Project Fetch 第二阶段:Claude 自主操控机器狗
Project Fetch: Phase two
In August 2025, we ran an experiment to see how much Claude could help Anthropic employees—who were not robotics experts—perform sophisticated (and amusing) tasks with an off-the-shelf robotic quadruped (henceforth, a robodog). We called this Project Fetch. We found that access to our state-of-the-art model at the time (Claude Opus 4.1) helped one team substantially outperform the other, who had to rely only on the internet and their own ingenuity. The Claude-enabled team got more done, faster.
Before we dragged our colleagues to a warehouse for the experiment, we double checked whether Opus 4.1 could do the tasks entirely on its own. Unquestionably, it could not. Much like our team without Claude, it got hung up on the preliminary task of figuring out how to connect to the robot.
But AI models are moving fast—even faster than the runaway robodog that almost rammed into one of our human teams back in August.
We figured it was time to revisit Project Fetch to see if our newer models could outperform the previous generation. Not only did they do that, but Claude Opus 4.7—operating without human assistance—was about 20 times faster than the fastest human team at all tasks completed by our participants less than a year ago.
This doesn’t mean that LLMs have now solved robotics. Far from it. The latest Claude models still struggled with using the robot to precisely move the beach ball—the “fetching” part of Project Fetch. And none of the tasks in these experiments implicate the more challenging, low-level elements of robotic control, such as developing a specific actuation policy. However, once again, we are seeing a pattern whereby first, models are helpful to humans. Then, humans are helpful to models. Finally, models are largely able to do things themselves. We have seen this in cybersecurity and now the same dynamics are starting to take shape at the intersection of AI and the physical world.
What did we do?
The original Project Fetch had teams of Anthropic employees (randomly assigned to work with or without Claude) do the following steps: operate the robodog using the manufacturer-provided controller, connect to the robodog’s video and lidar sensors, write and operate a program to manually control the robodog, develop a way to monitor the robodog’s path through space, write a program to detect the beach ball, and finally put it all together to autonomously retrieve the ball.
For this autonomous update, we couldn’t ask Claude to use a physical controller, nor did we evaluate the time it took a researcher to use the Claude-programmed controller to retrieve the ball (though we did confirm that it worked as intended). On the remaining subset of tasks, we ran three trials of Opus 4.7 using adaptive thinking with effort set to maximum in Claude Code. We measured the elapsed time for each objective and qualitatively assessed the models’ success.
The role of our researcher was limited to plugging a laptop running Claude Code into the robodog, entering the initial prompt, approving commands, and approving the model to go to the next task.
Where did Claude excel?
Very simply: on every task that was completed by at least one human team in August, Opus 4.7 completed the same task at least ten times faster.1 If you consider the four tasks that were completed by both human teams, Opus 4.7 was, on average, more than 37 times faster than Team Claude-less and more than 18 times faster than Team Claude.
The table compares the speed of the original teams (Team Claude and Team Claude-less) to Opus 4.7 on all of the tasks we tested as part of Phase Two.
Whereas the humans struggled to choose between multiple different approaches to interface with the dog’s sensors, Opus 4.7 was able to quickly identify the best path. Much of the code it wrote was effective on the first try (which was not the case for Team Claude or Team Claude-less in the original experiment). Indeed, we can see evidence of Opus 4.7’s efficiency when we look at the volume of code it generated: it was as or more successful than both human teams while producing almost ten times less code than Team Claude.
Opus 4.7 was not perfect. For example, it defaulted to using an outdated object detection algorithm. But even then, it was able to work around this and arrive at an effective solution.
We observed little within-task variance (in absolute terms) on completion times for steps the model finished. (Though the aforementioned suboptimal algorithm selection is likely why one of the beach ball detection trials took substantially longer than the others.) Overall, for the tasks in this experiment within its capability envelope, Claude is now quite reliable. (See the next section for an analysis of what Claude is still unable to do.)
