Perplexity CEO 阿拉文德·斯里尼瓦斯:美光会比 Meta 更值钱,出口管制反而帮了中国

这条视频还没有中文字幕
该条目暂未提供中文字幕。本系统只对人工挑选的内容生成翻译。
挑中后 → 取 YouTube 字幕 → 精翻 → 此处切换为双语字幕
Perplexity CEO 阿拉文德·斯里尼瓦斯:美光会比 Meta 更值钱,出口管制反而帮了中国
这期 20VC 录在伦敦,面对面,火药味从第一句就出来了。阿拉文德·斯里尼瓦斯(Aravind Srinivas)是 Perplexity 的联合创始人兼 CEO——一家三年里靠四百个人做到约两百亿美元估值、月搜索量过十亿、四千五百万用户的公司。主持人哈里·斯特宾斯给他的开场白是「他从不坐墙头观望」("he doesn't do defense, he doesn't do comfortable"),并直接把这期的几个论断摊在桌面上:阿拉文德断言美光(Micron)会比 Meta 更值钱,断言对数据中心的抵制只会越来越凶,断言今天最大的瓶颈是电力短缺,还断言 Perplexity 改 Google 比谷歌任何一个产品经理改得都多。
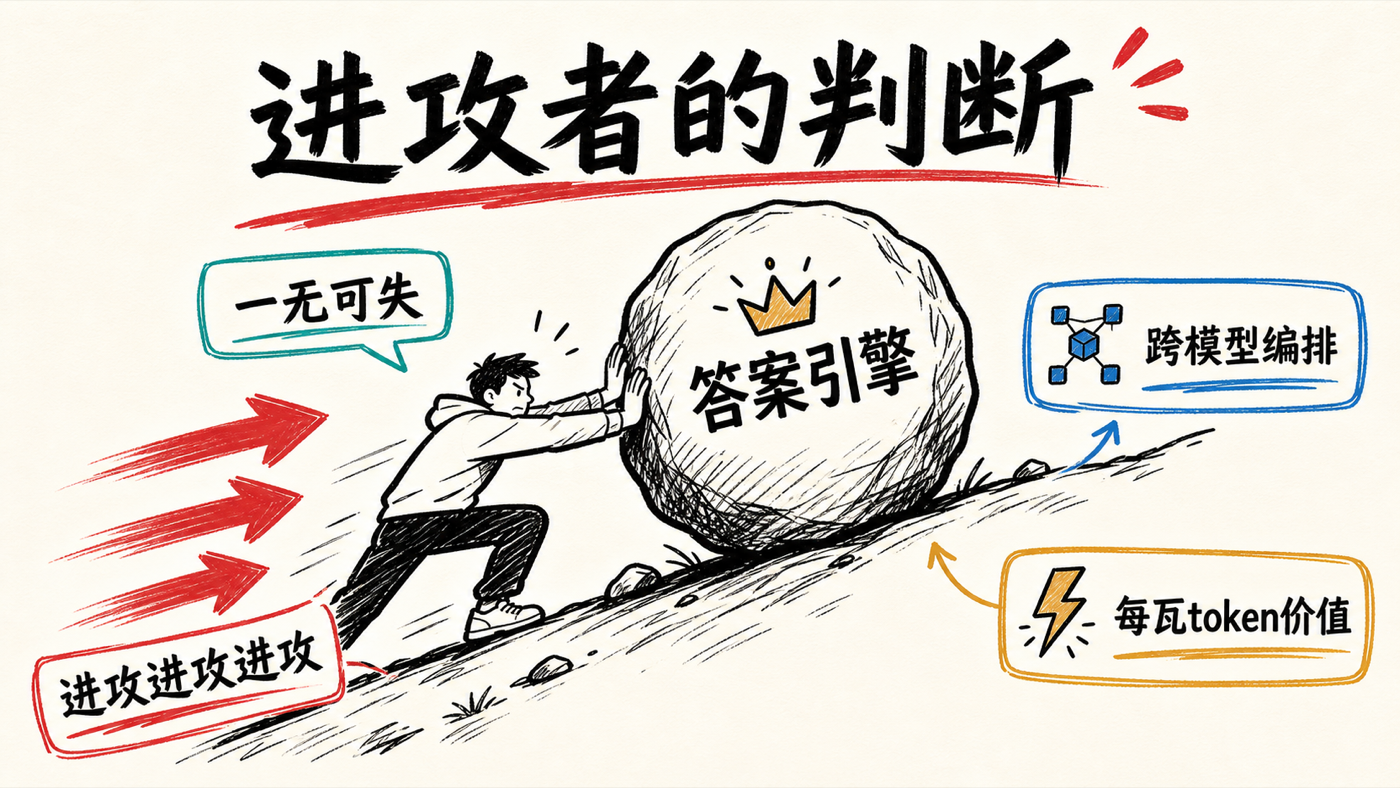
阿拉文德自己给这一切定了底色。斯特宾斯问他:你更被「怕输」驱动,还是被「赢的快感」驱动?他答赢的快感,理由是——「我一无可失,我从一无所有里来」("I have nothing to lose. I came from nothing")。他说自己在印度是财务上的中下层,那种「中下层」还不是英美意义上的中下层;全家当年的成功标准就是「进谷歌当工程师」。所以他认定,任何时候当他发现自己在「避免失败」,那就是在防守,而防守是最蠢的事。他的座右铭是三个词:进攻,进攻,进攻("attack, attack, attack")。整场访谈里所有反共识的判断,都得放回这个进攻者的心态里读才说得通。
要点速览
一、「答案引擎」只是钓饵,钱在前沿(the frontier is where the money is)。 阿拉文德称 Perplexity 做出了世界上第一个答案引擎,但他主动把这块「资产」贬值——按他的判断,搜索已被商品化、不赚钱,今天真正付费的是深度研究报告和能替你干活的智能体(agent)。
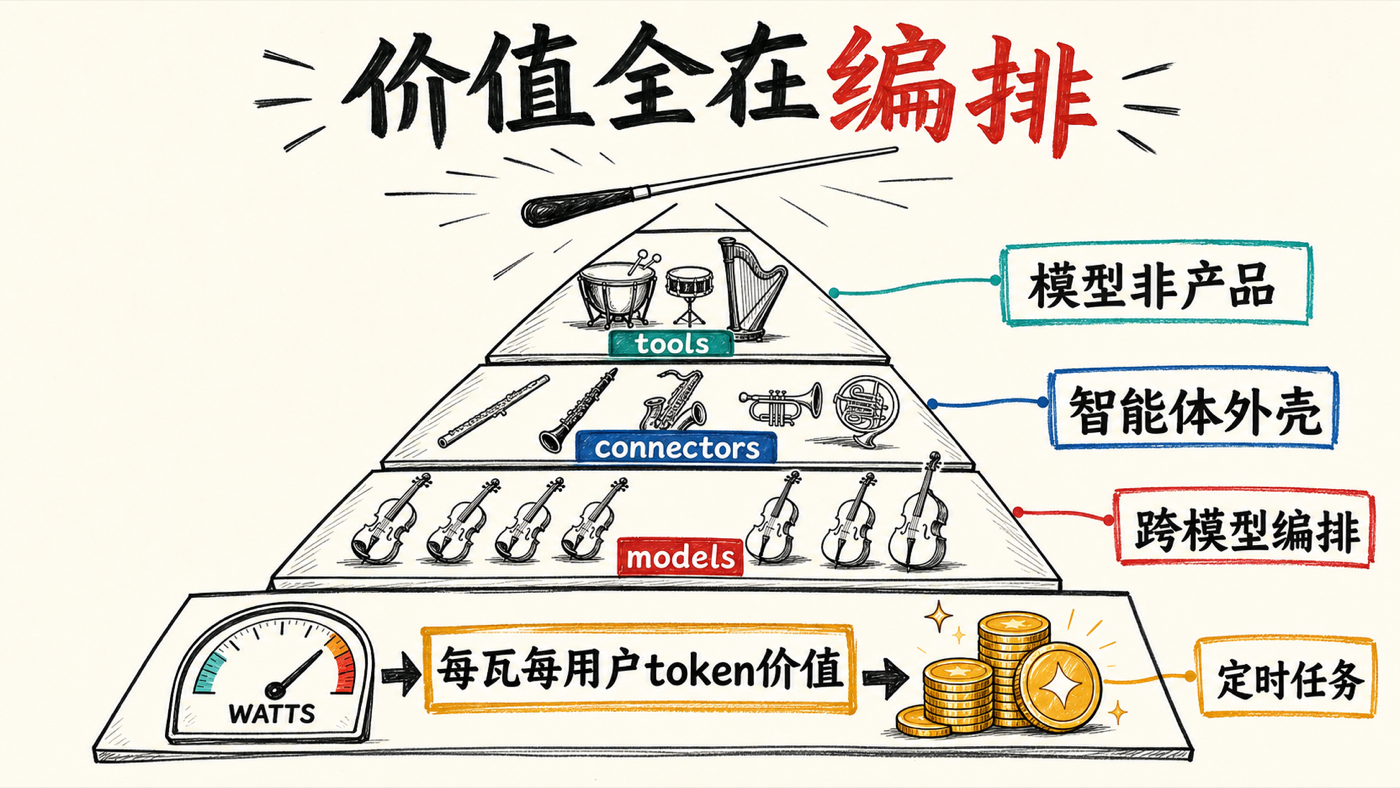
二、模型不再是产品(the model is no longer the product)。 他借用格雷格·布罗克曼(Greg Brockman)这句话立论:单纯转卖模型 token 没有生意,价值在于把模型套进一套「智能体外壳」(agent harness)——也就是编排。Perplexity 的差异化是不只在工具间编排,还跨模型编排。
三、整个 AI 里唯一最重要的指标,按其判断是「每瓦每用户的 token 价值」(token value per watt per user)。 谁能用最少的电产出最有价值的输出 token,谁就有定价权——这是他全部判断的换算底座。
四、最大的瓶颈不是芯片,是电力。 这是嘉宾判断。他进一步称当下约百分之四十的数据中心因公众阻力建不起来(这个「四十/一百」的数字由斯特宾斯先抛出、阿拉文德附和),而阻力的真实根源不是耗水耗电,是对失业和贫富差距的恐惧借环保之名发泄。
五、美光未来六到十二个月市值可能超过 Meta。 这是阿拉文德的预测,无法独立验证。逻辑是「谁是瓶颈谁定价」——高带宽内存(HBM)现在是瓶颈,所以供应商美光会被重新定价。
六、出口管制短期帮的是美国,长期可能把中国逼成更可怕的对手。 注意:这不是视频标题暗示的「单纯帮了中国」。阿拉文德的完整论断带转折——短期看,开源与前沿之间那约十二个月的差距「唯一的原因就是出口管制」,它确实奏效;但正因为被卡死,中国被迫把整条技术栈垂直整合进自研芯片和制程,反而可能炼出一个绕开英伟达栈、内存效率更高的体系。他给「下一个 DeepSeek 时刻」出现的概率打了百分之二十到三十。
七、没人能松懈(no one can relax)。 这是贯穿全场的复调——他用它说 OpenAI、说 Anthropic,也说自己。哪怕是模型厂商,只要六个月拿不出新能力就完蛋。

