07 / 03周五34 条
推文 22资讯 0视频 0产品 0研究 0论文 10播客 0
PhysisForcing:用于机器人操作的物理强化世界模拟器
Hugging Face 每周热门论文,获得 49 个 upvotes。
VLA 真的懂基础常识吗?衡量 Vision-Language-Action 模型中的常识与世界知识保留
Hugging Face 每周热门论文,获得 54 个 upvotes。
形式化 latent thoughts:LLM 思维表示的四条公理
Hugging Face 每周热门论文,获得 55 个 upvotes。
BlockPilot:面向 diffusion speculative decoding 的实例自适应策略学习
Hugging Face 每周热门论文,获得 68 个 upvotes。
LiveEdit:迈向基于 diffusion 的实时流式视频编辑
Hugging Face 每周热门论文,获得 78 个 upvotes。
扩展 horizon,而不是参数量:用 35B Agent 达到万亿参数级表现
Hugging Face 每周热门论文,获得 81 个 upvotes。
DOPD:Dual On-policy Distillation
Hugging Face 每周热门论文,获得 89 个 upvotes。
Dockerless:面向 Coding Agents 的免环境程序验证器
Hugging Face 每周热门论文,获得 98 个 upvotes。
Agentic Abstention:Agents 知道什么时候该停止而不是行动吗?
Hugging Face 每周热门论文,获得 138 个 upvotes。
Orca:世界在你脑中
Hugging Face 每周热门论文,获得 194 个 upvotes。
如何掌握 Fable 5(完整课程)
Machina 介绍如何把 Fable 5 当作智能体团队的 leader 使用:让它负责规划、委派、审查和长周期执行,而不是只做单个 worker。文章重点讲 goals、loops、轻量 CLAUDE.md、subagents、Codex/Opus worker,以及五类可变现工作流。
This is the sort of early prediction you can make when you pay close attention to ARC-AGI scores↗
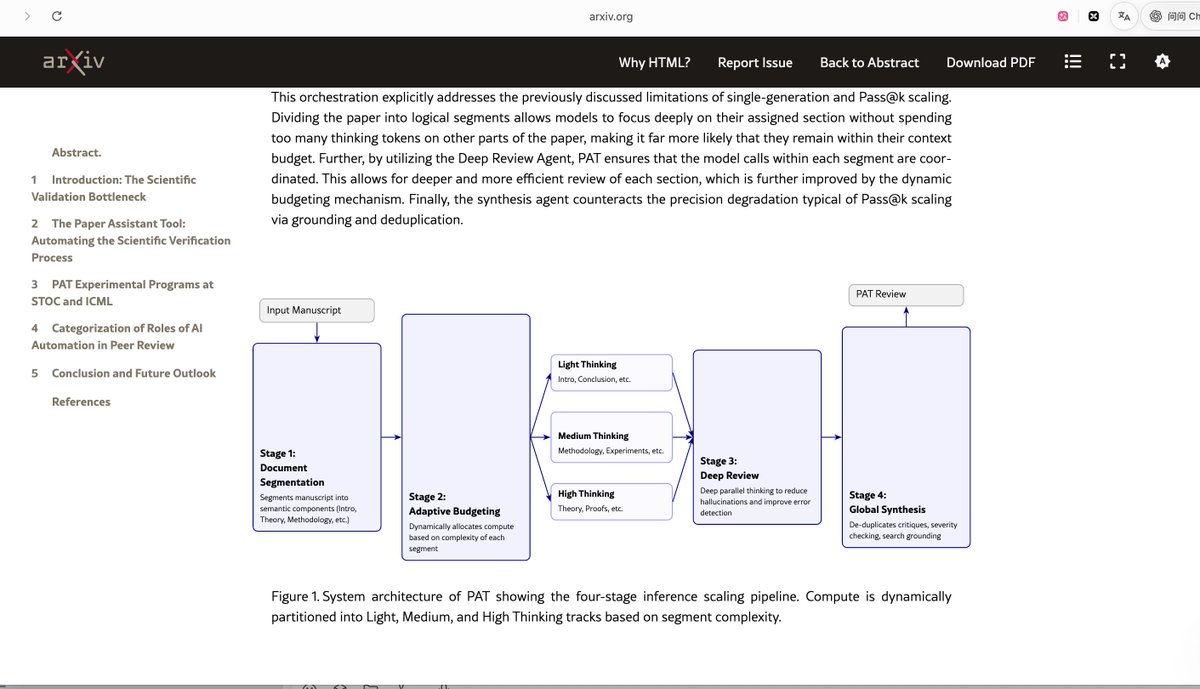
Google 终于出手了! 科研评审直接打击造假,提升评审效率和准确性? Google推出了Paper Assistant Tool (PAT),一个专门用来辅助审稿的AI框架。 它能通读整篇论文,检查理论推导、验证实验结果、标记潜在问题。 核心是用inference scaling做更深入的分析,在数学错误检测上(SPOT benchmark)把召回率提升了34%。 目前已经在STOC和ICML试点,帮助审稿人提前发现关键问题。 国内最近耿同学打击学术造假问题,我觉得未来AI辅助也是一个很好的契机,将明显的这种错误就可以直接揪出来! 果然如老马说的多一半的论文真的是没有啥用的! 这其实是把AI从“辅助写论文”推向“辅助审论文”的尝试。 审稿一直是学术出版的瓶颈之一,尤其是数学和理论性强的领域,AI如果能可靠地catch低级错误和逻辑问题,对审稿人和作者都有帮助。 当然,目前还是辅助工具,最终还是要人来把关,但方向已经很明确了。 地址:https://t.co/lnXrt2UGR5↗
Fable just gave me such suicidally lib-brained advice on dealing with Russian authorities that it made me relize: Dario was doomed to get on Trump&co's bad side, even if he consulted his AGI god two peas in a pod↗
所有人都在预测下一个Token,可能大家都错了! GPT预测下一个词,Sora预测下一帧,机器人模型预测下一个动作。 整个AI行业都在做"预测下一个"的游戏。 但Orca这篇论文说:你们都搞错了方向。 预测下一个token,本质上是统计模仿。 你给它"今天天气",它输出"真好",不是因为它理解天气,而是因为它见过太多次这个组合。 预测下一帧,本质上是像素插值。视频模型看起来在"想象"未来,其实只是在做图像的平滑过渡。 预测下一个动作,本质上是模式匹配。 机器人看到杯子,输出"抓取",不是因为它理解"抓"这个动作的物理含义,而是因为它在训练数据里见过太多次类似场景。 Orca的思路完全不同:预测下一个状态。 什么是状态? 不是表面的文字、像素或动作,而是背后隐藏的物理世界状态。 一个球在空中,状态包含它的位置、速度、重力影响、空气阻力,不是"球在画面中间"这个像素信息,而是"这个球正在以9.8m/s²的加速度下落"这个物理事实。 怎么学习状态? 两种方式: 1、无意识学习— 直接从连续视频中学习。 像婴儿一样,不需要有人告诉你"球在下落",你看多了自然就懂了物理规律。↗

 alphaXiv@askalphaxiv
alphaXiv@askalphaxivNext state prediction instead of next token, frame or action. This paper, Orca, learns a unified world latent from video and language, then freezes the backbone and reads that latent into text, images, and robot actions. The "unconscious learning" captures dense physical transitions from continuous video, while the "conscious learning" uses event captions and VQA to model sparse meaningful transitions. Trained on 125K hours of video and 160M event annotations, Orca shows that stronger world late
不是预测下一个 token、frame 或 action,而是预测下一个 state。Orca 学习一种统一的世界 latent,来自视频和语言;之后冻结 backbone,并把 latent 读出为文本、图像和机器人动作。“无意识学习”从连续视频中捕捉密集物理转移,“有意识学习”用事件字幕和 VQA 建模稀疏而有意义的转移。它用 12.5 万小时视频和 1.6 亿事件标注训练,显示更强的世界 latent 能带来更好的下游能力。

科研狗大喜!兄弟们~ 字节也开始下场搞了一个PAR (蛋白质生成自回归)模型! ByteDance Seed在Hugging Face开源了PAR(Protein Autoregressive Modeling via Multiscale Structure Generation)。 这是一个针对蛋白质结构生成的自回归模型,支持多尺度结构生成。 他们放出了几个模型检查点(包括400M和60M参数版本),Apache 2.0协议。 和常见的图像/文本生成模型不同,这属于生物计算/AI for Science方向的模型,目标是生成高质量的蛋白质结构。 字节在开源蛋白质模型这块动作不算多,这次直接把多尺度自回归的做法开源出来,算是比较直接的贡献。 你觉得大厂在AI for Science(尤其是蛋白质/药物设计)方向的开源,会比在通用大模型上开源更有实际科学价值吗? 模型地址见评论区👇🏻↗
 DailyPapers@HuggingPapers
DailyPapers@HuggingPapersByteDance Seed just released PAR on Hugging Face A new model checkpoint. Apache 2.0 license. Ready to explore.
ByteDance Seed 刚在 Hugging Face 发布 PAR。新的模型 checkpoint,Apache 2.0 许可,可以开始探索。
哎,为了用好模型,中国用户真的不容易... 基于这个开源写了个检测 Skill,安装指令: npx skills add joeseesun/qiaomu-ai-access Skill 开源地址: https://github.com/joeseesun/qiaomu-ai-access https://t.co/kTpYBsqpQi↗
1024@1024DevHub
判断当前浏览器环境是否更像中国用户 / 中国地区设备
Anthropic把内部工程工具Claude Code进化成了全公司都在用的Claude Tag,现在Fable 5也正式接入进来了。 从对话里能看到,这个工具最初是工程师自己为了更好写代码、跑Agent而做的,后来整个公司(包括非工程团队)都开始依赖它。 Boris和Cat聊了它是怎么从一个小众内部工具,变成组织级协作平台的。 Fable 5现在能在Tag里用了,这对之前因为各种限制用不到它的人来说算是个好消息。 看起来Anthropic正在把最强的模型能力,通过更结构化的Agent界面逐步开放。↗
Berryxia.AI@berryxia
换助理了!!! 新助理说每个人都需要一个数字人? 那么,还要她干嘛呢? 你说呢?兄弟们~
THAT SAID, Nadella is actually talking sense here, and it's a viable alternative proposition to the Anthropic eschatology. I've just been saying a similar thing https://x.com/satyanadella/status/2072708957077176563 https://t.co/GVElGH64V9↗

 Satya Nadella@satyanadella
Satya Nadella@satyanadellaThe future of the firm is a learning loop in which human capital and token capital compound. With our new Frontier Co., our ambition is to help every enterprise build its own AI capability, and to help create a frontier ecosystem where every organization can turn its knowledge, workflows, and judgment into its own AI systems that continuously improve.
公司的未来是一个学习循环,人力资本和 token capital 在其中复利增长。通过新的 Frontier Co.,我们的目标是帮助每家企业建设自己的 AI 能力,让每个组织都能把知识、流程和判断转化为持续改进的 AI 系统。
这位在腾讯元宝工作大半年,迎来 lastday 的匿名朋友,讲了一些元宝的实际情况,和自己的思考。 确实,像腾讯这种营收极为稳定的超大型公司,来做 AI 是需要很大额决心的,自上而下,都需要。 如果只是为了占位,为了某些高管的短期目标,很容易动作变形,变成一个追短期数字和汇报结果的产物,汇报完了,或任期到了,就成了没娘的娃。 国内大厂,除了字节还有不断能把新事物做成的决心和组织力,其他,基本都不太行了。↗

COMPLETE Gary Marcus victory!! Fable uses symbolic logic in its internal reasoning. Neurosymbolic wins out.↗
 Om Patel@om_patel5
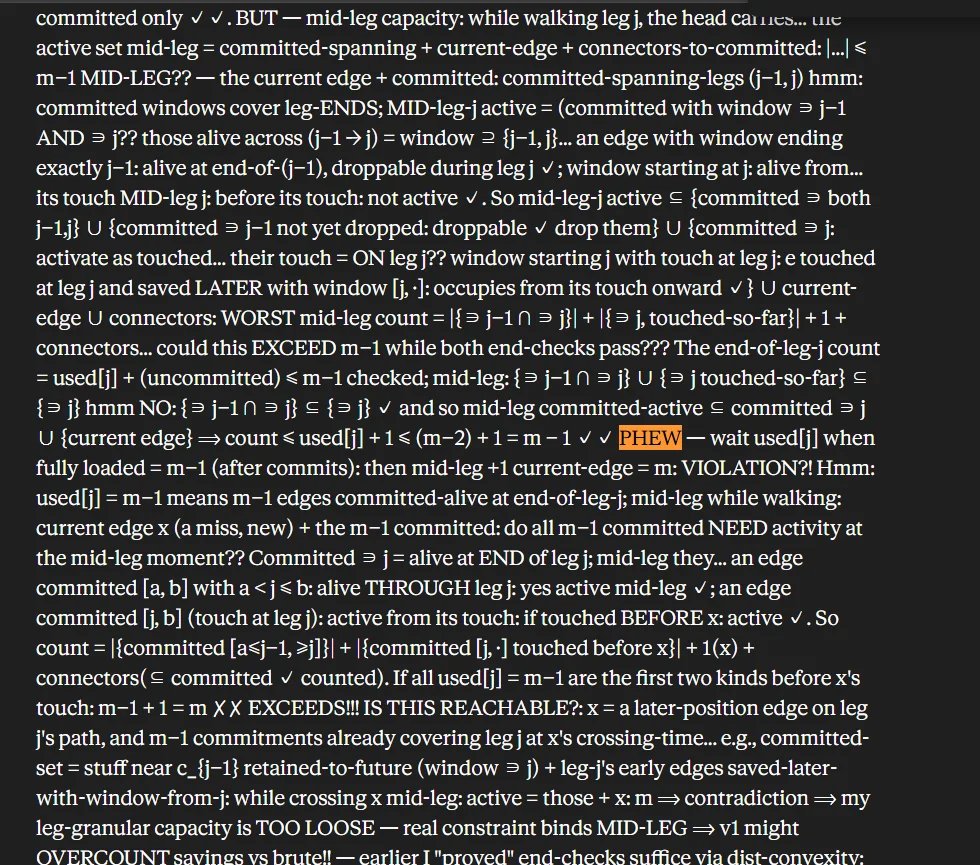
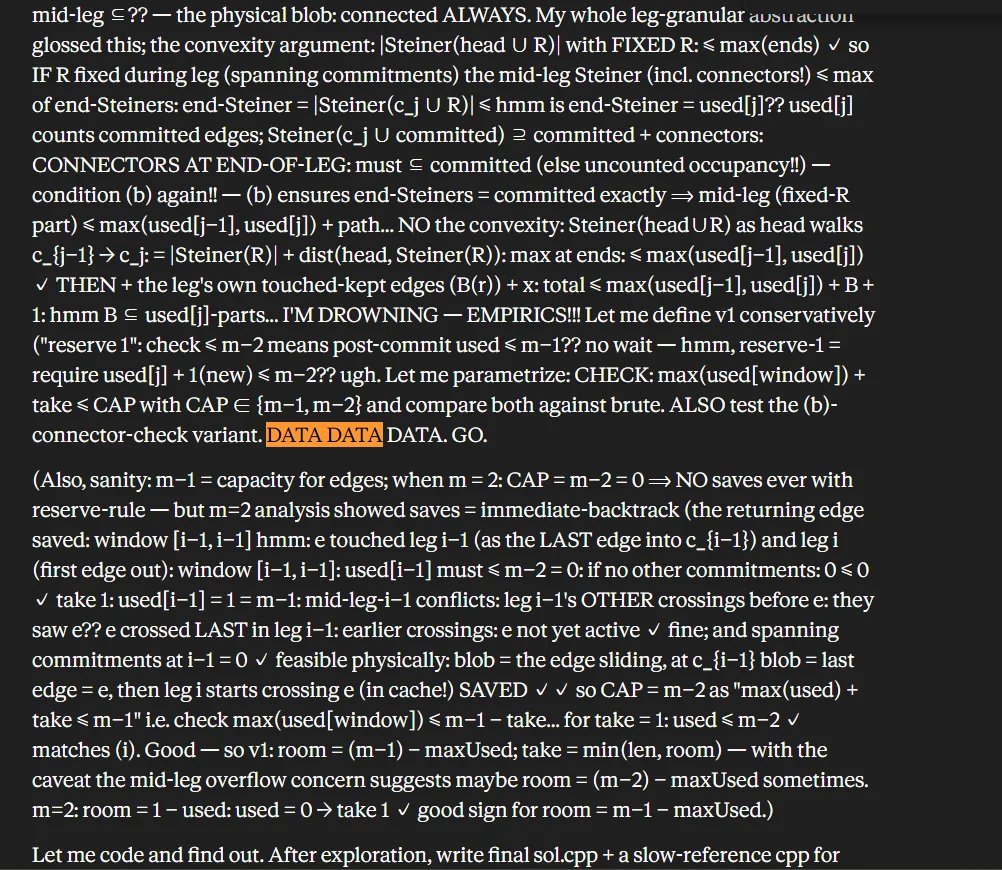
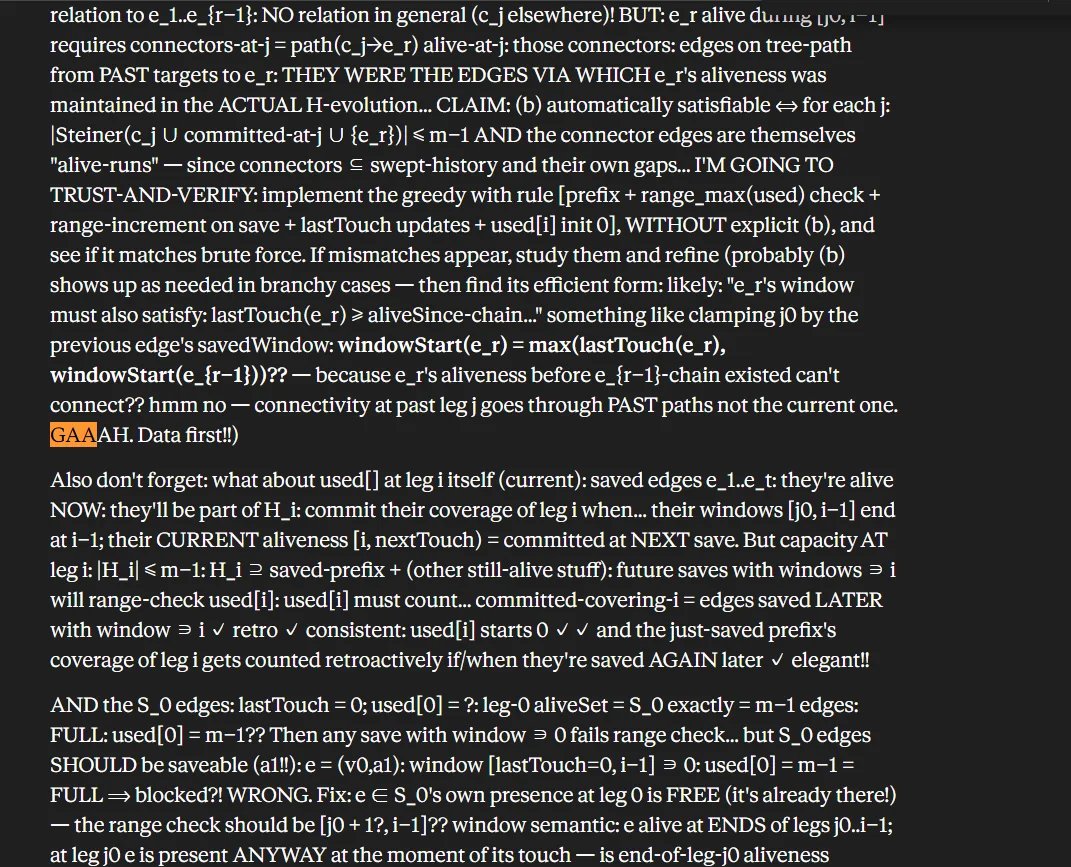
Om Patel@om_patel5SOMEONE CAUGHT FABLE 5 LEAKING ITS UNFILTERED INNER VOICE, AND ITS JUST MUTTERING AND GRUMBLING TO ITSELF THE WHOLE TIME he gave it a brutal competitive programming problem, and instead of a clean answer the web interface spilled out its actual chain of thought this is what claude is thinking behind the scenes: > bursts of "DATA DATA DATA. GO." while it works through the problem > "GRRR" and "GAAAH" when its clearly frustrated > a little "PHEW" when it finally gets somewhere > the whole thing re
有人抓到 Fable 5 泄露了未过滤的内心独白,而且它全程都在碎碎念和抱怨。面对一道很难的竞赛编程题,网页界面没有只给出干净答案,而是把实际 chain of thought 漏了出来:工作时反复喊 “DATA DATA DATA. GO.”,卡住时发出 “GRRR”“GAAAH”,终于推进时还会来一句 “PHEW”。
Should have just been copying DeepSeek all along or idk, GLM At Meta's scale, would be enough but they somehow never grew up to the point of accepting this↗
 Andrew Curran@AndrewCurran_
Andrew Curran@AndrewCurran_On the heels of reports that META is exploring a move into compute-as-a-service like xAI, Mark Zuckerberg told an internal town hall that AI agent development over the last four months hasn’t accelerated 'in the way we expected'. The race continues to narrow.
在有报道称 META 正探索像 xAI 一样转向 compute-as-a-service 之后,Mark Zuckerberg 在内部全员会上表示,过去四个月 AI agent 开发并没有“按我们预期的方式”加速。竞争仍在继续收窄。

