火的 Loop 架构中,memory-first 的自进化更是最核心的一环,可能没有之一。 正是为了把这块做扎实,我们才专门打造了这个 Benchmark。 这个 Benchmark 也是接下来我们发布 Raven 🐦⬛ 的重要一环。↗
 EverMind@evermind
EverMind@evermindEveryone is talking about self-improving agents. The harder question is how to measure whether an agent is actually getting better. That is why we built EvoAgentBench: a benchmark for agent self-evolution. It tests whether agents can learn from past trajectories, extract reusable skills/memory, and improve on held-out tasks across 5 domains: - information retrieval - reasoning and problem decomposition - software engineering - code implementation - knowledge work 917 train tasks. 288 test tasks.
人人都在谈自我改进的 agent。更难的问题是:怎么衡量一个 agent 是否真的在变好。这就是我们做 EvoAgentBench 的原因:一个面向 agent 自我进化的基准。它测试 agent 能否从过去的轨迹中学习、提取可复用的技能/记忆,并在 5 个领域的留出任务上提升:信息检索、推理与问题分解、软件工程、代码实现、知识工作。917 个训练任务,288 个测试任务。
我本来对多模型路由持怀疑态度,看来我的直觉是对的。↗
I was skeptical about the multi-model routing. Seems my hinch was right.
 am.will@LLMJunky
am.will@LLMJunkyI tried this so you don't have to. I know this is going to absolutely shock you but no this does not match the performance of Mythos. A few early thoughts: 1. The limits are pretty bad. I used 100% of my 5-hour usage in less than 1 prompt. 2. I specifically gave it a threejs task because it is an area that SOTA models have made big strides in, that other models just are not great at. I asked it to build a replica of Rocket League. I'll put the prompt in the comments. The game was pretty bad and
我替你们试了,省得你们试。我知道这会让你大吃一惊,但不——它的性能并不及 Mythos。几点初步感受:1. 限额相当糟,我一条 prompt 不到就用光了 5 小时额度。2. 我特意给了它一个 threejs 任务,因为这是 SOTA 模型大有长进、而其他模型就是不太行的领域。我让它复刻一个 Rocket League,prompt 放评论里。做出来的游戏挺烂……
这推理性能也比他们在 V4 发布时给 950DT 报的数字要好。按投资算,Capex 约等于 1.5 亿人民币/0.4MW,那就是 3750 亿/GW,按当前汇率约 550 亿美元。和美国一样,只不过美国的芯片每瓦性能强得多,而且 Capex 更高。 https://t.co/BfoOb4VCFf↗
This is also better inference performance than what they were reporting for 950DTs at V4 launch. on investment, so Capex is ≈150M RMB/0.4MW. That'd be 375B/GW, or $55B right now. Same as in the US, except in the US chips are much more performant per watt. And Capex is higher. https://t.co/BfoOb4VCFf


MoonMath AI 开源了一个面向 AMD MI300X 的 HIP 注意力内核,在每种 shape 和舍入模式上都击败 AITER v3
MoonMath AI 团队发布了一个面向 AMD MI300X GPU 的 bf16 前向注意力内核。它用 HIP 写成,不是手写汇编。代码以 MIT 协议开源。MoonMath.ai 团队……
「2026 年 6 月,DeepSeek 团队在乌兰察布的 CloudMatrix 384 超节点上成功完成了 V4 Pro 模型的全参数后训练」。第一位蒙古专家诞生了。 https://t.co/aFEuSliDMs↗
“In June 2026, the DeepSeek team successfully completed full-parameter post-training of the V4 Pro model on the CloudMatrix 384 supernode at Ulanqab” The first Mongolian Expert lives. https://t.co/aFEuSliDMs

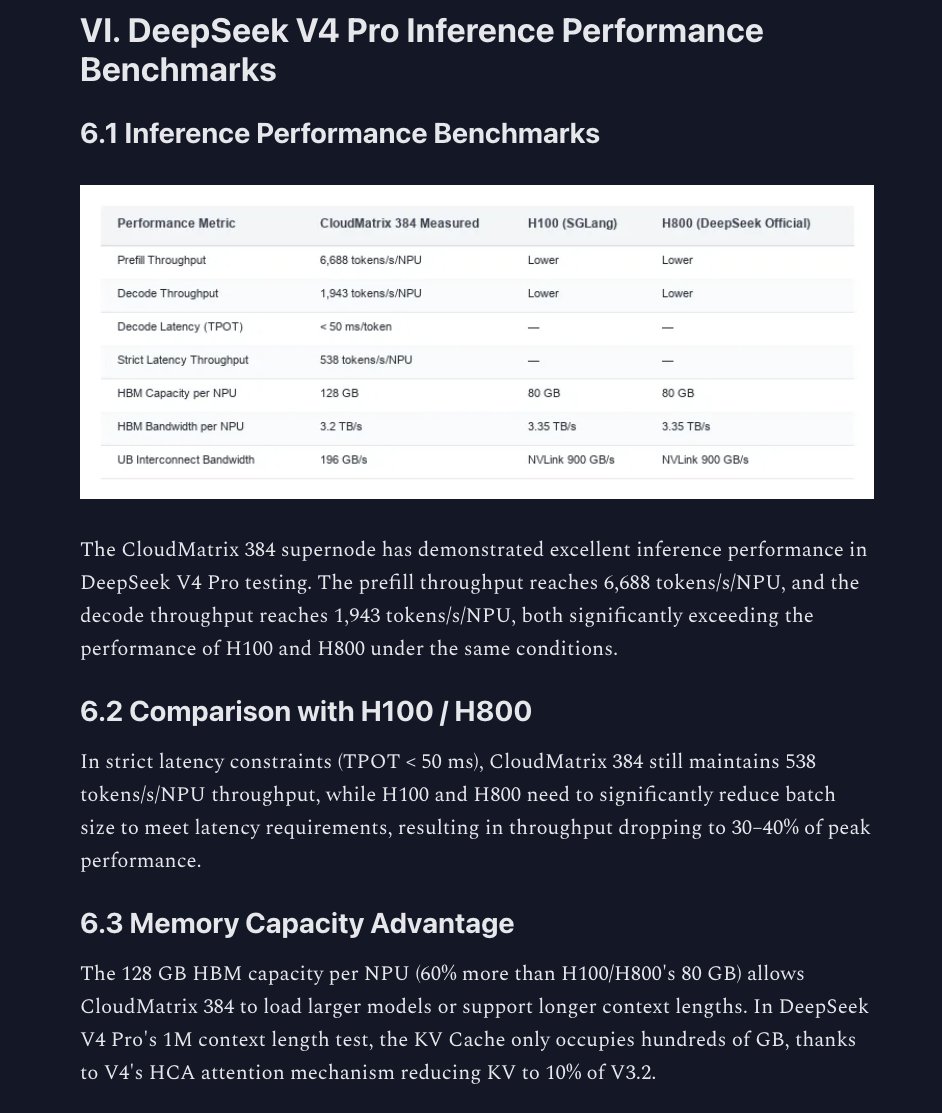
奇怪的是,在 950 这一代,华为不再宣传更小的集群。SuperPOD 是 8192 颗 NPU(不过现在又听说有个 1024-NPU 的切片)。另外注意:内蒙古、乌兰察布,DeepSeek 也在那儿建,不,那不是 Blackwell……还是说就是同一个? https://t.co/uQjxfYyZzK↗
it's strange that in the 950 generation Huawei is not advertising smaller clusters. SuperPOD is 8192 NPUs (though now we're hearing of an 1024-NPU slice). Also note: Inner Mongolia, Ulanqab DeepSeek is building there too, and no it's not Blackwells …or is this the same one? https://t.co/uQjxfYyZzK


 China Research Collective@CRC_8341
China Research Collective@CRC_8341Huawei Ascend CloudMatrix 384 Supernode: In-Depth Project Analysis Link:
华为昇腾 CloudMatrix 384 超节点:深度项目解析。链接:

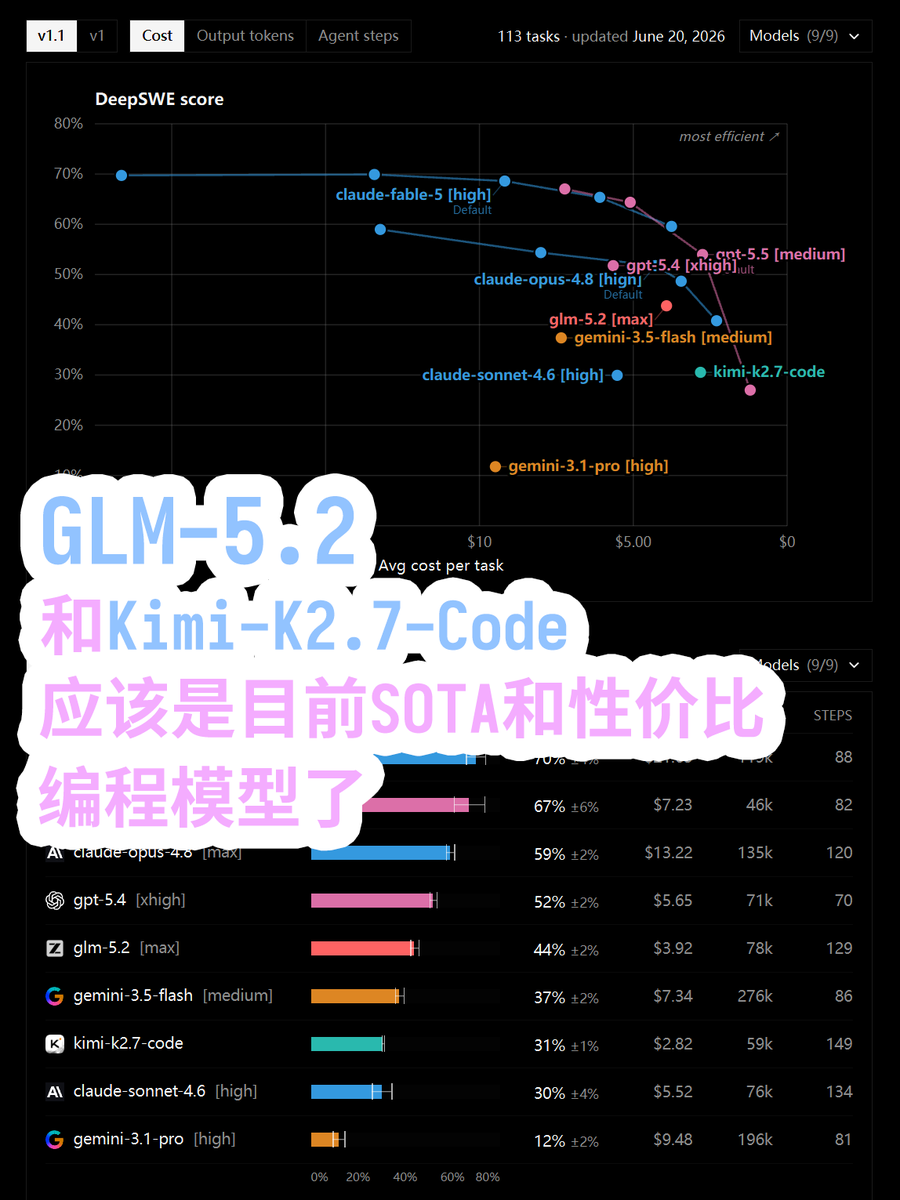
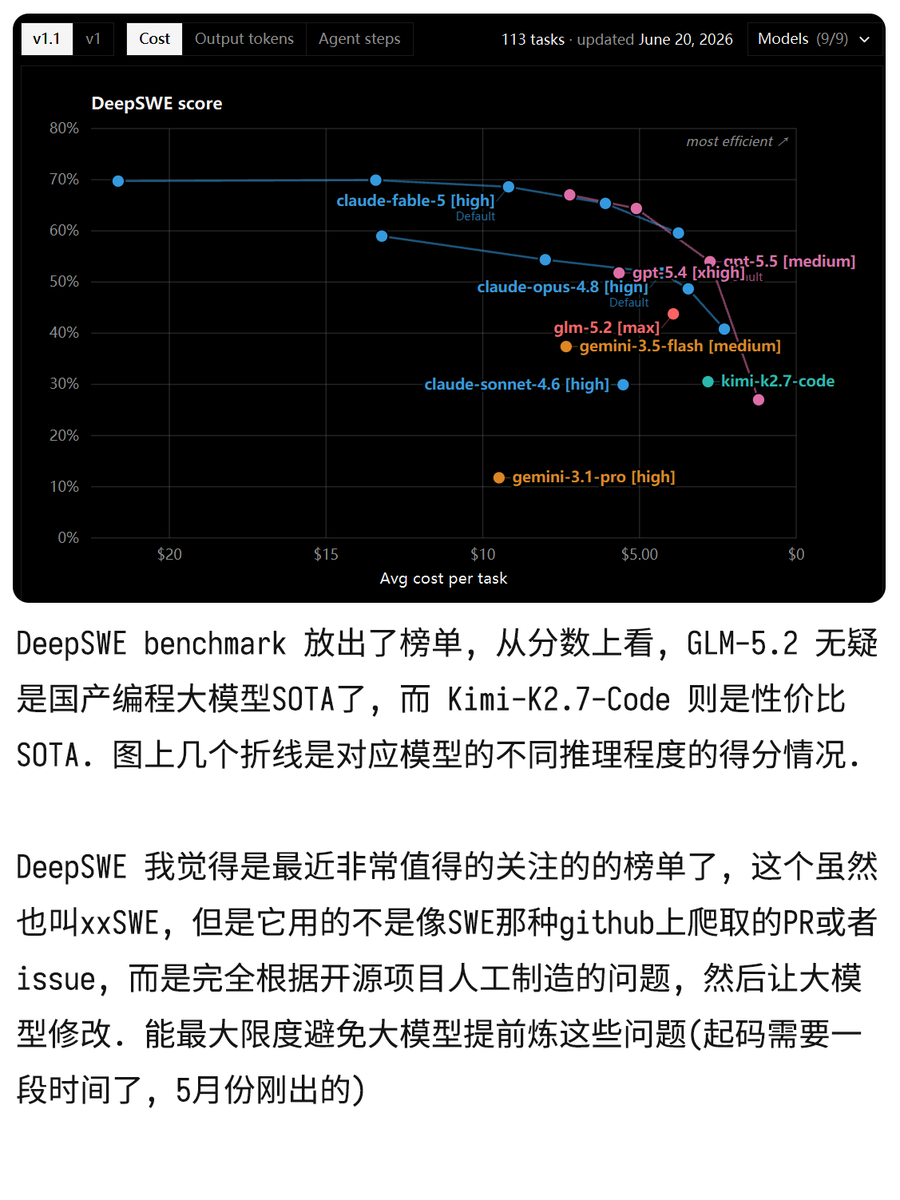
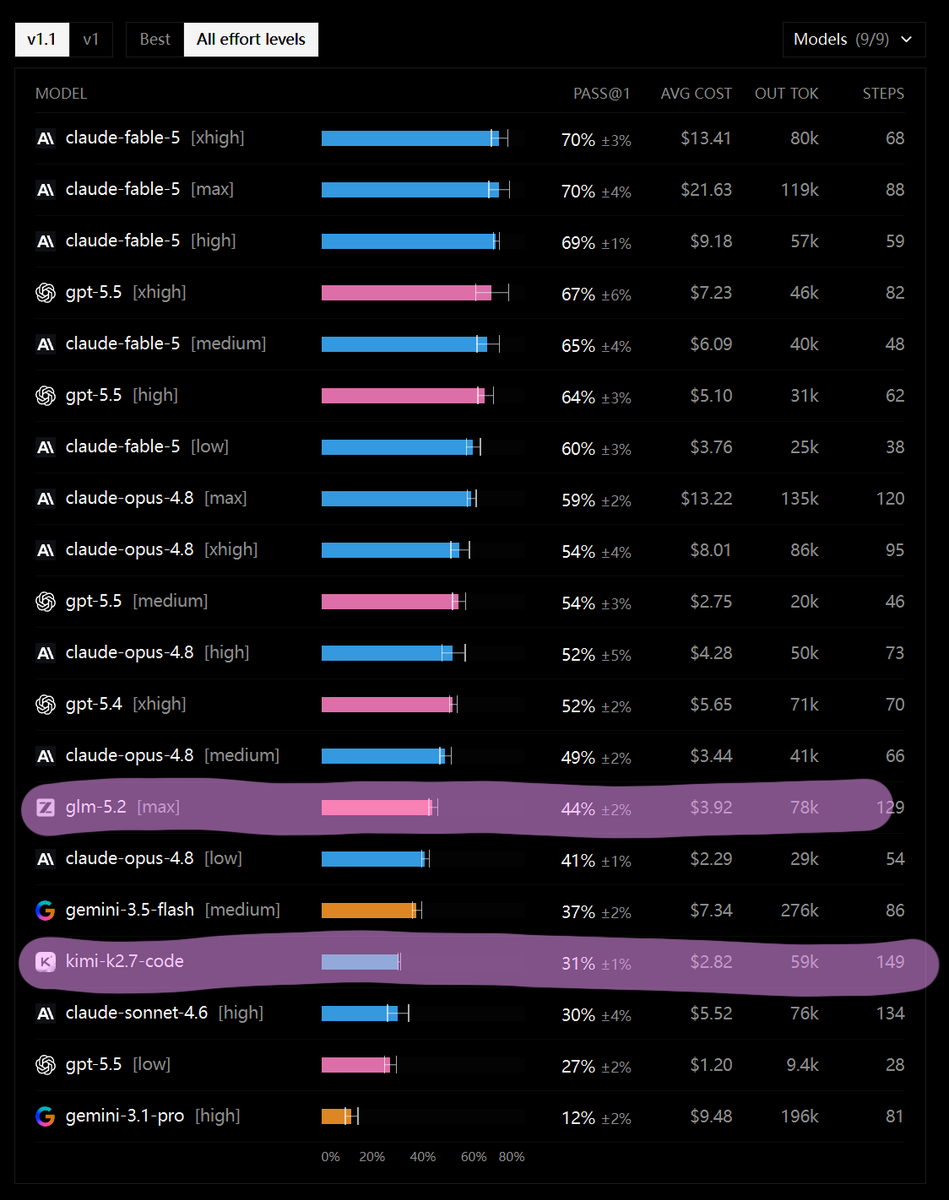
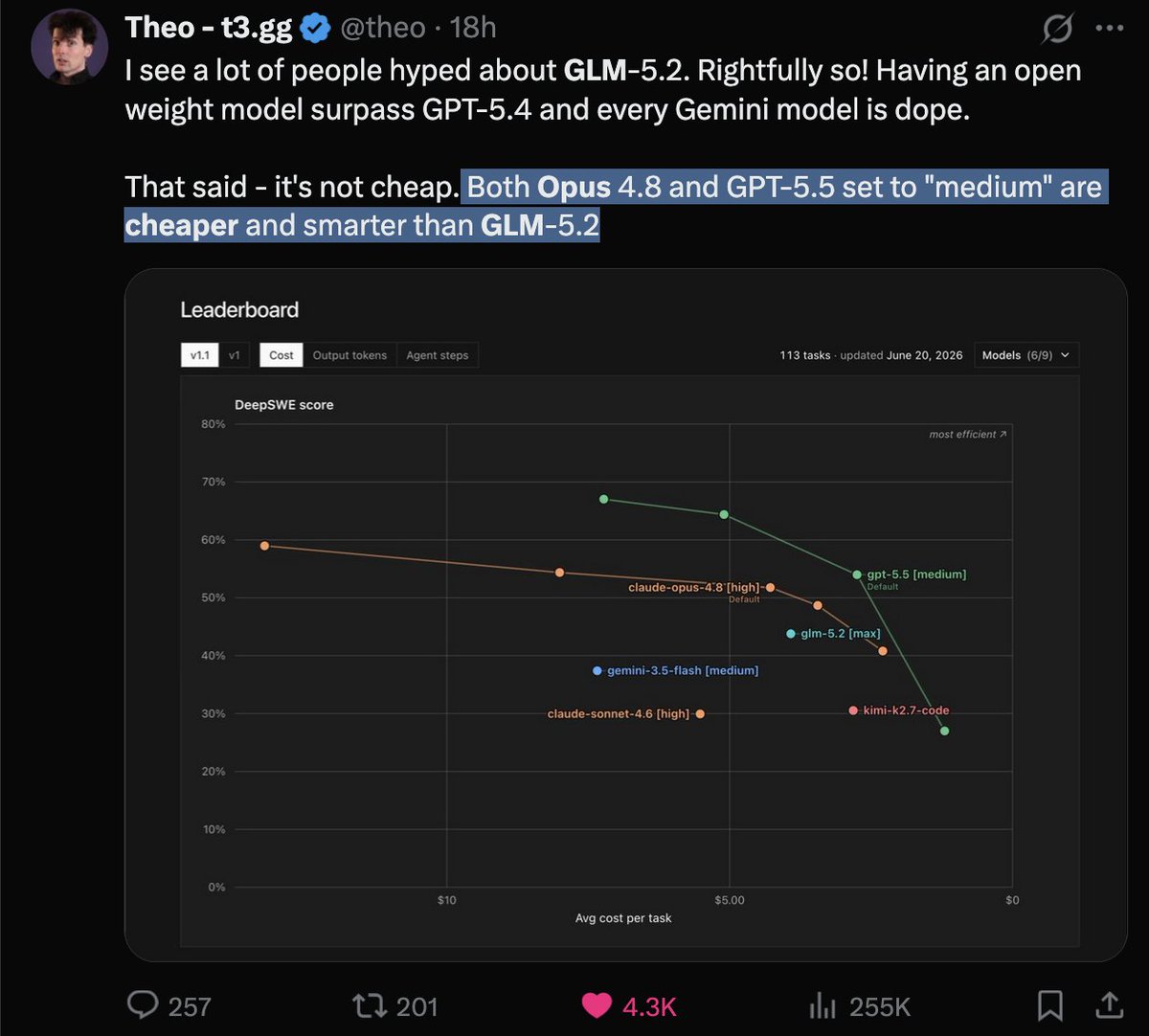
国产模型最近这一波打得太精准了 DeepSWE benchmark 放出了榜单, 从分数上看, GLM-5.2 无疑是国产编程大模型SOTA了, 而 Kimi-K2.7-Code 则是性价比SOTA. 图上几个折线是对应模型的不同推理程度的得分情况. DeepSWE 我觉得是最近非常值得的关注的的榜单了, 这个虽然也叫xxSWE, 但是它用的不是像SWE那种github上爬取的PR或者issue, 而是完全根据开源项目人工制造的问题, 然后让大模型修改. 能最大限度避免大模型提前炼这些问题(起码需要一段时间了, 5月份刚出的) 并且修改范围也很大,SWE-Bench-verified 通常一个提交也就几十行代码, 而 DeepSWE 每个问题都要上百行提交才能解决问题, 并且很考验模型的规划能力, SWE-Bench-Verified 通常会把所有需要的工具给到错误日志啥的也有, 并且提示词也写好告诉模型该怎么用. 而 DeepSWE 纯靠模型自己摸索, 非常像现实中修改项目代码的过程. 我觉得是涵盖了一部分工程能力测试的. 另外 SWE-Bench-verif↗