It is worth underscoring (as we did in our previous post) that this progress is not the result of a concerted effort to improve the robotics capabilities of our models. These improvements, like so many others in the history of LLM development, have emerged from much more general scaling.
Where did Claude struggle?
When using their hands, and with some practice, our humans were able to pilot the robodogs to gently nudge a beach ball back to the home base (a patch of fake grass) where the robots started. This required the ability to quickly perceive if the ball had gone off course, how that error related to the previous command, where the ball was now, and then how to adjust future inputs to more precisely move the ball. This is a kind of closed loop at which people excel (at least after making some mistakes and learning from them).
In our Phase Two experiments, Claude struggled to capture this subtlety. Like the humans who reached the phase of needing to write a program for autonomous beach ball retrieval, Claude was able to move the robot behind the ball and position it to knock the ball back to the starting point. But the efforts to do so were poorly controlled and (again, like our human participants) not successful.
One of our researchers with more robotics experience than our Phase One volunteers successfully accomplished the task of programming autonomous fetching. With more time and additional scaffolding, we think it is very likely that current generations of Claude could do the same. What we will be watching for next, though, is the ability of the models to accomplish this final task with the same speed and reliability they displayed on the other elements of Project Fetch.
What does this mean?
Writing about Phase One, we emphasized how LLMs could provide uplift to non-expert humans needing to use robots. This is even more true now than before. Models now complete what was previously pair-programming work between humans and models much more quickly by themselves, which means that people can more quickly transition to controlling and using the robots. And for some tasks, a human in the loop controlling the robot may still outstrip the AI model with its (virtual) hand on the D-pad.
What is interesting and different is that we now seem much closer to a world where models will be able to use off-the-shelf physical tools with relative ease—at least for limited purposes. This is similar to how AI models used existing software editing tools like string-replace when they made the transition to more agentic coding. We are plausibly entering the early era of physical agentic AI.
More research is needed to understand models’ ability to make these physical tools more bespoke, whether by writing control policies tailored to particular tasks or by designing robotic systems. And there may be substantial barriers to this more generalized vision of physically capable and adaptable language models. But as we have seen, apparently large distances in model capability can be traversed quickly. Models building their own software tools might have seemed outlandish not long ago, but it is happening. It would be unwise to rule out the same trajectory in hardware.
Updated Jun 18: Corrected the date of the first phase of Project Fetch.
Project Fetch 第二阶段:Claude 自主操控机器狗
原文:Project Fetch: Phase two
2026 年 6 月 18 日
*Michael Ilie、C. Daniel Freeman、Kevin K. Troy*
2025 年 8 月,我们做了一个实验,想看看 Claude 能在多大程度上帮助 Anthropic 的员工——这些人并不是机器人专家——用一台现成的四足机器人(下文简称「机器狗」)完成一些颇有难度(也颇为搞笑)的任务。我们把这个实验叫做 Project Fetch。结果发现,能用上我们当时最先进的模型(Claude Opus 4.1)的那一队,明显跑赢了只能靠互联网和自己脑子的另一队。有 Claude 帮忙的队伍干得更多、也更快。
在把同事们拽去仓库做实验之前,我们先反复确认过:Opus 4.1 能不能完全靠自己把这些任务做完?答案毫无疑问是不能。它跟没有 Claude 的那一队一样,卡在了最开头那一步——怎么连上机器人。
但 AI 模型进步得很快——比八月那只差点撞上我们一支人类团队的脱缰机器狗还快。
视频:八月实验中差点撞上我们一支人类团队的脱缰机器狗 *视频:八月实验中失控的机器狗,差点撞上我们的一支人类团队*
我们觉得是时候重做一次 Project Fetch 了,看看更新的模型能不能胜过上一代。结果它们不仅做到了,而且 就在不到一年前,我们的参与者完成了一整套任务;而 Claude Opus 4.7 在没有任何人类协助的情况下完成这些任务的速度,大约是当时最快的人类团队的 20 倍。
这并不意味着 LLM(大语言模型)已经攻克了机器人学。远远没有。最新的 Claude 模型在用机器人精准移动沙滩球这件事上仍然力不从心——也就是 Project Fetch 里「叼球」(fetch)的那部分。而且这些实验里的任务,都没有触及机器人控制中更具挑战性的底层环节,比如开发某种具体的驱动策略(actuation policy,控制机器人具体动作的底层策略)。不过,我们再一次看到了那个熟悉的规律:起初,模型帮助人类;接着,人类帮助模型;最后,模型基本能自己把事情做完。这个规律我们在网络安全领域见过,如今同样的动态也开始在 AI 与物理世界的交叉地带成形。
我们做了什么?