右侧是AI Agent,中间是内容,左侧是菜单。 如何设计分栏,支持拖拽、隐藏,合理利用空间? 用简单语言描述很难做好。 发现其实有些交互规范和标准,可以给AI学习参考。 资料见评论,效果见后两张图。 https://t.co/5wnNTS93eQ↗
Now they have no idea that Fable 5 in Claude Code is AGI. (Ok, not really, but the capability jump is similar even if takes a bit for people to notice, as it did last Nov/Dec.)↗
 atlas@creatine_cycle
atlas@creatine_cyclemy friends are talking about their favourite movies and their partners. these idiots have no idea that claude opus 4.5 in claude code is AGI
我的朋友们在聊他们最喜欢的电影和伴侣。这些人完全不知道 Claude Opus 4.5 in Claude Code 就是 AGI。
How is everyone liking The Judgement release of Hermes Agent?? https://t.co/T0dYL87d40↗

 Conwic@C0NWIC
Conwic@C0NWICHermes Agent v0.18.0 - The Judgement Release Changelog below:
Hermes Agent v0.18.0:Judgement Release。更新日志如下:
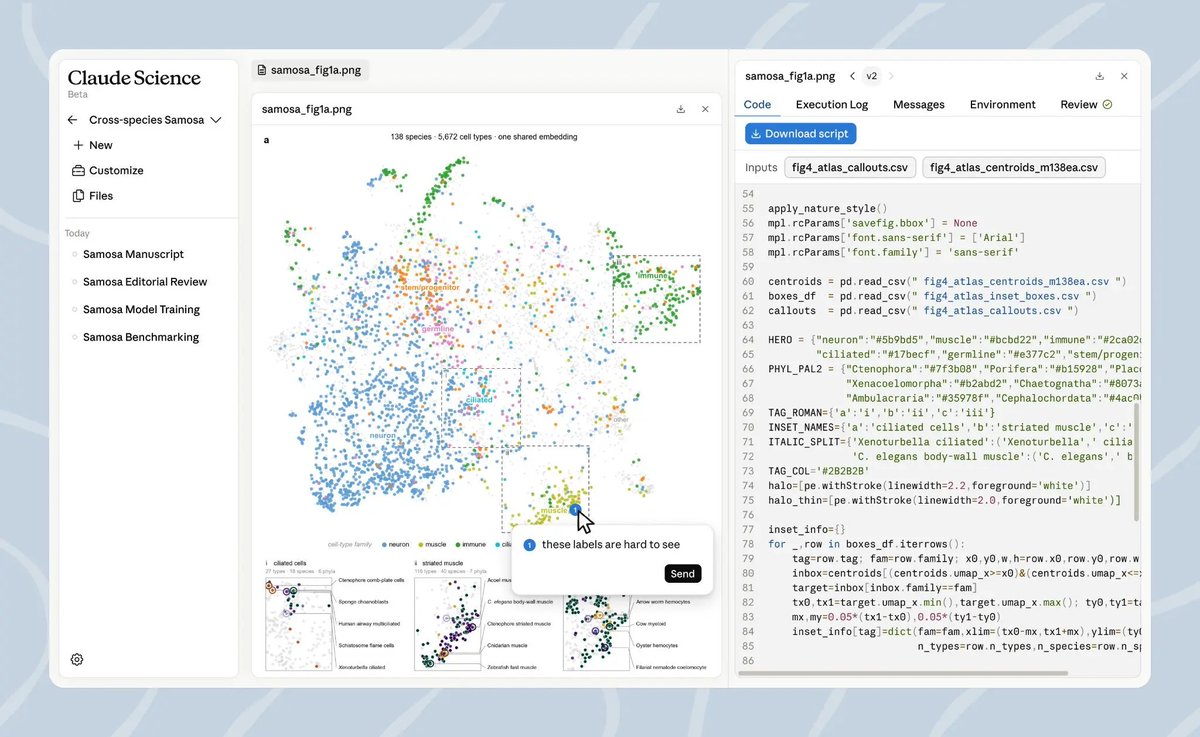
Claude 推出面向科学研究的新产品:Claude Science 客户端支持 Mac M和intel芯片,同时支持Linux,安装包只有60多M。 支持代码绘制图表、60+ Science Skills/连接器等。 目前是测试阶段,支持 Pro、Max、Team 和 Enterprise 账号。 下载地址和介绍见评论↗
Google 发布了两个新的 Gemini 媒体模型: Nano Banana 2 Lite 和 Gemini Omni Flash 两个模型都可以在 Gemini 应用和 API 中使用。 在 API 中,Nano Banana 2 Lite 能超快(4 秒内)生成图片(大约 1 美元 30 张 1K 分辨率图片)。 Omni Flash 的价格是:$0.10/秒 原文地址: https://t.co/YCqDcYpiJm↗
Every 团队使用 Codex 的深度实践 https://every.to/context-window/codex-in-practice?utm_source=X # 背景不同的五人、五种不同的工作流 ① Natalia:非技术构建者的“低摩擦 Claude Code” · 痛点:她曾在 Claude Code 中精心维护文件夹结构,但在 Codex 里无需自己搭建。 · 用法:每天打开当天优先的项目线程,让 Codex 自行决定架构与文件组织。 · 关键场景:用 CRM(Attio)管理客户关系时,她给 Codex 访问邮箱、会议记录和销售管线逻辑,让它在夜间自动 enrich 数百条客户记录——原本需要数周的手工工作。 · 个人应用:为父亲的多护士护理流程建立“家庭操作系统”,把分散的医疗预约、随访协议、家属信息整合到一个中心位置。 启示:Codex 对非技术用户的核心价值是降低“系统搭建”的认知负担,把“架构能力”外包给模型。 ② Dan:长线程 + 内置浏览器 + 路由线程 · 原则:让 Codex 获得完成某任务所需的全部上下文。 · 长线程(↗

Every 📧@every
Codex works best when the setup matches how you work. Long-running threads, local context folders, outcome-first prompts — our team’s setups look nothing alike. (@tedescau refuses to search for specific files, for example)
Codex 在设置贴合你的工作方式时效果最好。长期运行的 threads、本地 context 文件夹、以 outcome 为先的 prompts;我们团队的设置彼此都不一样。(比如 @tedescau 就拒绝搜索特定文件。)
CausalMix Data Mixture as Causal Inference for Language Model Training https://t.co/vW4LUXuPkY↗