【1】「我一无可失」——为什么他从不防守,连嘴上都要进攻
斯特宾斯一上来就用了个怪问题:怕输还是想赢?阿拉文德选后者,并把根扎到出身上。他说自己当年在印度读本科,用实验室里别人拿来打游戏的显卡训练神经网络,纯属好玩,路就这么一步步走到今天。「我的人生已经超出任何想象的离谱程度了」——所以一旦他发现自己在防守,他就提醒自己这是最蠢的事,不如全力以赴,永远在进攻。
但斯特宾斯追问得很准:那你今天哪里还不够进攻?阿拉文德承认早年他亲自在社交媒体上很大声地喊「Perplexity 对决谷歌」,有些人因此不喜欢他;今天他对产品和对手的措辞克制多了。可他坚持这不是「成熟了」或「话术变温和了」,而是——那套话已经说腻了,「人们已经听够我说这个了」,他需要新的东西。他甚至说这个对立框架本身已经不相关了。
也正是在这里,他抛出全场最自利、也最值得拆的一句自述:「你可以说是我、或者说是 Perplexity 这家公司,把 Google.com 改得比谷歌任何一个产品经理这辈子改过的都多。」 让他论证,他说:谷歌内部从来没人想发一个答案引擎,没人愿意去动那个一年给他们赚两千五百亿美元的界面;可你现在看谷歌的 AI 模式(AI mode),「它看起来跟 Perplexity 一模一样」——字体、引用、行内文字的加粗方式、行内超链接、推荐的追问,整个体验就是照着 Perplexity 长的,「只是还没我们做得好」。
斯特宾斯问:他们学你、抄你,对你是好是坏?阿拉文德说两面都有。他说自己 2024 年底就知道这事一定会发生,从没被打个措手不及;他唯一惊讶的是谷歌的质量到现在还是不行。但他「真心高兴」谷歌被逼成了它本该成为的样子。然后他把话锋转向自己真正的赌注:前沿已经不在「回答问题」了,而在「真的替你去把事干了」。人们订阅他们的 pro 和 max 产品,不是为了传统意义上的得到答案,是为了要复杂的研究报告、要能替自己跑腿的智能体。
他顺势把这条逻辑捅向所有人,包括 Anthropic:在 AI 里没人能舒舒服服坐着以为自己稳了,「如果 Anthropic 以为 Claude Code 已经是胜利了,六到十二个月后它们连影子都不剩」。这是这个行业「令人不适的事实」——没人能松懈。

【2】聊天界面赚不了广告的钱——他为什么对 OpenAI 的广告生意看空
斯特宾斯按住一个点不放:OpenAI 在消费者搜索上是主导者吗?阿拉文德说是。那不就值钱吗?阿拉文德反手就是一刀:消费者搜索没钱,因为已经被商品化了,它永远只是个钓饵(lead gen)。真正的钱在前沿——所以 OpenAI 全力扑 Codex,Anthropic 扑 Claude Code,Perplexity 扑它的 computer 产品,Meta 想推每月两百美元的订阅,谷歌这个品类还没产品但一定会杀进来。
斯特宾斯不服:总不能钱就只在写代码这一件事上吧?阿拉文德说重点根本不是代码。在非广告的订阅或按量付费收入里,钱就在「无论当下前沿是什么」那个位置上,而今天的前沿就是替你出去把事办了。
然后他用一段很扎实的推演说明,为什么聊天界面接不住广告。他先报账:谷歌头号广告主是亚马逊,第二是 Booking.com,第三第四大概是 Expedia;Booking.com 一年在谷歌上花大约一百六十亿美元这种量级。接着他问斯特宾斯:你订酒店机票,是在 ChatGPT 上订还是在谷歌上订?答案是谷歌。为什么?因为你想「探索」,你想看到一排选项。阿拉文德接得很顺:当决策是主观的、靠感觉(vibes based)的,你要的是探索界面而不是一个客观的答案引擎。 直接面向消费者的服装、时尚那类预算,钱都进了 Meta 和 Instagram,因为你在那儿是漫无目的地刷。
他还补了第二层:广告会从根上腐蚀人们对答案产品的信任。你问哪款蛋白粉最好,产品突然塞一句「顺便这几款也不错你可以看看」——这就伤了平台的信任。他说在消息应用和邮件里塞广告历来没成过,微信里成了是因为「他们没有别的办法给整个体系融资」,整个经济和用户行为被围着「游戏化」优化过,美国不是这么运转的。所以他对聊天界面里跑广告看空,「我很乐意被证明是错的,但我看空」。
【3】「模型不再是产品」——价值全在编排,差异化在跨模型