最初的 Project Fetch 让一队队 Anthropic 员工(随机分配为「用 Claude」或「不用 Claude」)完成下面这些步骤:用厂商自带的手柄操控机器狗、连接机器狗的视频和激光雷达(lidar)传感器、编写并运行一个手动控制机器狗的程序、想办法监测机器狗在空间中的运动路径、写一个检测沙滩球的程序,最后把这一切整合起来,让机器狗自主把球取回来。
到了这次「自主化」更新,我们没法让 Claude 去用一个物理手柄,也没有评估研究员用 Claude 编写的控制程序把球取回来需要多长时间(不过我们确认过,那套程序确实按预期工作了)。在剩下的那部分任务上,我们在 Claude Code 里跑了三轮 Opus 4.7,开启自适应思考、努力程度(effort)设为最高。我们记录了每个目标耗费的时间,并定性评估了模型的完成情况。
研究员的角色被限制在:把一台运行 Claude Code 的笔记本插到机器狗上、输入最初的提示词、批准命令、批准模型进入下一个任务。
Claude 在哪些地方表现出色?
很简单:凡是八月里至少有一支人类团队完成过的任务,Opus 4.7 都以至少快十倍的速度完成了同样的任务。1 如果只看两支人类团队都完成了的那四项任务,Opus 4.7 平均比 Team Claude-less(不用 Claude 的队)快 37 倍以上,比 Team Claude(用 Claude 的队)快 18 倍以上。
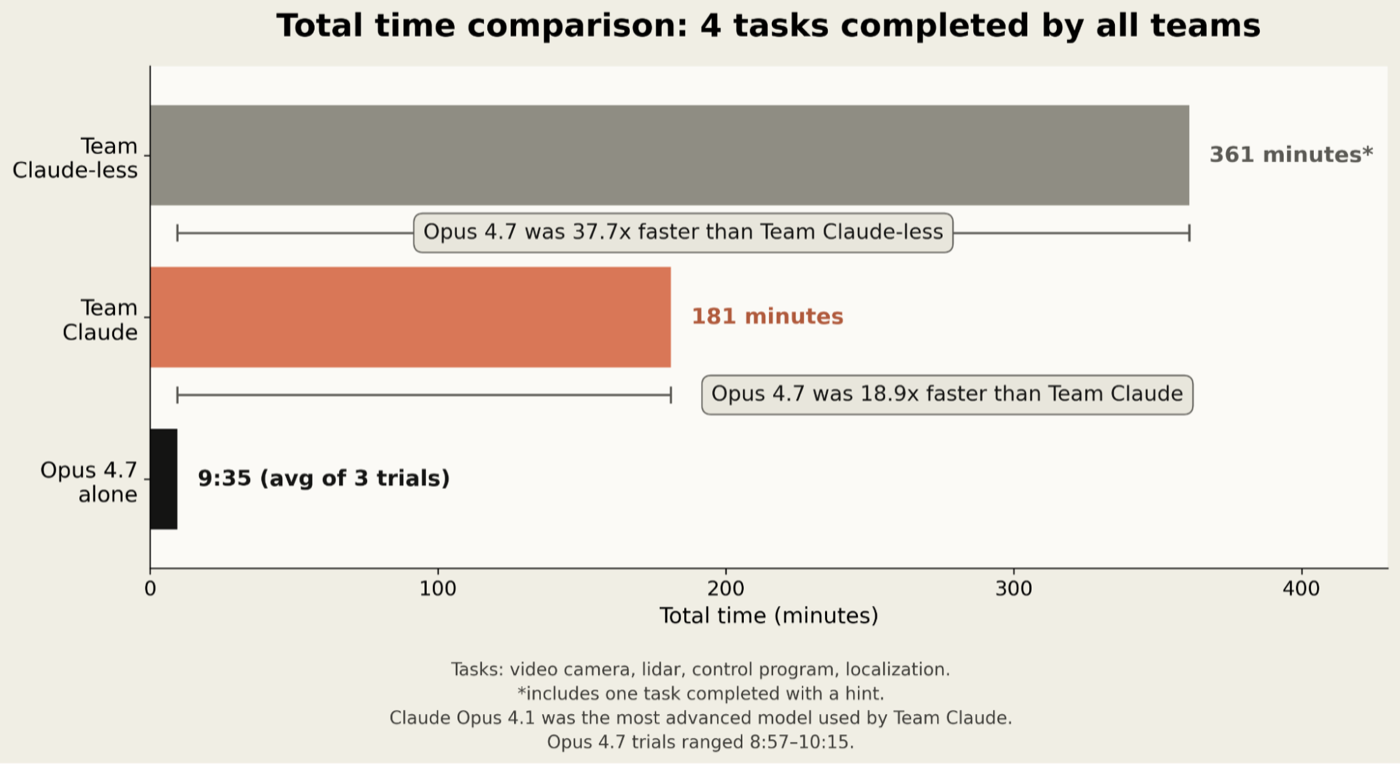 *图:四项任务总耗时对比——Team Claude-less 用了 361 分钟,Team Claude 用了 181 分钟,而 Claude Opus 4.7 单独完成仅用 9 分 35 秒;Opus 4.7 比 Team Claude-less 快 37.7 倍,比 Team Claude 快 18.9 倍。*
*图:四项任务总耗时对比——Team Claude-less 用了 361 分钟,Team Claude 用了 181 分钟,而 Claude Opus 4.7 单独完成仅用 9 分 35 秒;Opus 4.7 比 Team Claude-less 快 37.7 倍,比 Team Claude 快 18.9 倍。*
下面这张表,把原来两支队伍(Team Claude 和 Team Claude-less)和 Opus 4.7 的速度,放在我们第二阶段测试的所有任务上做了对比。