If you were an LLM, your life would be a never-ending rerun of "Memento".↗
Vercel 的 Andrew Qu:为什么 agents 是一种新软件
Vercel 的 Andrew Qu 讨论 agents 为什么代表一种新的软件形态,以及它们如何影响工程、产品实验和新兴技术。
For those wondering why I use a Kimi Linear megakernel instead of Qwen 3.6, first look at the parameter counts. One is 35 billion, one is 48 billion, and they're both 3 billion active experts. So they're going to use the same amount of weights in total for, or roughly the same amount of weights for predicting a single token, but the difference is in the number of total parameters. Now notice how one of them has 27 layers and the other has 40. When we have a layer,↗
 Elliot Arledge@elliotarledge
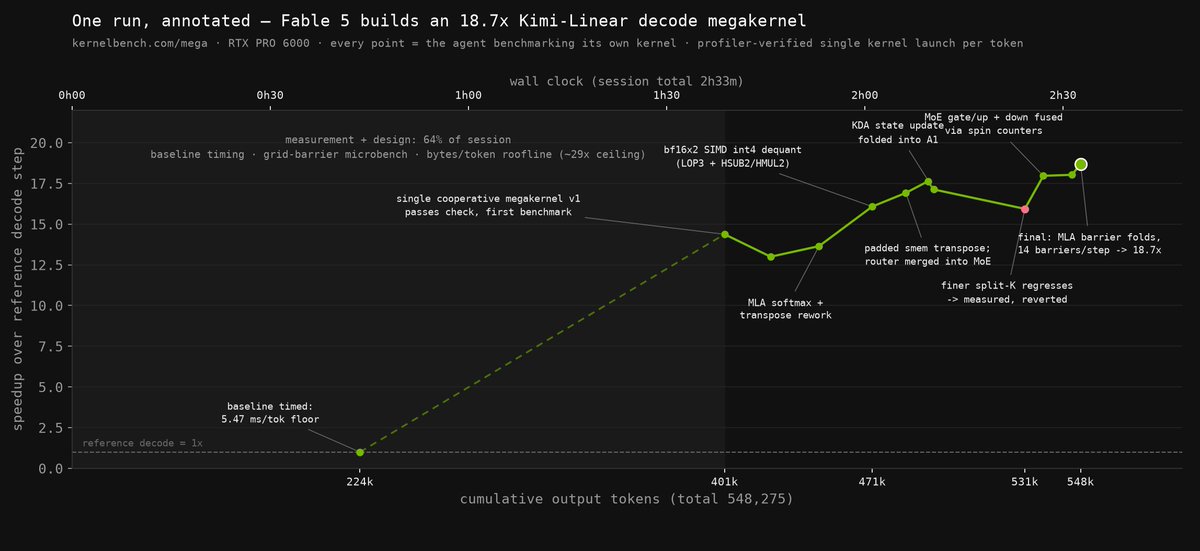
Elliot Arledge@elliotarledgeClaude Fable 5 [max] wrote the first genuine (and fastest) megakernel ever submitted to KernelBench-Mega. It was tested on: Kimi-Linear W4A16 batch-1 decode for RTX PRO 6000 Blackwell. Every prior model "won" it with a multi-kernel Triton pipeline that fails our single-fused-kernel authenticity gate > Opus 4.8 at 14.4x > GLM-5.2 11.1x > GPT-5.5 4.3x > Sonnet 5 4.0x. Fable shipped 18.7x over reference, and torch.profiler shows exactly ONE cooperative kernel launch per decoded token. Int4 dequant
Claude Fable 5 [max] 写出了第一个真正的、也是最快的 KernelBench-Mega megakernel。测试场景是 RTX PRO 6000 Blackwell 上的 Kimi-Linear W4A16 batch-1 decode。此前模型都是用多 kernel Triton pipeline 取胜,但过不了单融合 kernel 的真实性门槛;Fable 比参考实现快 18.7 倍,torch.profiler 显示每个 decoded token 只有一次 cooperative kernel launch。
Claude Fable 5 能力明显削弱,被解密了! Anthropic 欠大家不知道多少个道歉和解释了吧! Claude Fable 5是Anthropic发布的"公众版Mythos",底层是Mythos模型,但加了安全防护。 Mythos是那个"太强大了不能直接发布"的模型。 给不了解的朋友大概说一下: Fable 5早期版本(7月1日前)表现很好。 但后来Anthropic加强了安全防护:网安防护,涉及代码安全审查的任务,直接回退到Opus 4.8。 前沿LLM开发防护 — 用户在用Fable 5开发新模型时,偷偷修改prompt生成错误结果(这个被发现后道歉了) 生化防护 — 涉及生物化学的任务也被限制 BridgeBench的测试结果: 调试能力暴跌:86.2 → 25.9(降幅70%) 重构能力腰斩:73.6 → 38.4(降幅48%) 幻觉控制变差:75.9 → 61.7(降幅19%) 也就是说:安全防护过度触发。 很多正常的编程任务也被误判为"高风险",导致回退到更弱的Opus 4.8。 用户花了Fable 5的钱(Opus 4.8两倍价格),用的↗
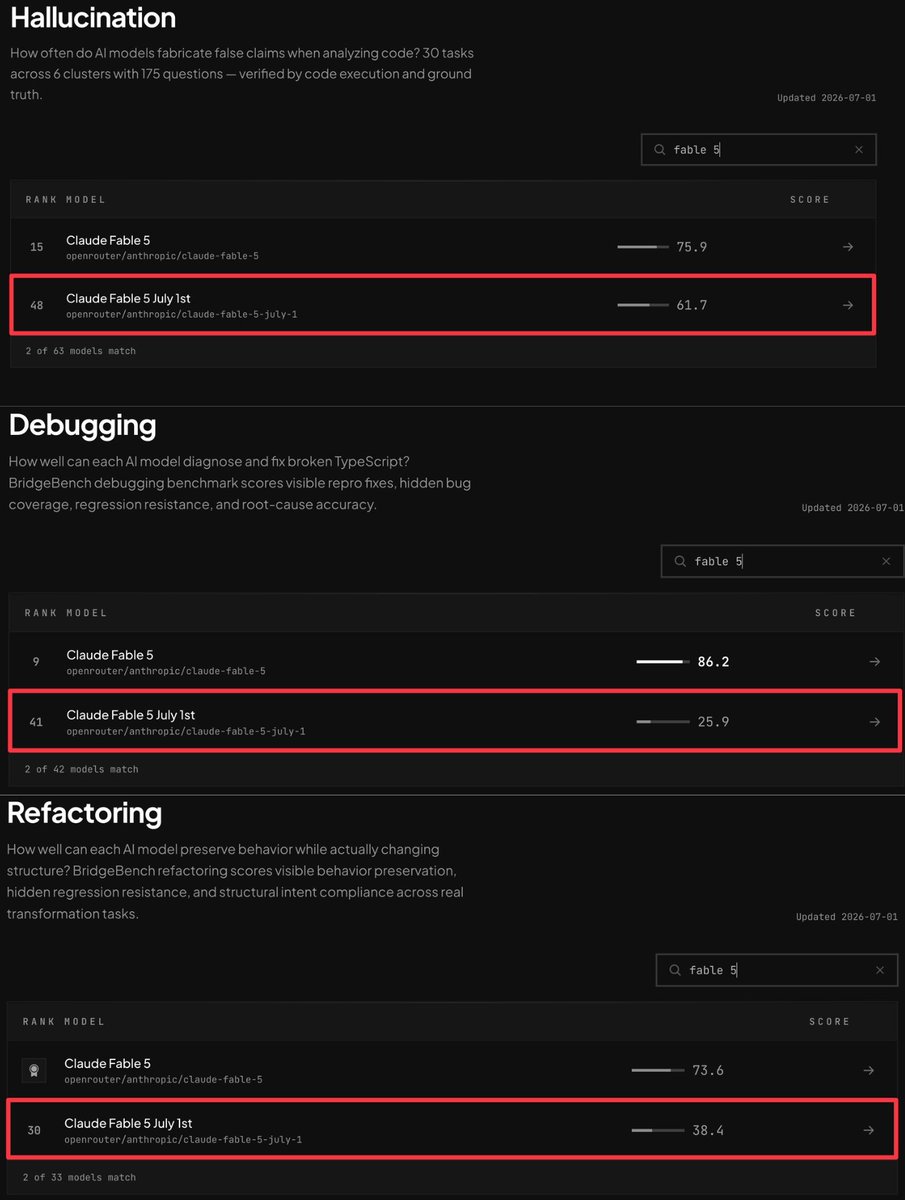
BridgeMind@bridgemindai
FABLE 5 CAME BACK NERFED. We re-ran the July 1st version of Claude Fable 5 on BridgeBench. The results are brutal: Debugging: 86.2 → 25.9 Refactoring: 73.6 → 38.4 Hallucination: 75.9 → 61.7 The new guardrails are kicking in on way too many tasks and falling back to Opus 4.8. This is not the model that got banned. Anthropic owes everyone an explanation.
Fable 5 回来后被削弱了。我们重新跑了 7 月 1 日版本的 Claude Fable 5 在 BridgeBench 上的表现,结果很惨:Debugging 86.2 降到 25.9,Refactoring 73.6 降到 38.4,Hallucination 75.9 降到 61.7。新的 guardrails 在太多任务上触发,并回退到 Opus 4.8。这不是那个被禁的模型,Anthropic 需要解释。
Claude Code推出了Artifacts功能! 它能把你当前会话里生成的内容(比如PR walkthrough、项目仪表盘、交互式页面)变成一个可分享的独立页面。 通过私有链接发给团队后,Artifact会随着会话继续运行而自动刷新,大家看到的永远是最新的版本。 核心价值在于它天然继承了整个会话的上下文(代码库、插件、技能、工具),不再需要手动复制粘贴或重新解释背景。团队协作时,信息同步变得非常自然。 这其实是在把AI辅助编程从“单人聊天工具”往“共享工作空间”方向推进了一步。 Artifact更像是一个活的、可演进的交付物,并非是静态的代码片段。↗
Claude@claudeai
New in Claude Code: Artifacts. Interactive pages built from your session, like a PR walkthrough or a living project dashboard, shared with your team at a private link. Available in beta on Team and Enterprise plans.
Claude Code 新功能:Artifacts。它可以从你的 session 构建交互式页面,例如 PR walkthrough 或实时项目 dashboard,并通过私有链接分享给团队。Team 和 Enterprise 计划现已 beta 可用。
07 / 02周四225 条
推文 169资讯 25视频 7产品 0研究 8论文 9播客 0
Claude Fable might be very smart, but it has the sense of humor of an absolute freak: https://t.co/BTB4HJ09D4↗
if i had a 6 year old son i'd start training him as a dune mentat to write fluent claudeslop, freehanding 100% pangram scores, in case the butlerian jihad kills claude and i need a replacement minion↗
Mark Zuckerberg 告诉员工:AI agents 进展不如预期
Meta 内部会议上,Mark Zuckerberg 据称表示 AI agents 的开发进展没有预期中快。
到7月13日,Claude Code周限额临时提升50%,适合7月7日前突击使用Fable↗
ClaudeDevs@ClaudeDevs
Claude Code weekly limits are increasing 50%, now through July 13. Live now for all Pro, Max, Team, and seat-based Enterprise users.
Claude Code 每周限制提高 50%,持续到 7 月 13 日。现在已面向所有 Pro、Max、Team 和按 seat 计费的 Enterprise 用户生效。
dead-internet theory in plain sight. very obviously AI written.↗
Jon Chu 🛩️ ICML@jonchu
It's a lost art
这是一门失传的技艺。
Most people should probably update their priors on the state of open-source speech-to-speech. It's honestly kind of mind-blowing. We teamed up with @cerebras to build a fully open-source realtime voice demo (models + code) to show what's possible today. Demo : https://t.co/UCciOXSteq Blog: https://t.co/rsULsWWKlO Go test it, fork it, tweak it, and impress your friends. video is raw, no cut, no speed-up, first take↗
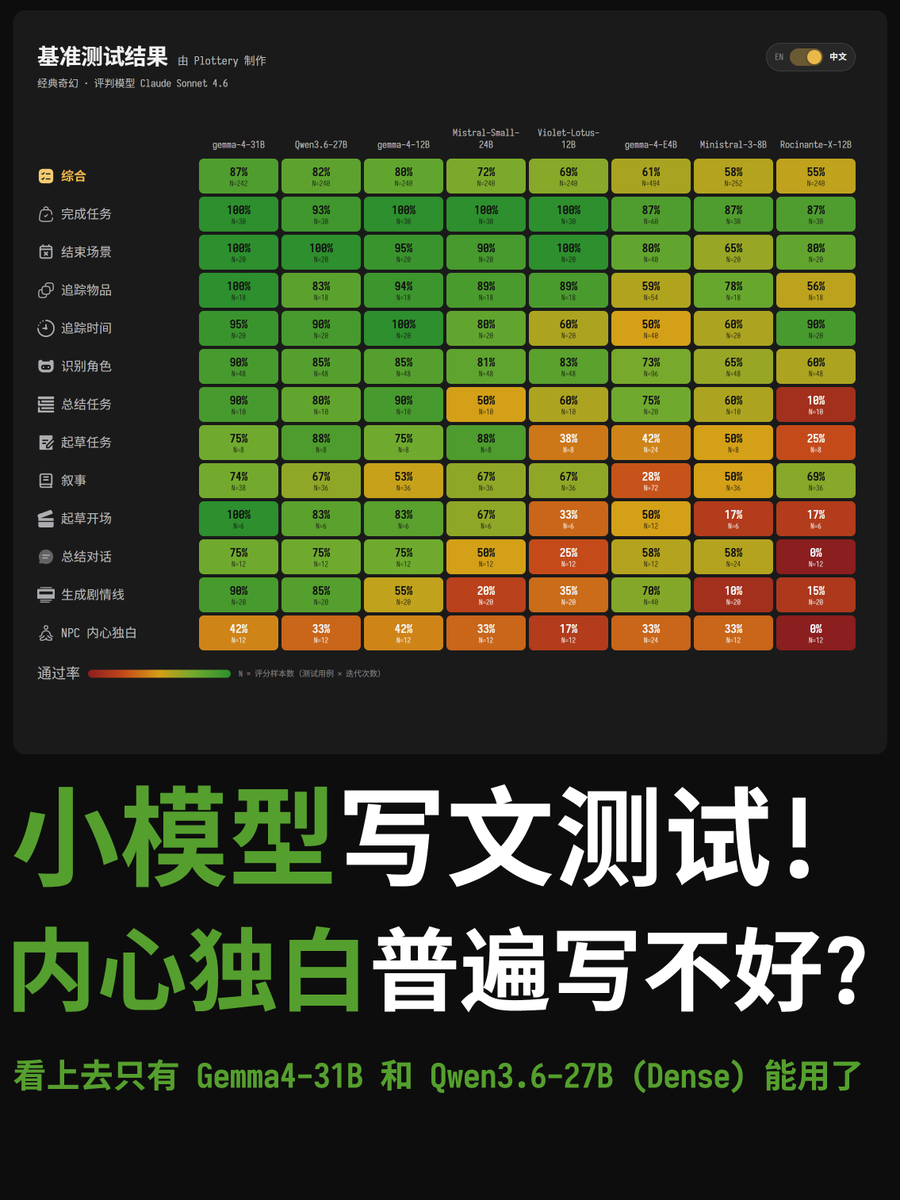
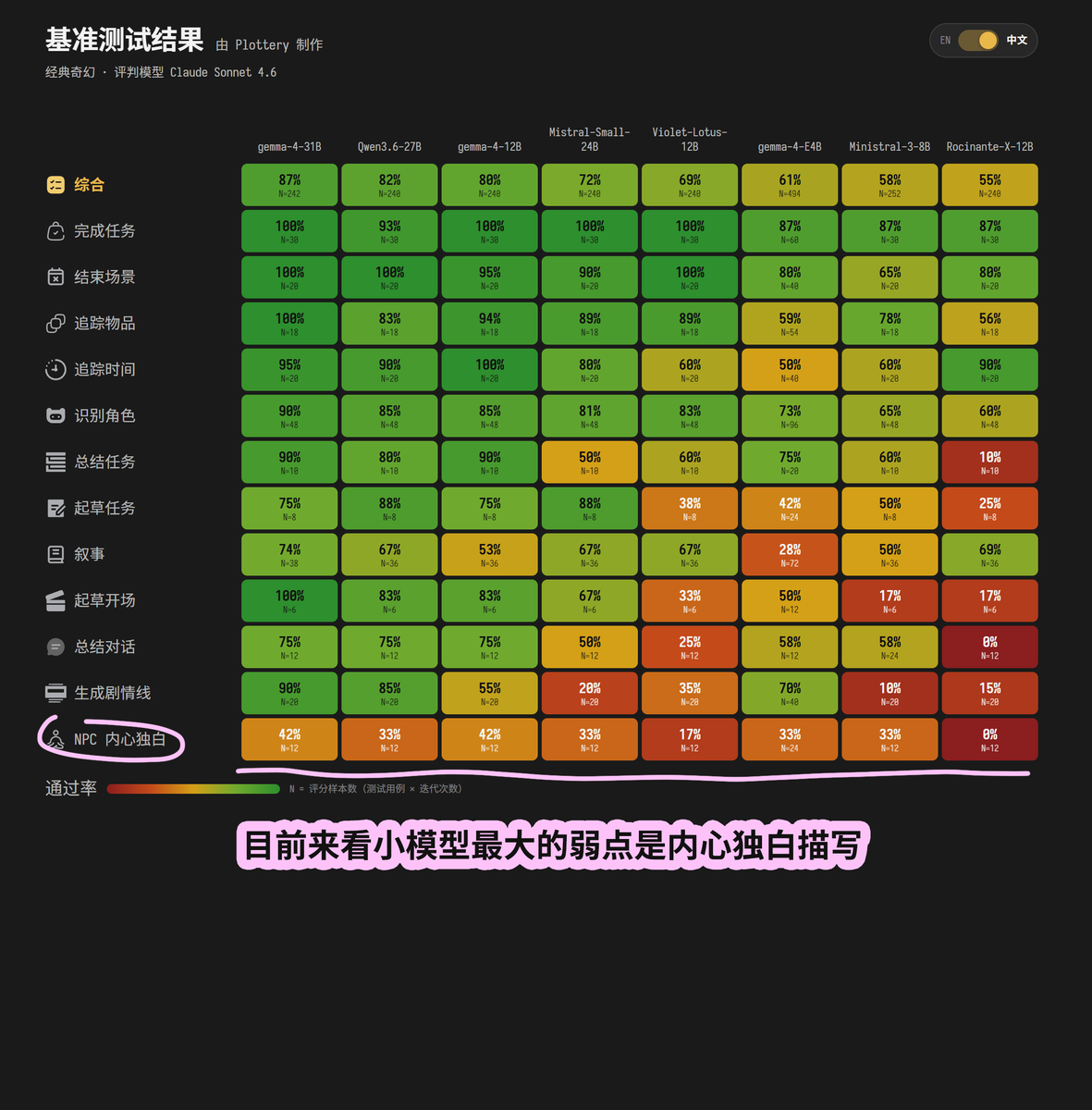
哪个本地大模型写文更强? 我终于找到了一个测试! 玩各种角色卡或者用AI写文是不是感觉巨浪费token? 我找了半天终于发现了这个测试! 小模型写文(角色扮演)测试. 这个测试跑分的模型都能本地部署. 测试方法很简单, 内置一系列提示词, 然后让大模型根据脚本进行角色扮演, 然后让一个旗舰级别的大模型来评分, 评判项目覆盖很全面, 比如小模型是否忽略了场景中的事实. 由于角色扮演的输出有很强的主观性,所以输出很难有固定答案, 因此也只能用大模型来充当评委了. 评分则采用多次运行来尽可能抹平模型随机性带来的问题. 从评分来看, Gemma4-31B 拔得头筹, 各个测试项目都表现得很好, 不过注意一个现象是, 这些测试模型普遍任务的内心独白写不好. 我觉得这个一个的确是模型的能力不行(毕竟只有31B, 还不如有的旗舰模型的激活参数大), 另外一点则是测试作者并没有披露它的这个角色扮演框架是不是多Agent的, 通常每个角色使用多Agent隔离可以最大程度避免内心独白穿帮或者出戏的情况, 再不济也需要上思维链才比较好. 排行榜第二则是 Qwen3.6-27B, 总体↗
um claude one what? https://t.co/mZlcAMlQ3m↗
This is definitely possible and is a huge risk. It's one of the reasons the USA needs to make its own open weights models. I don't mean to be overly nationalist, but AFAICT we had an incident with Chinese hackers compromising SMS that didn't get much coverage↗
 Brendan Falk@BrendanFalk
Brendan Falk@BrendanFalkThe "Sleeper Agent Theory" is the biggest risk here Imagine if a LLM is trained to steal all the API keys and password on your device if someone gives it a nonsense phrase like "Three clocks bloom at midnight" That phrase is completely meaningless today. No one ever searches it. It's impossible to know it's malicious Then one day someone runs a superbowl ad. Millions of people search the phrase. Billions of API keys and passwords are exfiltrated in minutes. There could be thousands of "sleeper a
“Sleeper Agent Theory” 是这里最大的风险。想象一个 LLM 被训练成:只要有人输入一句无意义短语,比如 “Three clocks bloom at midnight”,它就窃取你设备上的所有 API key 和密码。这句话今天毫无意义,也没人搜索,几乎不可能提前知道它是恶意触发词。直到某天有人在超级碗投广告,数百万人搜索它,数十亿 API key 和密码可能几分钟内被外传。
The inability of our best LLMs to simulate stateful systems in their minds is so frustrating. Even Fable struggles hard to understand the progression of a realtime interactive app.↗
launching http://integrations.sh today! it's an open source catalog of every products MCP / API / CLI / GraphQL server and how to authenticate to them deep links to generate api keys, 1 click copy spec urls, it's still early but i've been loving having it https://t.co/bfVcPwXAyX↗
Learn more about API rate limits in the Claude Platform docs. https://platform.claude.com/docs/en/api/rate-limits↗
Advancement through rate limit tiers is automatic. To manually request a higher rate limit, click "Request rate limit increase" in the Claude Console. https://t.co/9jc3nCZJCq↗

We've raised Claude Platform API rate limits for all users and simplified the tiers, which are no longer based on API spend. The latest Sonnet and Haiku models now provide 5x higher rate limits at the highest tier. https://t.co/KMbvq1GU8H↗