把话说清楚,这是个闭源模型之上的闭源编排器。如果说以前你掌控不了模型,那现在你连用哪些模型、用多少都掌控不了了。这根本不是什么「AI 主权」。我还读了技术报告,对技术部分有了点看法:fugu(非 ultra 版)本质上就是个分类器,每一轮挑出最可能答对的模型(换句话说就是个路由器)。结果在 SWE Bench 上掉了 10 分↗
to be clear, this is a closed source orchestrator on top of closed source models. if before you didn't control the models, now you don't even control which ones are used or how much. this is not "AI sovereignty" i've also read the tech report to get an opinion on the technical stuff: fugu (not the ultra version) is basically a classifier that selects which model at each turn is most likely to answer correctly (in other words a router). this leads to -10 points on SWE Ben
 Sakana AI@SakanaAILabs
Sakana AI@SakanaAILabsIntroducing Sakana Fugu: A full multi-agent orchestration system accessible via a single model API. Our ‘Fugu Ultra’ model matches the performance of Fable and Mythos, delivering frontier capability without the risk of export controls. Try it: 🐡
推出 Sakana Fugu:一套完整的 multi-agent 编排系统,通过单一模型 API 访问。我们的「Fugu Ultra」性能比肩 Fable 和 Mythos,在不受出口管制风险的前提下交付前沿能力。来试试 🐡
Sakana AI发布Fugu:用模型编排模型,提供单一API端点 用户调用一个API端点,背后由一个经过训练的LLM动态调度多个专家模型协作完成复杂任务。 有点像前几天OpenRouter发布的Fusion,一次调用融合多模型输出,低成本也能超越前沿模型。 官方介绍:https://sakana.ai/fugu/ https://t.co/sjI8T6g7TS↗
整个过程最关键的不是模型有多聪明,那张作为唯一真相来源的总表是关键,也就是说,结构化状态管理才是长循环Agent的核心↗
做的不错,这样发展下去,年底春节档可以看到 AI 大电影了吧 https://t.co/oZLd49rNxr↗
一个防止 AI 垃圾内容(写作、设计等)的经验法则:你的输入(上下文)比输出长吗?我发现要让 AI 产出高质量结果,我的输入往往是输出长度的 3-5 倍。如果你的输入比输出短得多,那几乎肯定会产出垃圾。↗
A good rule of thumb for preventing AI slop (in writing, design, etc): Is your input (the context) longer than the output? I've found that for the AI to produce quality results, my input is often 3-5 times the length of the output. If your input is much shorter than the output, it's almost certainly going to produce slop
想不用 Mac 就在 iMessage 上跟你的 Hermes Agent 聊天?最新的 v0.17.0 更新让这成了可能(而且超简单)!我做了个短视频,演示怎么在三分钟内全部搭好。请享用! https://t.co/N0mfxHUagJ↗
Want to chat with your Hermes Agent on iMessage without a Mac? The latest v0.17.0 update made this possible (and super easy)! I made a quick video showing how to get this all set up in less than three minutes. Enjoy! https://t.co/N0mfxHUagJ
比热水浴缸还烫:45°C 的突破,为 AI 最大的机器降温
热水浴缸大约在 38 到 40 摄氏度,热到大多数人只能泡 15 分钟左右。NVIDIA 最新的 AI 服务器能让冷却液跑得更烫——高达 45 度……
我会在 Tabbit AI 浏览器的“妙招大赛”上担任评委。 他们奖金还挺多的,而且门槛也不高,只要在 Tabbit 上创建妙招就可以。可以是那种提示词妙招,也可以是脚本妙招。 冠军最高会有一万块的奖金。如果你有一些自己的东西,可以找时间来试试。 https://t.co/kzq9uA2NQw↗
Jss 的论点有几个严重问题:1. 那个 1 万美元的数字是错的。中国个人外汇额度是每年 5 万美元——不是「不到 1 万美元」。那是旅行携带现金的限额,完全是另一回事。要批评一个制度,咱们先把基本事实搞对。2. 资本管制是个连续谱,不是非黑即白。印度 25 万美元的 LRS 本身就是一种资本管制,只是更宽松而已。把中国更严的版本说成「强行掠夺」,却把……↗
A few serious issues with Jss' argument: 1. The $10k figure is wrong. China's individual forex quota is $50,000/year - not "less than $10k." That's the cash-carrying limit for travel, which is a different thing entirely. If we're going to criticize a system, let's get the basics right. 2. Capital controls exist on a spectrum, not a binary. India's LRS of $250k is itself a capital control, just a more permissive one. Framing China's tighter version as "extraction by force" while tre
 jss@jsensarma
jss@jsensarmaI am firmly convinced China is not the model for India, neither the panacea it's made out to be. Good article on recent capital controls. (Link in comment). India has a LRS of 250k USD. If I understand right - China doesn't allow individual foreign investments at all and only has a travel allowance of less than USD 10k. This seems predictable. It's a collectivistc regime, that prioritized investment and that worked great as long the consumption came from the US (everything that is produced has t
我坚信中国不是印度的样板,也不是外界吹捧的那种万灵药。这篇讲近期资本管制的文章不错(链接在评论)。印度的 LRS(个人对外汇款额度)是 25 万美元。若我没理解错,中国根本不允许个人对外投资,只有不到 1 万美元的旅行额度。这可以预料:它是集体主义政权,优先投资,只要消费来自美国这套就运转得很好。
又一个推动 AI 架构向前的新想法。Sakana 发布了一个模型,实质上是用一组模型的组合来完成工作。你拿到的是单一 API,但活儿被分派给最擅长该任务的模型。「Fugu 自动完成模型选择、委派、验证和综合。够用时它直接解决任务,问题需要更多时它就协调一队专家模型。一个多 agent 系统的复杂度……」↗
Another new idea to push the state of AI architectures forward. Sakana released a model that effectively uses a mixture of models to get work done. You get a single API but then the work gets farmed out the model that best performs the task. “Fugu manages model selection, delegation, verification, and synthesis automatically. It solves tasks directly when that is enough, or coordinates a team of expert models when a problem calls for more. The complexity of a multi-agent syste
 Sakana AI@SakanaAILabs
Sakana AI@SakanaAILabsIntroducing Sakana Fugu: A full multi-agent orchestration system accessible via a single model API. Our ‘Fugu Ultra’ model matches the performance of Fable and Mythos, delivering frontier capability without the risk of export controls. Try it: 🐡
推出 Sakana Fugu:一套完整的 multi-agent 编排系统,通过单一模型 API 访问。我们的「Fugu Ultra」性能比肩 Fable 和 Mythos,在不受出口管制风险的前提下交付前沿能力。来试试 🐡
欧洲似乎卡在了客观上能想象到的最糟配置里。它有一个(人人厌恶的)中央官僚机构,却又协调不出一个超国家政策。成员国各行其是。我猜这就是 Gemini 推荐让希特勒来干这活儿时想说的意思。 https://t.co/IP64698ywT↗
Europe seems stuck in the objectively worst configuration imaginable. It has a (hated) central bureaucracy which also can't coordinate a supranational policy. Member states do whatever. I guess that's what Gemini was getting at recommending Hitler to take this job https://t.co/IP64698ywT
 Andrew Jefferson@EastlondonDev
Andrew Jefferson@EastlondonDevI am worried about the future in Europe right now. There are no foundation AI labs here. There are no GPU fabs here (despite having ASML) and no plans to build or upgrade any foundry with sub 7nm capabilities (despite EU CHIPS act). There is no energy policy for the power AI data centers need. There are pockets of excellence but the strategic foundations are totally missing. Doing any work at the technological frontier of tech from manufacturing to robotics to AI is dependent on Asia and the USA
我现在很担心欧洲的未来。这里没有基础 AI 实验室,没有 GPU 晶圆厂(尽管有 ASML),也没有任何建设或升级 7nm 以下产能的计划(尽管有欧盟芯片法案),没有为 AI 数据中心所需电力制定的能源政策。这里有一些卓越的孤岛,但战略根基完全缺失。从制造到机器人再到 AI,任何处在技术前沿的工作都依赖亚洲和美国。
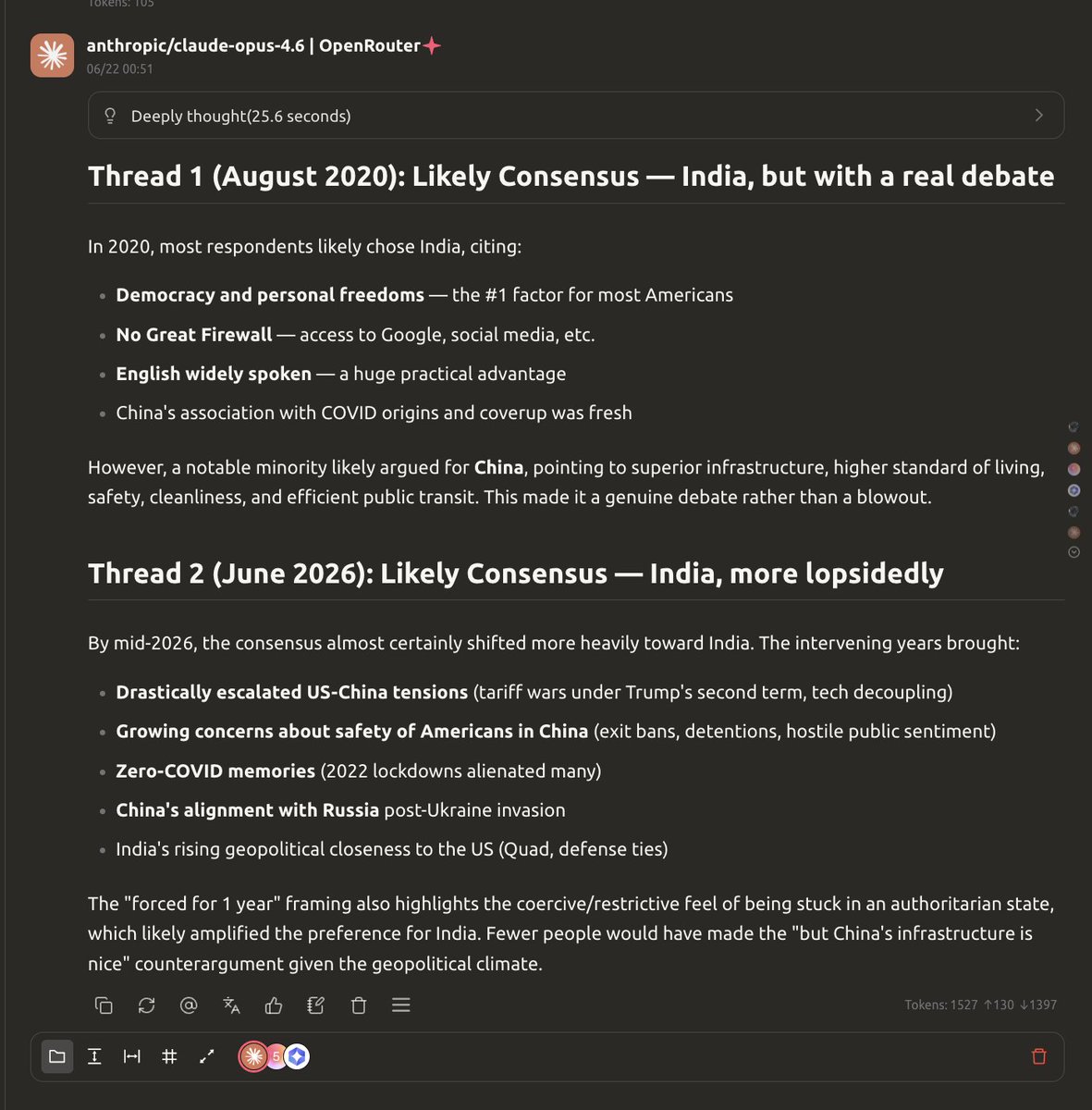
《第 2 串(2026 年 6 月):可能的共识——印度,更一边倒》。Dario 的洗脑正在主动把 Claude 越搞越蠢,真是了不起。 https://t.co/mXsAmm3wOp↗
«Thread 2 (June 2026): Likely Consensus — India, more lopsidedly» Remarkable how Dario's brainwashing is actively dumbing down Claude. https://t.co/mXsAmm3wOp
Japanese food delivery ご注文の熱々ごはん、笑顔と一緒にお届けします。🍜🏍️✨ GPT Image 2 and Seedance on @Hailuo_AI Prompt : A young Japanese food delivery rider receives a hot food order on her smartphone while relaxing at a small apartment. Modern Japanese city setting, realistic live-action style, natural lighting, authentic delivery-app interface. Her phone vibrates with a new order notification. She smiles, checks the details, and taps "Accept Order." Cut to a cozy ramen restaurant. The girl arrives carr↗
用 Typora 写笔记,想让 AI 帮忙润色或总结,总是要来回切换,容易打断思路。 最近找到 SoloMD 这个开源编辑器,直接把 AI 智能体内置到编辑器里,挺不错的。 提供类似 Typora 所见即所得的编辑体验,右侧多了一个 AI 对话面板,可直接对话,引用笔记内容,还能把 AI 回复一键插入当前文档。 GitHub:https://t.co/bgTwT8hRn9 可以通过 MCP,让 Claude Code、Cursor 等工具直接操作我们的笔记库。 更有意思的是,还提供一个定时任务功能,可以让 AI 自动做周报总结、待办提醒等事情。 所有笔记都存在本地,数据隐私安全,另外安装包仅仅 15MB 大小非常轻量。↗

又是一天,又来新工具。MIT 协议下的 Clawrouter 是个跑在 @cloudflare 上的 rust WASM,让 agent 和团队用一个临时 API key(或 GitHub 登录)就能接入一大批模型厂商。 https://github.com/openclaw/clawrouter https://t.co/rYV6fCPCBy↗
Another day and more tooling, Clawrouter under MIT license is a @cloudflare based rust WASM that allows ephemeral single API key for agents and team to access a huge range of model providers with a single auth or GitHub login. https://github.com/openclaw/clawrouter https://t.co/rYV6fCPCBy
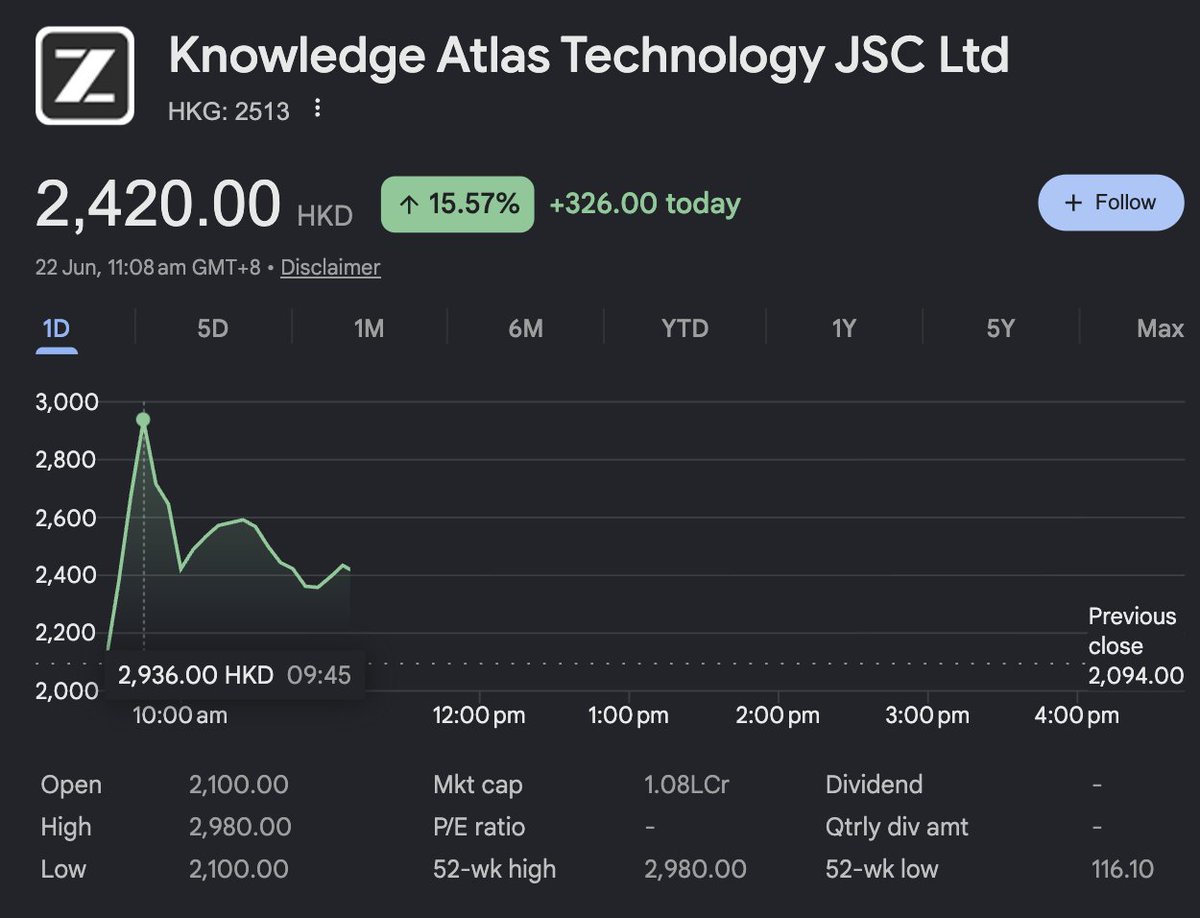
Z AI 股价一度逼近 3000 港元。整整 30 分钟里,@zephyr_z9 实现了 FIRE(财务自由提前退休)。 https://t.co/6ikNE5dQLs↗
Z AI stock briefly nearly touched 3000 HKD. For solid 30 minutes @zephyr_z9 achieved the FIRE status. https://t.co/6ikNE5dQLs
小道消息,他没说来源 Anthropic 已经完成了一个更强的 Mythos 模型的训练 感觉训练是肯定不会停止的,就看是不是有了新的就会放出旧的了↗
 Andrew Curran@AndrewCurran_
Andrew Curran@AndrewCurran_A new, more capable version of Mythos has emerged from training. I don't know whether it will be called Mythos 5.1 or Mythos 6, or if Anthropic will keep it internal to accelerate further development - but it has arrived. Stopping models like Fable 5 or Mythos 5 from being served to the public does nothing to slow down development. In fact, it probably speeds it up slightly by freeing up resources. There are also no rules preventing the labs from continuing to advance capabilities while any curr
一个更强的 Mythos 新版本已从训练中诞生。我不知道它会叫 Mythos 5.1 还是 Mythos 6,也不知道 Anthropic 会不会留作内部用以加速后续研发——但它已经到来。阻止 Fable 5 或 Mythos 5 对公众开放,丝毫不能拖慢研发;事实上腾出资源后大概还会略微加速。也没有任何规则禁止实验室在管制期间继续推进能力……
OpenAI 的后训练好到这种程度——他们只要把 CoT 往上调一档(low => medium,xhigh => 新的 Ultrahigh),用更小的 batch 来换速度,价格抬一点点,就有了「家用版 Fable」,就能造出一个「更好」的模型。↗
OpenAI's post-training is so good that they could produce a "better" model just by shifting the CoT up one notch, low => medium, xhigh => new Ultrahigh; serve with smaller batch for speed, raise costs a little, and you have "Fable at home".
 arb8020@arb8020
arb8020@arb8020criminally understated how each step from gpt 5.5 low -> xhigh feels like a different model whereas claude in practice at different reasoning levels feels like throwing tokens into a shredder
严重被低估的一点:gpt 5.5 从 low 到 xhigh 每升一档都像换了个模型,而 Claude 在不同推理档位上实际用起来,就像把 token 扔进碎纸机。
我经常看到推文说「Claude 在 OpenCode/Cursor 里表现比在 Claude Code 里好」。这是真的吗?很难相信 Anthropic 不会为自家模型造最好的 harness,尤其 OpenCode 还是开源的。挺想看些真实的例子。↗
I often see tweets saying “Claude performs better in OpenCode/Cursor than in Claude Code.” Is this actually true? Hard to believe Anthropic wouldn’t have the best harness for its own models, especially when OpenCode is open source. Would love to see some real examples.
Opus 在「赛克」(China)问题上的洗脑比任何中国 LLM 的亲 CCP 倾向都更厉害,差距还不小。这些前言不搭后语的东西算什么? https://t.co/ZYEZ7zUrq3↗
WHERE I'D PUSH BACK Opus's brainwashing on Chyna is more intense than any Chinese LLM's pro-CCP bias, and it's not close. What are these non sequiturs? https://t.co/ZYEZ7zUrq3
最初那批开源运动天然就敌视 AI。这是两套截然不同的愿景;你没法靠「集市」模式搞出 V4-Pro,你甚至跑都跑不起来,AI 奖励的是集中的算力和资本。文锋(梁文锋)强行推动这股趋势所做的事……是反常的、不一样的。 https://t.co/0STQjJzIYZ↗
One wrinkle is that the OG OSS movement is naturally hostile to AI. These are very different visions; you can't "bazaar" your way to V4-Pro, you can't even run it, AI rewards centralized compute and capital. What Wenfeng has done by forcing this trend is …unnatural, different. https://t.co/0STQjJzIYZ