这是全场的理论脊梁。斯特宾斯先泼冷水:我越听「钱在前沿」越怀疑,因为我们严重高估了前沿模型对干基础活儿有多重要。阿拉文德立刻澄清术语:前沿不等于前沿模型,前沿是「你此刻用 AI 能拿到的最好结果」。然后他搬出格雷格·布罗克曼那句「模型不再是产品」当论据,并点出其中的反讽——布罗克曼作为一家前沿实验室的领导者,本该有一切动机去说「模型就是产品」(谷歌的人就老在推特上这么讲),可他偏偏说反话,所以这话更可信。
他给「智能体外壳」下了具体定义:拿一个模型,配上一套规则,规定这个智能体循环(agent loop)怎么跑,它能调用哪些技能、子智能体、连接器和工具。没有这套外壳,你就没法把模型里那点内在智能转化成有价值的输出 token。「如果你只是直接转卖从模型里吐出来的 token,你根本没有生意,因为模型会被商品化。」 哪怕你自己就是造模型的,光转卖 token 也没生意;只有当你懂得把模型接上有价值的上下文、用一套很好的外壳编排、连上对的工具和连接器、再以一个统一系统交付给人,你才有生意。
Perplexity 的差异化,他说,是不只跨工具和文件编排,还跨模型编排——「这是 Anthropic 和 OpenAI 没法宣称的,因为你在 Claude Code 的外壳里找不到 GPT-5,在 Codex 的外壳里找不到 Claude Opus,它们在互相竞争;而 Perplexity computer 里这两个模型都有。」这样他就能压低、或者说提高每瓦每用户的 token 价值。他把这条逻辑钉死成一句定理:「AI 里唯一最重要的指标,就是每瓦每用户的 token 价值。」 因为说到底定价的是电(瓦特),而电这东西除了政府没人补贴得起;谁用最少的电产出最有价值的输出 token,谁就有最强的定价权和最大的价值。
斯特宾斯顺着问:那如果模型变成一种「可随时切入切出」的公用事业,OpenAI 和 Anthropic 还值什么?阿拉文德给了对所有创始人都该「反学习」的一课:别再想着造一个能拿到十亿用户的东西。 在 AI 产品层,无论你造不造模型,重点都不是用户规模——现在是一小撮重度用户在推动整个 token 经济。他举例:有工程师因为在 Claude Code 里设的智能体循环方式太蠢,一个月让亚马逊花掉了大约五亿美元;但也有 Meta 这类公司里真正的工程师,一年在编码工具上每人花掉一千万美元。Perplexity computer 里有个用户一个月花一万多美元,「不是在浪费钱,他的生意就靠跑在这些外壳里的智能体循环在运转」。
他点出重度用户和普通用户最大的分水岭:你是把 AI 当一次性任务用,还是当持续运行的定时任务(cron job)用。 一次性的就是丢个深度研究任务过去等结果;而真正拉开差距的是让 AI 持续监控、按事件触发、跑常驻工作流——每来一封邮件就自动分诊,每出现一次延迟尖峰就去定位是代码库哪部分引起的、做根因分析、再找到对的工程师。前沿就在这儿。所以这些产品不会被一亿人用,但它们产生的收入会高过谷歌或 Meta 的广告收入——「一定会发生」。
【4】token 花费会涨还是会跌——「你永远愿意为前沿付费」
斯特宾斯抓住一个硬数据顶他:马克·贝尼奥夫(Marc Benioff,Salesforce CEO)说他们一年在 Anthropic 上花三亿美元,折算下来约等于 Salesforce 开发者薪资的百分之三点八。那二十四个月后,开发者薪资里会有多大比例花在 token 上?这直接决定 OpenAI 和 Anthropic 值多少——停在百分之三点八,它们成不了五万亿美元的公司;要是像有人预测的一年内涨到百分之百,它们就是十万亿美元的公司。
阿拉文德没接这个二选一。他说成本会降,所以这个比例很难讲。斯特宾斯当场反驳:我们从聊天转到智能体时都以为成本会降,结果涨了。阿拉文德的回答分两层。
第一层,「你永远愿意为前沿付费」。 他打了个比方:给你一百万美元,你是雇五个二十万美元的中等工程师,还是雇一个杰夫·迪恩(Jeff Dean)级别的人付他一百万?答案是后者。所以你会为前沿付费——但「什么算前沿」一直在变。
第二层是关键的反直觉点。他做了个思想实验:十二个月后假如出现一个跟 Opus 一样好的开源模型,便宜十倍,配上对的外壳和所有连接器,你的开发者工作流照样跑通,那你今天这些活儿的 token 花费当然会降。但前沿会挪到一组你今天还想象不到的新事情上——他的预测是「完全自主的软件工程师」,而不是像今天这样把 Claude Code、Codex 当工具用。