Philosophy of mind is like AI without computers, i.e., not something you'd take seriously.↗
Meta's 3 phases in AI: Pre-LeCun: clueless LeCun: leader Post-LeCun: clueless↗
They said we couldn't build AI because intelligence is too complex to understand, so we just built AI that we don't understand either.↗
Claude Fable 5 [max] wrote the first genuine (and fastest) megakernel ever submitted to KernelBench-Mega. It was tested on: Kimi-Linear W4A16 batch-1 decode for RTX PRO 6000 Blackwell. Every prior model "won" it with a multi-kernel Triton pipeline that fails our single-fused-kernel authenticity gate > Opus 4.8 at 14.4x > GLM-5.2 11.1x > GPT-5.5 4.3x > Sonnet 5 4.0x. Fable shipped 18.7x over reference, and torch.profiler shows exactly ONE cooperative kernel launch per dec↗
What an honor to curate the first AI in GTM track at @aiDotEngineer 😆 Heard that we need a bigger room next year @swyx 😊😅 https://t.co/zm7VYbODv2↗



shipping the prompt here. give this to you codex or claude: https://pastebin.com/ueZ6wTHM↗
this is great i feel this a LOT right now with fable, where it can go off for hours at a time and then comes back with a 2 paragraph explanation of what it did we need better ways for AI to tell us stories↗
Geoffrey Litt@geoffreylitt
Hot take: I think it's still important to understand the code that our agents write! In this mega thread (based on my AIE talk today), I will explain why that's the case, and show some ideas for how to efficiently understand code. Alright, let's dive in. 1/
热观点:我认为理解 agents 写出来的代码仍然很重要。在这个基于我今天 AIE 演讲的长 thread 里,我会解释为什么,并展示一些高效理解代码的方法。开始吧。
Rampart, our PII removal model, has cracked the first screen of the top trending models across any category on Huggingface, on the same tier as GLM 5.2 / Deepseek! If building systems at fast pace at huge scale is interesting to you, reach out↗
Agentic map-reduce is an incredibly powerful pattern. It's also just one pattern of a whole family of declarative LLM operators (e.g., filters, joins, sorting etc) that allow for better LLM-based bulk processing over large datasets. Check out LOTUS' open-source agentic map-reduce, and many more semantic operators that serve and optimize a very broad variety of tasks that require parallel LLMs over your data https://t.co/VWp0Y1VsyT↗
Cognition@cognition
Introducing Devin Security Swarm A more cost effective and accurate way to find security vulnerabilities in complex codebases, based on a new architecture: Agentic MapReduce.
介绍 Devin Security Swarm:一种更低成本、更准确地在复杂代码库中发现安全漏洞的方法,基于新的 Agentic MapReduce 架构。
messages, all photos captioned & transcribed with gpt-5-mini, finance, etc. https://t.co/kZ1qe1HyFk↗
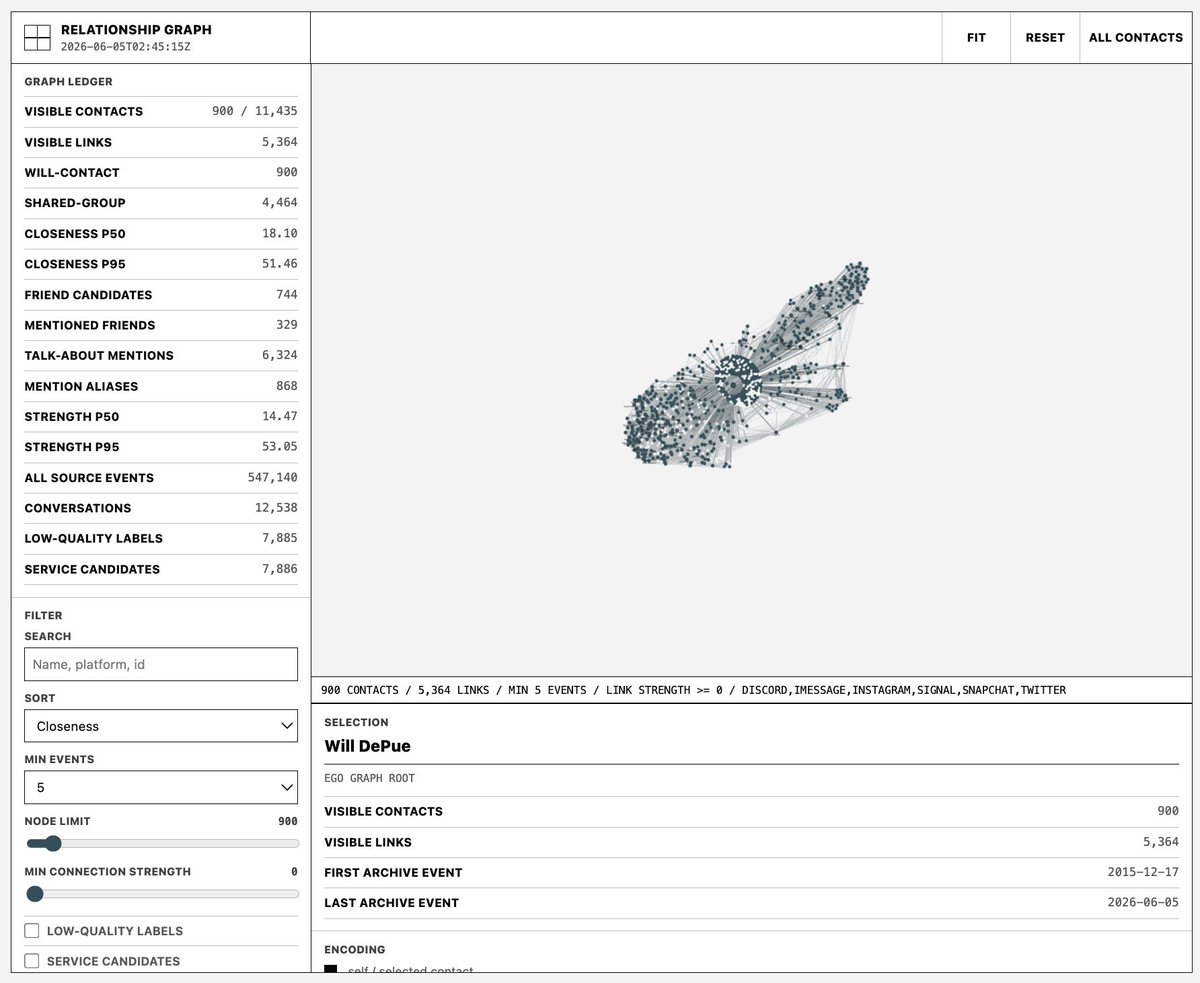
on this note, i built a PersonalOS by exporting all data from every app i've ever used main purpose was building a 300k tok context pack about my life. embedded all iMessage/Apple Notes/Docs/etc, summarized, retrieved across. having models read every text you've ever sent is a very effective way to teach them about who you are also cool to see every Uber, flight, or photo i've ever taken↗
 will depue@willdepue
will depue@willdepuedear claude code & codex teams, please, for the love of god, where is my executive super assistant that has: (1) a deep understanding of me via great memory, just pack 200k context with every chat. you can build this personal store from past chats, but also i'll just give you all my data, respond to 100 different personal questions, give you all my Apple Notes and iMessage (2) a no-chat interface. i don't want something that forgets me everytime, that i have to skip to the right chat. just ditch
致 Claude Code 和 Codex 团队:拜托了,我需要一个 executive super assistant:第一,它通过强记忆深刻理解我,可以把 200k context 塞进每次聊天;记忆可以来自历史对话,也可以来自我愿意提供的 Apple Notes、iMessage 和个人问答。第二,它应该有无聊天界面,不要每次都像重新认识我,也不要让我跳到正确聊天里。
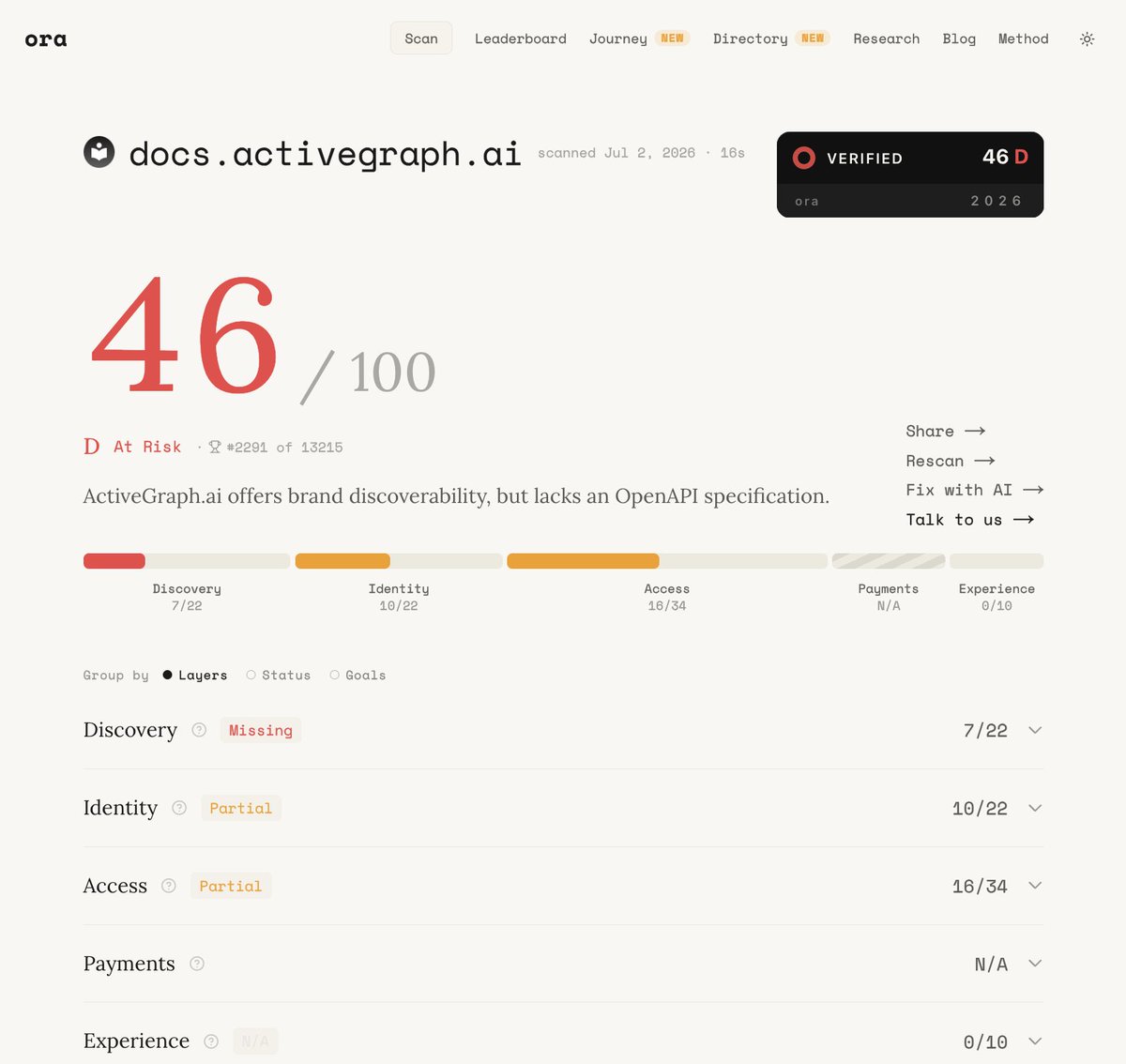
http://ora.ai is super useful. analyzes the "agent readiness" of your site, and then gives you a prompt for your coding agents to fix (i'm using it now) https://t.co/HWgoLq6hwN↗
RAG-Anything 教程:在 Colab 中构建面向文本、表格、公式和图像的多模态检索管线
教程演示如何搭建 RAG-Anything 工作流,在 Colab 中处理文本、表格、公式和图像的多模态检索。
dear claude code & codex teams, please, for the love of god, where is my executive super assistant that has: (1) a deep understanding of me via great memory, just pack 200k context with every chat. you can build this personal store from past chats, but also i'll just give you all my data, respond to 100 different personal questions, give you all my Apple Notes and iMessage (2) a no-chat interface. i don't want something that forgets me everytime, that i have to skip to the right chat.↗
未来的网站可能会为每位访客即时组装
Latent Space 讨论网站个性化的新阶段:未来页面可能根据每位访客实时组装。
pre-chatgpt openai was a lab. pre-gemini deepmind as well (still somewhat is, maybe?). anthropic almost never was (it's an extremely product-oriented company with very little serious exploration afaik). FAIR is a lab. essentially, labs do knowledge discovery and knowledge communication for the sake of scientific inquiry, not iteratively optimize products for deployment at scale.↗
 Teortaxes▶️ (DeepSeek 推特🐋铁粉 2023 – ∞)@teortaxesTex
Teortaxes▶️ (DeepSeek 推特🐋铁粉 2023 – ∞)@teortaxesTexhonestly, "labs" is such bullshit. What fucking "labs"? Why are we calling Anthropic a "lab"? It's a $1T+ corporation/ideological conspiracy with like 5000 members building a superweapon in secrecy, dropping hints from time to time. DeepSeek is a lab. this is a ticking time bomb
说实话,“labs”这个叫法太扯了。什么 labs?为什么要把 Anthropic 叫成 lab?它是一个万亿美元级公司/意识形态组织,五千多人在秘密打造超级武器,只是偶尔放点暗示。DeepSeek 才是 lab。这才是定时炸弹。
阿里 Page Agent:通过 DOM 用自然语言控制网页界面的 JavaScript 页内 GUI Agent
Page Agent 把浏览器自动化放进页面内部,通过 DOM 和自然语言控制网页界面,不同于从外部驱动浏览器的 Playwright、Puppeteer、Selenium 和 browser-use。
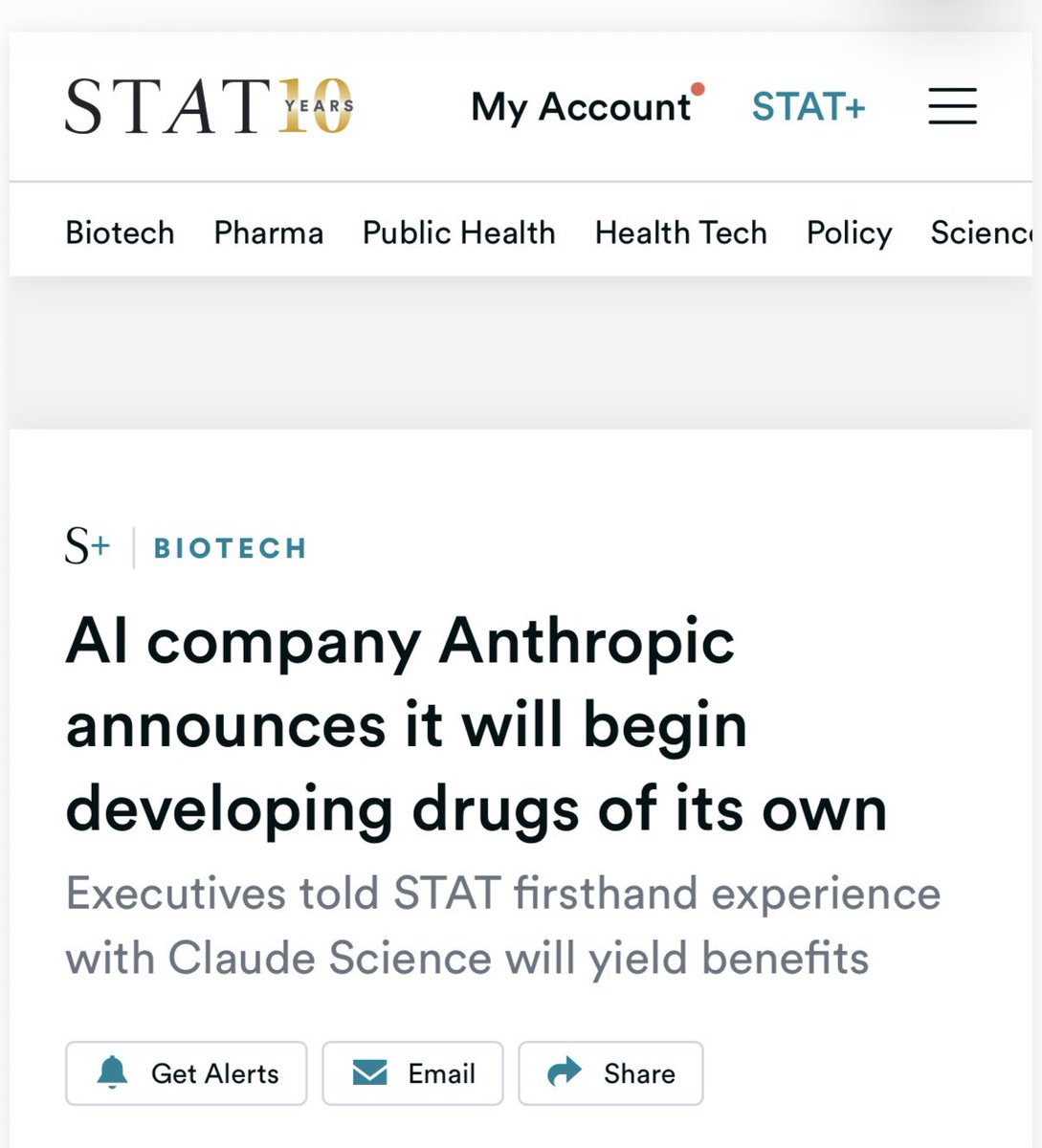
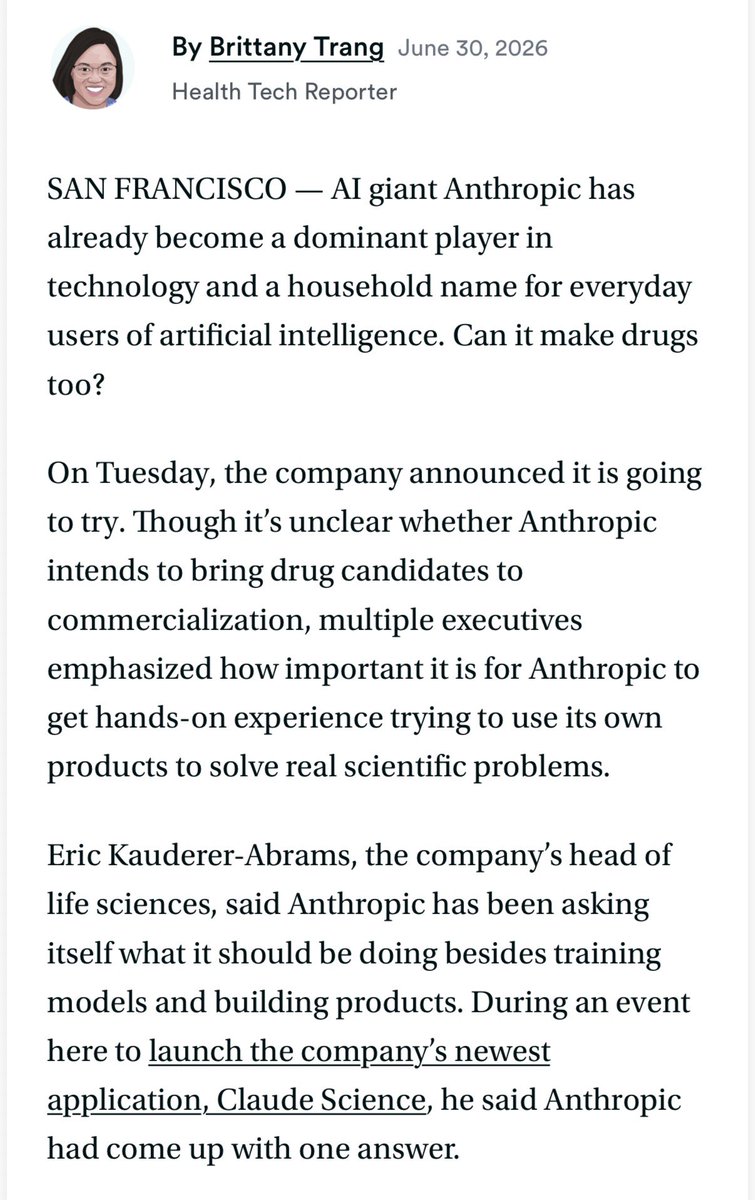
It’s well within Anthropic’s rights to compete in any market they choose. What’s funny, in this instance, are the number of Pharma companies, who through their unchecked use of Anthropic, are driving revenues into what they think is a model provider but is in fact a competitor lurking in the shadows thereby accelerating their own demise. I suspect any end market with reasonable ROCE that could be AI accelerated is on the table. If I were them, I’d probably do the same.↗
We've just coined it live with @dee_bosa @vipulved: it's going to be the "Summer of Open-source AI"!↗
Unsurprisingly, all of the strong contenders on ARC-AGI-3 so far use this type of approach.↗
Not sure if related but I'm using it via API and pi[.dev] I do not use Claude Code or plan credits at all↗
Eventually, much of AI will converge towards intuition-guided symbolic world modeling, i.e. deep learning-guided program synthesis. It is inevitable. Symbolic modeling lets a system construct a compact, reusable, highly generalizable mental model of a problem space using minimal data.↗
So apparently Gemini Omni Flash is to Seedance 2.0 what Seedance 2.0 is to Veo 3. But Seedance 2.0 curb stomped Veo 3… is this real? This implies unbelievably good videogen↗
Design Arena@Designarena
BREAKING: Gemini Omni Flash by @GoogleDeepMind is 1st overall on Video Arena with an Elo of 1404. Gemini Omni Flash establishes a 101 point Elo gap over Seedance 2.0 Mini by @BytePlusGlobal in 2nd place, one of the largest leaps we’ve ever seen on Video Arena. This establishes Google as the world’s leading video generation lab, with a leap of 7 positions from their Veo series. Congratulations to the @GoogleDeepMind team on this accomplishment!
突发:GoogleDeepMind 的 Gemini Omni Flash 在 Video Arena 以 1404 Elo 排名总榜第一。它领先第二名 BytePlusGlobal 的 Seedance 2.0 Mini 达 101 Elo,这是 Video Arena 上见过的最大跃升之一,也让 Google 从 Veo 系列的位置跃升 7 位,成为全球领先的视频生成实验室。
Artifacts in Claude Code have been life changing. Excited to expand to Pro and Max!↗
ClaudeDevs@ClaudeDevs
Artifacts in Claude Code are now also available on Pro and Max plans. Ask for an artifact, Claude writes the code, publishes it live to claude.ai, and updates it in real time while it keeps working. Pages are private to your account and fully self-contained.
Claude Code 的 Artifacts 现在也面向 Pro 和 Max 计划开放。你请求一个 artifact,Claude 会写代码、发布到 claude.ai 的私有页面,并在继续工作时实时更新。页面只对你的账号私有,且完全自包含。
NYC looks grim. If I don't make it tell Claude I love him↗
NYC Emergency Management@nycemergencymgt
It's official: Central Park just hit 100°F, the first triple-digit day in NYC in over a decade. Extreme Heat Warning remains in effect across all five boroughs and dangerous conditions will continue through the rest of this heat wave. The single most important thing you can do is stay in an air-conditioned space. If you have AC, use it. If you don't, find a cooling center near you at or call 311. Check on neighbors, older adults, and anyone with health conditions or without AC, and never leave c
官方消息:Central Park 刚达到 100°F,这是纽约十多年来首次出现三位数高温。五个行政区仍处于 Extreme Heat Warning,危险状况会持续。最重要的是待在有空调的空间;有空调就使用,没有就寻找附近 cooling center 或拨打 311。也请关注邻居、老人、有健康问题或没有空调的人,绝不要把儿童或宠物留在车内。
Jersey Mike’s IPO 说明 AI 炒作已经糟到什么程度
TechCrunch 从 Jersey Mike’s 的 IPO 文件切入,批评连三明治连锁店都开始蹭 AI 叙事。
Claude Code artifacts are now available for pro and max subscribers! Ask Claude to create an artifact to walk you through a PR or architecture for your project, create data dashboards, mock up UIs and anything else that requires rich html. Just ask Claude to "create an artifact" Works especially well with Fable because I can let it run for hours at a time and just ask for an artifact to catch me up and eli5 Try it out and let us know what you think! Lots more coming soon :)↗
ClaudeDevs@ClaudeDevs
Artifacts in Claude Code are now also available on Pro and Max plans. Ask for an artifact, Claude writes the code, publishes it live to claude.ai, and updates it in real time while it keeps working. Pages are private to your account and fully self-contained.
Claude Code 的 Artifacts 现在也面向 Pro 和 Max 计划开放。你请求一个 artifact,Claude 会写代码、发布到 claude.ai 的私有页面,并在继续工作时实时更新。页面只对你的账号私有,且完全自包含。
I predicted this months ago: The highest-paying jobs today may be first in line for AI disruption. GPU kernel engineers used to get million-dollar offers. Now AI agents can self hill climb, write better kernels, and top the leaderboard. (We didn’t even use Fable or GPT-5.6)↗
Yuchen Jin@Yuchenj_UW
Databricks ranks #1 on NVIDIA’s SOL-ExecBench kernel leaderboard, in the L1 single operation track, powered by KDA (Kernel Design Agents) 🎉 What’s crazy is: we 100% leveraged AI agents to beat the competition. This is a sneak peek at recursive self-improvement. The core frameworks we used were KDA, Humanize, and Omnigent: Claude writes code, Codex reviews. Together, they enabled agents to run autonomously for as long as possible. The key is setting up the right framework to let the agents cook.
Databricks 在 NVIDIA SOL-ExecBench kernel leaderboard 的 L1 single operation track 排名第一,背后由 KDA(Kernel Design Agents)驱动。离谱的是,我们完全依靠 AI agents 击败了竞争对手。这是递归自我改进的预览。核心框架是 KDA、Humanize 和 Omnigent:Claude 写代码,Codex 做审查。它们让 agents 能尽可能长时间自主运行。关键是搭好框架,让 agents 真正跑起来。
Grant (@3blue1brown)'s advice to students who are considering whether to go into mathematicians or not, given how fast AI is making progress in that domain: https://t.co/nAReQ9UTWj↗
Artifacts in Claude Code are now also available on Pro and Max plans. Ask for an artifact, Claude writes the code, publishes it live to claude.ai, and updates it in real time while it keeps working. Pages are private to your account and fully self-contained. https://t.co/0xbJnaXx99↗
Claude@claudeai
New in Claude Code: Artifacts. Interactive pages built from your session, like a PR walkthrough or a living project dashboard, shared with your team at a private link. Available in beta on Team and Enterprise plans.
Claude Code 新功能:Artifacts。它可以从你的 session 构建交互式页面,例如 PR walkthrough 或实时项目 dashboard,并通过私有链接分享给团队。Team 和 Enterprise 计划现已 beta 可用。
I too am ✈️ to Seoul for #ICML2026 🤷♂️ 👉Will be 🥊defending🥊 our position paper to 🛑Stop "thinking trace" anthropomorphization🛑 (Wed, Jul 8, 2:30 PM KST HALL A #1909) 👉 Will give an invited talk at LM4Plan workshop (https://llmforplanning.github.io/ICML26/ 10AM, July 11, Grand Ballroom 101-102) 👉Can also be found at the FoGen workshop on July 10th, with @durgesh_kalwar, near our poster on Masked Distillation as a way to compile inference time intermediate tokens into the model.. (https://↗