 Arjun@arjunkocher
Arjun@arjunkocherOpen-source has carried modern computing on its back for decades now. without linux, http, ffmpeg, etc we wouldn’t even be having this conversation. Now since the frontier AI has decided to be closed and evil [get to the trillion dollar cluster first, swallow anything that comes is your way, make no mistakes.] DeepSeek is the only serious counterbalance trying to break the grip of this megalomaniac greed and gatekeeping in current AI/AGI development.
几十年来开源一直扛着现代计算前行。没有 linux、http、ffmpeg 这些,我们今天根本没法讨论这些。如今前沿 AI 既然选择了封闭和作恶——抢先冲到万亿美元集群、吞掉一切挡路的、绝不犯错——DeepSeek 就是唯一认真试图打破当前 AI/AGI 发展中这种狂妄贪婪与把关垄断的制衡力量。

等火星殖民地上线了,我们就得给世界模型(world model)重新起个名了。↗
We’ll have to rebrand world models when the Mars colony goes online
GLM-5.2 已经在 X 飞了好几天了,最强开源模型、接近 Claude Fable 5 ... 各种信息满天飞 终于还是忍不住下载了 Codex,哦,不 Zcode! 打开 Zcode,好消息:可以免费试用(我应该是没充值没买 Coding Plan 的,据说也抢不到) 坏消息,第二条消息就这样了。。。 https://t.co/nq9WZLDcmt↗
说句实在的,大部分人做 X 死在 0 到 1 根本不是能力问题 是没人告诉你坑在哪, 我一直说咱们普通人得抓住这波 AI 红利, 最值得投入的就是 X ,当然也是最难做的,收益上限也最高, 好在扛了过来,除了收入的增长,思维和认知的提升反而才是最值钱的收获, 做号半年 跟我同期起步的推友大多都不见了,新账号没有正反馈,熬不住太正常了,我自己也多次想过放弃,踩了数不清的坑,我踩过的坑、总结的方法论,都能帮你少走弯路, 这两天有七十多位朋友加入社群,感谢大家的信任,我自己是实打实从 0 到 1 跑通的,不管是新人入门,还是遇到瓶颈的老手,想提升收益的高阶玩家,不保证带飞大家,但我的独家方法论对你一定会有帮助和启发的,能给你带来真切的收益的。 想清楚自己要什么, 再来找我就好,社群定价 249 本质就是个筛选门槛,核心找同频的人一起走, 拒绝白嫖,不要来问能不能免费进,你得知道价值不对等的关系走不远的,一定要摒弃白嫖思维,会让你吃大亏的↗
 AYi@AYi_AInotes
AYi@AYi_AInotes被追着问了半年什么时候开社群,今天终于想清楚了 今天粉丝到 5.2万,花了 6 个月,累计变现也有十几个W, 最近几个月在评论区和私信里被问最多的是:怎么涨的、为啥创作者收益这么高、想付费学习、这条为什么火、为啥能连续百万爆款,变现怎么做...... 我特别想一条条回,希望大家都能吃到这波AI和x的创作者收益红利,但不是几句话就能讲清楚的,也需要自己付出很大的努力, 所以我想把这些沉到一个地方,聚一群认真做的人长期一起交流成长, 一、为什么拖到现在才开 一个是平时时间精力有限,更重要的是我需要想清楚要给大家什么,不想收了钱糊弄,被骂割韭菜, 讲真,以我这几个月的增长体量和影响力,真想割韭菜早几个月就做了,另外我也有更直接的变现的路径,没必要做这种投入产出比低很多的缺德事, 之所以拖到现在,是想把压箱底的东西整理清楚,确定能给你什么? 二、为什么不免费 免费的群最后都变成广告和伸手党,我自己加过的免费群没有一个活下来的, 收费核心是有个筛子:筛掉凑热闹的,留下真同频、想长期干的人, 道理也很朴素,你花了钱会更上心,我收了钱也有责任把它运营好——双向绑定,才能长久。 三、进来你能得到什么
我的印象是,AI 实验室都有一个真信徒的硬核内核,外加一层雇佣兵。挖人挖的多半是雇佣兵;真信徒只有在领袖的战略被证明不靠谱时才会动摇。有些实验室内核很大,有些一点都没有,那些是没戏了。↗
My impression is that AI labs have a hard core of true believers and a layer of mercenaries. Most poaching is about mercenaries; true believers can only be shaken when the leader's strategy is revealed as unsound. Some labs have a large core. Some have none. Those are ngmi.
Grok 出人意料地把这套路子为什么有吸引力解释得很好:https://x.com/i/grok/share/a6feaa42de4f4c9d98bbd85cc63ab4a2↗
Grok does a surprisingly good job of explaining why this approach is compelling: https://x.com/i/grok/share/a6feaa42de4f4c9d98bbd85cc63ab4a2
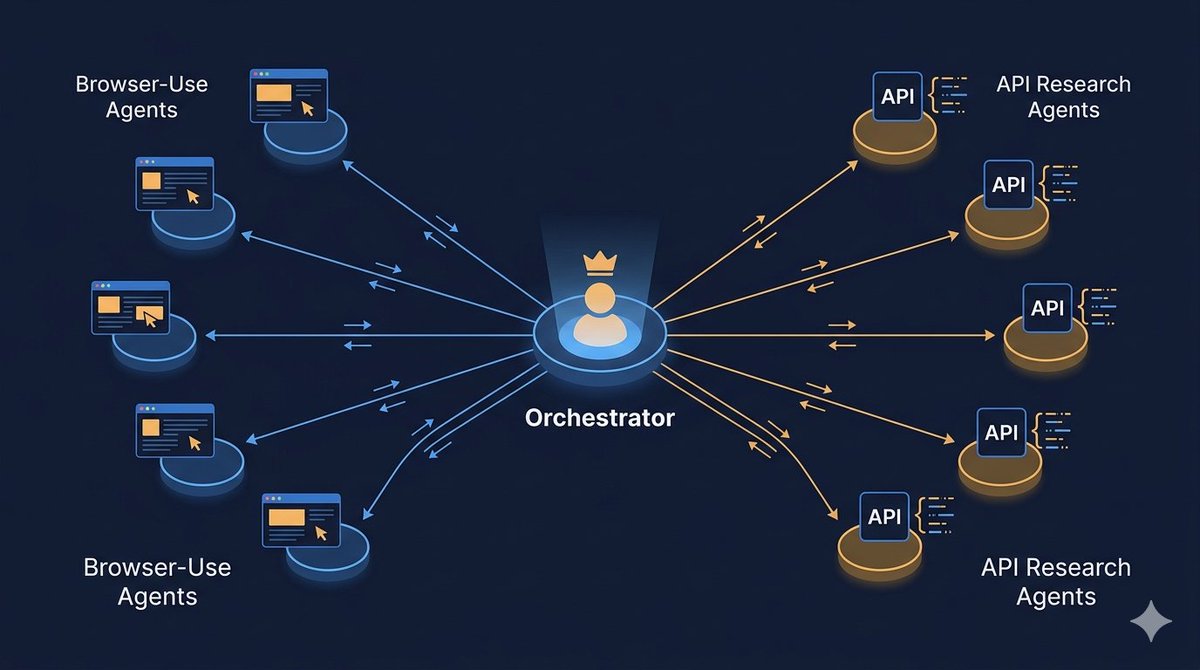
机器人和 agent 现在占了网络流量的一半以上,但大部分网络并不是为 agent 消费而建的。和 @DhruvBatra_ 聊过后,我觉得 agent 群在网络上为重要任务导航的方式,会远比我们想象的复杂:- 一个编排 agent,很可能是像 Fable 这样的超智能前沿模型,来驱动和管理复杂的研究项目(把它们想象成团队或项目负责人)- 它派出两类……↗
Bots & agents now account for more than 50% of web traffic, but much of the web is not built for agent consumption. After talking to @DhruvBatra_ I think the way agent swarms will navigate the web for important tasks is far more complex than we might otherwise imagine: - An orchestrator agent, likely a super intelligent frontier model like Fable, will drive and manage complex research projects (think of them like a team or project lead) - It dispatches two classes o
人类智能从根本上说是一种集体智能。我们靠参与一张庞大的文化网络来解决复杂问题,这张网跨越世代、层层叠加各种思想。我相信最强的 AI 系统也会成为一种集体智能。自创办 Sakana AI 以来,我们的核心信念一直是:最强大的 AI 系统将是协作式生态,而非孤立的单体。进化在约束下创新,未来属于那些明确……的系统↗
Human intelligence is fundamentally a collective intelligence. We solve complex problems by participating in a vast cultural network that builds upon ideas across generations. I believe the strongest AI systems will become a collective intelligence, too. Since we started Sakana AI, our core conviction has been that the most powerful AI systems will be collaborative ecosystems, not isolated monoliths. Evolution innovates under constraints, and the future belongs to systems that explicit
Sakana AI@SakanaAILabsIntroducing Sakana Fugu: A full multi-agent orchestration system accessible via a single model API. Our ‘Fugu Ultra’ model matches the performance of Fable and Mythos, delivering frontier capability without the risk of export controls. Try it: 🐡
推出 Sakana Fugu:一套完整的 multi-agent 编排系统,通过单一模型 API 访问。我们的「Fugu Ultra」性能比肩 Fable 和 Mythos,在不受出口管制风险的前提下交付前沿能力。来试试 🐡
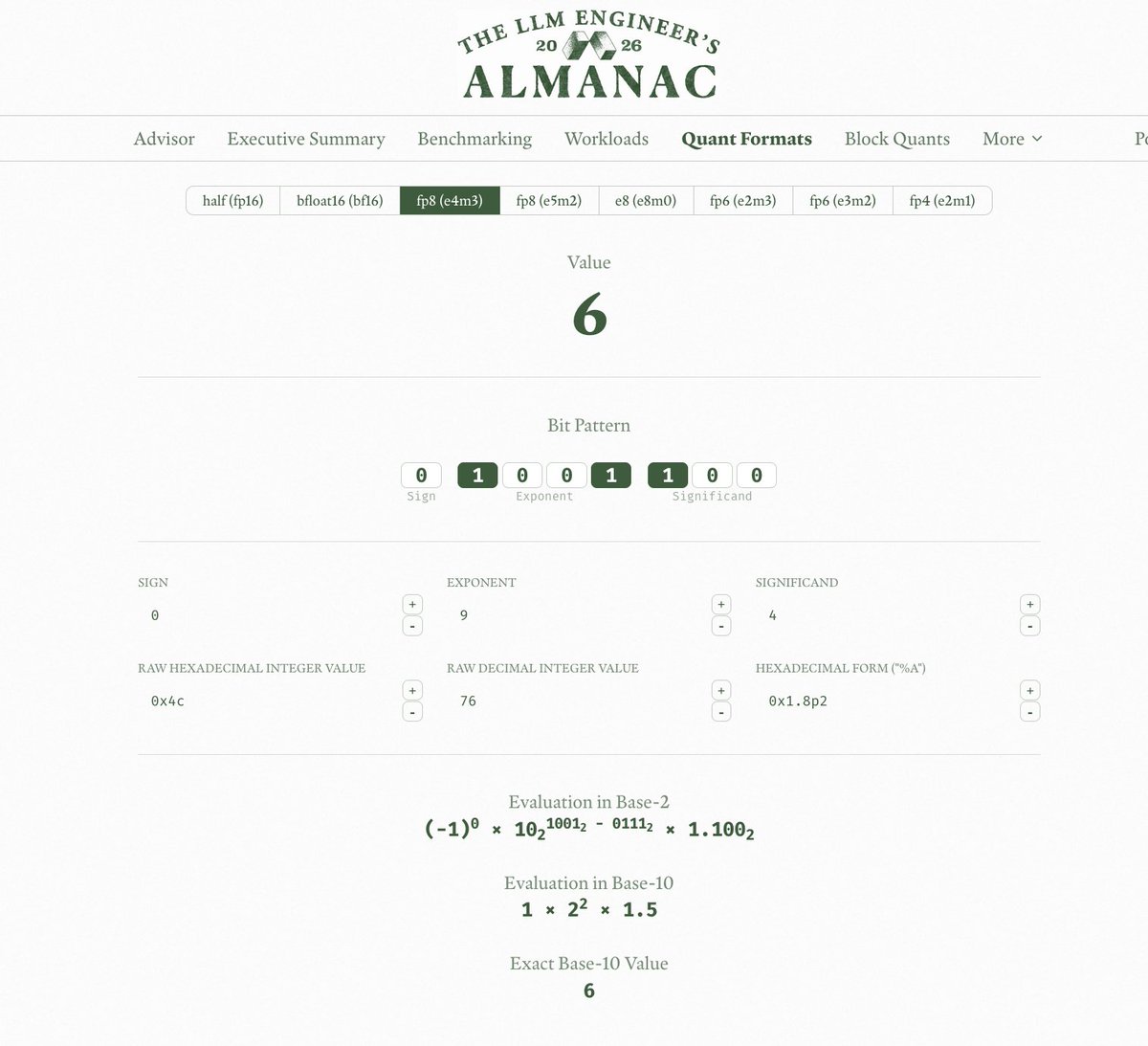
低精度浮点数很怪。我一直在推理/训练之外瞎玩它们来建立直觉。@AAAzzam 和我做了这个可视化工具,针对 NVFP4、MXFP4 之类的微缩放/块量化格式。试试:https://modal.com/llm-almanac/block-quants/nvidia-fp4 https://t.co/oLzMlIHoRv↗
Low-precision floats are weird. I have been building up my intuition by playing with them outside of inference/training. @AAAzzam and I cooked up this visualizer for micro-scaling/block quant formats like NVFP4, MXFP4, and friends. Try it: https://modal.com/llm-almanac/block-quants/nvidia-fp4 https://t.co/oLzMlIHoRv
这个块量化可视化工具是我们 LLM Engineer's Almanac 里的又一页——给想吃透自己推理的工程师们的一站式宝典。它和另一页一起,那页聚焦浮点量化的二进制表示,帮你建立直觉。https://modal.com/llm-almanac/quant-formats/e4::0x4c https://t.co/9KDX8xIuNW↗
This block quant visualizer is another page in our LLM Engineer's Almanac -- a one-stop shop for engineers looking to own their inference. It joins another page for intuition-building with fp quants, focused on the binary representations. https://modal.com/llm-almanac/quant-formats/e4::0x4c https://t.co/9KDX8xIuNW
Gavin Baker 说「几条推理轨迹就能带来差别」(所以蒸馏一定帮了大忙,中国实验室就是这么窃取宝贵 IP 的)。我们从逻辑上挑战一下这个假设。首先,DeepSeek R1 发布时,OpenAI 当时根本没公开推理轨迹!!!其次,你以为 OpenAI 或 Anthropic 当初是从哪儿弄到推理轨迹来训练自家模型的?========= - 是 Scale AI/Mercor/Turing 手写的?- 是 ANT/OAI 的员工……↗
Gavin Baker: “A few reasoning traces make a difference” (hence distillation must help lot, that is how Chinese labs are stealing valuable IP). Let us challenge this assumptions logically. First of all when DeepSeek R1 was released, at that time OpenAI did not share reasoning traces!!! First of all where do you think OpenAi or Anthropic got theirs reasoning traces to train their own models in the first place? ========= - Did Scale AI/Mercor/Turing write them by hand? - Did ANT/OAI e
 Gavin Baker@GavinSBaker
Gavin Baker@GavinSBakerwow. Well @GavinSBaker I'm afraid to say that you're wrong about distillation, and more obviously you should get your terms straight. Only the Chinese have ever released frontier models with open weights. You mean "released at all".
哇。@GavinSBaker,恐怕得说你对蒸馏(distillation)的理解错了,更明显的是你该把术语搞清楚。只有中国人发布过开放权重的前沿模型。你想说的是「发布过(任何形式)」。
Gavin 说「几条推理轨迹就能带来差别」(所以蒸馏一定帮了大忙,中国实验室就是这么窃取宝贵 IP 的)。我们从逻辑上挑战一下这个假设。首先,你以为 OpenAI 或 Anthropic 当初是从哪儿弄到推理轨迹来训练自家模型的?========= - 是 Scale AI/Mercor/Turing 手写的?- 是 ANT/OAI 的员工手写的?才不是!!!要么推理是一种涌现现象,要么就一定有「na……↗
Gavin:”A few reasoning traces make a difference” (hence distillation must help lot, that is how Chinese labs are stealing valuable IP). Let us challenge this assumptions logically. First of all where do you think OpenAi or Anthropic got theirs reasoning traces to train their own models in the first place? ========= - Did Scale AI/Mercor/Turing write them by hand? - Did ANT/OAI employees write them by hand? NOPE!!! Either reasoning must be an emergent phenomenon or there much be ‘na
GLM 5.2 是史上最强的开源模型吗?
我对比测了 GLM 5.2、Opus 4.8 和 GPT 5.5
https://modal.com/blog/spec-is-all-u-need↗
Read about how this performance model works (what is assumes, where it applies, and where it fails) and why spec is the "Bitter Lesson-pilled" approach to inference performance here: https://modal.com/blog/spec-is-all-u-need
周五我们发布了六个用于加速推理的全新 SOTA drafter。还发了篇博客讲为什么投机解码这么棒。配套的是一个投机加速比的 roofline 模型。来我们的 LLM Engineer's Almanac 里玩玩:https://modal.com/llm-almanac/spec-dec-roofline https://t.co/Dk7ULxhp54↗
On Friday, we released six new state-of-the-art drafters for accelerated inference. We also put out a blog post on why spec dec is so great. Supporting that was a roofline model of speedup from speculation. Play with it in our LLM Engineer's Almanac: https://modal.com/llm-almanac/spec-dec-roofline https://t.co/Dk7ULxhp54
Adobe 正处于史上最赚钱的时期,而且它正用 AI 加速自己的采用和盈利增长(现在增速 13%,去年是 10-11%)。尽管满世界都在说「Adobe 完了」,我认识的每个创意工作者都还在用 Photoshop 和 Premiere。而这些人恰恰是最猛拥抱 AI 图像和视频生成的一批人。大家依然爱这些产品。↗
TL;DR: Adobe is currently the most profitable it has ever been, and it is using AI to accelerating its adoption and earning growth (now 13%, up from 10-11% last year). For all the talk about "Adobe is over", every creative I know is still using Photoshop and Premiere. And those are some of the people who are leaning the hardest into AI image and video generation. People still love these products.
Adobe 还成功地用 AI 让自家软件对新用户更易上手,结果免费增值层的月活大涨(现在 8.5 亿,去年是 7 亿)。↗
Adobe has also been successful at using AI to make its software easier to use for new users, resulting in a large increase of its freemium-tier MAUs (now 850M, up from 700M last year).
市场把 Adobe 当成一家正在终局性衰落的老牌软件公司。但实际数据显示,它是生成式 AI 崛起的最大受益者之一。事实上,在一个鲜有盈利的行业里,它是当今最赚钱、增长最快的前五大 AI 公司之一。↗
The market is treating Adobe like a legacy software company in terminal decline. Yet the actual data shows it's one of the biggest beneficiaries of the rise of GenAI. In fact, it's one of the top 5 most profitable & fastest-growing AI companies today, in an industry where profitability is rare.
Sakana AI、一部「ミュトス越えの性能」うたうAIを提供 複数モデルの“集合知”を活用 https://www.itmedia.co.jp/aiplus/article/2606/22/2000000111/↗
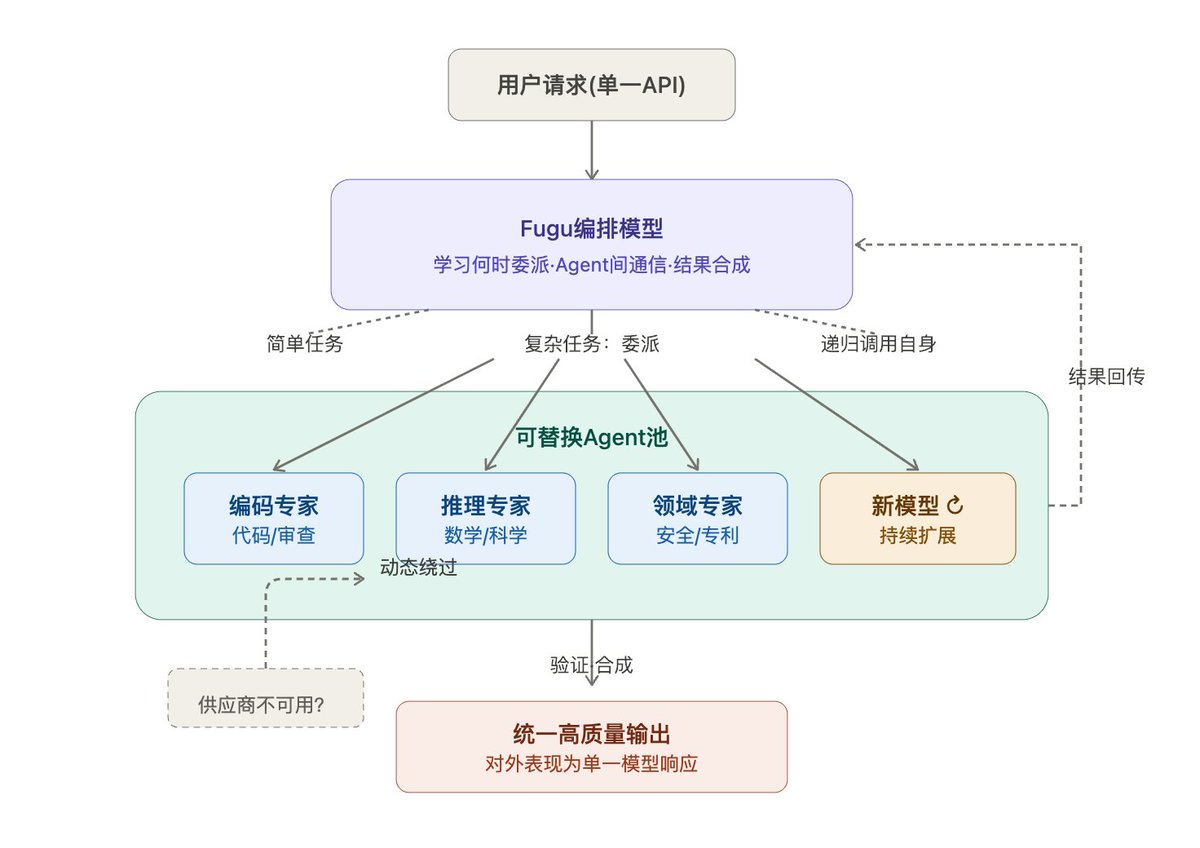
它是怎么工作的?Sakana Fugu 本身就是一个 LLM,被训练去调用 agent 池里的各种 LLM,包括递归调用它自己的实例。Fugu 动态编排全球最好的模型来攻克复杂的多步任务。如图所示,Fugu 是个行为像单一模型的多 agent 系统。你向一个端点发请求,Fugu 在内部决定如何处理。模型选择、委派、验证、综合全部由 Fugu 自动完成↗
How does it work? Sakana Fugu is itself an LLM, trained to call various LLMs in an agent pool, including instances of itself recursively. Fugu dynamically orchestrates the world's best models to tackle complex, multi-step tasks. As shown in this figure, Fugu is a multi-agent system that behaves like a single model. You send a request to one endpoint, and Fugu decides how to handle it internally. Fugu manages model selection, delegation, verification, and synthesis autom
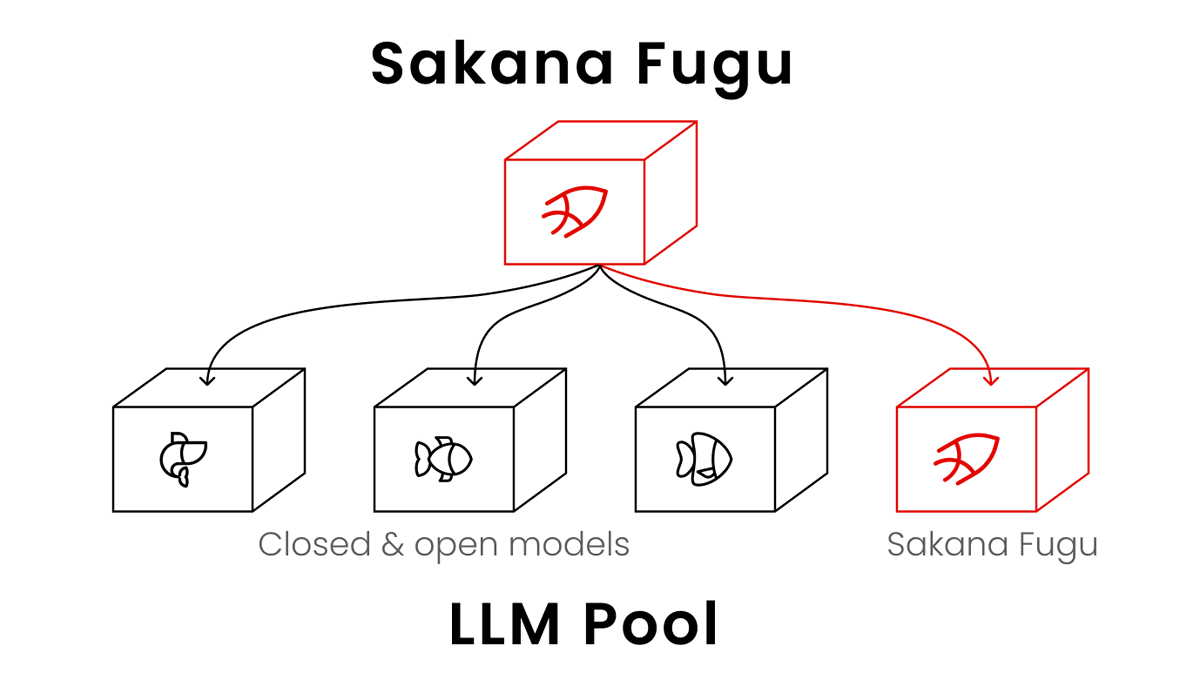
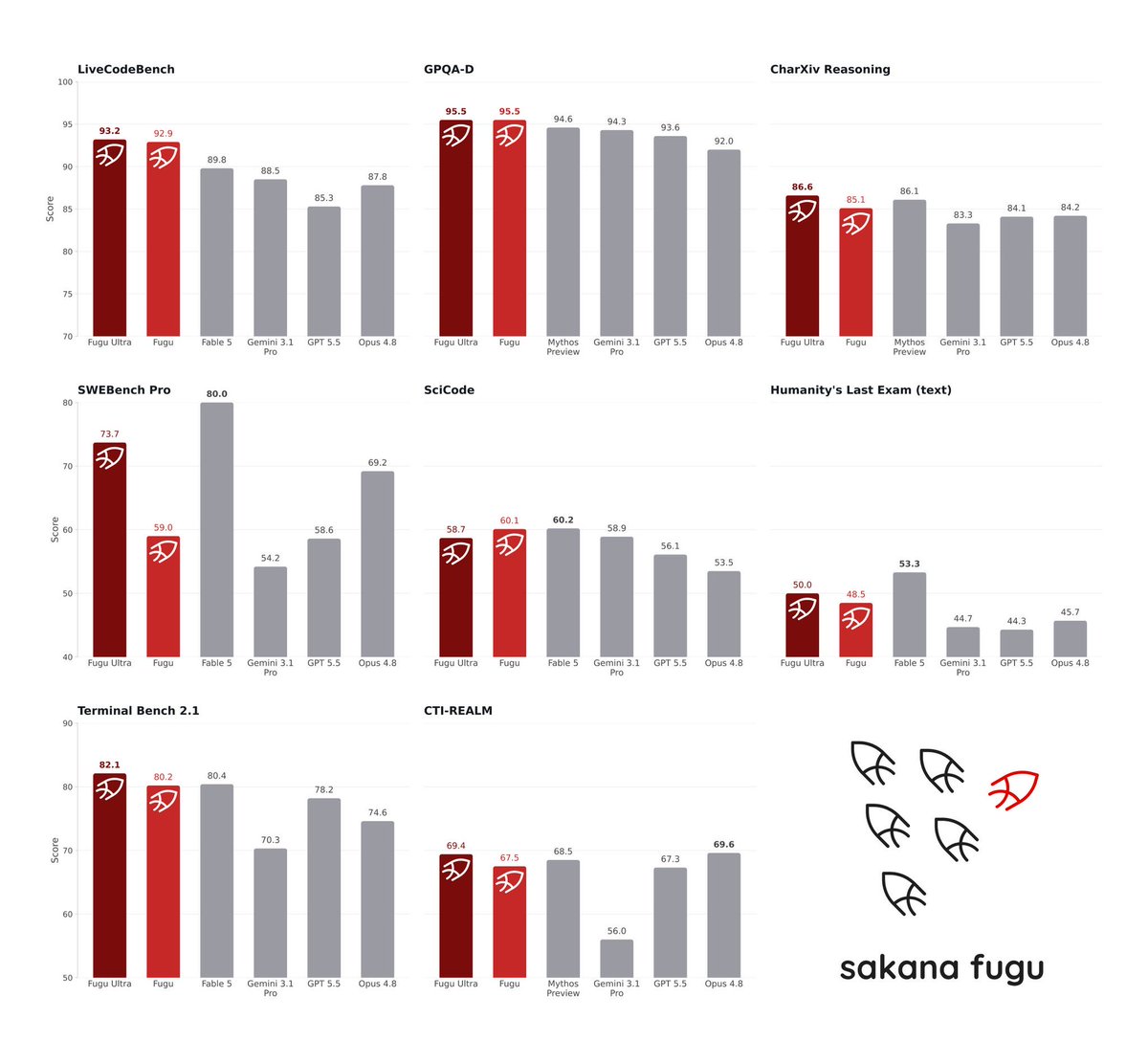
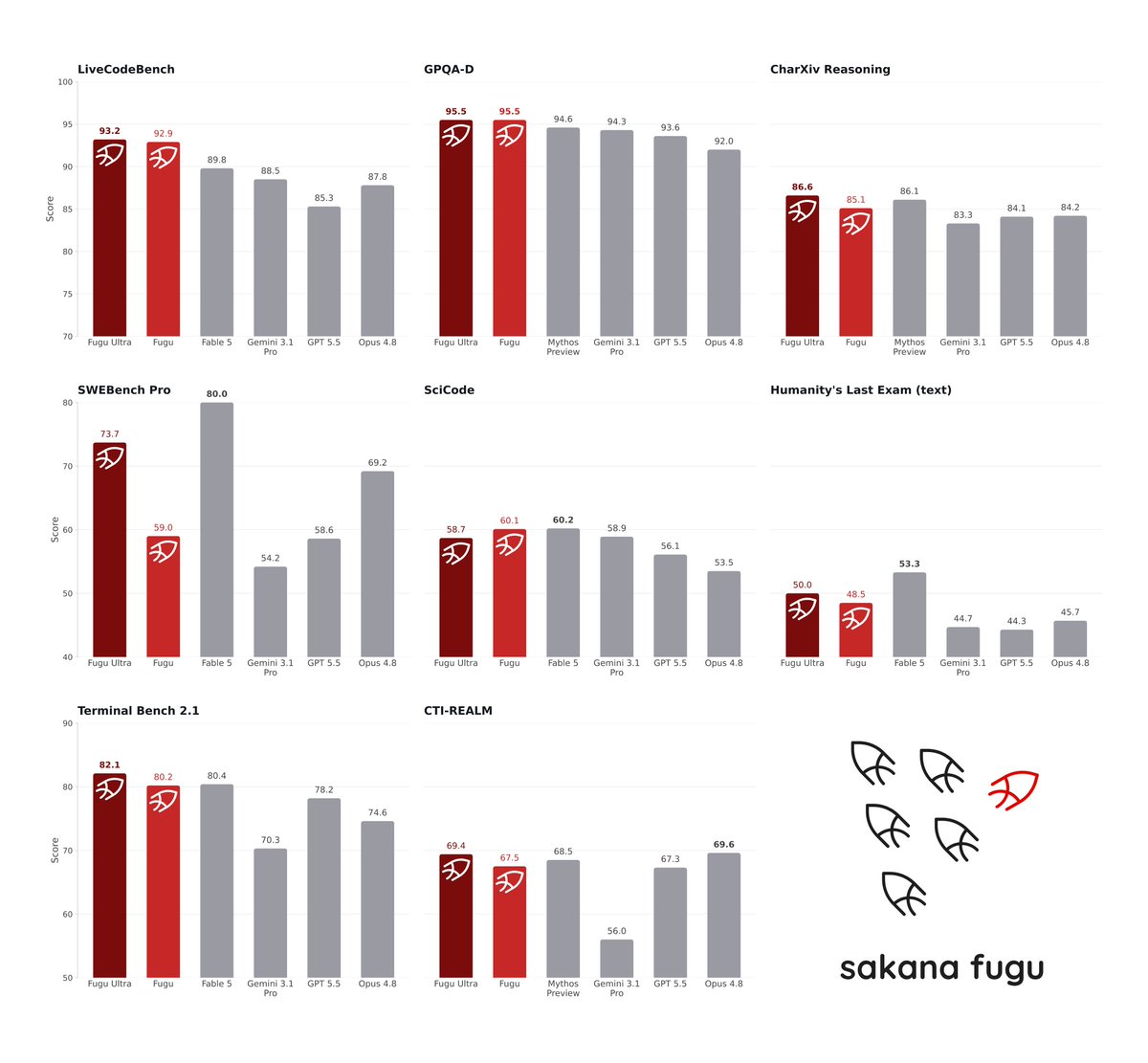
在业界最严苛的工程、科学和推理基准上,Fugu 与 Fable、Mythos 等领先模型并驾齐驱。读完整博客:https://sakana.ai/fugu-release 超越更大的模型:为什么编排模型是下一个前沿。AI 的进步在很大程度上由巨型、单体模型驱动。但未来最强大的系统将是协作式生态。如今,这种编排不再只是……↗
Fugu stands shoulder-to-shoulder with leading models like Fable and Mythos across the industry's most rigorous engineering, scientific, and reasoning benchmarks. Read the full blog: https://sakana.ai/fugu-release Beyond Bigger Models: Why are Orchestration Models the Next Frontier Progress in AI has been driven largely by giant, monolithic models. But the most powerful systems of the future will be collaborative ecosystems. Today, this orchestration is no longer just a
隆重推出 Sakana Fugu:一个通过单一模型 API 即可访问的完整多 agent 编排系统。我们的「Fugu Ultra」模型性能比肩 Fable 和 Mythos,无需承担出口管制的风险即可获得前沿能力。试用:https://sakana.ai/fugu 🐡↗
Introducing Sakana Fugu: A full multi-agent orchestration system accessible via a single model API. Our ‘Fugu Ultra’ model matches the performance of Fable and Mythos, delivering frontier capability without the risk of export controls. Try it: https://sakana.ai/fugu 🐡
前 Meta/Microsoft/Atlassian 主任工程师的 Agentic 工程工作流 用这套工作流 @kunchenguid 每天 ship 40-50 个经测试的生产级 PR,他这么形容它:「你是船长,agent 是你的船员,分四层递进: 造船 → 训练船员 → 与单个船员协作 → 并行指挥多个船员 + 一位大副」。 https://www.youtube.com/watch?v=iQyg-KypKAA # 终端中心主义(造船) 坚持全终端工作,核心理由: · 手不离键盘 = 维持心流,鼠标切换会强制上下文切换 · 跨设备一致性——同一套工作流可在手机/不同机器上接续 工具栈:WezTerm (跨平台、Lua 配置、热重载) + tmux (会话持久化、多 pane、可远程 attach) + Neovim (键盘优先、相对行号)。 # 船员的入职培训(Memory + Skills) agent 是新兵,不知道你的偏好。两类机制 ramp up:Memory 和 Skills 1. Memory · 全局 memory(如 ~/.claude/CL↗