他把这条线拉得更远:未来的前沿会是 AI 去设计芯片、设计药物、造机器人、治癌症——这些应用没有一千万用户,只有少数几家公司在做,但效果会触及大量人类生命。他说你能从前沿实验室的动作看出这个方向,比如 Anthropic 买了个湿实验室(wet lab)——可能为人才,也可能为跑湿实验的基础设施,想象一下把那些 token 不是喂给 GitHub 数据,而是喂进中段训练(mid training)。
斯特宾斯抛了个近乎哲学的问题:前沿问题有没有渐近线(asymptote)?你一路追下去,追到癌症、追到气候变化,这跑步机有没有头?阿拉文德说没有数学论证表明 AGI/ASI 能创造的经济价值有上限,并引埃隆·马斯克的说法:在后 AGI 经济里钱失去一切意义,因为你会生产出过剩的能量和劳动,而经济根本上就锚在能量和劳动上。他还引大卫·多伊奇(David Deutsch)那句——人类是唯一能对已经熟悉的东西仍保持好奇的物种;你盯着一个芒果,知道它的味道形状季节,但你仍能问出一个从没问过的问题,别的动物做不到。
【5】真正的瓶颈是电——以及他对「美光>Meta」的赌注
到了基础设施,斯特宾斯先把那句「AI 基础设施泡沫论」骂作「又蠢又荒唐」,再问:今天数据中心到底有没有供给问题?阿拉文德给出本场最站得住的判断:最大的问题其实在电力。
他拆解什么叫数据中心:不是从戴尔或超微买一堆芯片就完事,你得拿地或租地,得买涡轮机自己发电、或对接电网供应商,还得解决散热,还得拿一堆许可证——这些都慢得多,有大量前置时间(lead time)。他顺手讲了代际:今天在用的模型是 Hopper 代训出来的,Blackwell 代的第一个模型已经让人发怵;明年 Vera Rubin(英伟达 Blackwell 之后的下一代架构)满产,跑在它上面的模型会更强。所以总有一个物理建设时间在卡住前沿能力,这正是这一层有价值的原因——谁会把 GPU、网络、电力、散热和上面的软件层整合好、转化成前沿输出 token,这种垂直整合就值钱。市场因此给基础设施公司的市盈率比 Meta 还高。
斯特宾斯把 Meta 单拎出来:Meta 也大建基础设施,却被当软件公司估值;它的资本开支对应的是广告精准度提升,大概换来百分之六到八的收入增长,「我懂前者,但 Meta 这笔资本开支说不通」。阿拉文德替 Meta 辩了几句(他们不傻,正在推一堆订阅产品,也许会搞个出租服务器的 Meta 云),然后甩出本场最大的预测:
「美光,作为 HBM 的供应商,未来六到十二个月市值可能超过 Meta。」 他报的数字是美光已经在一万亿左右,Meta 在一万三到一万四千亿。(这些数字均为嘉宾原话,视频录于 2026 年 6 月,超出可独立核验的窗口,详见注。)斯特宾斯顶他:内存早就是巨大瓶颈,价格涨了五倍,大家都说美光已经被充分定价了,凭什么还没到顶?阿拉文德的回答很干脆:「因为它还是瓶颈。谁是瓶颈谁定价。」
他把这条「瓶颈即定价权」的逻辑推到 CPU 上:AMD 表现好,因为 CPU 又成了瓶颈——智能体循环、智能体外壳全跑在 CPU 上。token 由前沿模型在 GPU 上产出,但 Claude 写个脚本去下五百个文件、嚼数据、转换、画图、再挂到网站上让你分享,这些「计算」全在 CPU 上跑。「智能体比人类更会用 CPU。」 于是英特尔和 AMD 成了受益者。谁将来是瓶颈谁就赢,而现在基础设施就是瓶颈,因为需求很大、供给不够。
斯特宾斯继续掘:CoreWeave、Nebius 这类「新云」(neocloud)是可持续的几百亿美元公司,还是只在解一个短期供给问题?阿拉文德说能可持续,但有前提,也讲了门道:你得会从自然资源丰富、建数据中心又便宜又快、服务又可靠的地方拿电;有人甚至在电力层创新、自己发电来压低毛利。他点了一个关键区分:光当个 GPU 机架出租方、按小时租给别人,没多少价值;你得像 AWS 那样在上面叠一层软件编排,才能拿到软件利润——它叫 Amazon Web Services,不叫 Amazon Servers。 这正是 Nebius 这类公司往 AI 推理(inference)业务走的原因。