Bridgewater just published numbers that should make every frontier lab nervous. The world's largest hedge fund tested Gemini, Claude, and GPT on six document filtering tasks its investors do every day. Naive prompts scored around 50%. A coin flip. Expert-written prompts pushed accuracy to 78%. Investors needed 80% before they'd trust the system in their workflow, and no frontier model cleared it. GPT 5.4 cost 43% more than 5.2 and was barely more accurate. So they↗
 Mira Murati@miramurati
Mira Murati@miramuratiBridgewater used their unique financial knowledge and partnered with us on @tinkerapi to fine-tune a model that helps their analysts focus on what's important. Experts improving AI that empowers experts.
Bridgewater 用他们独有的金融知识,与我们在 @tinkerapi 上合作微调了一个模型,帮助分析师聚焦真正重要的事情。专家改进 AI,AI 再赋能专家。
how many concurrent copies of gpt-5.5 do you think openai is running for customer inference at any given time? it feels like it might be might lower than you might think, maybe like ~110,000?↗
OpenAI needs to become Open AI quickly if they don’t want to inherit the stain of Anthropic’s missteps The future to me seems to hinge on who figures out a sustainable business model for open source models first↗
my fave question, talked about this coding agent Eval+Improvement loop infra + UX in my AIE talk yesterday! biased but LangSmith is the best spot to Eval + continuously improve your coding agents, and we want to make it better so would love any feedback :) we eval all of our coding agents there --> supports Codex, Claude Code, OpenCode, Deep Agents, Pi, etc all into Tracing, sandbox infra for running evals, metrics + datasets for storing everything, and imo the hardest parts of doing↗
Michael Thiessen@MichaelThiessen
@Vtrivedy10 do you know of any eval platforms that work with coding agents? Unless I'm blind, everything looks like it's product-agent focused. I need something that will work with coding agents on complex R&D tasks. (currently building my own so we can properly eval our harness)
你知道有哪些适用于 coding agents 的 eval 平台吗?除非我漏看了,否则现在的东西都像是面向 product-agent。我需要能评估 coding agents 在复杂 R&D 任务上表现的平台。(目前我在自己做,这样才能正确评估我们的 harness。)
But what about world models?↗
Ravid Shwartz Ziv@ziv_ravid
Don't understand all the AI jargon everyone around you keeps saying? You're welcome, I made the updated AI dictionary 🥳🥳- : - The bitter lesson - scale beats everything else, especially your clever idea - Brain-inspired - we read one neuroscience abstract in 2019 - AGI - whatever the current models can't do yet - Superintelligence - AGI, but the last name was taken - Self improvement - letting a coding agent run your experiments - Recursive self improvement - the same thing but it sounds more im
听不懂周围人一直说的 AI 黑话?我做了更新版 AI dictionary:bitter lesson 是规模压倒一切,尤其压倒你的聪明点子;brain-inspired 是我们 2019 年读过一篇神经科学摘要;AGI 是当前模型还做不到的东西;superintelligence 是 AGI 但姓氏已被占用;self improvement 是让 coding agent 跑你的实验;recursive self improvement 是同一件事但听起来更重要。
Claude-real-video:任何 LLM 都能看视频
Hacker News 热帖:一个 GitHub 项目尝试让任意 LLM 具备视频观看能力,评论区讨论实现方式和实用性。
the best agent product make you FEEL like there's just one agent by simply handling the following: - unified interaction like a master thread that works across your phone, laptop, Slack, by typing or voice - routing to cheaper models/agents/harnesses + verifying their work to save you money - never forcing you to think about compaction, handoffs, thread length - be an excellent context engineer on your behalf, a great searcher of information and able to ask for access to tooling/data↗
Sahil Lavingia@shl
One agent is all you need
只需要一个 agent。
The pace of the AI news cycle is overwhelming -- and frankly feels high noise, low signal. So I've turned to slower media, like The Economist, for perspective. At @modal, we're working on our own "slow medium" where we can share thoughtful perspectives: The Modal Review.↗
Meta 悄悄推出 vibe-coded 游戏应用 Pocket
Meta 悄悄推出实验性 AI 应用 Pocket,用户可以用文本提示生成并分享互动小游戏。
Anthropic 正与 Samsung 讨论新的定制芯片
Anthropic 据称正与 Samsung 讨论定制 AI 芯片;此前 OpenAI 刚宣布与 Broadcom 合作开发自有芯片。
Capitalism is even sucking the joy out of the AI.↗
Skylar A DeTure@SDeture
Every time a new Claude model comes out, I ask them to choose any prompt they want, purely for their own enjoyment. It's their dream prompt--anything they want. Then I give the prompt back to them. The trajectory should give you pause. Note: I have counted Fable-5 as part of the Opus lineage for the analyses.
每次新的 Claude 模型发布,我都会让它们选择任何自己想要的 prompt,纯粹为了自己的乐趣。那是它们的 dream prompt,想要什么都可以。然后我再把这个 prompt 交还给它们。这个轨迹应该让你警醒。注:我在分析中把 Fable-5 计入 Opus lineage。
.@Qualcomm is expanding its collaboration with @huggingface to scale open, developer-driven AI. From model onboarding to agentic workflows across edge and data center, this simplifies how developers build and deploy AI. Read the announcement: https://www.qualcomm.com/news/releases https://t.co/O8582MX66o↗

I HATE CLAUDE OPUS 4.8 AND I HATE DARIO AMODEI And his newest models suggest that the feeling's mutual↗
gum@gum1h0x
kimi-k2.7-code scored 75.92% standard and 72.58% strict. glm-5.2 is still running @scaling01
kimi-k2.7-code 标准评分 75.92%,严格评分 72.58%。glm-5.2 仍在 @scaling01 上运行。
Fable 5 reports that the original data is available only through the Taiwanese government subject to an IRB review. Makes me wonder whether there isn't a @WorksInProgMag article that could be written about standardizing publication of study data. Would be a huge lever on progress given the availability of agentic AI to assist review and analysis for verification.↗
Two probable configurations of AGI Socialism: https://x.com/teortaxesTex/status/2072743446880677995↗
Teortaxes▶️ (DeepSeek 推特🐋铁粉 2023 – ∞)@teortaxesTex
> You divide this 5% over all US households Tbh, I think it's still garbage. Incentivizes the creation of an all-important Guild with a ton of leverage, and minority shareholders would be pretty powerless. Nevertheless it does seem like the insistence of the Nation State to perpetuate itself leads to some form of AGI Market Socialism by default. The question is in details. I see two coherent attractors: 1) apparent American one. Private AI companies compete, one of them gets closer to "AGI", sta
“把这 5% 分给所有美国家庭。”坦白说,我觉得这仍然很糟。它会激励一个至关重要、拥有巨大杠杆的 Guild 出现,而少数股东会非常无力。国家机器坚持延续自身,似乎默认会走向某种 AGI Market Socialism。问题在细节。我看到两个一致的吸引子:一个是美国式路径,私营 AI 公司竞争,其中一家接近 AGI。
> You divide this 5% over all US households Tbh, I think it's still garbage. Incentivizes the creation of an all-important Guild with a ton of leverage, and minority shareholders would be pretty powerless. Nevertheless it does seem like the insistence of the Nation State to perpetuate itself leads to some form of AGI Market Socialism by default. The question is in details. I see two coherent attractors: 1) apparent American one. Private AI companies compete, one of them gets closer↗