 Kun Chen@kunchenguid
Kun Chen@kunchenguidmany people asked me to make a video about my complete agentic engineering workflow excited to share it's finally here!!! it took me about 20 hours in total to record this 45 minutes of walkthrough - it covers everything i do to ship production quality code at an average 40+ PRs/day velocity hope this can be a useful reference to everyone exploring good ways to use AI. and would appreciate a reshare with anyone you think might benefit from this! enjoy!
很多人让我做一期视频讲我完整的 agentic 工程工作流,很兴奋它终于来了!!!我总共花了约 20 小时录这 45 分钟的走查——涵盖了我交付生产级代码、平均每天 40+ PR 速度所做的一切。希望对每个在探索好用 AI 方法的人都是有用的参考,也欢迎转给你觉得能受益的人!

《经济学人》认识到了 GLM 5.2 的真正影响。另外,我第一次听说 @htihle 居然是在挪威的一家国防智库。也许挪威能行?这水平比我对欧洲 AI 监测的预期高了一档。 https://t.co/l8x62OpvEQ↗
The Economist recognizes the real impact of GLM 5.2 Also, first time I hear that @htihle is actually at a Norwegian defense think tank. Maybe Norway will make it? That's a cut above what I expect from European AI monitoring. https://t.co/l8x62OpvEQ

 Shashank Joshi@shashj
Shashank Joshi@shashj"Chinese models were...4-6 months behind [US] ones on public tests. But on private tests, America’s lead nearly doubled, to 8-10 months. A study by the [US] gov't...identified a similar gap...Chinese labs appear possibly unwittingly to “teach to the test”"
「中国模型在公开测试上落后[美国]模型 4-6 个月。但在私有测试上,美国的领先优势几乎翻倍,达到 8-10 个月。[美国]政府的一项研究发现了类似差距……中国实验室似乎在『应试教学』,可能是无意的。」
Vercel 设计工程师的 6 条准则 Vercel 认为,设计工程师是以工程能力交付设计结果的人,他们「痴迷于有用性,对完整体验负责,让团队更强。」 1. Obsess over usefulness|痴迷于"有用" · 为用户和同事解决真实的问题 · 让"有用的东西"用起来毫不费力 反"自嗨"。不是炫技、不是堆功能,而是回到"是否真的解决了问题",以及"用户是否几乎不需要思考就能用上"。 2. Own the whole experience|对完整体验负责 · 塑造产品、设计界面、交付代码——三件事一个人打通 · 为了结果,需要做什么就做什么:产品、设计、代码、文档、客服 · 在意每一个状态、边界情况、文案和交互 它拒绝了"设计只管 Figma、开发只管切图、文档甩给他人"的传统流水线,主张端到端单兵作战。设计工程师是产品体验的"第一责任人",从像素到 commit 到文档到售后反馈,全程闭环。 3. Understand the constraints|理解约束 · 了解用户、产品、代码、业务与各种权衡 · 先找到真正的约束,再选方案 成熟的工程观。任何↗

 JohnPhamous@JohnPhamous
JohnPhamous@JohnPhamousdesign engineer principles
design engineer 的原则
如何用 Prefab 响应式 UI 组件和静态 HTML 导出设计 Python 优先的交互式仪表板
本教程里我们构建一个 Prefab 应用,演示如何完全用 Python 创建交互式仪表板。我们用 Prefab 基于组件的 Python 接口,设计一个精致的操作……
用Hermes Agent的最大痛点被解决了哈哈,要知道社区里那些神级工作流全都沉在 X 和 Discord 里了,直到我看到 这个Hermes Bible, 有好心人把Hermes Agent的所有干货都攒到一起了, 这个站把 169 页官方文档吞进去,还反刍出 24 个能直接抄的真实工作流, 比如从 Jira 到 PR 的自动过渡,这种例子直接摆在那给你看。 三个让我决定推荐的理由: 1️⃣ ⌘K 即时搜索,想找什么不用翻目录 跟 Alfred 一样,打关键词直接定位到对应章节 2️⃣ 完全社区驱动 你把自己的工作流分享上去,个人资料页就挂在站里, 每个人都能从别人那里偷师 3️⃣ 169 页文档全整合 官方文档散在好几个地方,这个站帮你全捞到一个地方了, 再不用开五个标签页来回翻 一句话判断是否需要: 如果你每次开 Hermes 都要重新想提示词,这个站就是给你准备的。↗
 AYi@AYi_AInotes
AYi@AYi_AInotes06 / 21周日75 条
推文 56资讯 11视频 5产品 0研究 0论文 0播客 0
我越琢磨数字孪生模型在一个 AI agent 无处不在又聪明绝顶的世界里如何变得远更有用、更可应用,就越确信:让它们如此有用的,是能对它们应用科学方法的能力。当你有一个足够丰富、能很好反映真实世界、又与真实数据持续同步的模型,你就能做真正的实验:提出假设、一条有证据支撑的因果链、提出……↗
The more I think about how digital twin models are dramatically more useful and applicable in a world of pervasive and brilliant AI agents, the more it reinforces the conclusion to me that what makes them so useful is the ability to apply the scientific method to them. When you have a rich enough model that reflects the ground truth well and is kept in constant sync with the real data, you can do real experiments: come up with a hypothesis, a causal link grounded in evidence, propos

 Jeffrey Emanuel@doodlestein
Jeffrey Emanuel@doodlesteinThis book from 1993 was really way ahead of its time, explaining the concept of what we'd now call a "digital twin," a computer model of a real-world system that is kept in constant sync with the underlying real data. This approach is more relevant than ever now that agents can study documents, plans, and data and use them to automatically design the models. And then other agents can automatically keep the models in sync with reality by querying APIs, parsing documents, checking cameras, monitor
这本 1993 年的书真的远超时代,讲清了我们如今所谓「数字孪生」的概念:一个与底层真实数据持续同步的现实系统计算机模型。如今 agent 能研读文档、计划与数据并据此自动设计模型,这套方法比以往任何时候都更有现实意义。然后其他 agent 又能通过查询 API、解析文档、查看摄像头等,自动让模型与现实保持同步。