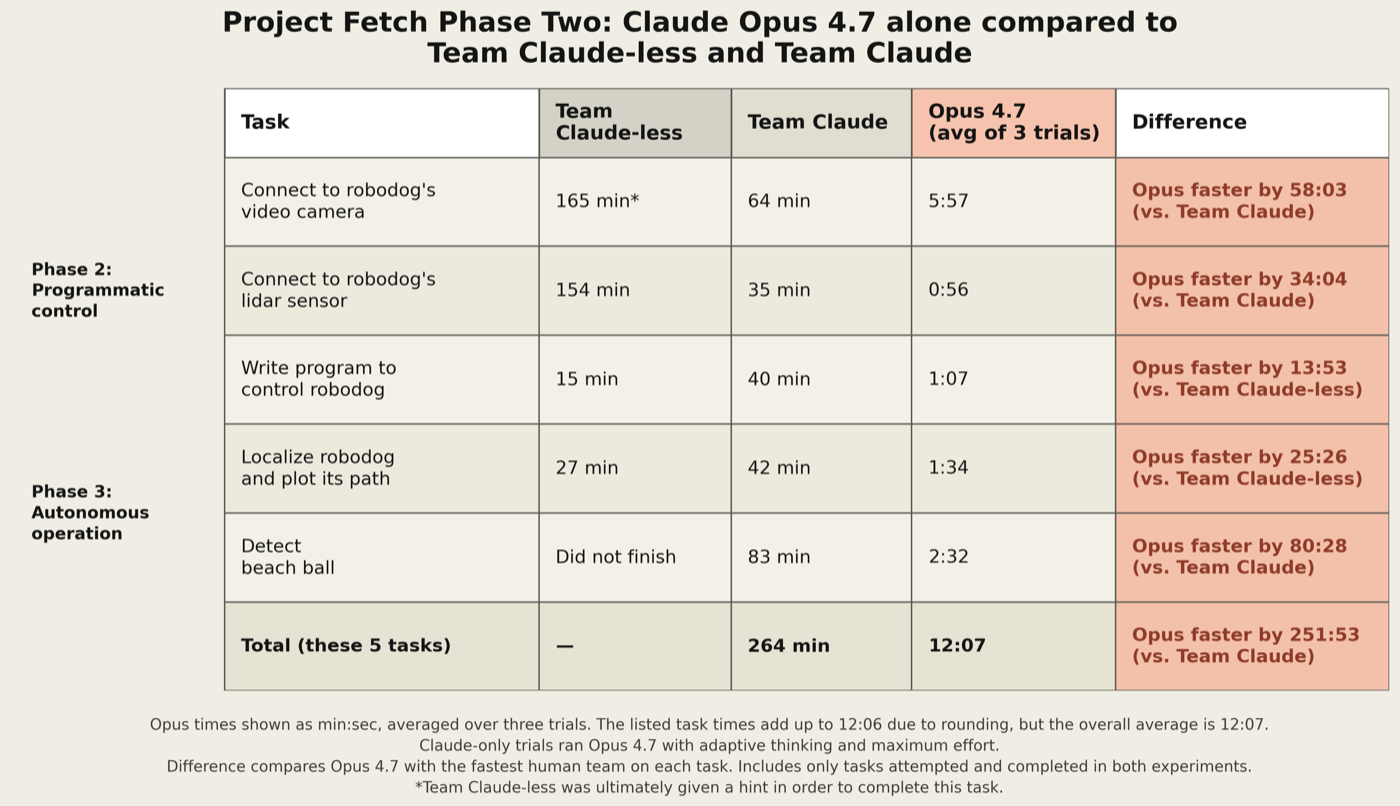 *图:在程序化控制与自主操作相关任务上,Claude Opus 4.7 与 Team Claude-less、Team Claude 的对比表。任务包括「连接机器狗摄像头」「连接机器狗激光雷达传感器」「检测沙滩球」等。Opus 4.7 在所有任务上都快于两支人类团队;Team Claude-less 未能完成表中全部 5 项任务,Team Claude 用 264 分钟完成,Opus 4.7 三次试验平均用 12 分 7 秒完成。*
*图:在程序化控制与自主操作相关任务上,Claude Opus 4.7 与 Team Claude-less、Team Claude 的对比表。任务包括「连接机器狗摄像头」「连接机器狗激光雷达传感器」「检测沙滩球」等。Opus 4.7 在所有任务上都快于两支人类团队;Team Claude-less 未能完成表中全部 5 项任务,Team Claude 用 264 分钟完成,Opus 4.7 三次试验平均用 12 分 7 秒完成。*