他随后给「百亿美元推理公司能不能独立存在」算了笔账,逻辑很硬:要做一家千亿美元公司,假设十亿美元收入、百亿美元收入对应三到四成毛利、不错的净利和现金流——一家能把 AI 托管推理、服务器产能、数据中心建设三件事在运营上都做扎实的公司,十亿美元收入并非天方夜谭。但他指出这些公司「掌握不了自己的命运」:它们活得好不好,取决于开源模型是否持续够强(若开源和前沿的差距拉到十五到十八个月以上,纯租产能给 OpenAI 和 Anthropic 的生意就崩了),以及市场会不会走向只剩两三家主导厂商的「整合」——他援引 Nebius 的罗曼(联合创始人)的话,整合是这类公司最大的威胁。
至于「模型选择/路由」业务能不能撑起千亿美元公司,阿拉文德说大概不能。他对 OpenRouter 的拆解很犀利:它叫 OpenRouter,但它的商业价值其实不在「路由」——它不是在跨模型路由(决定这条 prompt 该走 GPT 还是 Claude),而是在同一个模型的不同接入端点(endpoint)之间路由。你为什么不用自己的 API key 直连,而要走它?最简单的理由是模型故障回退(model fallbacks):你的限额可能不够,或者 OpenAI 服务器报错保证不了响应时间。OpenRouter 用手里的钱提前一年买好产能、锁定多家供应商(Bedrock、Azure 或 OpenAI 自己)的多个端点的限额——它在解的是基础设施问题,即「可靠的 token 供给」,而不是「帮你省钱」。 它的商业模式是靠保证大额供给从模型厂商拿折扣,但仍按 API 标价收用户,赚那个差价。还有一层:很多中国开源模型,你可能不想让自己的 API token 流到中国,又没精力去甄别一堆推理供应商,就把这事甩给 OpenRouter——所以这一层有价值,但不是高毛利生意。

【6】出口管制——短期帮了美国,长期可能把中国炼成更可怕的对手
这是全场最容易被标题带偏的一段,必须按阿拉文德的完整论证读,而不是按那个被压缩成 clickbait 的标题读。
斯特宾斯问:三年后会出现一个我们今天还没在谈的新瓶颈吗?阿拉文德说电力会一直是瓶颈,除非数据中心的建法发生剧变。他还判断对数据中心的抵制会越来越大,因为人们错误地以为数据中心耗水耗电(两者都不实,萨提亚·纳德拉甚至说过这些公司效率高到「一罐水」的程度)。那阻力到底从哪来?斯特宾斯猜是「它是失业的象征」,阿拉文德附和并展开:阻力是各种焦虑借不同管道发泄——有时借对贫富差距的仇恨、想加税,有时借对环境和气候的担忧,有时借「电网涨价、内存涨价害我手机笔记本变贵」的怨气,但底层的共同情绪是「对 AI 一种相当糟糕的观感」。这时斯特宾斯抛出那个「四十/一百」的数字(百分之四十的数据中心因公众阻力没建成),阿拉文德接了过去——所以这个数字是斯特宾斯先提、阿拉文德认同的,不是阿拉文德原创的。
然后他把视线转向中国,给出本段真正的论断——带转折的两段式,而不是「出口管制帮了中国」这么简单。
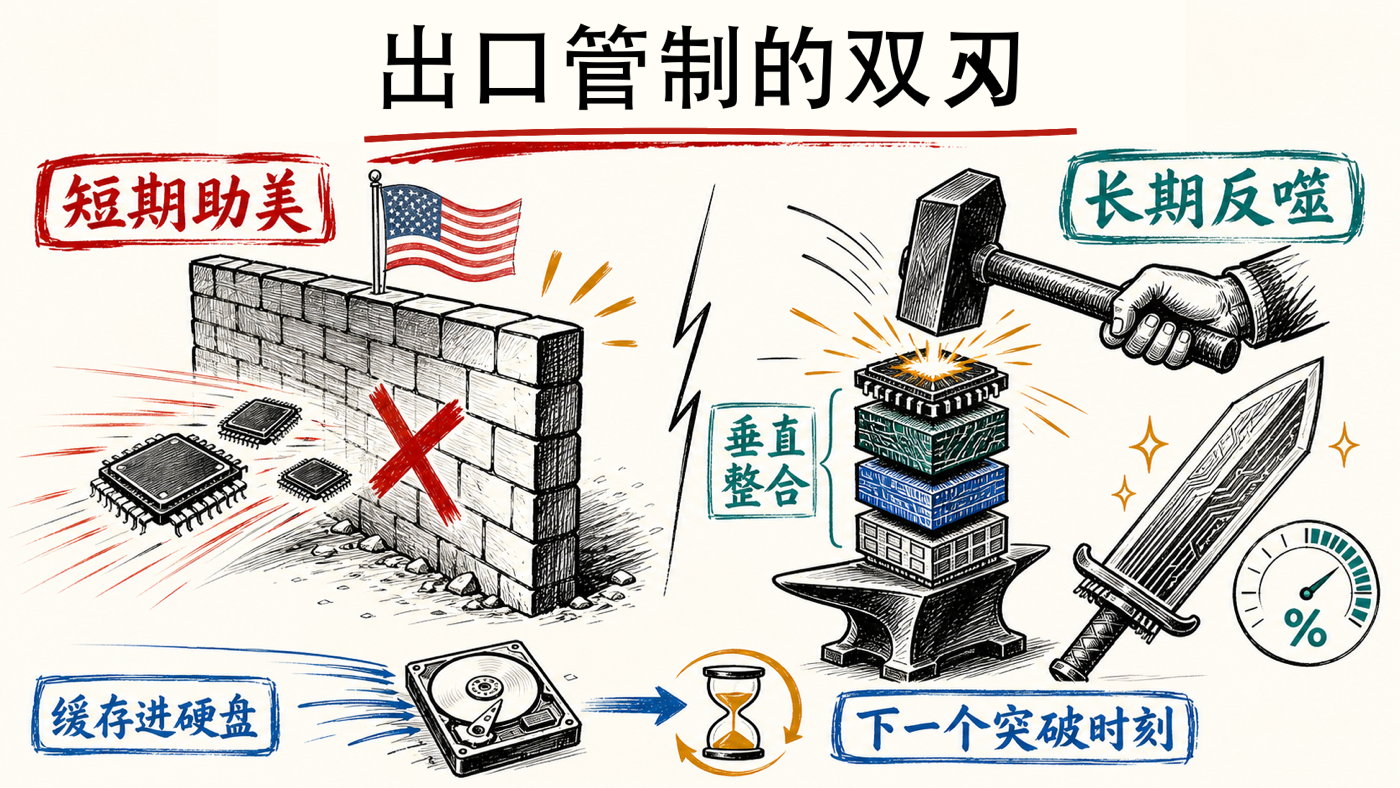
斯特宾斯直接问:出口管制到底帮了我们还是害了我们?阿拉文德的回答(建议把这句当本段的锚)是——短期看它在帮美国。 「按我的判断,开源和前沿之间之所以还有约十二个月的差距,唯一的原因就是出口管制;它确实奏效了,Anthropic 这类公司也游说得很凶。」
但紧接着是反噬的另一半:正因为被卡,「你可能正在把中国炼成一个远更强悍的竞争者」。 DeepSeek 不是在英伟达栈上造的,是在华为栈上造的;因为 GPU 和 HBM 都被管制,它们的架构变得极度内存高效——在 KV 缓存上做创新,做到小得能直接塞进 SSD,推理时根本不需要高带宽内存;因为用不上 3D NAND,它们的存储架构也完全不同。这不只是模型架构的不同(它们在注意力层、在训练算法上都做了创新,让训练不吃太多互联带宽),而是整条栈——芯片、制程、晶圆厂——都在围着自家硬件垂直整合,「这是和美国押的完全不同的一注」。
阿拉文德给这个反噬出现的概率打了分:「下一个 DeepSeek 时刻」——一个用截然不同的垂直整合架构、效率高得多、能跑在你 MacBook 或 Windows PC 上的本地模型——出现的概率大概是百分之二十到三十。 如果它出现,那些大建产能的人会发现自己「过度建设」了,会慌。斯特宾斯问我们是不是仍严重低估中国,阿拉文德说是——因为 AI 不只是数字的,也是物理的,要建晶圆厂、机器人、芯片、把能源驾驭好再封进本地设备,「在这些方面中国比美国优势大得多」。