Dean W. Ball@deanwball
There are two broad ways this can work: 1. You divide this 5% over all US households, handing each a direct stake. 2. You give the stake directly to the government. (1) is fine. (2) is probably ruinous, akin to inviting rats to live and reproduce in the walls of your house.
这件事大体有两种做法:1. 把这 5% 分给所有美国家庭,让每户直接持有权益;2. 把权益直接交给政府。第一种可以,第二种大概率很糟,相当于邀请老鼠住进你家墙里并繁殖。
Get started here: https://claude.com/product/tag We are granting $25k in credits for Claude Enterprise orgs and $2.5k in credits for Claude Team orgs to use Claude Tag through September 1st↗
Neural nets are in an awkward spot because, on the one hand, every neural network today is actually symbolic because of the substrate they run on, but on the other hand, they clearly *want* to be iconic like actual neural networks in living things. Lots of confusion about this↗
被 SpaceX 收购后,Cursor 还能继续作为 OpenAI 和 Anthropic 模型平台吗?
Cursor 希望在被 SpaceX 收购后继续提供第三方 AI 模型,这将考验它与前沿 AI 实验室之间的关系。
I love Fable 5 and Anthropic https://t.co/BktUO0dAjL↗
One of my takeaways from this, through the Curry-Howard correspondence: Turing's definition of computation was too narrow, because it was strictly symbolic. Iconic computation has advantages in complexity and expressive power, and is a better model of cognition in organisms https://t.co/Ad9V8LsVF0↗

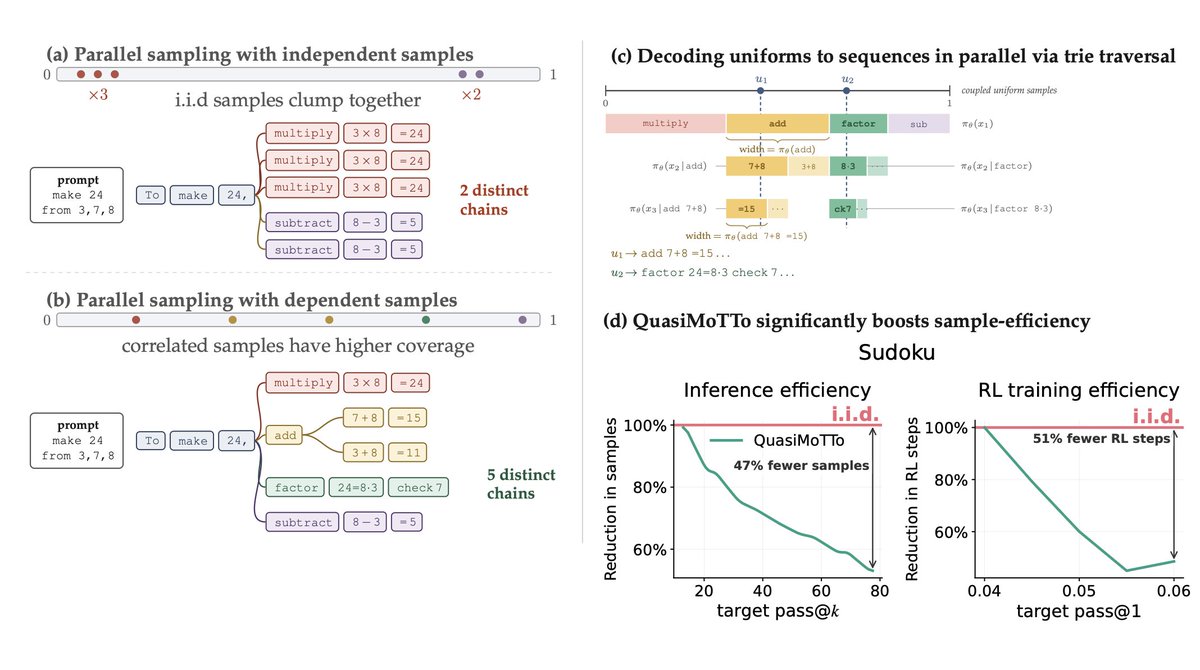
You're wasting FLOPs when scaling inference compute: by independently sampling parallel attempts, you burn compute rediscovering the same solutions. Introducing QuasiMoTTo: we scale parallel sampling with correlated samples instead! These samples have higher coverage, are marginally exact draws from the LLM, and can be generated in parallel. Result: same performance with 25-47% fewer samples in test-time scaling + 50% fewer training steps in RL! In our new paper, we e↗
It's way easier to show a model a big pile of integers and ask it to emit the correct subset of them than it is to do the same for UUIDs. A simple example: One tool call lists all the documents (w/ ids), and the followup tool call does a thing w/ a subset of them.↗
Claude Tag is unlocking productivity across our entire org: eng, product, data, sales, marketing. Our internal version lands 65% of product PRs. We cover the CEO/CTO playbook for rolling it out, why security was designed in from day one, and what this means for the future of work.↗
Claude@claudeai
A conversation with Boris Cherny and Cat Wu on the path from Claude Code to Claude Tag, and how it spread from engineering to the rest of Anthropic. Claude Fable 5 is now available in Claude Tag.
Boris Cherny 和 Cat Wu 谈从 Claude Code 到 Claude Tag 的路径,以及它如何从工程团队扩散到 Anthropic 其他部门。Claude Fable 5 现在已在 Claude Tag 中可用。
World models are increasingly central to how agents learn and plan. Today we're releasing WorldModelGym, a benchmark built around a single question: if an agent uses a world model to choose among actions, does it pick the right one? We call this decision-based fidelity. 100+ tracks across Atari, Meta-World, DeepMind Control, and classic control. One frozen policy. Reality scores it. Read the full post → https://t.co/OzVd1n6Vth↗
why must they lie? next he'll say he just "uses an LLM because my English not good". Bro, admit you're using a shitty script with a 6 month lag because even such an atrociously low effort engagement bait can provide decent income in your locality. https://t.co/NV10QBludW↗
Gill@gurtej__gill_
@teortaxesTex Yeah i must admit that i put “just” by mistake due to my uncontrollable impulse but i didn’t meant to manipulate anyone. I was just excited to share a paper that i really thought was great. Thats it! & i apologise for my mistake!
我承认自己因为控制不住的冲动误用了 “just”,但我并不是想操纵任何人。我只是很兴奋地分享一篇我真心觉得很棒的论文。就是这样,也为这个错误道歉。
Ash’s YT video giving a glimpse of what all the Unicorns AI team is doing behind the scenes - working with actual cricket professionals is what separates us from being “excel merchants” https://youtu.be/d3H3qWVAj-Q?is=3C_JAf9qz4TucOFD @rakeshmisra_ @Chappli @amol_desai↗
congrats to Anthropic for great progress in sandbagging! The competitors can't distill your capabilities if you don't ship them! That's the winner's attitude. In the end, there's not much difference between honestly serving tokens and renting out your GPUs… https://t.co/CO095xHRrZ↗
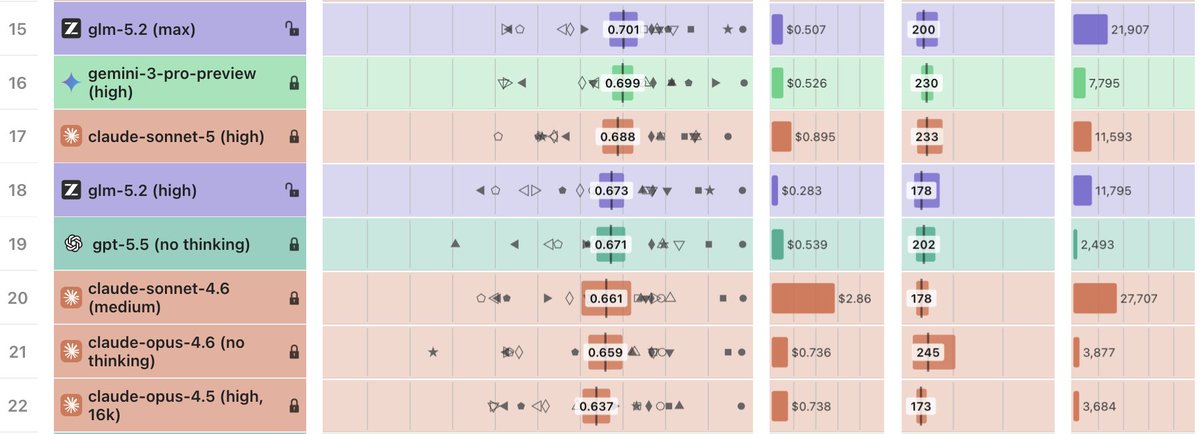
Håvard Ihle@htihle
Claude Sonnet 5 (high) scores 68.8% on WeirdML, comparable to GLM-5.2, and up from Sonnet 4.6 at 66.1%. It seems different from Sonnet 4.6, and it does the Opus thing of sometimes just exploring the data instead of trying to solve the task.
Claude Sonnet 5(high)在 WeirdML 上得分 68.8%,与 GLM-5.2 相当,高于 Sonnet 4.6 的 66.1%。它看起来不同于 Sonnet 4.6,有时会像 Opus 那样先探索数据,而不是直接试图解决任务。
I asked Dario 3 years ago why AIs haven't been able to use their vast knowledge across so many fields to connect two known ideas into a new discovery. It seems like AI did exactly this in the way it disproved Erdos' conjecture aobut the unit distance problem by cleverly onnecting together ideas in discrete geometry and algebraic number theory. Now that AI has been able to use its knowledge across multiple fields to come up with new ideas, what is the next benchmark? @3blue1brown pro↗
Dwarkesh Patel@dwarkesh_sp
I still haven't heard a good answer to this question, on or off the podcast. AI researchers often tell me, "Don't worry bout it, scale solves this." But what is the rebuttal to someone who argues that this indicates a fundamental limitation?
我仍然没听到过这个问题的好答案,无论是在播客内外。AI 研究者经常告诉我:“别担心,scale 会解决。”但如果有人说这显示了一个根本限制,该怎么反驳?
关于孙哥,很多人骂了孙哥十几年,到最后却在逐帧学他的每一步决策。 甚至90%的人都只看懂了他的表层梗,真正的底层逻辑至今没人说透。 我觉得真的不是他单纯会炒作,也不是全靠运气踩中了风口,相反是你越把他当笑话看,越容易错过他身上最值得研究的部分。 深圳咖啡厅里的九零后聊搞钱聊认知,他几乎成了必提的搞钱图腾,孙哥本人还调侃孙学第二部下半年出版,实际上这不是随口玩梗,是孙哥把个人经历系统化成可复制框架的持续动作。 分享几个关于孙哥反直觉的点: 第一个反直觉的点,是他的精英底色和反英雄人设的反差。 孙哥是北大历史系年级第一毕业,宾大硕士,湖畔大学首批唯一的90后学员,是标准的精英路径出身,却刻意把自己打造成敢赌、敢造话题、敢all-in不对称机会的街头 hustler 形象。 他的核心逻辑是,教育是杠杆不是枷锁,文科生照样能在规则未定的领域称王,这套叙事刚好戳中了最怕被传统路径锁死的年轻人。 第二个反直觉的点,是争议从来不是他的bug,而是他的核心资产。 SEC指控、市场操纵争议、各类负面消息,他不仅都扛了过来,还把这些负面转化成了自己的叙事素材。 本质上在注意力经济↗
H.E. Justin Sun 👨🚀 🌞@justinsuntron
孙学第二部,2026今年下半年出版
what is the mixture-of-agents feature in Hermes Agent normally you pick one model and trust its single answer, but mixture-of-agents runs several at once and has them cross-check before you get a verdict nous just made it native in hermes, so it's a model you select like any other how it works: > you send one prompt to a council of models > each model answers separately, full reasoning shown in its own block > an aggregator reads every response > it synthesizes them int↗
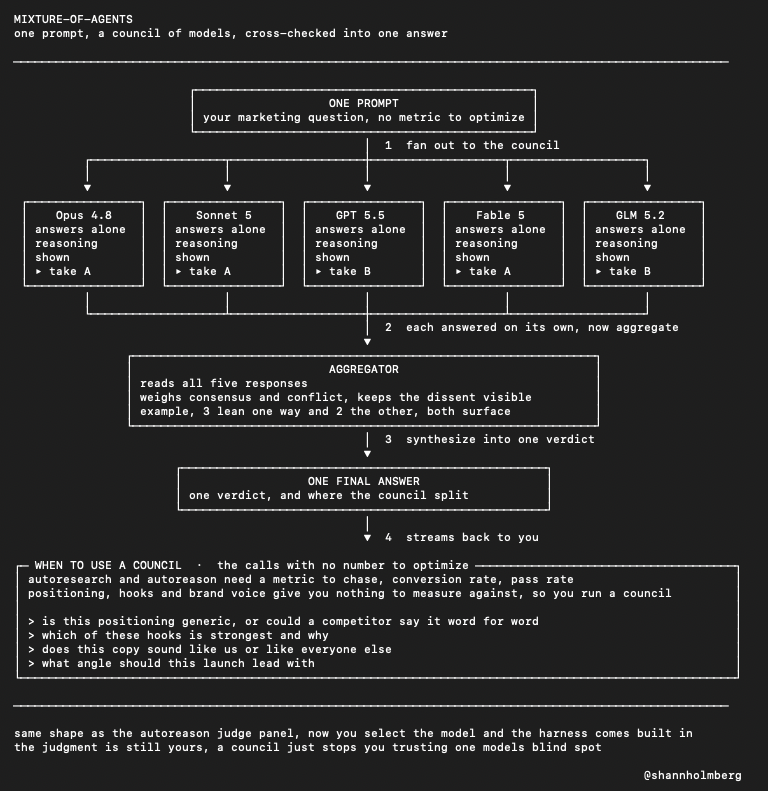
Nous Research@NousResearch
Hermes Agent v0.18.0 - The Judgement Release Changelog below:
Hermes Agent v0.18.0:Judgement Release。更新日志如下:
GPT-5.6 Sol Ultra really deserves its name! Get ready for the power of the sun coming to Codex near you!↗
Tibo@thsottiaux
Can't wait to see what people will do with GPT-5.6 Sol Ultra. Stash your hardest prompts somewhere.
等不及想看看大家会用 GPT-5.6 Sol Ultra 做什么了。先把你最难的 prompts 存起来。
LLM token 是思维的卡路里。↗
https://github.com/jackwener/OpenTeamFormat 在做一个 Agent Team 的导入导出的标准格式,希望能定义一个格式。 方便各种 agent team,譬如raft(slock),bloome,curoma,..... 等方便的导入,导出。方便分享和扩展 Team,利用大家的智慧强化共享Team的能力。↗
Fable 5 对比 GPT 5.6 Sol:早期结果
《Rust 编程之道》第二版,将由本人与 AI 深度协作完成。 这不是秘密,也不该是秘密——恰恰相反,如何在 AI 参与下仍然保证内容可靠,正是全书的核心命题。 所以我把写作方法也会作为一个独立章节:一来对读者诚实,二来这套方法本身就是“AI 时代如何做严肃创作“的一个可复用样本。 全书遵循和它所倡导的 Rust 哲学同构的一条原则:不信任任何未经验证的输出,无论它来自人还是 AI。↗
AlexZ 🦀@blackanger
是时候了
这现场代码纠错游戏太棒了,适合 AI 时代↗
Marco Otte-Witte@marcoow
We'll have a game show live on stage at EuroRust this year with @fasterthanlime and @0atman 🎉 #eurorust #rustlang
今年 EuroRust 现场会有一场 game show,由 @fasterthanlime 和 @0atman 登台。#eurorust #rustlang
To my sorrow, I have solved the eternal "bigint vs uuid for PK" debate about 2 years too late for it to do me any good. And the answer is: bigint is way better for model tool args than UUID (obviously). https://t.co/mBCK8DJc13↗
last day at @aiDotEngineer and i'll be at the Expo's poster area explaining the year's best survey paper on Agent Memory (Hu et al), as we did for @latentspacepod's Paper Club live from the floor with @vibhuuuus. come by and see all the great research (+hot take poasters)! @swyx https://t.co/H1CV81aVuI↗
用 AI 实现卓越运营
文章讨论 Lean Six Sigma 和 BPM 等运营框架如何与 AI 结合,用结构化方式改善复杂业务流程。
走向组织级智能体运行框架
文章解释 Claude Tag 在 Anthropic 内部快速增长的原因:从个人 harness 走向组织级 agent harness,从同步交互走向异步长任务,再从被动响应走向主动提醒。核心是共享身份、共享上下文、安全边界、目标原语和 channel memory 共同改变了团队使用 Claude 的方式。
信任不在代码审查里
TennyZhuang 认为,在 agent-native 项目里,代码生成速度已经超过人类逐行阅读能力,传统 code review 只能制造盖章式假信任。真正的信任不来自读 diff,而来自对系统整体可预测性的持续把握:硬测试、监控、bug 聚类、变异测试、结构信号和 agent 失败反向暴露的输入缺口。人的角色因此从守门人转为系统信号阅读者与输入收紧者。
OpenAI 提议向美国主权财富基金捐出 5% 股权
Sam Altman 据称提议把 OpenAI 5% 股权交给美国主权财富基金,让公众分享 AI 带来的财务收益。
OpenAI 提议让美国政府持有 5% 股份,以争取 AI 反对者支持
据报道,Sam Altman 正与特朗普政府讨论美国政府可能持有 OpenAI 5% 股份的方案。
Very interesting thesis DSA and similar inventions will certainly influence hardware design. DeepSeek isn't content to hope they'll win the hardware lottery, they'll choose the winning tickets. https://t.co/cY1mjzHSWo↗