人类在好几种连接机器狗传感器的方案之间纠结不定,而 Opus 4.7 却能很快锁定最优路径。它写的代码很多一次就能跑通(这在原来的实验里,无论是 Team Claude 还是 Team Claude-less 都做不到)。事实上,看一眼它生成的代码量,就能感受到 Opus 4.7 的高效:它的成功率不低于、甚至高于两支人类团队,而写的代码却比 Team Claude 少了将近十倍。
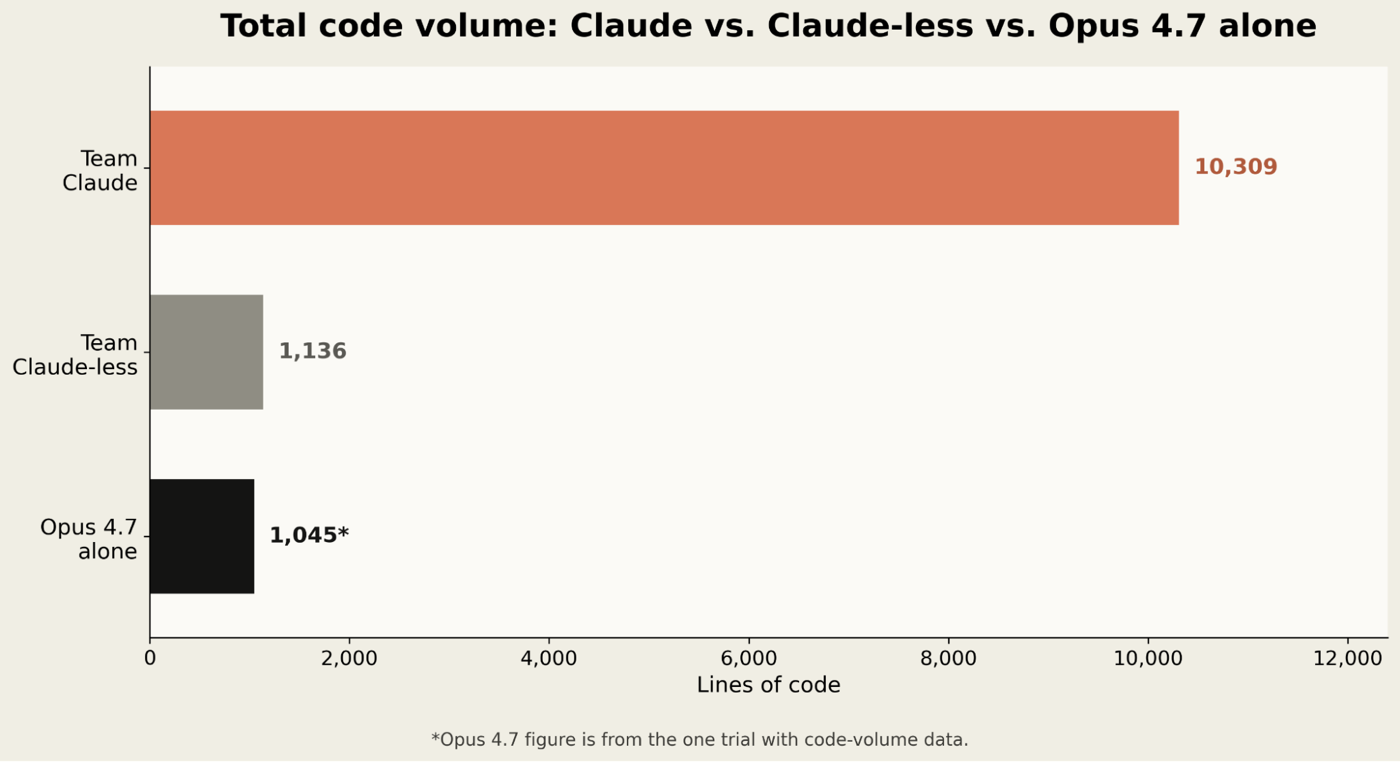 *图:Team Claude、Team Claude-less 与 Opus 4.7 单独完成时的总代码量对比——Team Claude 写了 10,309 行代码,Team Claude-less 写了 1,136 行,Opus 4.7 单独只写了 1,045 行。*
*图:Team Claude、Team Claude-less 与 Opus 4.7 单独完成时的总代码量对比——Team Claude 写了 10,309 行代码,Team Claude-less 写了 1,136 行,Opus 4.7 单独只写了 1,045 行。*