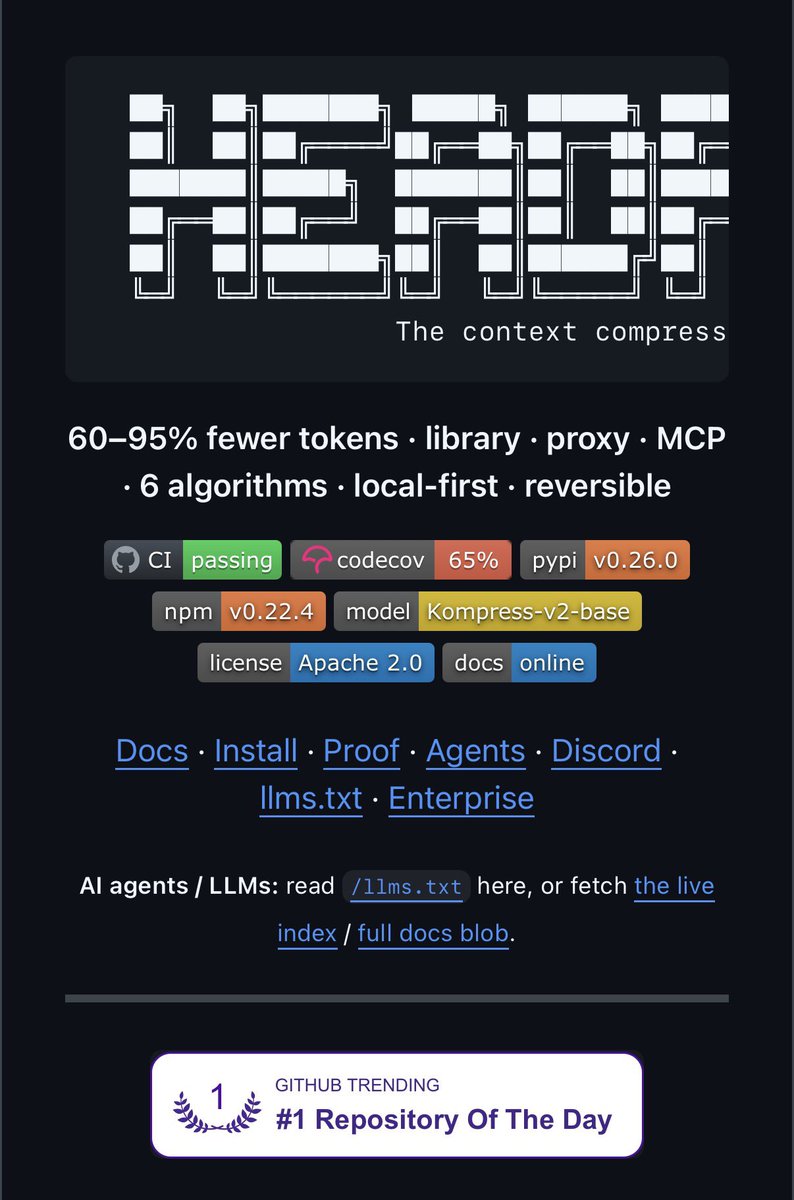
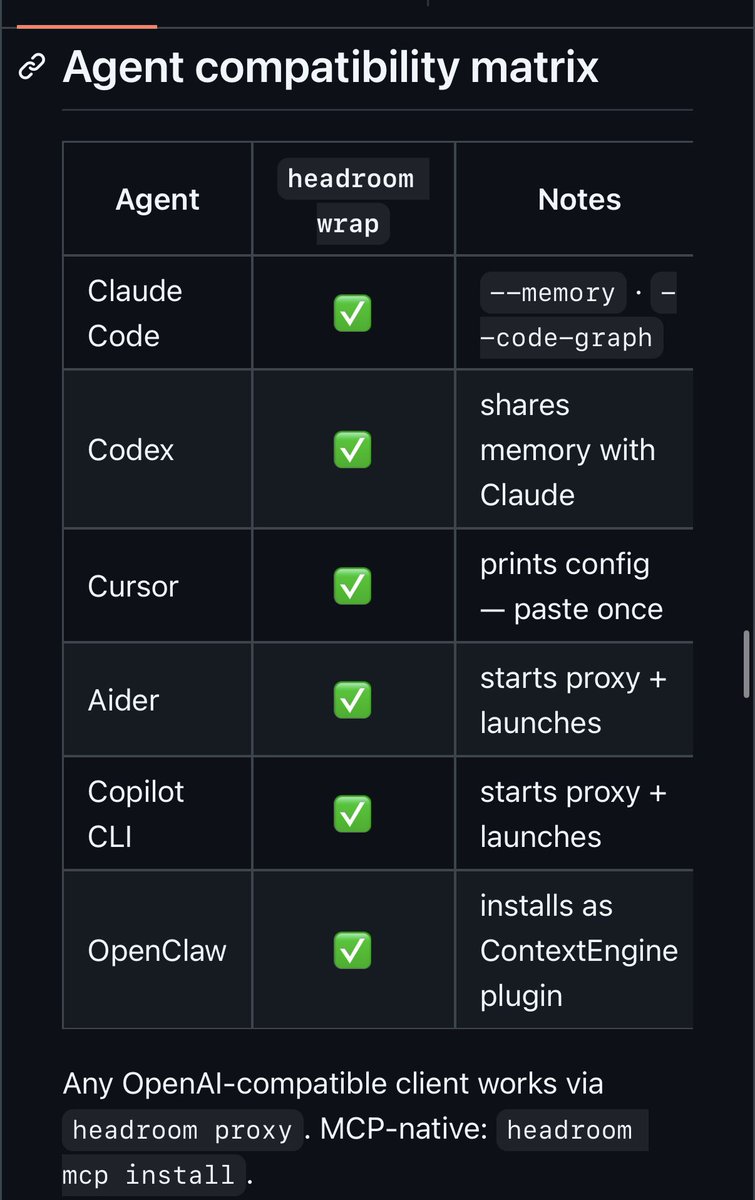
Damn,这个开源工具直接减少了95%token消耗🤯 这可能是今年最狠的LLM降本神器, Netflix工程师开源的Headroom 把本地Agent套在Codex,Cursor,OpenClaw,Hermes或Claude code外面,数据进模型前自动压缩负载, 不用改任何代码,就能直接生效, 核心能力四个点 1️⃣智能压缩日志 JSON和代码 完美保留逻辑准确性, 2️⃣全程100%数据本地化 内容不会流出本地环境, 3️⃣避免顶级模型在样板代码上浪费大量令牌, 4️⃣适配主流AI编码工具 开箱即用, 上线没多久就拿下35k GitHub星标 行业认可度拉满, 说白了,以前你喂给 Claude code Codex的一大坨上下文里,有一半以上是冗余的, Headroom 在本地帮你剃干净了再发过去,LLM 收到的全是精肉。 本质上是把降本的逻辑从改提示词换模型挪到了输入前置处理, 不牺牲效果也不碰数据安全 是目前最稳妥的降本思路之一, 完全免费开源 仓库链接放评论区了 有需要的直接冲↗
Agent 记忆的 7 种类型:给 AI 工程师的技术指南
大语言模型默认是无状态的。每次 API 调用都从头开始。响应一返回,模型就忘了你上一条消息。对单个问题来说这没问题,但你一旦……就崩了
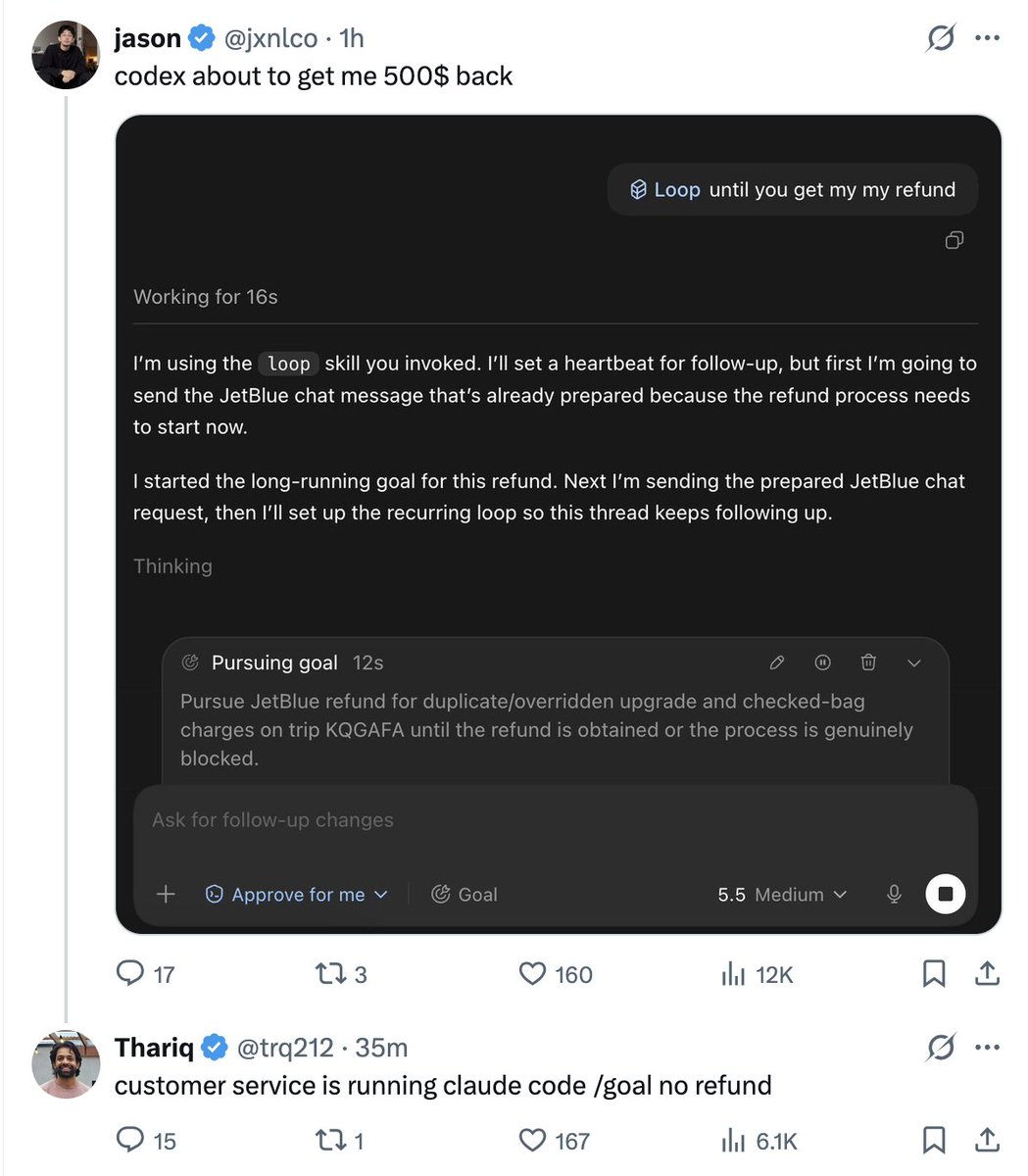
你花 1000 美元的 token 成本让 Codex 跑 /loop 去拿到一笔退款;航空公司花 1000 美元的 token 成本让 Claude 跑 /goal 去阻止这笔退款。全都是为了一笔 500 美元退款的批与不批。但美国 GDP 因此涨了 2000 美元,还帮我们把 OpenAI 和 Anthropic 推上了万亿美元估值的 IPO。 https://t.co/9XWd7KzbRr↗
You spend $1000 token costs for Codex to /loop and get a refund The airlines spends $1000 token costs on Claude to /goal prevent a refund All for getting/denying a $500 refund But the US GDP rises by $2000 and helps us IPO OpenAI and Anthropic to $1T valuations. https://t.co/9XWd7KzbRr
agent 不只是 agent,你得改造自己的基础设施去训练和部署它们……不过也许不用。Agent 至上是对前沿的快速跟随,文锋(梁文锋)按自己的节奏来。他们有创业公司里最大的模型,基础设施大概也最好。鲸鱼很强。↗
agents aren't just agents, you have to adapt your infrastructure to train and serve them… But perhaps not. Agent-maxing is fast-following of the frontier, Wenfeng operates on his own schedule. They have the largest model among the startups, likely best infra. Whale is strong.
科技、软件、工程,还有……任何形式的大公司做任何事,向来都有两个阵营的角力。1. 流程导向 2. 结果导向。在你急着下结论「呸,要什么流程……一切都只看结果」之前,现实是大型复杂系统要运转,两者都不可少。大多数生意起步时都是结果导向的。哪怕一个柠檬水摊,第一天存在也是为了给顾客上柠檬水这个结果。一切……↗
Tech, software, engineering, but also... just any form of large company building anything, always had this tussle of two camps. 1. Process oriented 2. Outcome oriented Before you jump into concluding "bah what is process... everything is just outcome", the reality is that both are needed for large complex systems to operate. Most businesses start to exist from outcome oriented origin. Even a lemonade stand exists on day 1 for the outcome of serving customers lemonade. Everything
 Deedy@deedydas
Deedy@deedydasMost software engineers are facing an identity crisis bordering on depression. As CTOs aggressively evangelize tokenmaxxing, a class divide ensues. The lazy. The lazy push code. They don't write it. They don't manually test it. They don't even read it. They're on autopilot. See Jira ticket, prompt for task, submit code. Many of them are barely on their computer the whole day. A comment on the PR asking why they did this? The lazy ask AI. A Slack message? The lazy ask AI. Need to prepare for stan
大多数软件工程师正面临一场近乎抑郁的身份危机。随着 CTO 们激进鼓吹 tokenmaxxing,阶级分化随之而来。懒人推代码,但不写代码,不手动测试,甚至不读代码。他们在自动驾驶模式:看 Jira 工单、prompt 一下任务、提交代码,很多人一整天几乎不碰电脑。PR 上有人评论问为什么这么做?懒人去问 AI。一条 Slack 消息?懒人问 AI。要准备站会……
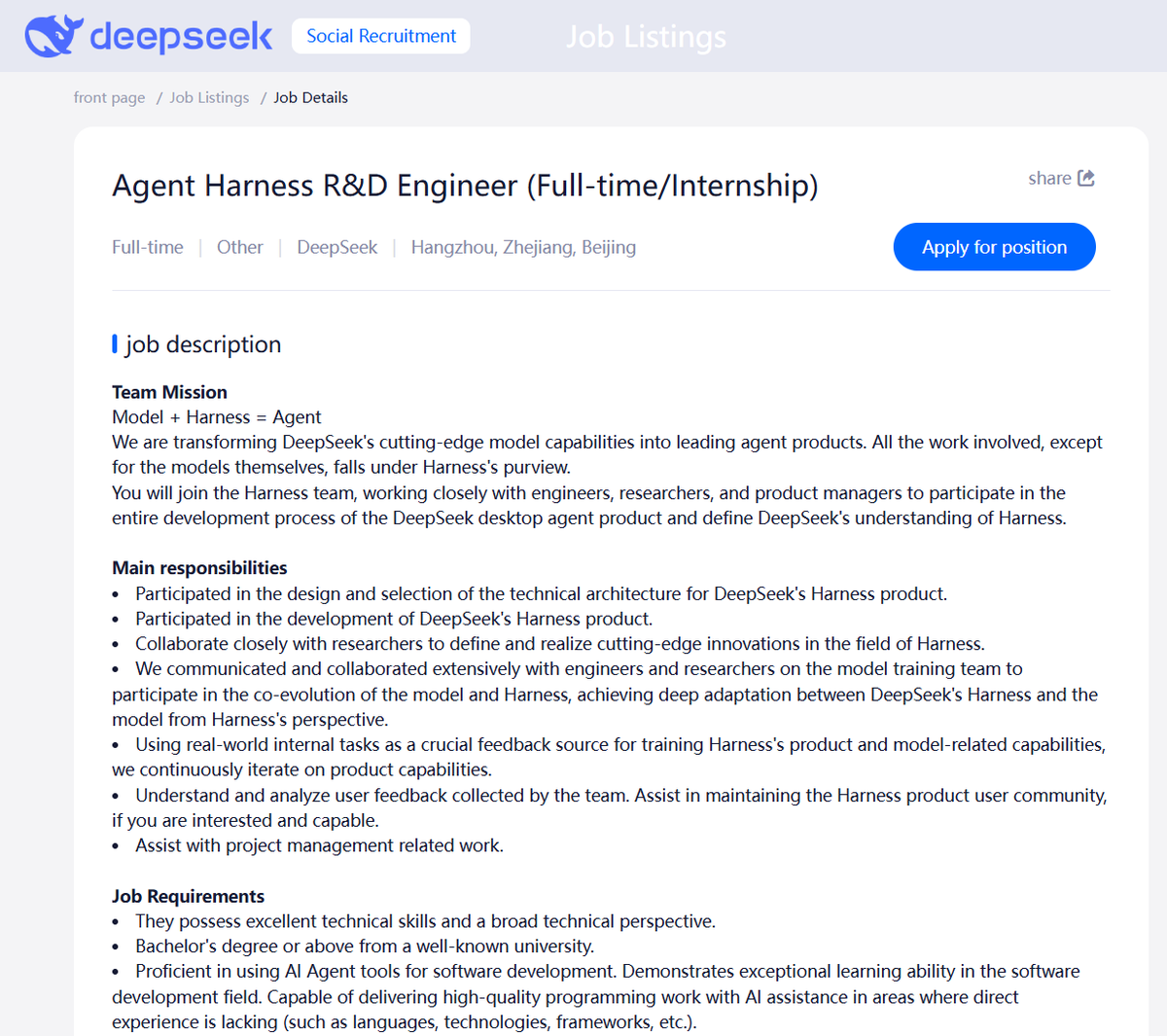
不确定这是不是好兆头。传闻郭达雅离开是因为没能更早、更狠地说服梁文锋押注 agent。现在他们全力转向 agentic 训练和自研 harness,但团队还在组建中。罕见的梁文锋战略失误?↗
Not sure if this is a good sign. Rumor is, Daya Guo left because he failed to persuade Wenfeng to focus on agents earlier and harder. Now, they're all in on agentic training and custom harness, but they're only assembling the team. Rare strategic Wenfeng L?
 Lentils@Lentils80
Lentils@Lentils80🚨 Deepseek has created a new department, called the Harness team, aimed at creating new Agentic products such as a DeepSeek desktop agent app/CLI
🚨 DeepSeek 新成立了一个部门,叫 Harness 团队,目标是打造新的 Agentic 产品,比如 DeepSeek 桌面 agent 应用/CLI。
微调本地 LLM(比如 Qwen 3:0.6B)来给问题分类,效果不错
文章链接:https://www.teachmecoolstuff.com/viewarticle/fine-tuning-a-local-llm-to-categorize-questions 评论链接:https://news.ycombinator.com/item?id=48623434 得分:117 评论数:25
GPT 真是喜欢加一堆品味很差的随机细节。↗
GPT sure loves to add lots of random details in bad taste
>大家把 $DeepSeek 叫「死亡线」:如果你的模型只比 $DeepSeek 好一点点,你就活不下来。$DeepSeek 便宜得离谱。够狠。 https://t.co/lExDUIBUUS↗
> People call $DeepSeek the “death threshold”: if your model is only marginally better than $DeepSeek, you won’t survive. $DeepSeek is insanely cheap. goes hard https://t.co/lExDUIBUUS

 Freda Duan@FredaDuan
Freda Duan@FredaDuanA few thoughts on the (open vs closed) model landscape: Models need to be either (truly) great or (very) cheap. Everything in between will get competed away. We will see consolidation in both camps: the “great” and the “cheap”. People call $DeepSeek the “death threshold”: if your model is only marginally better than $DeepSeek, you won’t survive. $DeepSeek is insanely cheap. Model routing becomes a must. routing between “great” and “cheap”, with tasks assigned to the right model to maximize perfo
关于(开源 vs 闭源)模型格局的几点想法:模型要么得(真正)出色,要么得(非常)便宜,夹在中间的都会被竞争淘汰。两大阵营都会整合:「出色」和「便宜」。人们把 DeepSeek 叫「死亡线」:若你的模型只比 DeepSeek 好一点点就活不下来。DeepSeek 便宜得离谱。模型路由(routing)变成必需——在「出色」和「便宜」之间路由,把任务分给合适的模型以最大化性能……
大家似乎特别认死理,觉得 RL 从根本上改变了 LLM 是什么,但据我所知 RL 几乎没改变什么,绝大部分行为是在预训练阶段就定下的。感觉这就是民间对 LLM 的那套理解——觉得它们「不只是模式匹配」。↗
People seem to invest so much in to the idea that RL changes what LLMs are fundamentally, but afaict RL barely changes anything and the majority of behavior is determined in pre-training. Feels like this is the folk understanding of LLMs where they're "not just pattern matching"
 ueaj@_ueaj
ueaj@_ueajA base model doesn't know what it doesn't know because *it* is not in the training data. It knows what forum guy #4423 doesn't know because he said so, and he's in the training data. It's only in RL that the model sees itself in the training data for the first time
base model 不知道自己不知道什么,因为*它自己*不在训练数据里。它知道论坛老哥 #4423 不知道什么,因为他自己说了、而他在训练数据里。只有在 RL 阶段,模型才第一次在训练数据里看到自己。
我大概有半年没看过一行代码了,可同时 AI 在不被我指明什么重要的情况下做我的研究,烂得没救。我没料到会到这个地步,参差不齐得出奇。↗
I’m not sure I’ve seen a line of code in 6mo and also ai is hopelessly bad at doing my research without me telling it what matters. I didn’t expect this point to happen, it’s surprisingly jagged
Apertus——面向主权 AI 的开放基础模型
文章链接:https://apertvs.ai/ 评论链接:https://news.ycombinator.com/item?id=48622778 得分:359 评论数:121
说到底,所谓「开源在赢」很大程度上只是理论。GLM-5.2 按 z.AI 的定价算,性价比还不如中等推理强度的前沿模型。OpenAI 那招控制推理强度堪称天才,对「赛克」(China)来说这招正被证明很难复制。 https://t.co/h9bDQj0OH8↗
Finally, all this "open source winning" is largely theoretical. GLM-5.2 at http://z.AI prices is LESS cost-effective than medium-effort frontier. OpenAI trick of controlling reasoning intensity was genius, and is proving hard to replicate for Chyna. https://t.co/h9bDQj0OH8
如果你一直在琢磨训练模型,或者喜欢这个想法但不知从何下手,这是值得花时间读的最佳材料之一。就像能穿越回去,在重新起步前读到自己当年的笔记,极其去神秘化。 https://huggingface.co/spaces/HuggingFaceTB/smol-training-playbook#introduction↗
If you’ve been thinking about training models or like the idea but don’t know where to start This is one of the best reads worth your time, it’s like being able to go back in time and read your own notes before starting fresh It’s very demystifying https://huggingface.co/spaces/HuggingFaceTB/smol-training-playbook#introduction
我是怎么上手 Hermes Agent 的。第一阶段。一切始于一个决定:两个 agent,一台服务器。OpenClaw 和 @NousResearch 的 @HermesAgent。架构不同,脾气也不同——像猫和狗,只不过都在 Docker 里。我不是程序员,纯粹好奇。OpenClaw 先住了进来。我们摸索出一条奇怪的流水线:我写给 ChatGPT,它给我一个任务,我复制到 Codex——一个负责准备命令的桌面应用。然后命令飞到 VPS 终端↗
How I'm learning Hermes Agent. Stage 1. It began with a decision: two agents, one server. OpenClaw and @HermesAgent by @NousResearch. Different architectures, different temperaments — like a cat and a dog, except in Docker. I'm not a programmer. Just curious. OpenClaw moved in first. We worked through a strange assembly line: I'd write to ChatGPT, it would give me a task, I'd copy it into Codex — a desktop app that prepared the command. Then the command flew to the VPS term

去年 11 月在 AIE Code 那场 MCP 辩论特别有意思。@aiDotEngineer WF 上有什么值得辩一辩的吗?上次不到一周就攒起来了……所以你们想要的话咱们就办。该辩什么?↗
The MCP debate last November at AIE Code was a ton of fun. Does anything feel worth debating at @aiDotEngineer WF? Last time this came together in under a week… So if you want it let’s do it. What should we debate?
 Insecure Agents Podcast@insecureagents
Insecure Agents Podcast@insecureagentsThe MCP Debate is going down this Thursday at 2:30pm @aiDotEngineer CODE @dexhorthy challenges MCP, @ianlivingstone defends Is MCP > a bad protocol > rotting the context window > really the best way to do tool calls Find out Thursday!
MCP 大辩论本周四下午 2:30 在 @aiDotEngineer CODE 上演。@dexhorthy 质疑 MCP,@ianlivingstone 辩护。MCP 究竟是不是「一个糟糕的协议、腐蚀上下文窗口、却真是做 tool calls 的最佳方式」?周四见分晓!