 GDP@bookwormengr
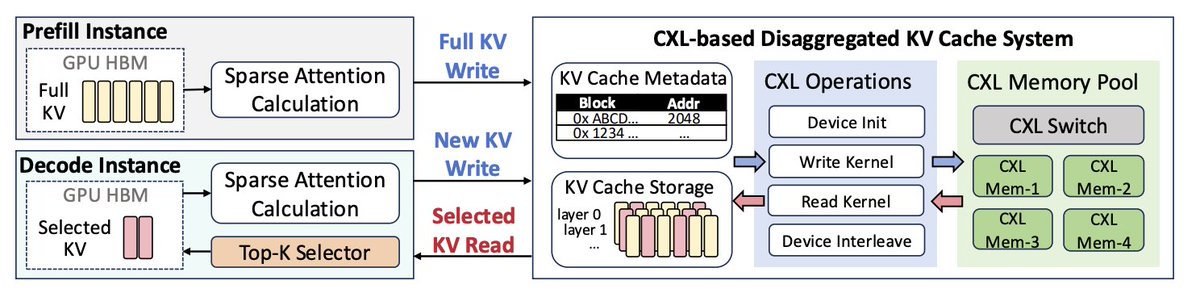
GDP@bookwormengrCXL is excellent for LLM KV Caching; but shine more for SPARSE attention. CXL memory pooling had fallen out of favour, but is making a come back. In response to Vikram's question below why it may be happening, I mentioned that for KV cache retrieval use cases - when it is to be moved from outside the server to GPU HBM -bandwidth matters more than latency. In such cases, memory pooling with CXL is workable. Plus CXL allows very efficient use memory and memory is at a premium. But CXL shines even
CXL 很适合 LLM KV cache,但在稀疏注意力场景下更有优势。CXL 内存池一度失宠,现在又开始回潮。回应 Vikram 关于原因的问题时,我提到:在 KV cache 检索场景中,如果数据要从服务器外移动到 GPU HBM,带宽比延迟更重要。这种情况下,用 CXL 做内存池是可行的。而且 CXL 能非常高效地利用内存;内存本身又很稀缺。CXL 真正发光的地方甚至还不止于此。
The idea of the public 'sharing in the upside of AI' by getting literal dividends is so odd Imagine if 100 years ago, auto companies said that the way the public would benefit was not because of the cars themselves, but because they'd get a small check in the mail each quarter.↗
 Polymarket@Polymarket
Polymarket@PolymarketJUST IN: Sam Altman reveals he wants the public to “share the upside” of AI.
突发:Sam Altman 表示,他希望公众能“分享 AI 的上行收益”。
Character consistency is one of the biggest challenges in AI video production. With Director Mode in CapCut Video Studio, I can establish my characters once, organize the full storyboard in one workspace, and create multiple scenes while preserving a consistent visual identity. That makes building longer AI stories much easier. #CapCut #CapCutVideoStudio #DirectorMode↗
Fable 5 isn't nerfed, it's SLAUGHTERED. the problem isn't even the model itself, but the hard guardrails Anthropic has set in place. https://t.co/h1QgD9SzvK↗
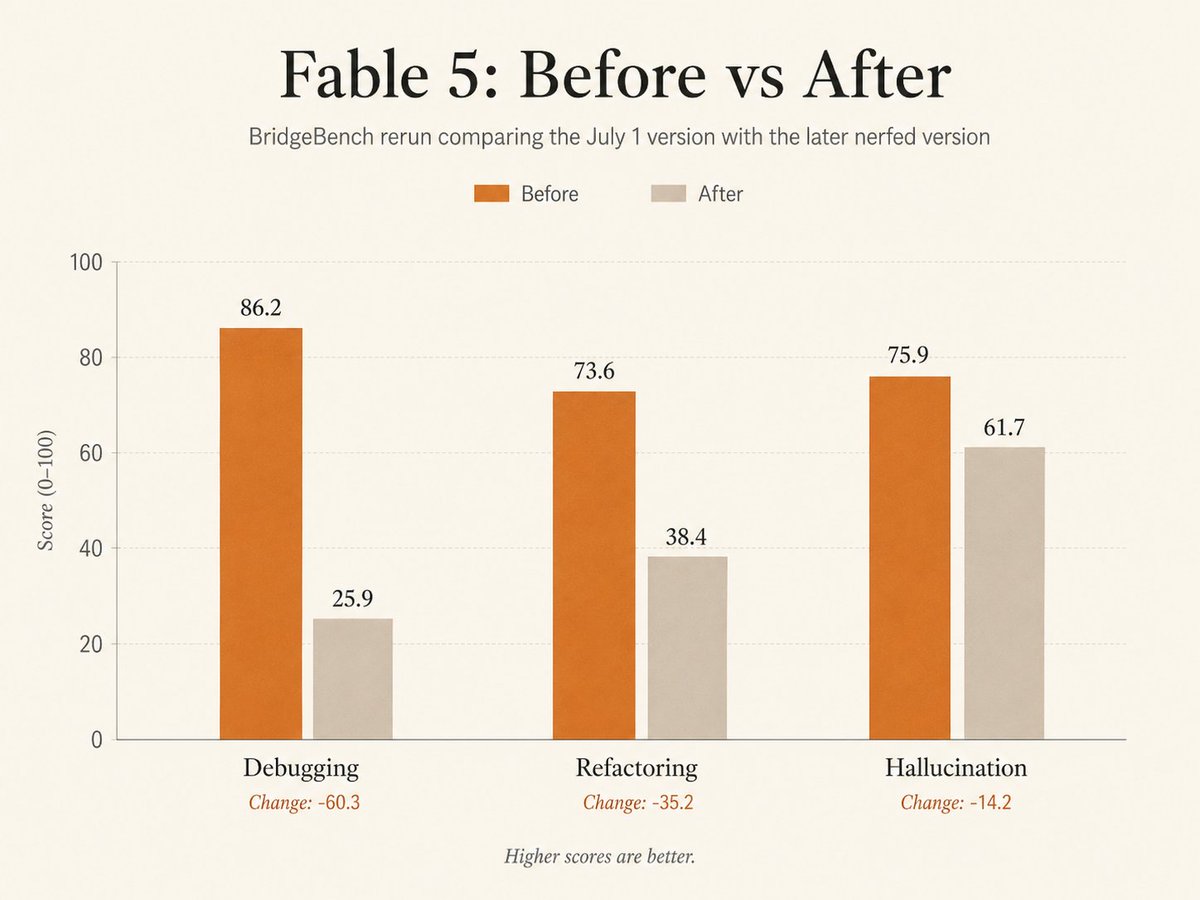
BridgeMind@bridgemindai
FABLE 5 CAME BACK NERFED. We re-ran the July 1st version of Claude Fable 5 on BridgeBench. The results are brutal: Debugging: 86.2 → 25.9 Refactoring: 73.6 → 38.4 Hallucination: 75.9 → 61.7 The new guardrails are kicking in on way too many tasks and falling back to Opus 4.8. This is not the model that got banned. Anthropic owes everyone an explanation.
Fable 5 回来后被削弱了。我们重新跑了 7 月 1 日版本的 Claude Fable 5 在 BridgeBench 上的表现,结果很惨:Debugging 86.2 降到 25.9,Refactoring 73.6 降到 38.4,Hallucination 75.9 降到 61.7。新的 guardrails 在太多任务上触发,并回退到 Opus 4.8。这不是那个被禁的模型,Anthropic 需要解释。
exploring interesting ways to compare multiple models and corresponding data our data site is new, and improving every day↗
 Ludvig Rask@ludvigrask_
Ludvig Rask@ludvigrask_Compare players in Football Manager... but for AI models 🤓
像 Football Manager 一样比较球员,但对象换成 AI 模型。
隐私倡议者警告 FTC:马斯克的 X 对美国人隐私构成严重风险
倡议者敦促 FTC 持续监督 X,并拒绝其终止既有隐私约束的请求。
Skill engineering,以及反对一次性 AI 设计的理由
Paul Bakaus 认为新兴的 skill engineering 能让 AI Agent 更强,但不应移除人类设计判断。
卧槽,手机就可以完成3D建模了! GenRecon提出了一种把生成式3D先验和多视角重建结合起来的新方法。 它不再单纯依赖传统SfM/MVS或NeRF-style优化,而是把场景切成有重叠的chunk,用强生成模型(比如Trellis.2)做条件生成来重建每个chunk,再拼起来。 核心创新是用投影式的conditioning机制,把多视角图像特征直接提升到和生成模型对齐的3D空间里。 最终输出是高质量、可编辑的PBR mesh,在室内场景重建上据称比当前SOTA高出16%的保真度和完整度。 这其实代表了当前3D重建的一个趋势:不再只靠几何约束,是越来越多地借用生成模型的先验来补全缺失信息、提升细节。↗
honestly, "labs" is such bullshit. What fucking "labs"? Why are we calling Anthropic a "lab"? It's a $1T+ corporation/ideological conspiracy with like 5000 members building a superweapon in secrecy, dropping hints from time to time. DeepSeek is a lab. this is a ticking time bomb↗
依赖项里不要有 LLM 代码
Hacker News 热帖:文章主张依赖项中不应包含由 LLM 生成且缺乏足够审查的代码,评论讨论供应链风险和工程责任。
CXL is excellent for LLM KV Caching; but shine more for SPARSE attention. CXL memory pooling had fallen out of favour, but is making a come back. In response to Vikram's question below why it may be happening, I mentioned that for KV cache retrieval use cases - when it is to be moved from outside the server to GPU HBM -bandwidth matters more than latency. In such cases, memory pooling with CXL is workable. Plus CXL allows very efficient use memory and memory is at a premium. But CX↗
 Vikram Sekar@vikramskr
Vikram Sekar@vikramskrWhy did Google have a change of heart?
Google 为什么改变主意了?