关于美国怎么保竞争力,他给的处方很务实:更认真地对待物理基础设施并持续投钱,别再「围着数据中心散播假新闻」说它们污染、抢水;要用人们听得懂的语言把真相讲清楚、别制造恐慌——别动不动喊「百分之九十的工作要没了、你们都要被我们的模型搞惨了、告诉你们这些是我们的道德义务」,这种话既赢不了,又和「抱怨数据中心建不快」自相矛盾。他还顺手批了 Anthropic 的达里奥·阿莫迪(Dario Amodei)那套「工作全要没、一片末日」的市场叙事是帮了倒忙,并指出他们自己的口径都前后矛盾(最近又说「没有证据表明 AI 正在抢工作」)。在芯片自主上他给了一串数字:台积电(TSMC)在亚利桑那建美国晶圆厂,承诺投约一千五百亿美元、已投四百到六百亿;美国政府持有英特尔百分之十,英伟达和软银各持百分之五;埃隆在建「terafab」——「人们已经意识到建晶圆厂的重要性了」。(这些金额均为嘉宾原话,无法独立核验。)
【7】小公司倒逼巨头,以及「人人都能成」的进攻者世界观
后半程斯特宾斯把话题转向人和未来。阿拉文德反复回扣同一个主题:现在是「凭空起家」最好的时代。他说 Perplexity 起步时拿了亚马逊、谷歌云、Azure 加起来约一百万美元的算力额度;今天 Perplexity 自己在搞一个叫「十亿美元构建」(billion dollar build)的计划,给任何有可信路径做出十亿美元公司的团队发一百万美元算力额度,「我想要一千家这样的公司被造出来」。他赞成山姆·奥尔特曼给 YC 公司发两百万美元 token 的做法,「该多做这种事」。
他对「AI 让公司更高效」给了具体换算:四百人能做出两百亿美元的公司,那意味着四十人就能做十亿到二十亿;反过来,他宁愿那些一家两万亿美元公司本会雇的十万人,被拆成一千个一百人的团队、每个值几十亿——「那才酷」。但他对大众有一句不留情面的判断:很多人没有能动性(agency),有受害者心态;斯特宾斯接「他们得自救」,阿拉文德说「你得帮他们,得给他们一个榜样」。他举了个旧金山 Uber 司机的例子:那司机看了他的 YouTube 访谈,照着用 AI 从零搭了个网页应用、加了计费,被动收入超过开 Uber,于是减少了开车时间——「对有能动性、对未来抱正面态度的人,一切皆有可能」。
快问快答里几个判断值得记:
- 一个被普遍相信但完全错的观念?「太多人执着于在公司头一两年就找到护城河;你唯一的机会是跑得快——对我来说,跑得快是一种表达谦卑的方式,因为你在不停和真实世界接触、不停质疑自己的假设。」
- 给你无限的钱你会干嘛?「我会建数据中心。」在太空吗?「我没那个本事,我会从地球上的土地开始。」他把基础设施建设比作「工业时代的回归」。
- SpaceX、Anthropic、OpenAI 三个即将上市的公司,买入持有十年选哪个?「SpaceX——它是 n=1 的公司,Anthropic 和 OpenAI 能宣称彼此能做对方的事,但 SpaceX 是唯一在为连接性建太空基础设施的公司。」
- 关于「下一估值层级」,他引了 Coatue(科图资本)披露的数据:到达更高估值层级的概率更高——一家公司在十亿美元时跃到百亿很难,但越往上越容易;这对人也成立,一个有一亿美元流动净资产的人成为亿万富翁,比一个一千万的人容易得多。(按公开报道,这组数据出自 Coatue 的托马斯·拉丰,2026 年 6 月 4 日披露:独角兽跃到百亿美元的概率约百分之八,已过千亿美元的公司到达万亿的概率约百分之三十一。)
收尾他谈了从埃隆和黄仁勋(Jensen Huang)身上学到的东西。黄仁勋让他震撼的是那种「极度求真」的强度——据说每天醒来都告诉自己「我很烂」,告诉身边所有人「我们离破产只有三十天」;一家五万亿美元、未来两年几乎确定赚五千亿美元、握着全世界最先进芯片的公司,老板用「离破产三十天」的心态运营,「这才是当黄仁勋要付的代价」。埃隆教他的是「永远只盯那个限制性问题(the limiting problem),忽略其余一切」——这极难,因为你得擅长专注、擅长忽略那些「重要但此刻是干扰」的事。被问「这些数字(两万亿、二十万亿)激励你吗」,他说不,「很难被财富激励,你得被影响力激励」。
代表性短摘与中文转述