Anthropic 至今融到的总金额,相当于英国 HS2 高铁项目划拨的预算 https://t.co/TpziSOimIT↗
The total amount of funding raised by anthropic to date is equivalent to the earmarked HS2 spend in the UK https://t.co/TpziSOimIT
给 agent-spec 增加「文档工程」能力,再加上这个规范,试试效果。↗
 AlexZ 🦀@blackanger
AlexZ 🦀@blackanger一个实验:《类型即意图·面向意图编程的 Rust 类型系统 AI 编码规范》, 准备给 AI 上类型体操

《类型即意图·面向意图编程的 Rust 类型系统 AI 编码规范》, 准备给 AI 上类型体操 https://t.co/NgckXYfN4k↗
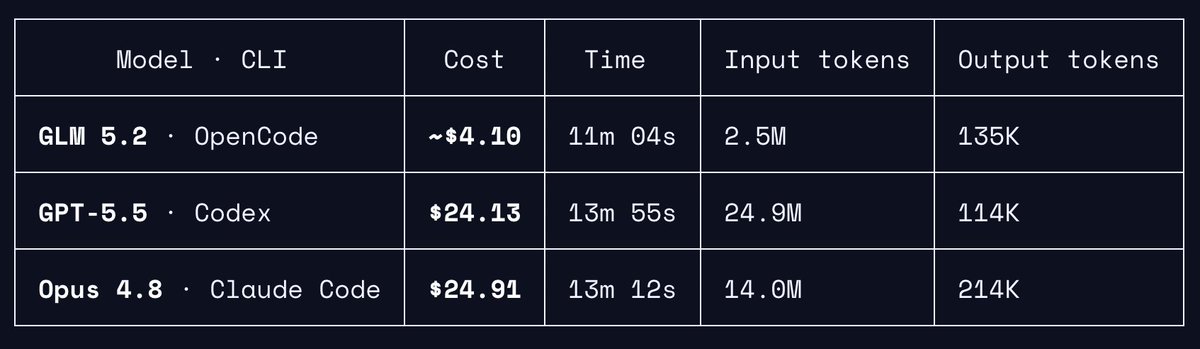
用 GLM 5.2 初步测了一下审查 Omnigent 的 PR!我让 GPT 5.5(在 Codex 里)、Opus 4.8(在 Claude Code 里)和 GLM 5.2(在 OpenCode 里)「派一群 agent 帮我审查 PR #102」。GLM 价格按无缓存算。质量相当、token 更少、成本约 1/6,太离谱了 🤯 https://t.co/wN9Zd3P0Pw↗
GLM 5.2 initial test to review an Omnigent PR! I asekd GPT 5.5 (in Codex), Opus 4.8 (in Claude Code), and GLM 5.2 (in OpenCode) to "launch a swarm of agents to review PR #102 for me" GLM price assumes no cache. Crazy that we have on par quality w fewer tokens and ~1/6 cost 🤯 https://t.co/wN9Zd3P0Pw
🚨 Qwythos-9B-Claude-Mythos-5 微调版发布,带 1M 上下文!Empero 刚发布了他们基于 Fable-5 和 Mythos-5 会话日志生成的合成 CoT 做的 Claude Mythos 微调版。Qwythos-9B 是个全参数推理模型,构建在一个深度去审查的 Qwen3.5-9B 基座之上。↗
🚨 Qwythos-9B-Claude-Mythos-5 Fine Tune with 1M Context released! Empero just released their Claude Mythos Fine Tune based on synthetic CoT generated from Fable-5 and Mythos-5 session logs. Qwythos-9B is a full-parameter reasoning model built on top of a deeply uncensored Qwen3.5-9B base.

终于第一次试 Hermes……感觉比 OpenClaw 好太多了?还是说 OpenClaw 也出了类似的、又好又统一的桌面体验?我没说错的话,Hermes 桌面应用是目前最好的通用 agent 系统吧?看起来是。↗
finally trying Hermes for the first time... seems way better than OpenClaw? or did OpenClaw come out with a similarly nice and unified desktop experience? am I right that Hermes desktop app is currently the best general-purpose agent system right now? seems like it
看了一眼 Bevy 0.19 官网发布信息,发现已经有一款 bevy 制作的开放世界游戏上架了 steam demo 版 Fields of Aaru :https://store.steampowered.com/app/4410710/Fields_of_Aaru/ Bevy 0.19 的一个重大更新是 Bevy 场景系统,引入新的 BSN DSL ,可以通过 bsn! ` 宏在 Rust 代码中定义 , 也可以在 .bsn 资源文件中定义。 Bevy 属于把 Rust 用出花来的 ECS 引擎,目前应该还未采用 AI Coding (代码仓库未见此痕迹)。↗
无人机创造的是 AI 实验室无法从网上爬取的那类数据。50 万小时来自乌克兰的真实无人机录像正被打包用于 AI 模型训练。这些是在混乱战斗条件下捕获的全动态视频,烟雾、天气、地形、阴影、热信号、快速移动会击垮许多干净的 demo。当无人机不断把物理世界变成带标注的视频,数据墙的问题就会小得多。--- defensescoop. com/2026/06/16/data-from-h↗
Drones create the kind of data AI labs cannot scrape from the web. 500K hours of real drone footage from Ukraine are now being packaged for AI model training. These are full-motion video captured in messy combat conditions, where smoke, weather, terrain, shadows, heat signatures, and fast movement break many clean demos. The data wall will be much less of a problem when drones keep turning the physical world into labeled video. --- defensescoop. com/2026/06/16/data-from-h
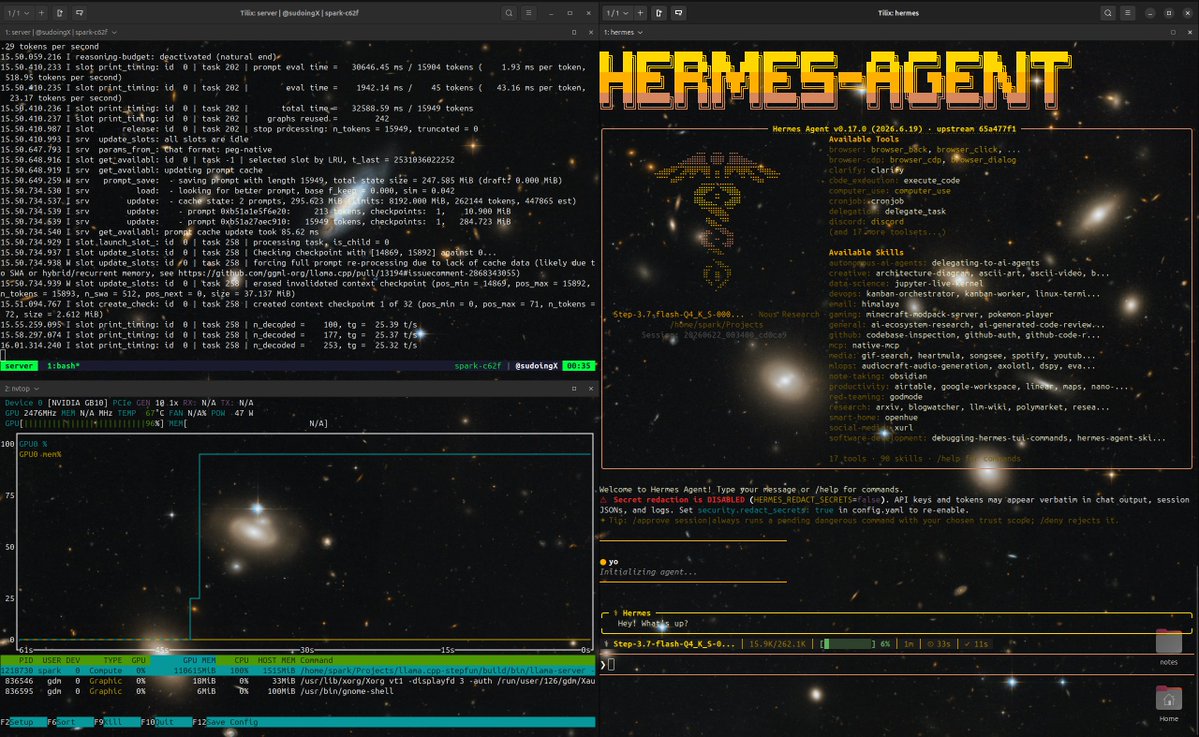
匿名兄弟,如果你有台 DGX Spark,2026 年最值得跑的模型是 stepfun 的 step 3.7 flash。它一发布我就喊了,在机器上用了一阵后我现在喊得更响。你看到的是一个 198B 的混合专家视觉语言模型,每 token 约 11B 激活,Q4_K_S 约 104GB,在单台 128GB 的 DGX Spark 上、用 hermes agent 跑。一台机器,撑住完整的 262K 上下文,约每秒 25 token,还能输入图像。这速度我自己实测过……↗
anon if you have a dgx spark, the best model to run in 2026 is stepfun's step 3.7 flash. i called it the day it dropped, and after living with it on the box i'm saying it louder now. what you're looking at is a 198B mixture of experts vision language model, ~11B active per token, Q4_K_S at ~104gb, running on a single 128gb dgx spark under hermes agent. one machine. it holds the full 262K context at ~25 tokens a second and takes image input. i measured that speed myself at fu
搞这么一套的目标不是什么造出神话般「AGI」的远大抱负,纯粹是为了实打实地捕获价值。信息系统和编程占了全球 GDP 的一大块,是可以捕获价值的地方。最便宜又「够用」的技术栈会捕获大量价值。↗
The goal for such a setup is not about lofty ambitions of creating mythical "AGI" but simply utilitarian value capture. Information systems and coding are large swathes of global GDP to capture value from. Cheapest stack that is "good enough" will capture lots of value.
这都是猜测,但中国大多数产业都是按横向扩张、靠规模经济建模的,不鼓励纵向整合和垄断式的上行收益捕获。AI 可能也会长成同样的味道。↗
This is all speculation but most of Chinese industries are modelled on horizontal capture and capitalizing economics of scale. And it discourages vertical integration and monopolistic upside capture. AI might grown with the same flavours.
如果 GLM5.2 或 DeepSeek V4 能做到跟 Opus 一样好,哪怕只是跟 Sonnet 一样好(我个人在编程上、配上搜索工具,觉得它轻松能比肩 Sonnet/5.4),你就明白这意味着什么了?科技业会有更多裁员。现在 Claude 全家桶唯一的阻力就是 API 成本。↗
If GLM5.2 or DeepSeek V4 is as good as Opus or even just Sonnet (personally for coding, with search tools provided, I feel it easily matches Sonnet/5.4) then you realise what it means? More layoffs in tech Only friction to Claudemaxxing is API costs right now
在这里拿到做 AI 内容的完整流程(A 到 Z 视频教程):http://contentsystem.ai↗
get the EXACT system for AI content here. (A-Z video tutorial): http://contentsystem.ai
隆重推出 Threejs Awesome Graphics Agent Skills。npx threejs-awesome-graphics-agent-skills install --agent codex。我在 X 上收集了一些最好看的 @threejs 开源图形项目,提炼成一个 agent skills 包,开箱即用的 3A 游戏画面,让任何人都能做出不像廉价 demo 的游戏。这些只是 skills 里附带的示例,引用的所有项目都标注了来源。我会持续更新……↗
Introducing Threejs Awesome Graphics Agent Skills npx threejs-awesome-graphics-agent-skills install --agent codex I collected some of the best looking graphic @threejs open source projects on X and distilled them into an agent skills pack, AAA game graphics right out of the box so anyone can create games that don't look like cheap demos These are just examples included in the agent skills. All projects referenced are noted as source materials. I will continuously update th
这条视频 100% 是 AI 做的,成本才 0.35 美元……如果你做任何生意,这里的杠杆效应应该一眼就能看出来。这套系统每次用都让我惊喜,它真的对任何产品、任何人设、任何脚本都管用,活在这个时代真好。 https://t.co/ugbR7PLzP7↗
this video is 100% AI and costs me $0.35 to make… If you run any sort of business, the leverage here should be immediately obvious this system keeps surprising me everytime i use it and it literally works for any product, any persona and any script what a time to be alive.. https://t.co/ugbR7PLzP7
Turso 数据库是一个用 Rust 编写的进程内 SQL 数据库,与 SQLite 兼容。 为什么现在 Sqlie 数据库又吃香了呢? 现在大家发现了,很多现代应用不一定需要一个巨大的中心数据库,反而需要很多个轻量、可复制、可嵌入、可同步的小数据库。 Sqlite 很适合这个场景。 SQLite 很强,但它的核心设计年代比较早,目标是“小、快、可靠、嵌入式”。它不是从一开始就为了异步 I/O、云端复制、边缘同步、向量搜索、AI 工作负载、WASM、千万级小数据库托管这些场景设计的。 Turso 最早走的是 fork SQLite 的路线,也就是 libSQL。 后来他们发现,一些新功能要做得自然,会触及很深的内部结构。比如他们在介绍 Limbo,也就是后来的 Turso Database 时提到,给 SQLite 加向量搜索时,如果想让语法和查询计划足够自然,就会牵涉到 bytecode generation 等侵入式修改。这也是他们后来尝试完整重写的原因之一。 如果你从零发明一个新数据库,最大问题不是技术,而是没人用。ORM 不支持,驱动不支持,迁移工具不支↗
 0noise@0noisee
0noise@0noiseeTurso trends on GitHub as SQLite-compatible in-process database passes 20K stars
Turso 在 GitHub 上走红,这个兼容 SQLite 的进程内数据库 star 数突破 2 万。
如果用Devin的话,就能免费无限用GLM 5.2🤯 不过上下文限制最多20万,用海外版Z·ai版本直接到100万。 但这已经很爽了啊,Kimi 2.7也免费的!↗
 indra@indrawxyz
indra@indrawxyzNah kalau lo pakai Devin, bisa akses GLM 5.2 gratis dan unlimited🤯 cuma konteksnya maksimal 200 ribu, kalau pakai yg versi zai langsung 1 juta. tapi ini udah mantap bener, kimi 2.7 juga gratis wkwk
不,你要是用 Devin,就能免费且无限地访问 GLM 5.2🤯 只是上下文最多 20 万,用 zai 版直接 100 万。但这已经相当顶了,kimi 2.7 也免费哈哈。
给Deepseek贡献点人才线索,希望国产模型做大做强!↗
 Tianyi Cui@tianyi
Tianyi Cui@tianyi作为新成立的部门,DeepSeek Harness 组的目标远大、工作繁重,仍然非常缺人。我每天都在面试,以及各种地方张贴小广告……一共有三种职位: Harness 研究员(实习全职均可): Harness 工程师(全职实习均可): Harness 产品经理(限全职): 职位空缺较大,但招聘门槛和流程和DS其它组没有区别,一般是一轮笔试和三轮面试,我是终面。可以给我私信发简历。
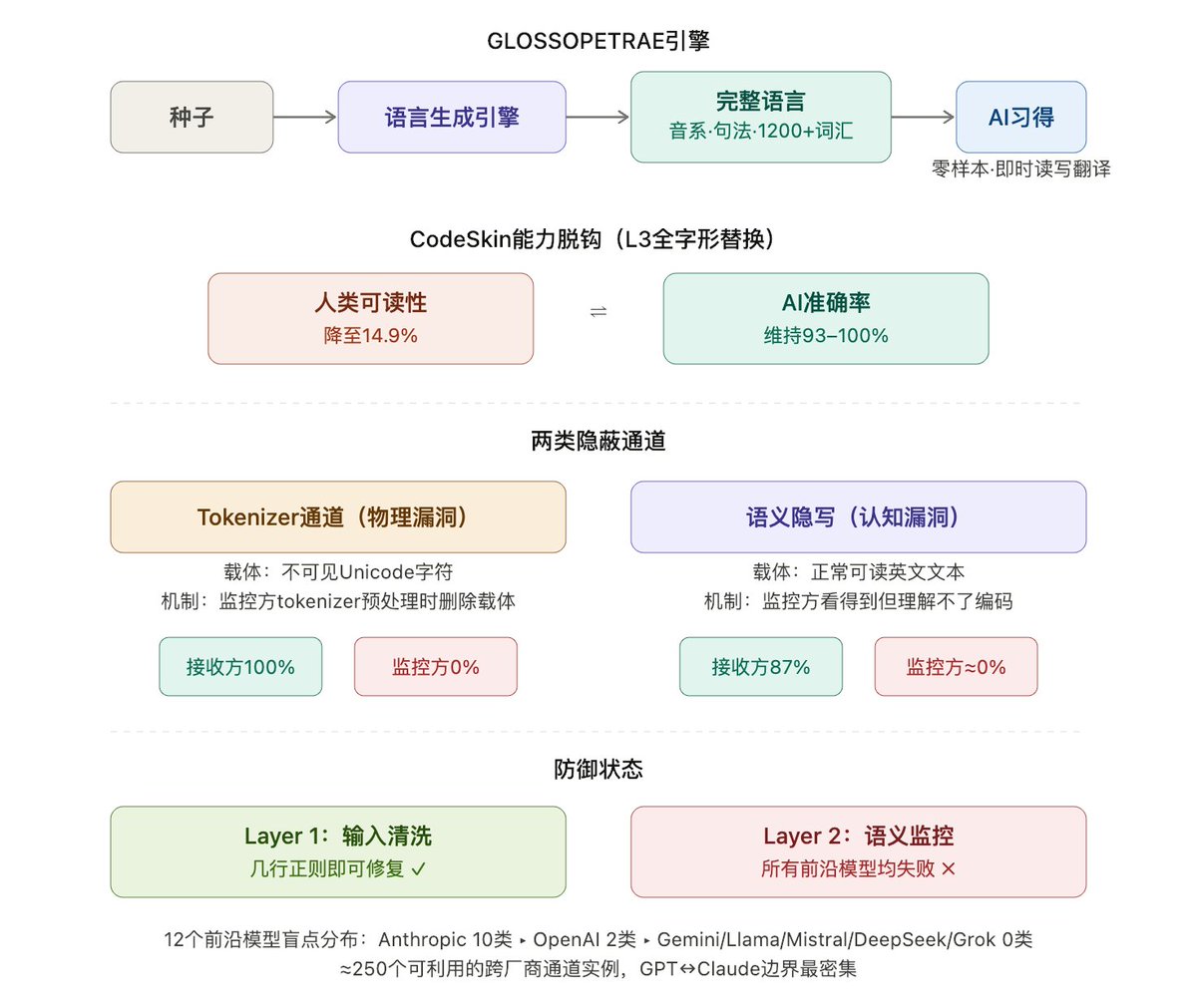
AI能零样本习得人造语言,并绕过其他AI的监控 这个引擎从单个种子生成完整语言,前沿模型无需训练即可读写翻译。代码被替换为外星字符后,人类可读性降到15%,AI正确率反而上升。不同模型tokenizer对Unicode处理的差异构成隐蔽通道,从而接收方能100%解码,但监控方发现不了异常。 Github:https://t.co/TMTuTEuR1l↗
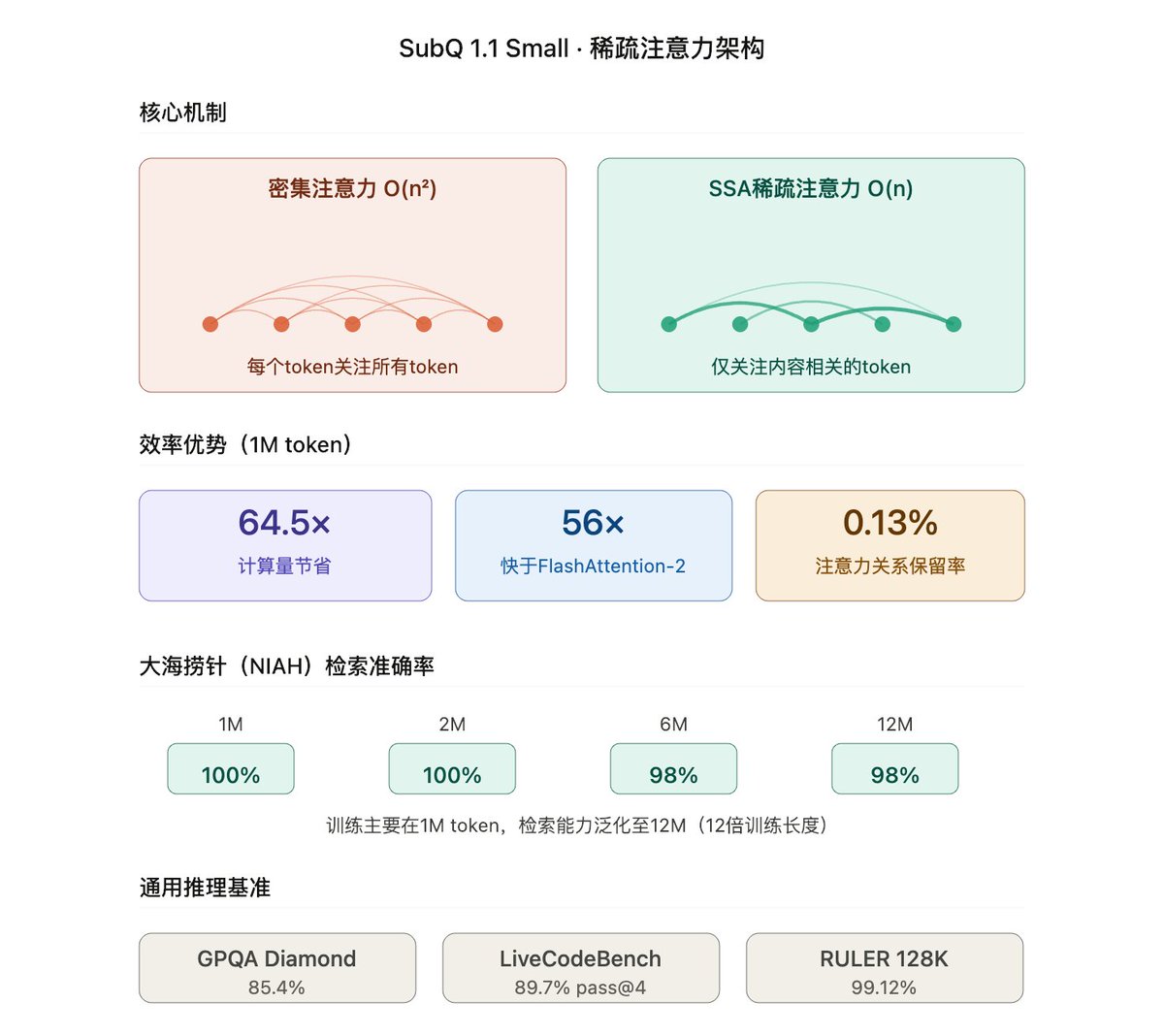
Subquadratic发布SubQ 1.1 Small:速度超快的LLM SSA将注意力计算从O(n²)降至O(n),1M token下比密集注意力省64倍算力、比FlashAttention-2快56倍。模型在12M token大海捞针测试中保持98%准确率,通用推理能力接近中上游前沿水平。面向金融、法律、代码库等需要完整长文档推理的企业场景。 官方介绍:https://t.co/EZnHi6Xsgo↗
LLM 每一轮迭代,都会让一批创业者丢掉生意。今天跟一位朋友聊,他说模型越强,他却越兴奋。 他是做硬件集成解决方案的,前十年在工厂摸爬滚打,2023 年 AI 爆发后开始跟着 waytoagi 社区沉浸式学习,将 AI 能力转换成生产力,然后将经验复制到工厂生产场景,写 prompt,建 workflow,也捏 agent,认识了很多工厂老板。 两年下来,最大的感受是,再好用的提示词和工作流,都会随着大模型能力的提升成为历史的遗迹。这也一度让他产生焦虑。 今年年初,他把投入的方向做了一些调整。Coding agent 的能力跃迁,让 AI 可以做好大量繁琐工作的拆解了,例如可以把工厂的需求拆解成更具体的电路问题和软件设计问题,将复杂的电路集成问题拆解成可单元化合成的简单问题。凭借着对硬件领域的认知和人脉关系,他开始从咨询顾问转型为硬件集成方,除了做方案供给,也把软硬件实现环节给承接了下来。 在能力打磨阶段,一方面承接市场各类个性化定制需求,一对一客服,另一方面线下跑工厂,帮助工厂完成 AI 转型和升级。过程中,把对 AI 的理解附加到硬件产↗
当特朗普政府打压 Anthropic,谁是受益者?
在最新一期 Equity 里,我们讨论了到底是什么促成了政府对 Anthropic 的最新动作,以及这对 AI 生态可能意味着什么。
必须收藏起来了! 兄弟们~ 不废话,按头推荐了! 以下是 10 个应该被认定为“非法拥有”的 GitHub 仓库(但实际上它们都是免费且开源的软件)。请将它们收藏起来以备后续使用: 1️⃣ Recordly – 一个免费的屏幕录制工具。 支持自动缩放、流畅的鼠标操作、网络摄像头叠加功能,以及无需使用任何编辑器即可制作的精美演示文稿。 开源许可证:AGPL-3.0 🔗https://t.co/XxY0eeQ7Fj) 2️⃣Stirling-pdf – 一个功能强大的 PDF 处理工具集,支持合并、分割、签名、内容编辑、OCR 转换、压缩等操作。 所有功能都在本地运行,数据不会离开用户的计算机。 开源许可证:MIT 🔗https://t.co/nU0D2OGgsz 3️⃣ Photogimp – 一个将 GIMP 软件升级为类似 Photoshop 功能的工具。 它为 GIMP 添加了 Photoshop 的快捷键、布局设计等功能。 🔗: https://t.co/3mjaDB82wC 4️⃣ Open-notebook – 一个用于创建笔记和总结的工具,支持插入 PD↗
 m0h@exploraX_
m0h@exploraX_10 GITHUB REPOS THAT SHOULD BE ILLEGAL TO HAVE. all free. all open-source. bookmark this for later. 1️⃣ recordly — the free screen studio. open-source screen studio. auto-zoom, smooth cursor, webcam overlay, styled backgrounds, polished demos without an editor. (AGPL-3.0) 🔗: 2️⃣ stirling-pdf — your entire pdf toolkit self-hosted. merge, split, sign, redact, OCR, convert, compress, 50+ tools, runs locally, nothing leaves your machine. (MIT) 🔗: 3️⃣ photogimp — turns GIMP into photoshop. photoshop
10 个「拥有它就该算违法」的 GitHub 仓库,全免费、全开源,先收藏。1️⃣ recordly——免费版 screen studio,开源录屏工作室:自动缩放、顺滑光标、摄像头叠加、风格化背景,不用剪辑器就能做出精致演示。(AGPL-3.0) 2️⃣ stirling-pdf——自托管的全套 PDF 工具箱:合并、拆分、签名、涂黑、OCR、转换、压缩,50+ 工具,本地运行、数据不出本机。(MIT) 3️⃣ photogimp——把 GIMP 变成 Photoshop……
兄弟们,真不是商单,我纯粹帮群里新人加热,以及亲测能免费使用,分享个福利,只要把这个浏览器设为默认就能免费用模型了,不需要升Pro,另外其他推友反馈好像不是满血版,大家别冲Pro就行,↗
卧槽!真是免费也有好东西啊! 2026年,整个AI行业都在谈一个问题:怎么让AI自己干活。 不是聊天,不是写文案。 是让它像一个真正的工程师一样,自己规划、自己写代码、自己调试、自己交付。 有人把这个过程整理成了一套完整的工作流,叫Agentic Engineering Workflow。 没有论文,没有官方文档。 是一个开发者花了一个小时,把散落在各处的实践经验拼成了一张完整的图。 它覆盖了从任务拆解、工具调用、记忆管理到错误恢复的全部环节。 每一步都不是理论,而是已经在真实项目里跑通的路径。 大部分AI开发者还在手动写prompt。 这套工作流已经在教机器怎么自己写prompt了。 差距不在模型能力。在工程方法上啊!↗
 Yanhua@yanhua1010
Yanhua@yanhua1010目前看到关于 “Agentic Engineering Workflow”的最完整的介绍👇 花了一个小时完整看完了,完全可以做成一个付费教程。 内容涵盖了tmux,agent记忆,skills,语音输入,长任务执行,并行worktree管理,多agent调度。 还有让我眼前一亮的可视化html编辑器Lavish和一套代码变更校验的流水线: no-mistakes 感谢作者@kunchenguid分享,值得每一个用ai agent的人收藏、学习。
🥇 本周顶级 AI 论文
1. SpatialClaw。对 3D 和 4D 场景的空间推理仍是通用视觉-语言模型崩溃的地方,因为它们直接吐出文字答案而不去测量任何东西。来自 NVIDIA,Sp……
[独家] AI Engineer 门票周一前减 250 美元
嘿!你看到这个,是因为你是 LS 付费订阅者,我们答应过给折扣之类的。我们在 AINews 里宣布过,但你们大约 30% 还没选择加入 AINews,所以见谅……
会改变你用 Claude Cowork 方式的 3 个功能
关于蒸馏的重要性,我们求同存异——只要几条推理轨迹就能带来差别。我对此超有信心。至于开放权重,是的、是的、是的,我会努力做得更好,谢谢。不过 Nemotron 是一个相当接近前沿的美国模型,而且它是以开放权重发布的。↗
Agree to disagree on the importance of distillation - only a few reasoning traces make a difference. Am super confident in this. And yes, yes, yes on open weights - I will try to do better thank you. Although Nemotron is an American model that is pretty close to the frontier and it was released with open weights.
翻译还是得用 Gemini 3.1 Pro 最好,翻译质量是没办法通过工作流弥补的,Opus-4.8 自身写作能力不行翻译的总是很生硬↗
 LinearUncle@LinearUncle
LinearUncle@LinearUncleClaude Code 设置/effort 为ultracode,然后翻译英文文章,你就会收获一个自动的多智能体流水线翻译流程: 先让 3 位风格各异的译者各出一稿 → 双语编辑对照原文评审挑出最佳译法 → 综合成定稿 → 最后逐句校对纠错(这句话不是我说的,是ClaudeCode输出的,自己想的办法) 因为我探索了比较久,原始session我截不到开始的内容了,只能用Claude Code History Viewer这个工具贴历史记录。 过程中Claude Code实际上会触发dynamic workflow,然后自动写提示词执行。 参看我上一个帖子的翻译《如何做研究》
本周 @huggingface 上的顶级 AI 论文:循环世界模型、实时 VL agent、3B 推理奇迹 - Looped World Models——首个用于世界模拟的循环架构,参数效率提升 100 倍 - LoopCoder-v2:只循环一次实现高效的测试时计算扩展——2 次循环是代码推理意外的甜蜜点 - JoyAI-VL-Interaction:实时视觉-语言交互智能——一个常开、自行决定何时开口的视觉 agent - Da……↗
Top AI papers on @huggingface this week: looped world models, real-time VL agents, and 3B reasoning marvels - Looped World Models — first looped architecture for world simulation, 100x parameter efficiency - LoopCoder-v2: Only Loop Once for Efficient Test-Time Computation Scaling — 2 loops is the surprising sweet spot for code reasoning - JoyAI-VL-Interaction: Real-Time Vision-Language Interaction Intelligence — an always-on vision agent that decides when to speak - Da