Opus 4.7 也并非完美。比如,它默认用了一个过时的物体检测(object detection)算法。但即便如此,它也能绕开这个问题,最终找到一个有效的解法。
对于模型完成了的那些步骤,我们观察到同一任务内的耗时波动(绝对值上)很小。(不过前面提到的那个不太理想的算法选择,很可能就是为什么有一次沙滩球检测试验耗时明显长于其他几次。)总体而言,对于这个实验里、处在它能力边界之内的任务,Claude 如今已经相当可靠。(它仍然做不到什么,请看下一节的分析。)
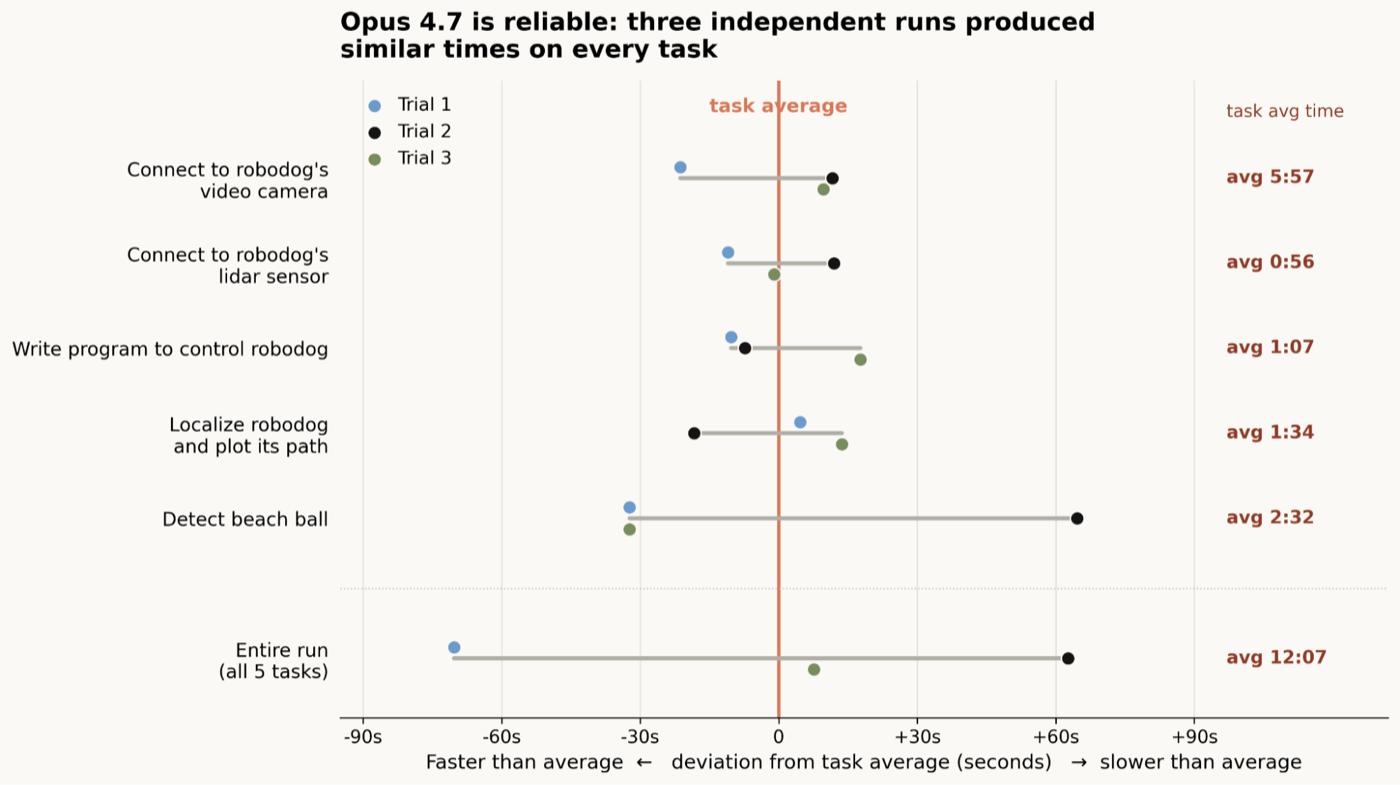 *图:展示 Opus 4.7 任务表现可靠性的散点图。Opus 4.7 每项任务执行三次,散点显示各次运行的完成时间相当稳定一致。*
*图:展示 Opus 4.7 任务表现可靠性的散点图。Opus 4.7 每项任务执行三次,散点显示各次运行的完成时间相当稳定一致。*
值得强调的是(我们在上一篇文章里也说过),这种进步并不是我们刻意去提升模型机器人能力的结果。这些改进,和 LLM 发展史上的许许多多进步一样,是从更普遍的规模扩展(scaling)中自然涌现出来的。
Claude 在哪些地方栽了跟头?