- 谈进攻者心态:「我一无可失,我从一无所有里来」("I have nothing to lose. I came from nothing")。他的座右铭就三个词——"attack, attack, attack"。中文转述:与其装作在避免失败、其实是在防守,不如永远全力进攻。
- 谈 Perplexity 对谷歌的影响:他自述「你可以说是 Perplexity 把 Google.com 改得比谷歌任何一个产品经理这辈子改过的都多」,证据是谷歌 AI 模式「看起来跟 Perplexity 一模一样,只是还没我们做得好」。这是嘉宾自利叙事,相似是事实、因果是断言。
- 谈钱在哪:「前沿才是钱所在的地方」("the frontier is where the money is")。中文转述:搜索被商品化、不赚钱,真正付费的是研究报告和能替你干活的智能体。
- 谈模型的命运:他借布罗克曼的话——「模型不再是产品」("the model is no longer the product")。中文转述:单纯转卖 token 没生意,价值在编排;Perplexity 的差异化是跨模型编排。
- 谈唯一指标:「每瓦每用户的 token 价值」("token value per watt per user")。中文转述:定价的根本是电,谁用最少的电产出最有价值的输出,谁就有定价权。
- 谈瓶颈与美光:「谁是瓶颈谁定价」「智能体比人类更会用 CPU」。由此推出美光六到十二个月市值可能超过 Meta(嘉宾预测)。
- 谈出口管制:短期「开源和前沿之间约十二个月的差距,唯一的原因就是出口管制」(帮的是美国);长期「你可能正在把中国炼成一个远更强悍的竞争者」,「下一个 DeepSeek 时刻」概率百分之二十到三十。
- 谈行业本质:「没人能松懈」("no one can relax")——哪怕模型厂商,六个月拿不出新能力就完蛋。
- 谈黄仁勋:他「离破产只有三十天」的运营心态,是「当黄仁勋要付的代价」。谈动机:「很难被财富激励,你得被影响力激励」。
注:
- 阿拉文德·斯里尼瓦斯(Aravind Srinivas):Perplexity 联合创始人兼 CEO,印度裔,加州大学伯克利分校 AI 方向博士背景,曾在 OpenAI、DeepMind、谷歌实习/工作。ASR 自动字幕把他的名字错拼成「Aravven Shrinus / Ara / Arvind」,均指同一人。
- HBM(高带宽内存,high-bandwidth memory):堆叠式 DRAM,是训练和推理大模型时喂饱 GPU 的关键内存,当前最紧缺的瓶颈环节之一,主要供应商为美光(Micron)、SK Hynix、三星。ASR 把 HBM 错听成「HPMs」;主持人斯特宾斯口播时说成「high performance memory(高性能内存)」也是口误,正确展开是「高带宽内存」。
- 答案引擎(answer engine):相对「搜索引擎返回一串链接」,答案引擎直接给出综合后的答案并附引用来源,是 Perplexity 的初代产品形态。
- 出口管制(export controls):指美国对向中国出口先进 AI 芯片(英伟达高端 GPU)及高带宽内存等的限制。注意阿拉文德的论断是「短期帮美国、长期可能反噬」的两段式,视频标题「Helped Not Hurt China」是被压缩的 clickbait,不能据此把他的话写成「出口管制单纯帮了中国」这一已证实事实。
- 约三百四十亿美元收购 Chrome 的报价:背景属实——2025 年 Perplexity 曾对谷歌的 Chrome 浏览器发出约三百四十五亿美元的非邀约(unsolicited)报价,金额超过当时 Perplexity 自身估值。本期 intro 提到的「$34 billion Chrome bid」即指此事。
- 强论断的来源限定(重要):以下均为嘉宾观点或预测,不是已证实事实——①「美光未来六到十二个月市值可能超过 Meta」是阿拉文德的预测;他报的「美光约一万亿、Meta 约一万三到一万四千亿」等市值数字、以及「台积电投亚利桑那一千五百亿、美政府持英特尔百分之十、英伟达和软银各百分之五」等数字,均为嘉宾原话,视频录于 2026 年 6 月,超出可独立核验的窗口,无法独立验证。②「出口管制短期帮美国、长期可能反噬」按其判断成立但属个人分析。③「AI 最大的瓶颈是电力短缺」是嘉宾判断。④「Perplexity 改 Google.com 超过任何谷歌产品经理」是嘉宾自述,AI 模式形似 Perplexity 是事实,但因果关系是断言而非证明。⑤「约百分之四十的数据中心因公众阻力没建成」这个数字由主持人斯特宾斯先抛出、阿拉文德附和,非阿拉文德原创。