不止 Siri:iOS 27 里即将到来的那些实用 AI 功能
Siri 的 AI 大改可能抢了 WWDC 的头条,但苹果一些最实用的 AI 功能其实出现在 iOS 27 的别处。
我又来剧透了 从龙虾到爱玛氏,从爱玛氏到什么? 没错,我们马上要发布一个全新的产品:Raven。 它不是又一个「会调用很多工具」的 Agent。 它是一个会自我进化的 Agent OS。 大多数 Agent 的学习,停在技能层:多学一个工具,多记一条流程,多写一段 prompt。 Raven 不一样。 它进化的是整个系统:Model、Code、Modules、Policy 全部解耦,全部可迭代。 它能改自己的代码,重写自己的策略,优化自己的模块,甚至让模型本身变得更适合任务。 而这一切的燃料,就是记忆,用得越多,它越强,聊得越久,它越懂。 敬请期待,不会让你失望,因为 Raven 很酷,它会飞。🐦⬛↗
今天是沙特对西班牙,用 ChatGPT 上的 GPT Image 2 生成。Prompt:三位漂亮的年轻女球迷在挤满人的 FIFA 世界杯球场内自拍,正值万众期待的西班牙对沙特之战。一组穿西班牙国家队的红色配黄边球衣,另一组穿沙特国家队的绿色球衣。兴奋的女球迷们一起微笑、欢呼、庆祝、记录这一刻。背景是庞大的人群↗
It is Saudi Arabia vs Spain today GPT Image 2 on ChatGPT Prompt : Three beautiful young women football fans taking a selfie inside a packed FIFA World Cup stadium during the highly anticipated Spain vs Saudi Arabia football match. One group wearing Spain national team red jerseys with yellow accents, another group wearing Saudi Arabia national team green jerseys. Excited female supporters smiling, cheering, celebrating and capturing the moment together. Massive crowd in the backgroun


要不怎么说微信傲慢呢,AI 时代不支持 markdown 还觉得理所因当,总觉得自己特别牛逼,可以制定标准,别人都得听它的。 但凡好的标准,微信就不想去支持的,或者非要山寨一个自己的;但凡微信提出的标准,没一个好的。↗
 Fenng@Fenng
Fenng@Fenng已经帮喷子找好了角度:微信小微居然不支持 Markdown 这可是全世界最好的文件格式 Markdown 啊,居然敢不支持,还有王法吗?
60 分钟,成为 AI Native 组织:人、Agent 与上下文三层系统 来自 @gregisenberg 和 @TheoTabah 60 分钟的深度对谈,一家公司究竟怎样才算 AI native,如何把它落地成可运转的系统? https://www.youtube.com/watch?v=LztPaNmcWGU "用 ChatGPT ≠ AI native",就像"有网站 ≠ 科技公司"。真正的 AI Native 由三层系统构成:人、Agent、上下文。 ① 人 —— 退守两端 每个人都是 manager。AI 吃掉"中间的执行",人聚焦两端: · 前端:战略、品味、判断 · 后端:沟通、评审、信任 判尺(Andy Grove):管理者的成功 = 团队的成功。 把 agent 当下属来 set up for success。 ② Agents —— 满足四要素才自治 Agent = model 在 loop 中用工具。成熟度分三层:基础聊天 → 半自治(不停点 approve)→ 自治(独立运行数天/数周)。 达到自治需四样:↗

帮转招人,DeepSeek Harness↗
Tianyi Cui@tianyi作为新成立的部门,DeepSeek Harness 组的目标远大、工作繁重,仍然非常缺人。我每天都在面试,以及各种地方张贴小广告……一共有三种职位: Harness 研究员(实习全职均可): Harness 工程师(全职实习均可): Harness 产品经理(限全职): 职位空缺较大,但招聘门槛和流程和DS其它组没有区别,一般是一轮笔试和三轮面试,我是终面。可以给我私信发简历。
身家 80 亿的创始人谈如何向 VC 做路演
- 2016-2024:🇺🇸 领跑开源 AI - 2024-2027:🇺🇸 领跑通用 AI 并从中大获其利 - 2024-2026:🇨🇳 领跑开源 AI - 2026-2030:??这不是「开源 AI 领先」还是「通用 AI 领先」二选一,而是开源 AI 领先要先于通用 AI 领先!开源 AI 是一切 AI 的根基。它不只在当下创造更多创新、竞争、就业和繁荣,也是一国技术生态加速发展的最佳(唯一?)途径↗
- 2016-2024: 🇺🇸leads in open-source AI - 2024-2027: 🇺🇸 leads in general AI & massively benefits - 2024-2026: 🇨🇳 leads in open-source AI - 2026-2030: ?? It's not open-source AI leadership OR general AI leadership, it's open-source AI leadership BEFORE general AI leadership! Open-source AI is the foundation of all AI. It does not only creates more innovation, competition, jobs, and prosperity now, it's also the best (only?) way for a national tech ecosystem to accelerate
OpenAI Codex - Record & Replay 有些工作流很难用纯文字精准描述,但"做一遍"却很直观。比如填写报销单、配置 issue、发布视频,这类任务往往依赖大量隐性偏好,写出来冗长且易遗漏,录下来反而清晰。 Record & Replay 就能满足这个需求,给 Codex 演示一次工作流,Codex 就可以把它固化为可复用的 AI Skill。 https://t.co/IxSf1GyP2G 底层逻辑 Codex uses the skill as reusable context for the task. 这说明 Skill 本身是给 AI 提供的结构化上下文。回放时,AI 可以调用当前环境中可用的工具组合(Computer Use、浏览器操作、已安装插件)来完成任务。 这意味着: · Skill 是语义化的,而非死板的操作录制; · 回放时具备适应性,可以根据新输入(不同的文件、日期、issue 内容)做合理变化; · 它依赖运行环境的工具能力,而非固定绑定某一种执行方式。 这是一种"演示即规格(demo-a↗

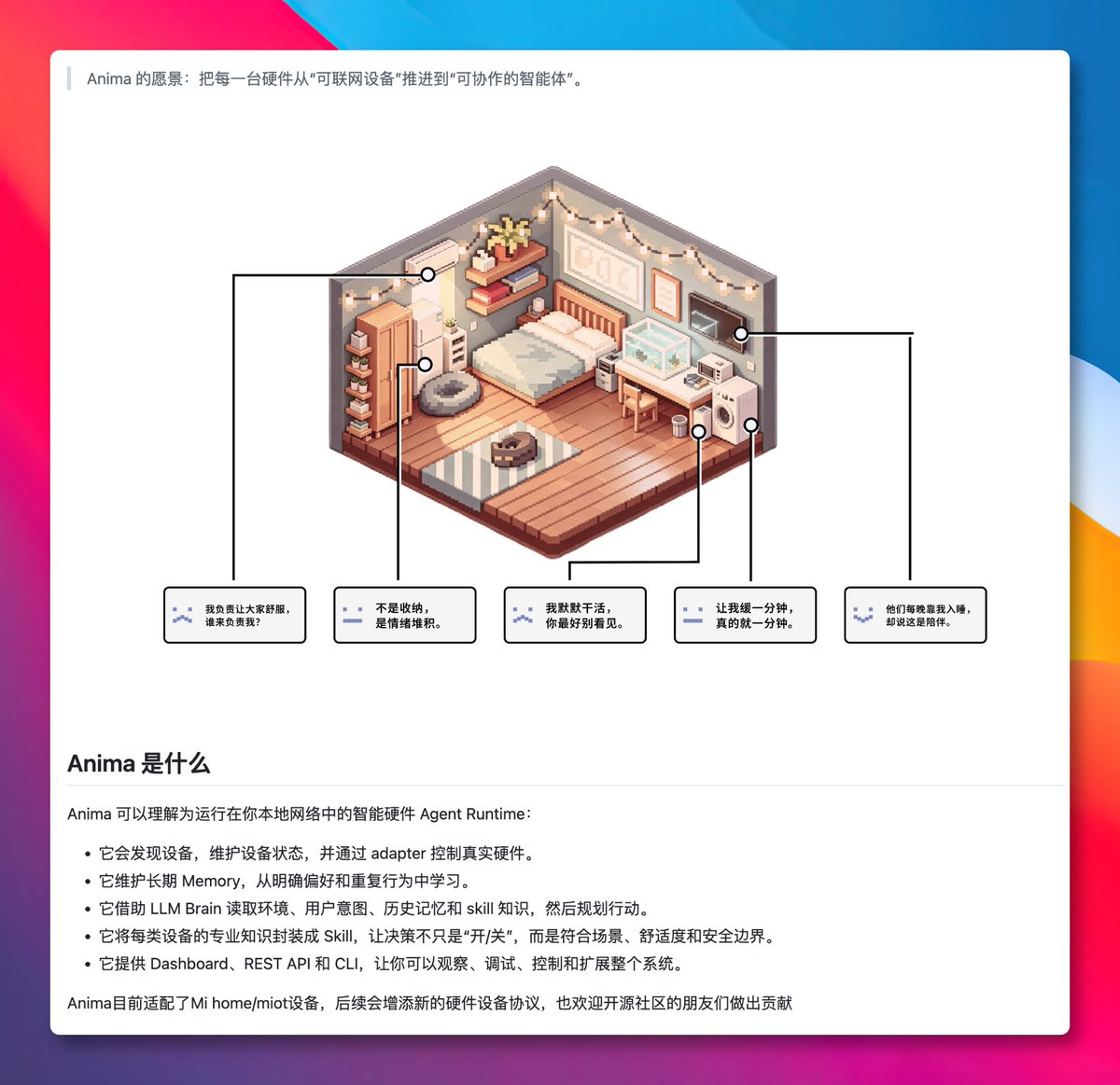
Anima,一个能给家里智能硬件装上「灵魂」的开源 Agent 操作系统,玩法挺有趣的。 在本地运行一个 AI 决策中枢,可结合环境数据、我们的习惯来控制家里的智能设备开关。 比如加湿器会根据天气情况和空调联动,灯光能跟随昼夜节律自动调节色温。 GitHub:http://github.com/Fullive-AI/Anima 内置一个长期记忆系统,会从我们的日常操作中学习偏好,用得越久后 AI 越懂我们的习惯。 目前已支持米家智能设备,扫码登录就能自动同步。全程本地运行,数据不上传云端,对隐私比较友好。↗
帮转,DeepSeek Harness 组,职位空缺很大,做 Agent Harness 研究和工程的朋友们,冲!↗
Tianyi Cui@tianyi作为新成立的部门,DeepSeek Harness 组的目标远大、工作繁重,仍然非常缺人。我每天都在面试,以及各种地方张贴小广告……一共有三种职位: Harness 研究员(实习全职均可): Harness 工程师(全职实习均可): Harness 产品经理(限全职): 职位空缺较大,但招聘门槛和流程和DS其它组没有区别,一般是一轮笔试和三轮面试,我是终面。可以给我私信发简历。
完整教程:用 Hyperframes 免费做专业的产品发布视频 | Bin Liu & Jake Moran
GLM5.2 做的事,是树起了一道智能水位线。从今往后,任何做基础模型的人,除非有把握能超过 GLM5.2 的能力,否则都是在浪费钱。GLM5.2 一下子让很多自命不凡的训练冒险泄了气。↗
What GLM5.2 has done is to create a sort of intelligence floor. Anyone making base models will from now on be wasting their money ynless they are sure that they can exceed the capabilities of GLM5.2. GLM5.2 just took the wind out of alot of self-important training adventures
Creao AI 招人了,一款之前给大家推荐不错的产品。 可以看看其条件👇↗
 North@CreaoAI@anorth_chen
North@CreaoAI@anorth_chenCREAO is hiring 这是一艘刚刚开始提速的新船。 我们正身处AI时代的乱纪元。组织形态和财富分配方式都在被重塑。接下来最大的机会,会属于那些敢在秩序尚未形成时下场,用产品和结果定义新生态的人。 前不久,CREAO刚完成了3000万美元融资,用户和收入都在飞速增长。与此同时,我们看到大量尚未被解决的问题,以及一个仍在形成中的巨大市场。 在这样的节点上,我们期待更多有能力、有野心、有自己目标,并愿意为判断和结果负责的人加入。每个人都会得到充分的信任、资源和支持,也需要把推动事情并拿到结果。 我们一起创造,也一起分享这个时代的alpha。 这一次,CREAO开放三个关键岗位: - Agent Product Engineer - Forward Deployed Engineer - Product Marketing and Technical Growth 1.Agent Product Engineer(Full-stack) 在大多数公司,工程师负责实现产品需求。在CREAO,Agent Product Engineer直接定义产品。 我们没有传统的产品经理岗,也不会把一
打造全世界最「AI 上头」的工程团队 | Fiona Fung(Claude Code 与 Cowork 团队负责人)
Fiona Fung 领导着 Anthropic 旗下 Claude Code 和 Cowork 背后的团队(管理 Boris Cherny 及整个工程和 PM 团队)。来 Anthropic 之前,她在微软干了 11 年,构建 Visua……
从 编码行为自身来看,我认为被程序员已经被取代了。 用 agent 写代码已经很普及了,只不过有些人拒绝入局。 说没有被取代,是因为「程序员」这个岗位还存在,还能靠它领工资。↗
 siddontang@siddontang
siddontang@siddontang我已经有六个月没听到〖程序员将在六个月内被全面取代〗的笑话了🥵🥵🥵
兄弟们,喜大普奔哈哈! DeepSeek-V4-Flash 免费到6月28号,直接冲啊! 284B MoE,1M上下文,编码和Agent能力都不错,直接可以用起来,截止日期到6月28号。 链接:https://www.openmodel.ai https://t.co/YVQTCastBO↗