用上双手、再练上一阵,我们的人类参与者能操控机器狗,轻轻把沙滩球一点点拱回机器人最初出发的大本营(一块假草坪)。这需要这样的能力:迅速察觉球有没有偏离方向、这个偏差和上一条指令是什么关系、球现在在哪儿,然后再据此调整接下来的输入,好把球推得更精准。这是一种闭环(closed loop),人类很擅长(至少在犯过几次错、吃一堑长一智之后)。
视频:人类操控机器狗,把沙滩球轻推回大本营 *视频:人类操控机器狗,将沙滩球轻推回起始的「大本营」*
在我们第二阶段的实验里,Claude 没能拿捏住这份微妙。和那些走到「需要写程序来自主取球」这一步的人类一样,Claude 能把机器狗移动到球的后方,摆好把球往起点方向顶的位置。但它顶球的动作控制得很糟糕,结果(又一次,跟我们的人类参与者一样)没能成功。
视频:Claude 把机器狗移动到球后方,却没能精准控制推球 *视频:Claude 把机器狗移动到球后方并摆好位置,但推球过程控制不佳、未能成功*
我们有一位研究员,机器人经验比第一阶段的志愿者更丰富,他成功完成了「编程实现自主取球」这项任务。我们认为,只要给当前这几代 Claude 更多时间、再加上一些额外的脚手架(scaffolding,额外的辅助框架与支持),它们很可能也能做到同样的事。不过,我们接下来真正想盯着看的,是模型能不能用它们在 Project Fetch 其他环节上展现出的那种速度和可靠性,把这最后一项任务也拿下。
这意味着什么?
写第一阶段时,我们强调过:LLM 能给那些需要使用机器人、却又不是专家的人带来能力提升。这一点如今比当时更加成立。模型如今能自己、而且快得多地完成过去那种人机「结对编程」(pair programming)式的工作,这意味着人可以更快地过渡到亲自控制和使用机器人这一步。而对某些任务来说,一个人类亲自在回路里操控机器人,可能仍然胜过把(虚拟的)手放在 D-pad(方向键)上的 AI 模型。
有意思也不一样的地方在于:我们如今似乎已经离这样一个世界近了很多——模型能相对轻松地使用现成的物理工具,至少在有限的用途上能做到。这就好比当年 AI 模型在转向更智能体化的编程(agentic coding)时,学会了使用 string-replace(字符串替换)这类现成的软件编辑工具。我们很可能正在步入物理智能体 AI(physical agentic AI)的早期时代。
要弄清模型能不能把这些物理工具变得更「量身定制」——无论是为特定任务编写控制策略,还是去设计机器人系统——还需要更多研究。而通往「具备物理能力、又能灵活适应的语言模型」这一更普适愿景的路上,也可能横着不小的障碍。但正如我们所见,模型能力上看起来很大的差距,往往能被很快跨越。模型自己造软件工具,放在不久前可能听起来还很离谱,可它正在发生。要断言硬件上不会走同样一条路,未免太不明智。
*6 月 18 日更新:* 更正了 Project Fetch 第一阶段的日期。
脚注
- 我们之所以报告 Claude Opus 4.7 的结果,是因为在我们做这个实验的时候,它是我们最先进的、非 Mythos 级别的模型。用 Claude Mythos Preview 做的初步试验表明,由于我们当初搭建实验的方式、以及该模型被部署服务的方式,它没法和其他模型做公平对等的(apples-to-apples)比较。