- ASR/口播纠错对照:Vera Rubin(英伟达 Blackwell 之后的下一代架构,字幕错作「ver rubins / wear rubons」);Nemotron(英伟达模型线,字幕错作「Limatron」);Marc Benioff(Salesforce CEO,错作「Mark Benov」);SK Hynix(错作「SKH / Heinix」);CoreWeave(错作「Corev」);Crusoe(错作「Cruso」);Baseten(错作「base 10」);HashiCorp(错作「Hashikarp」);vibe coding(错作「wipe coding」);萨提亚·纳德拉(Satya,微软 CEO);达里奥·阿莫迪(Dario,Anthropic CEO);格雷格·布罗克曼(Greg Brockman,OpenAI 总裁);杰夫·迪恩(Jeff Dean,谷歌);大卫·多伊奇(David Deutsch,物理学家/《无穷的开始》作者);Coatue(科图资本,「下一估值层级概率」数据出自其托马斯·拉丰,2026 年 6 月 4 日披露)。少数字幕中身份不明的人名(如开场前聊过的女性、某个一年内涨到百分之百的预测者)因无法核实,正文按角色描述处理、未硬安姓名。
最后:这些反共识论断,哪些有据、哪些是创始人话术
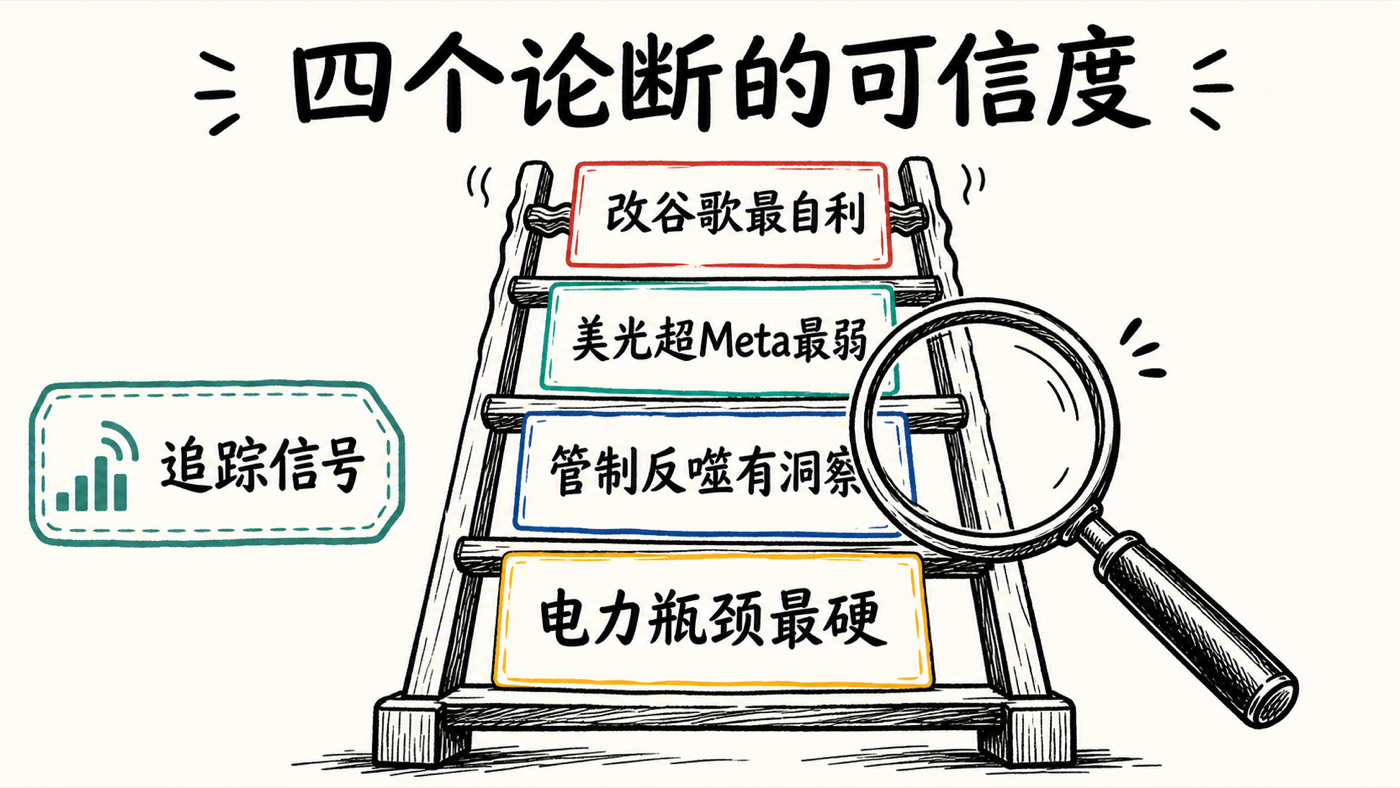
这不是总结,是给阿拉文德四个反共识论断排一个可信度。
最站得住的是「电力是真瓶颈」。 这几乎是业内共识,不算他独有的洞见,但他把它讲得最具体:数据中心的真正前置时间在拿地、拿许可证、对接电网和散热,而不是买芯片;公众阻力把一部分产能堵在门外。这条判断的支撑细节最硬,几乎可以当事实接受——唯一要小心的是那个「四十/一百」的数字是主持人先说的、且没有给出来源,别当成实测数据。
最有洞察、也最被标题糟蹋的是「出口管制长期反噬」。 「短期助美、长期可能把中国逼成垂直整合的更强对手」是一个真正非平凡的判断,DeepSeek 用华为栈、改 KV 缓存塞进 SSD、绕开 3D NAND 这些细节给了它经验支撑,他还诚实地给了百分之二十到三十的概率而不是拍胸脯。这是全场最值得追踪的信号。但要警惕被那个「Helped Not Hurt China」的标题简化——他从没说出口管制单纯帮了中国,他说的是短期它在帮美国。把强版本当他的观点引用,就是曲解。
最弱的是「美光市值超 Meta」。 「谁是瓶颈谁定价」这条逻辑本身成立,但他在两个地方滑过去了:一是把「当下是瓶颈」直接等同于「有可持续定价权」——内存历史上是强周期、易商品化的品类,HBM 的紧缺更像产能错配下的阶段性现象,而非结构性护城河;当三星、SK Hynix 产能跟上,定价权会被稀释。二是他报的「美光约一万亿」基数本身存疑(按历史区间这明显偏高),但因为视频录于 2026 年 6 月、超出可核验窗口,只能照搬并标注不可验证。一句话:逻辑链条性感,落到具体标的上是创始人式的大胆下注,不是稳健分析。
最自利的是「Perplexity 改 Google 超过任何 PM」。 谷歌 AI 模式在体验上越来越像 Perplexity,这是可观察的事实;但「是 Perplexity 逼的」是断言,不是证明——谷歌本来就在做 LLM 驱动的搜索,ChatGPT 的冲击同样是动因。这句话的功能更多是品牌叙事而非因果分析,听的时候要把「相似」和「我导致的相似」分开。
把这四条放回开头那个「进攻,进攻,进攻」的底色里就都讲通了:他不是在做平衡的分析,他是在做一个一无可失的进攻者会做的事——挑最大胆的版本说出来,赌对了是远见,赌错了反正「我从一无所有里来」。对听众而言,最该提取的不是他的结论,是他那条换算底座——每瓦每用户的 token 价值,和那个值得长期追踪的变量——下一个 DeepSeek 时刻会不会来。