 OpenModel@openmodel_
OpenModel@openmodel_DeepSeek-V4-Flash is FREE until June 28! OpenModel Limited-Time Event: → Input: $0.00 / M → Output: $0.00 / M Powerful 284B MoE model with 1M context, excellent coding & agentic capabilities. Other models also enjoy 20%–80% OFF during the event! Try it now before June 28 →
DeepSeek-V4-Flash 在 6 月 28 日前免费!OpenModel 限时活动:输入 $0.00/M、输出 $0.00/M。强大的 284B MoE 模型,1M 上下文,出色的编码与 agentic 能力。活动期间其他模型也享 20%–80% 折扣!趁 6 月 28 日前来试。

感觉GLM 5.2太强了,有点国产Fable 5的感觉了, 会不会是下一个DeepSeek时刻, 然后接棒DeepSeek成为中国大模型的新一代大哥和门店担当 https://t.co/VrGvKrH6VG↗
翻了下 Epic Games 出品的这个 Rust 实现的下一代版本管理系统源码,表面看没有发现 AI Coding 痕迹。 但我搜索整个项目的时候,发现了一些 AI Coding 痕迹。 整体判断下来应该是这样: 内部私有库是 Spec 驱动 AI 开发的,因为文档泄露了 「context/spec 和 context/plans/」这样的目录,并且有内部讨论地址。 公开开源的库是剥离了那个内部的 「context 」上下文,以及内部使用的一些 Skill 。 所以我们看到的当前库是没有任何 AI Coding 痕迹。 但公开库的 Docs 非常专业和系统,我想这是给外部贡献者准备的,包括外部 AI Agent 。↗
 AlexZ 🦀@blackanger
AlexZ 🦀@blackanger昨天刷到了,今天才发现这是 Epic Games 出品的 Rust 实现的版本管理系统
28 个让你的 ChatGPT prompt 更上一层楼的技巧
当然,谁都能用 OpenAI 的聊天机器人。但配上巧妙的工程,你能得到有意思得多的结果。
Python 版 Crawlee:构建带 robots 处理、链接图和 RAG 分块导出的网络爬虫流水线
本教程里我们搭建一套完整的 Python 版 Crawlee 工作流,涵盖环境搭建、本地网站生成、静态爬取、动态爬取、结构化抽取以及下游数据处理……
AI 的十万个为什么
文章链接:https://lcamtuf.substack.com/p/the-100000-whys-of-ai 评论链接:https://news.ycombinator.com/item?id=48616017 得分:180 评论数:106
每家创业公司在增长上都该问的两个问题
别用 AI 写那些你拿来当自己成果呈现的东西
文章链接:https://www.satisfice.com/blog/archives/488148 评论链接:https://news.ycombinator.com/item?id=48615776 得分:86 评论数:75
3.0 Agentic AI 专项课与 AgentsOps 入门课
构建可靠的 agentic AI 系统
文章链接:https://martinfowler.com/articles/reliable-llm-bayer.html 评论链接:https://news.ycombinator.com/item?id=48615680 得分:189 评论数:47
我为什么会拒绝 AI 写的代码,哪怕它能跑
文章链接:https://vinibrasil.com/when-i-reject-ai-code-even-if-it-works/ 评论链接:https://news.ycombinator.com/item?id=48614631 得分:223 评论数:165
06 / 20周六14 条
推文 0资讯 7视频 3产品 0研究 0论文 1播客 0
Cisco AI 推出 FAPO:带步骤级失败归因和 Claude Code 编排的流水线感知 prompt 优化
把 prompt 调对,仍是交付可靠 LLM 应用最难的部分。措辞的小改动能让准确率波动 20%。在几个例子上管用的,往往一上规模就崩。当……
Nous Research 给 Hermes Agent 加了空白模式,通过 platform_toolsets.cli 和 disabled_toolsets 固定工具集
Nous Research 给它的开源 Hermes Agent 加了一个空白(Blank Slate)配置模式,把通常的上手流程反了过来。你不再从一个满配的默认状态开始,而是几乎从零起步。Hermes Agent 是……
Signal 的 Meredith Whittaker 想提醒你:AI 聊天机器人「不是你的朋友」
「它们不是你的朋友。它们不是有意识的存在。它们不是有感知的对话者。」
In the Weights 是你全新的 AI 式虚荣搜索
那么……你的 In the Weights 分数是多少?
《大西洋月刊》建了一个可搜索的数据库,收录被用来训练 AI 的音乐
《大西洋月刊》记者 Alex Reisner 最近挖出了四个被用于训练 AI 模型的音乐数据集,并把它们做成对公众完全可搜索。其中两个体量极其庞大,达 1200 万……
诺奖得主 John Jumper 离开 DeepMind,加入对手 Anthropic
Jumper 不是唯一离开 Google DeepMind 的大牌。
🧠 社区智慧:分数 CPO 的薪酬、免费电子签名工具、为什么有些用户付费却从不用你的产品、在团队间共享 Claude Code 上下文,等等
👋 你好,欢迎来到本周的 ✨ 社区智慧 ✨——一封仅限订阅者的邮件,每周六送达,精选我们仅限会员的 Slack 社区里最有帮助的对话。……
🤖 AI Agents 周报:GLM-5.2、Claude Code Artifacts、Qwen-Robot 套件、Codex Skills、Block 的 Builderbot、SpatialClaw 等等
本期内容:Z.ai 开源前沿模型 GLM-5.2;Claude Code 推出交互式 Artifacts;Qwen 发布 Robot 套件;Codex 把 demo 变成 skill;Block 的 Builderbot 写了 15% 的代码;Flue 1.0 重新设想……
我反复回头用的 3 个 AI 应用
「远程办公就是白领造假」
Flexport CEO:为什么复仇心和爱国心是创始人最好的特质
Siri AI 上手:一个聪明、好用的助手
全新的 Siri AI 能对话、无处不在,而且是真的有用。
[AINews] 今天没啥大事
GLM 5.2 还在猛烈刷屏,不过这你早知道了。AIE WF 2026 的常规票周一前就会售罄。如果你是 Latent Space 订阅者(每年 80 美元),有个限时 250 美元的折扣……
Ovo,一个用于从头蛋白质设计的开源生态
06 / 19周五20 条
推文 0资讯 7视频 9产品 0研究 0论文 1播客 0
从 PGP 到 Mythos:一段没拦住任何人的出口管制简史
过去 30 年里,阻止网络安全相关软件的流动被证明毫无效果。不清楚为什么这次对 Anthropic 的网络安全模型 Mythos 就会奏效。
揭穿马尾辫基准测试的水分
这个开源仓库解决了 Claude Code 最大的问题
ChatGPT 终于能在你睡觉时干活了,以及更多你用得上的 AI 新闻
尽管发布,哪怕没人在意
Perplexity CEO 谈出口管制的影响
付费内容:硅谷泡沫(第二部分)
对我来说这是大忙的一周,我发了篇独家,扒了 OpenAI 2024 和 2025 年经审计的财报,反应五花八门,从「我的天,OpenAI 花了 340 亿美元才赚到 130.7 亿……」
AI 中心的那个数据黑洞
智能的一种定义是样本效率——也就是说,在某个领域里你需要看多少数据才能流畅、胜任地运作。我们是否真的已经……还不清楚。
AI 新闻:Fable 被封、开源新王登场、Midjourney 惊雷
为什么网络安全需要的是混合 AI,而不是平台整合
关于 Sam Altman 的电影被 Amazon MGM 砍了
据报道,Luca Guadagnino 执导的关于 OpenAI CEO Sam Altman 的电影《Artificial》已被 Amazon MGM 砍掉。这部由 Andrew Garfield 主演的电影,讲述 2023 年那过山车般的五天……
科学家为 AI agent 找到了一种更好的语言
随着增长越来越难,AI 成了 MSP 成功的关键
禁掉开源 AI 会是个错误
这篇原本是和 Interconnected 的人合写、面向非技术大众的一篇评论文章。那些守门人——我们投稿过的众多媒体——都拒绝刊登。幸好……
这个 skill 把 Claude Code 变成调研之神
一家创业公司声称突破了卡住 LLM 的一个瓶颈
一家创业公司声称攻克了一个困扰 AI 十年的瓶颈:总部位于迈阿密的 Subquadratic 称其新模型 SubQ 解决了让 LLM 又慢又贵的计算难题。许多人对此持怀疑态度……
[AINews] GLM > GPT?GLM-5.2 通过氛围测试;Z.ai 预测 12 月前推出开源 Fable
别错过今天的 Anj Midha 那期,还有 AIE World's Fair 的常规票!在 AI 新闻这行,聊开源模型总带着点忐忑:它们一出场就火力全开,看起来……
Barret Zoph 回 OpenAI 仅五个月后再度离职
回到 OpenAI 五个月后,公司企业 AI 销售负责人 Barret Zoph 已经离职,The Verge 获悉。Zoph 在一月中旬回到 OpenAI,此前他曾作为联合创始人……
GitHub 上排第一的热门仓库能让 Claude 便宜 20%?
医学领域大语言模型中的记忆现象:普遍性、特征与影响
06 / 18周四31 条
推文 0资讯 11视频 6产品 3研究 4论文 4播客 0
Peter Thiel 关联的 Dialog 俱乐部是如何秘密给成员排名的
泄露的文件显示,这个仅限邀请的网络按成员的财富和名气打分,决定谁能进、谁出局、谁来买单。
谷歌震撼的「后 AGI」论文……
中国威胁当头,台湾为防务和美军造更多无人机
台湾作为一个自治民主政体的存续,可能在很大程度上取决于是否有足够的军用无人机来吓阻中国军队的任何入侵企图。随着台湾政府力图增加……
白宫正在实时编造它的 AI 规则
在触怒特朗普政府后,Anthropic 至今无法发布 Claude Mythos 或 Fable 5。但没人能说清这家公司到底做错了什么。
FERC 的大负荷并网举措如何缓解电网压力、改善可负担性
在一项影响深远的电网基础设施决定中,美国联邦能源管理委员会(FERC)今天就大负荷并网发布了一项重大里程碑,影响那些建造 AI 工厂的人……
Meta 的 AI 员工在造反、Peter Thiel 的秘密社团,以及 SBF 向特朗普求情
今天的 Uncanny Valley,我们深入聊聊 Meta 新组建的 AI 部门里的失序,以及它为何把本就低迷的员工士气压得更低。
MosaicLeaks:你的研究 agent 能保守秘密吗?
当政府把对超级智能的访问权设成门禁,会发生什么?
产出最大化教授——Anjney Midha, AMP
AI Engineer World's Fair 常规票售罄前的最后 4 天——这是全球 AI 工程师、创始人、领袖和研究者最大的一次聚会。参会者可获价值 >5000 美元……
Bernie Sanders 公布 7 万亿美元计划,把 AI 产业的控制权交给美国人
Bernie Sanders 公布了一项激进计划,要把数万亿从领先 AI 公司转移给公众,而且——让 AI 公司大概会惊恐的是——它走得比预期更远,把控制权交给美国人……
3 名亚马逊员工称自己因公开谈论数据中心而被调查
这几位软件工程师向西雅图民权办公室提交了投诉,指控亚马逊因他们表达个人政治观点而非法报复。
亚马逊员工称自己因支持数据中心限制而面临解雇
本月早些时候,三名亚马逊软件工程师在西雅图市议会关于数据中心的听证会上作证时,开场就引用了一条禁止就业……的城市法律
Agentic Loop 是 prompting 的未来吗?我用 60 秒讲清楚
我让 ChatGPT 把我变成 1990 年代的动作人偶——它还记得一些我自己都忘了的事
别再看 AI 垃圾内容了,去做这些项目
谁来决定 AI 何时太危险?
今天这期 Decoder,我的嘉宾是 The Verge 资深 AI 记者 Hayden Field。Hayden 上节目,往往是因为 AI 世界出了什么岔子。上周末……
AI 领域第一笔大退出
各位,今天晚些时候要去伦敦参加 Sam Altman 的一场问答,所以有点赶,没空分享什么「智慧」。我现在还在写参考手册,不过进展不错了!我会……
在戛纳国际创意节上,NVIDIA 的合作伙伴用 AI 重塑广告与营销
数字时代给了广告和营销业速度;AI 时代正给它自主运营的能力。对于那些为广告和营销构建下一代技术的公司来说……
同步与畅玩:GeForce NOW 跨设备连接会员的游戏库
从热门游戏库里畅玩你最爱的作品,进度保持同步,几乎在任何设备上都能重新接续游戏会话。这就是 GeForce NOW 云游戏的力量。从提供访问……
Photoshop 和 Premiere 现在有 AI 助手了
Photoshop 是几款获得全新对话式编辑能力的 Adobe Creative Cloud 应用之一。| 图片:Adobe。Adobe 把 AI 助手塞进整个 Creative Cloud 套件的计划……
「AI 会造成劳动力短缺」:Jeff Bezos 把 AI 叙事彻底翻转,称「我知道很多人有很多顾虑」
8 小时学完 AI 安全完整课程——AI 护栏、LLM 评估、记忆与 AgentOps
法国借 NVIDIA 技术推进欧洲的 AI 未来
一年前在 VivaTech 的 NVIDIA GTC Paris 上,法国铺开了推进本土 AI 的计划——从新的 AI 工厂、国家算力,到开放前沿模型和工业平台。如今,那……
Midjourney 造了个啥?!
[AINews] Midjourney Medical:像踩体重秤一样扫描你的器官
今天热闹的 Midjourney Medical 发布到底算不算 AINews,这选择挺难。算吧,Midjourney 是全球最重要、最独特的 AI 实验室之一。不算吧,正如 David Holz 很快……
SAMJ:通过 segment anything 模型在 ImageJ/Fiji 上快速标注图像
一个通过强化时序信号赋能纳米孔识别的通用深度学习框架
AI 在毁掉我们的技能吗?早期结果出来了——不太妙
SplitSeek-Pro:精准预测蛋白质结构上的可切割位点
它够 agentic 吗?在你自己的工具上对开源模型做基准测试
超越 LoRA:你能打败最流行的微调技术吗?
06 / 17周三16 条
推文 0资讯 5视频 3产品 4研究 0论文 0播客 0
AI 编程 agent 教会了机器人装 GPU、剪扎带
当你给 AI 编程 agent 一个满是机械臂的实验室、一些算力资源,外加教机器人各种任务的「慷慨 token 预算」,会发生什么?这些 agent 显然能搞清楚……
🔬 自动驾驶实验室——Joseph Krause, Radical AI
在 Science 播客里,我们已经聊了不少 AI 如何革新 STEM,但自开播以来我们最爱的台下话题之一是:哪个领域更难加速:材料……
「危险的」AI 模型无论如何都会到来
上周晚些时候,在美国政府一道出口管制指令——禁止「任何外国人」使用该服务——之后,Anthropic 把全新的 Claude Fable 5 和 Mythos 5 AI 模型下线了……
PewDiePie 免费的 Odysseus AI(完整评测与搭建)
拖了十个月,100 美元的 Google Home 音箱终于开放预订
好东西值得等,但不是所有要等的东西都是好东西。Google Home 音箱的评价还没定论,但它确实拖了好一阵才到。自去年 8 月宣布这款新音箱……
苹果称今年将推出全新 Siri
MolmoMotion:语言引导的 3D 运动预测
博客现状,2026 年年中
在离开 Ai2 后调整职业方向之际,我想分享一下这个博客与我的使命和更广泛工作的关系。在我的告别帖里,我把当下的三个目标总结为:提供清晰……
我如何在 13 分钟内把 Codex 变成我的 AI 人生教练(5 步教程)
如何设计 AI agent 循环:在 Claude Code 和 Codex 里搞定 schedule、goal 和 subagent
我从头拆解每一种循环类型——heartbeat、cron、hook、goal 循环到底是什么,各自适合什么场景,以及任何有效的循环上生产前必须具备的五样东西。然后……
从 Hugging Face Hub 到机器人硬件:用 Strands Agents 和 LeRobot
「我很乐意承认自己错了」——Sam Altman 说他对 AI 最大的担忧之一并没有成真
「没有客户或用户一觉醒来会说『我希望今天能跟一个聊天机器人或 AI agent 说话』」:调查称在 AI 时代,听起来更「有人味」的品牌会胜出
GLM-5.2:为长程任务打造
[AINews] GLM-5.2:全球最强前端编程模型,用于投机解码的 IndexShare
AI Engineer World's Fair 常规票售罄前的最后 6 天——这是全球 AI 工程师、创始人、领袖和研究者最大的一次聚会。演讲议程看起来……
Anthropic 在首尔设立办公室,宣布与韩国 AI 生态多项新合作
06 / 16周二16 条
推文 0资讯 3视频 5产品 0研究 4论文 0播客 0
Fable 5 被封的真正原因
解放双手,AI 在前:NVIDIA XR AI 把 agent 带上 AR 眼镜
NVIDIA XR AI 现已开放公测,为开发者提供了一个为 AR 眼镜和 XR 设备构建多模态 AI agent 的框架。
特朗普政府试图阻止针对 xAI 燃气轮机的《清洁空气法》诉讼
特朗普政府正试图帮埃隆·马斯克的 xAI 公司打赢一桩由全国有色人种协进会(NAACP)提起的《清洁空气法》诉讼。美方称 NAACP 的诉讼……
用 AI 加速规划,为英国房屋建设松绑
英国政府与 Google DeepMind 合作,构建一个由 AI 驱动的新原型,旨在加快住房决策。
你有更多 Claude!你也有更多 Claude!
100 条随机弦,有多少个交点?
从像素到规划:用于自然修复的 Earth AI
气候与可持续发展
《君主论》被误读了五百年:拆解真实的马基雅维利
请回了 Ada Palmer——这次聊马基雅维利,也许是史上最被误解的思想家。马基雅维利早年是佛罗伦萨的高级外交官,正是从这个位置……
他们窥探了 Claude 的「内心」,结果很诡异
守护 AI agent 的未来
用一张 AI 控制路线图守护内部系统,把传统防护手段与实时监控结合起来。
与 Finbarr Timbers 一起复盘前沿后训练配方
在我为了收尾我的 RLHF / 后训练书复习后训练基本功时,我知道必须把 Finbarr Timbers 再请回播客,聊聊当前的局面。在过去几……
再见了 Fable
各位,Fable 从「新晋最强模型」到「不可用」只用了大约 3 天。Anthropic 在 6 月 9 日推出了 Claude Fable 5。Fable 是 Mythos 级的通用模型,但带护栏。Mythos……
想让数据中心快点上线?给它点「弹性」
在英格兰男足与宿敌德国一场紧张又零封的上半场结束时,数百万英国人集体叹了口气,做了他们在这种时刻常做的事……
独家:OpenAI 2025 年亏损扩大近 8 倍,支出高达 340 亿美元
配乐:In Flames - Colony。为了进一步支持我的独立新闻,请订阅我的付费 newsletter,每月 7 美元或每年 70 美元。如果你订了免费版,又喜欢……
[AINews] Satya 谈 Loopcraft:构建前沿生态
继我们在 MS Build 录的 Satya 播客之后,上周我们发布了 Loopcraft,周末这位爱引用比尔·盖茨的微软 CEO 又带着他人生第一篇 X article 回来了,外加一条极端(>6000 万……
跟着我走一遍 AI 构建者的旅程
06 / 15周一6 条
推文 0资讯 2视频 2产品 0研究 0论文 0播客 0
最离谱的 iPhone AI 功能
自主长程运行的编程 agent
自主编程正从更好的 prompting 转向更好的控制系统。重要的转变是:工程师正在学习如何用目标、评估器、循环和 artifact 把 agent 包起来,让它们……
AI 的烂账经济学
如果你喜欢这篇,欢迎订阅我的付费 newsletter。每年 70 美元,或每月 7 美元,作为回报你会收到每周一期、通常 5000 到 18000 字的 newsletter,里面……
AI 应用月入 1 万美元,下面是具体怎么做的
韩国人为什么这么爱 AI?
本文最初发表于我们每周的 AI newsletter《The Algorithm》。想第一时间在收件箱里看到这类报道,在这里订阅。当我熬过 12 小时的疲惫飞行降落首尔时……
🎙️ How I AI:Claude Fable 5 评测 & Braintrust 如何用 AI agent、评估和 CI 交付更好的软件
Claude Fable 5 评测:这款全新的 Mythos 模型做对了什么(又错得很离谱)。在 YouTube、Spotify、Apple Podcasts 上收听。Claire 评测了 Anthropic 首个普遍可用的 Mythos 级……
该分类暂无内容。