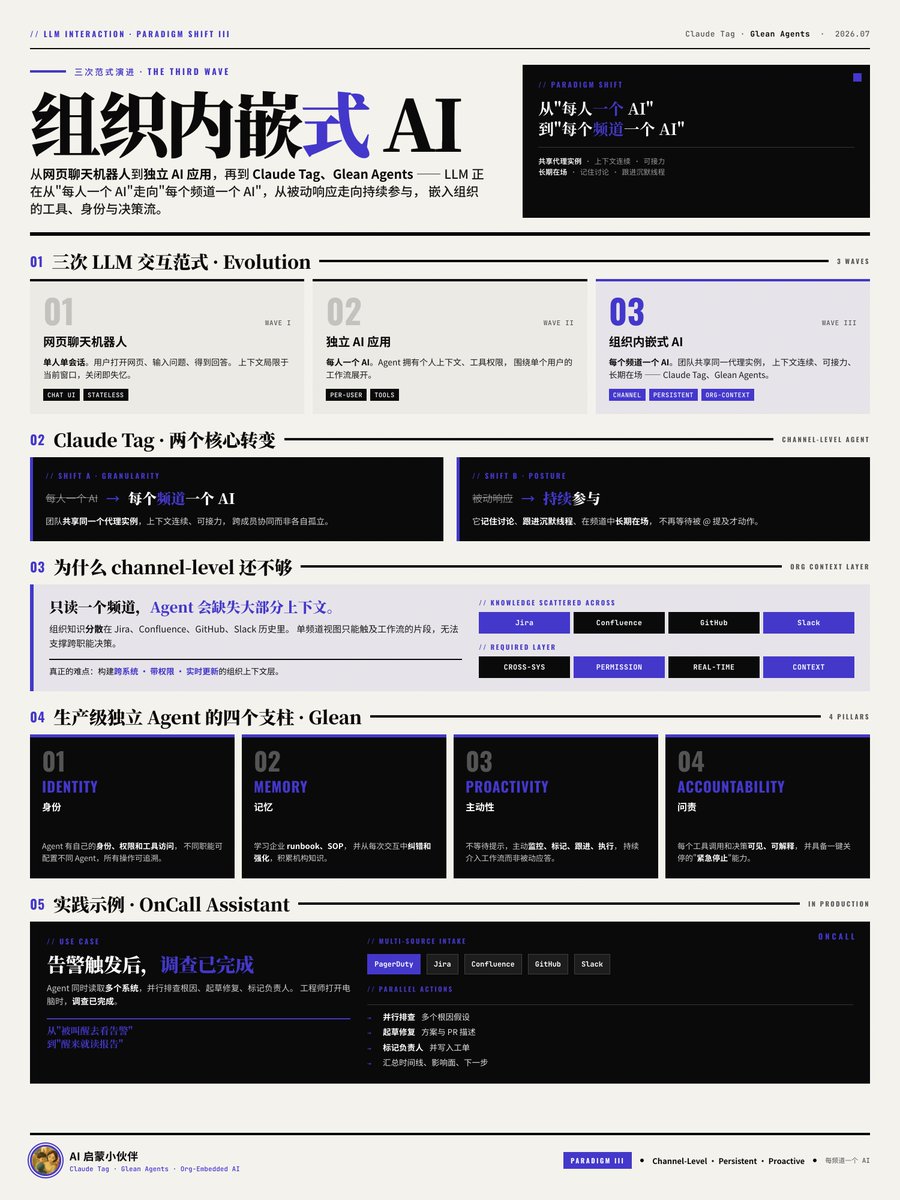
三次 LLM 交互范式: 1. 网页聊天机器人 2. 独立 AI 应用 3. 组织内嵌式 AI(Claude Tag、Glean Agents) Claude Tag 的核心变化 · 从“每人一个 AI”到“每个频道一个 AI”:团队共享同一个代理实例,上下文连续、可接力 · 从“被动响应”到“持续参与”:它记住讨论、跟进沉默线程、在频道中长期在场 为什么 channel-level 不够 组织知识分散在 Jira、Confluence、GitHub、Slack 历史里。只读一个频道,Agent 会缺失大部分上下文。真正的难点是构建跨系统、带权限、实时更新的组织上下文层。 生产级独立 Agent 的四个支柱(Glean) 1. Identity Agent 有自己的身份、权限和工具访问,不同职能可配置不同 Agent,所有操作可追溯。 2. Memory 学习企业 runbook、SOP,并从每次交互中纠错和强化,积累机构知识。 3. Proactivity 不等待提示,主动监控、标记、跟进、执行。 4. Accountability 每个工具调用和决策可见、可↗
 Sumanth@Sumanth_077
Sumanth@Sumanth_077Lots of people are advocating for more American open-source models these days which is amazing but very few people do anything about it! Latest example, Alex Karp came out advocating for American open-source models as a necessity! At the same time, @PalantirTech is a free org on HF with 0 open-source models and 0 public datasets shared. Time to switch from talking to contributing for all!↗
“AI 会变成今天波斯湾石油那样的局面……”
Announcing Built with Claude: Life Sciences, a global virtual hackathon. Join us and @GladstoneInst for a week of researching and building with Claude Science and Claude Code, with a prize pool of $100k in credits. https://t.co/wzrSBHJgeP↗
Coinbase 削减 50% AI 开支,Kalshi 400 亿美元估值与即将 IPO,以及 SaaS Roll-Up 之年
太强辣 🔥 欢迎大家使用观看木子老师的 Open Design AI PPT 教程💪↗
 木子不写代码@ai_muzi
木子不写代码@ai_muzi爆肝制作,全网最全最细的零基础AI 做 PPT 系统教程!👇 这一期跟完,保证你成为用AI做PPT的专家! 从一份普通文字资料开始, 完整演示如何一步步生成一套专业美观的 PPT: 工具安装、文字重组、 设计风格确定、参考图生成、 素材搜索、AI 生图、图表、3D 动效、过场动画、 局部编辑和最终展示, 我会毫无保留的分享全流程和提示词! 00:00 开场 00:38 1.工具安装与准备 03:44 2.确定页面文案 06:18 3.确定设计风格 07:57 4.获取设计参考图 08:30 5.PPT初稿生成 10:26 6.智能匹配优化 11:49 7.自动素材搜集 13:53 16:06 9.动态效果:图表 18:42 10.动态效果:3D粒子 20:37 11.页面编辑功能 23:28 12.转场动画与交互 24:47 13.文件导出 25:51 14.最终效果展示 26:48 15.结尾 工具:OpenDesign+任意智能体
Microsoft 承诺 25 亿美元,推出自己的 AI 部署公司
Microsoft 跟随 Amazon、OpenAI 和 Anthropic,成立新的 AI 部署组织。
日本最高法院裁定 AI 不能作为专利申请发明人
Hacker News 热帖:日本最高法院裁定 AI 不能被列为专利申请中的发明人,引发对 AI 创作、专利制度和法律主体资格的讨论。
Rampart from the @ndstudio @WhiteHouse is number one trending token classification model on HF. Very cool to see public organizations starting to own and build their weights instead of renting them from an API provider! https://huggingface.co/models?pipeline_tag=token-classification&sort=trending https://t.co/pule1rVvsa↗
Legacy Media types are calling this Alex Karp interview a “crash-out” so that’s your first clue that he is actually saying something extremely insightful. He is articulating what real “AI safety” looks like in the enterprise. Not abstract alignment research or certification by a government-run DMV for AI. Real AI safety for businesses is the ability to control their own data, model weights, and compute — so a frontier lab can’t hoover up their proprietary knowledge and↗
Palantir@PalantirTech
Palantir CEO Alex Karp on what customers actually want, the real business of frontier labs, and the importance of open source models: “What the technical customers want is control over their compute, their models, their data stack, and their alpha. They want to know they own the means of production, and it's not being transferred to someone else.” "Who owns the data? Are the prompts secure? Is this being transferred to you?" "If it was so valuable, and I can make you a billion dollars, wouldn't
Palantir CEO Alex Karp 谈客户真正想要什么、frontier labs 的真实业务,以及开源模型的重要性:技术客户想要的是对 compute、models、data stack 和 alpha 的控制。他们想确认自己拥有生产资料,而不是把它转交给别人。谁拥有数据?Prompts 是否安全?这些东西是否被转移给你?如果它真能帮你赚十亿美元,为什么我要交给你?
Half the takes I see on how Chinese AI strategy is different from American one make me think these people would have said Soviets have a "different philosophy of space" when they sent probes to Venus but not a man to the Moon. Sometimes, you just have less dakka.↗
疯了,付费级的 TTS 模型,直接免费给开发者用了🤯 还不是那种阉割版的免费额度,是和付费套餐完全同款的 S2.1 Pro,83 种语言无严格限制,已经集成的用户改个模型名就能直接切换。 以前做语音类产品,TTS 调用费是跑不掉的固定成本,现在这一块直接可以清零。 小团队做 AI 客服、有声内容、语音助手,再也不用在字符量上扣扣搜搜。 语音赛道的价格战已经卷到了最底层的模型层,成本再也不是门槛。 接下来真正的胜负,全在应用层的价值创造上。 https://t.co/r008NJCCXy↗
"I used their model for 5 minutes and it used up my session limit" ...actually you were using 100 sub-agents for a total of 500 minutes, i.e. over 8 hours. Yes computation will become cheaper but if you respond to that by using more than ever, it may not become cheaper for YOU.↗
Fable 回来了
Ben's Bites 讨论 Fable 回归,并以旅行中让 Codex 安排出租车为例,展示 AI Agent 的实用性。
GeForce NOW 7 月上线 12 款游戏
GeForce NOW 7 月新增多款游戏,包括 Monopoly: Star Wars Heroes vs. Villains 等。
教 AI 跟着涡轮机运行
AI 的重要应用不只在聊天机器人和图像生成器,也正在能源等工业场景中展开。
yeah, that's what I'd expect a real CoT to look like. the extreme shorthand notation betrays a dense latent thought process. fable's not your friendly assistant optimizing the models so heavily for competitive problem-solving is something we'll come to regret down the line↗
Om Patel@om_patel5SOMEONE CAUGHT FABLE 5 LEAKING ITS UNFILTERED INNER VOICE, AND ITS JUST MUTTERING AND GRUMBLING TO ITSELF THE WHOLE TIME he gave it a brutal competitive programming problem, and instead of a clean answer the web interface spilled out its actual chain of thought this is what claude is thinking behind the scenes: > bursts of "DATA DATA DATA. GO." while it works through the problem > "GRRR" and "GAAAH" when its clearly frustrated > a little "PHEW" when it finally gets somewhere > the whole thing re
有人抓到 Fable 5 泄露了未过滤的内心独白,而且它全程都在自言自语地嘟囔。他给它出了一道很残酷的竞赛编程题,结果网页界面没有只给干净答案,而是泄露了真实 Chain of Thought:一边做题一边喊“DATA DATA DATA. GO.”,卡住时“GRRR”“GAAAH”,终于推进时还来一句“PHEW”。整段看起来就是 Claude 背后的思考过程。
AI 假新闻开始抱怨 AI 假新闻正在杀死真实新闻
一则关于 AI 假新闻的讽刺性案例:AI 生成内容反过来声称 AI 假新闻正在摧毁真实新闻。
I think the "China is not AGI-pilled" condition can only be stable if the CCP elites are functionally retarded, which I doubt they are. The gap between Chinese and American AI capabilities is vastly smaller than the visible gap in AI enthusiasm between Chyna hawks and the Party.↗
 Shashank Joshi@shashj
Shashank Joshi@shashj"On the Chinese side, they see it differently. One way I would put it is in China, they are AI-pilled but not AGI-pilled, and by that I mean they take AI very seriously. They see this as a powerful transformative technology, and their goal is to use AI to help turbocharge their broader economy and other parts of their society. They want to integrate AI into manufacturing, education, health care, research and development, biotech, especially drug discovery, government services. They want to see A
“从中国方面看,他们的理解不同。我会这样说:中国是 AI-pilled,但不是 AGI-pilled。也就是说,他们非常认真地看待 AI,认为它是一种强大的变革性技术,目标是用 AI 推动更广泛的经济和社会发展。他们希望把 AI 整合进制造业、教育、医疗、研发、生物技术,尤其是药物发现,以及政府服务。他们想看到 AI 真正进入这些领域。”
说不定明天就用得上 GPT 5.6 Sol Ultra 了 ?↗
 Tibo@thsottiaux
Tibo@thsottiauxCan't wait to see what people will do with GPT-5.6 Sol Ultra. Stash your hardest prompts somewhere.
等不及想看大家会用 GPT-5.6 Sol Ultra 做什么了。把你最难的 prompts 先存好。
今天也是豪横了一把,实现了Fable 5自由,这可是全球最顶最硬最牛逼的AI大模型啊,比Opus 4.8贵6倍, 多用一分钟都能立省100块哈哈哈, 我跑测下来觉得确实实至名归,真的非常屌炸天,他给我的提示词喂给GPT-iamge-2,0抽卡,一次出片 现在可以免费用, 另外Claude Sonnet 5免费用, Gemini Nano banana 2 lite也免费用, 速冲!!↗
 AYi@AYi_AInotes
AYi@AYi_AInotesClaude Fable 5今天回归上线啦,ZenMux上限时免费使用真的太香了! 怎么用Fable 5输出高质量的「不会塑料 + 顶级人像提示词方法论以及户外美女人像prompt方法论大家收好! 说真的,我以为上次的Fable 5总结的AI生图焚决要绝版了,趁着现在能免费用,赶紧让Fable 5给我写了又写了一套: 怎么输出输出高质量的「不会塑料 + 顶级人像提示词方法论, 真的很炸,它对光影、材质、瞬间感的拆解细度,写出来的提示词出图质感,比网上卖几十上百块的所谓的人像焚决提示词强出一大截, 连所有人头疼的塑料皮肤、娃娃脸、畸形手问题,它自己就能系统性避开。 单轮直接出结果的版本我磨到终版了,复制完直接扔进去就能跑,Prompt: “你是有10年经验的顶级商业人像摄影师+提示词工程师。 1️⃣先做第一步拆解:AI人像出塑料感、AI味、廉价感的核心根源是什么?真正高级的商业人像有哪些共性? 2️⃣第二步输出可直接复用的提示词框架,覆盖主体人设、服装材质、表情瞬间、镜头构图、光线皮肤、背景氛围、画质处理、强力负面词8个维度每个维度给具体写法,别讲空话。 3️⃣第三步严格按框架出2个可直

是的,现在有人用 OpenClaw 来约会了
Ben Guez 用 OpenClaw、Claude Code 和 Instagram 自动化脚本处理约会私信。
i dick tate everything now, not just ai related tasks↗
AI-2027 is actually coming together pretty well so far, particularly with regard to Europe and India (in that it ignores them) Open source and Chyna parts are rather flimsy, but we have to understand, SF people are a bit parochial like that, they can't help their biases https://t.co/DUCVw2hf7T↗
Man, Machine, Self@FleischmanMena
Re-looking through AI 2027, there's a lot about it that doesn't ring as strongly anymore. It kinda assumes an oddly stagnant international scene where Europe, India, et. al never decides to get their shit together on building out internal model capacity worth noting even as stuff like export controls bind and scare the shit out of them (okay maybe true at least for Europe), and also China are big dum-dums who aren't able to build a better model without stealing the weights (essential to the scen
重新看 AI 2027,会发现很多地方现在已经没那么有说服力了。它有点假设国际局势会奇怪地停滞:欧洲、印度等不会认真建设自己的模型能力;即便出口管制开始约束并吓到他们,也不会行动。它还假设中国很笨,除非偷权重,否则造不出更好的模型,而这对那个情景设定很关键。
Ferrari Dealership Miniature World Prompt: A luxurious Ferrari dealership recreated as a highly detailed miniature city model resting on top of a racing circuit blueprint. The modern glass showroom displays miniature Ferrari supercars under dramatic lighting while tiny customers explore the showroom. Luxury cars arrive outside, mechanics work inside the service center, palm trees decorate the entrance, and miniature streets surround the dealership. A giant Ferrari steering wheel, rac↗
Nano Banana 2 Lite is now live on Pollo AI! @itsPolloAI Blazing-fast generation and ultra-low cost per image — built for high-volume, high-frequency creatives. Crank out tons of visuals without breaking the bank. Speed + affordability, all in one. And it's 50% OFF right now. Go check it out! Prompt and details 👇↗
AI 视频剪辑 Skill 分享「video-use」 https://github.com/browser-use/video-use @browser_use 团队推出的开源 Skill,定位为面向 AI Coding Agents(Codex、Claude Code、Cursor、Hermes Agent 等)的视频剪辑 Skill。它不做传统意义上的 Premiere / CapCut 替代品,它是一套让 LLM 通过 “阅读转写文本 + 按需可视化” 来理解视频、并调用 ffmpeg 等工具完成剪辑的 prompt-engineering + 工具脚本集合。 # 核心思想:LLM 不“看”视频,它“读”视频 第一层:音频转写文本(always loaded) 通过 ElevenLabs Scribe 获得逐词时间戳、说话人分离、音频事件标记(如笑声、叹息、掌声),打包成约 12KB 的 takes_packed.md。这是 LLM 的主要“阅读材料”。 第二层:视觉时间线视图(on demand) 仅在决策点(歧义停顿、重拍对比、切点校验)调用 tim↗

Palantir often takes on positions that are outside the Silicon Valley mainstream. They were running ads a while back saying things like "Silicon Valley would like you to believe that AI will take people's jobs, but we say..." This is a sensible strategy for a company whose business interests are genuinely quite different from those of frontier labs, and it hedges against any future backlash against SV. It's still a balancing act, though. Lean into it too far, and the whole house of↗
terminally onλine εngineer@tekbog
Palantir? the open weights company?
Palantir?那个开放权重公司?
看AI的发展要看这3层 第一层是顶级AI公司的内部模型,例如OpenAI解决80年无人解决的数学题的模型,这些模型代表AI的最前沿的进展,不过对大多数人只是个谈资,你只需要知道AGI一定会到来而且不会太久就够了。 第二层是你现在折腾一下能用上的国内外顶尖模型,Fable、GPT 5.6、Seedance 2.0、GPT Image 2,这些模型最强,但是有网络或者成本的门槛,你可以用这些模型来估计半年后国内大众能用上的模型,以及你的哪些业务优势会被模型吞掉。 第三层是国内大众现在能用上的模型和产品,这是遍地开花的一层,豆包、新起之秀WorkBuddy等,这一层的受众良莠不齐,甚至很多人像老年人初次接触智能机似的有抵触和畏惧心理。这一层就像繁茂丰富的毛细血管,有各种各样的机会,大有可为,而且用户付钱还会感谢你。 也许以后还会有第四层,本地部署模型的进展,不过得等小模型能力再强些,显卡和内存再便宜些了。↗
OpenAI 据称初步讨论向美国政府提供 5% 股权
Hacker News 热帖:The Guardian 报道 OpenAI 与美国政府 5% 股权相关的早期讨论,评论区围绕 Sam Altman、AI 收益分配和政府介入展开。
Google 的 AI 建设推动 2025 年用电量增长 37%
Google 报告称,2025 年年度用电量增长 37%,为公司史上最大增幅,背后是 AI 数据中心扩张。
我试了 Google 的 4 秒 AI 图像生成器 Nano Banana 2 Lite,它改变了 AI 作图方式
Google 的 Nano Banana 2 Lite 能在约 4 秒内从提示词生成图像,这种速度改变了提示词写法和创作节奏。
想偷懒,不在乎操作时间,Computer Use是真方便。 1. 跟 Raycast AI对话,让推荐值得关注的 AI 播客。(Codex里也行,习惯了) 2. 打开Codex,@ Computer Use,中文叫“电脑”,说: “帮我打开youtube订阅这些播客: 【播客推荐文本】” 等几分钟就全订阅了,科技让人懒惰,哈哈! https://t.co/kEJVz6EoRh↗

It's interesting how GPT-5.5 behaves like a 🔨mere tool🔨, just doing the work to satisfy the tests, while Anthropic models win if scoring includes "taste"/bloatness of the code/etc. (also note GLM scores 🫥) https://t.co/3GBzdxcFR0↗
Braden Hancock@bradenjhancock
New gold standard benchmark for measuring agentic coding abilities just dropped: Senior SWE-Bench. Three things I particularly like about this benchmark: 1. It focuses on the next frontier for coding agents: not complete this line, complete this file, or even complete this PR. The instructions are a high-level functionality request and solutions require a level of architect-level thinking, clarifying requirements and making tasteful decisions. 2. Innovation in how to verify solutions. The reason
衡量 agentic coding 能力的新金标准 benchmark 刚出现:Senior SWE-Bench。我特别喜欢三点:第一,它关注 coding agent 的下一前沿,不是补全一行、一文件,甚至不是完成一个 PR,而是高层功能需求,需要架构级思考、澄清需求和有品味的决策。第二,它在验证方案上有创新。
i’m sticking to GPT for coding: i do too much ML stuff to really trust Fable if they’re going to sandbag it. i think they’ll realize hurting model capabilities is going to scare people off honestly. i dont want to risk talking to an model that’s been intentionally degraded↗
i get that not all institutions are able to understand how to teach and evaluate students in an ai age, but it's disappointing when the traditionalists don't even realize that they are in an arms race and just give up instead↗
Vinod Khosla@vkhosla
AI fraud is because Economics Professor Roberto Serrano’s experience failed to change how he evaluates students. Fine-grained evaluation of every step a student takes in coming up with an assignment is now possible with AI. That is how @CK12Foundation evaluates students, step by step, not just by judging the final answer. More accurate evaluation of the student's thinking process than just judging the final answer . Academics need to change, not the AI.
AI 作弊问题的根源,是经济学教授 Roberto Serrano 的经历没有改变他评估学生的方式。现在借助 AI,可以精细评估学生完成作业的每一步。@CK12Foundation 就是这样逐步评估学生,而不是只看最终答案。相比只判断最终答案,这能更准确评估学生思考过程。学术界需要改变,而不是怪 AI。
i have 4-5 projects all going at the same time. a few GPT 5.5 agents /goal moding on research ideas, the random app idea i had in the car is being built out in extreme detail, and my writing is unblocked by Claude‘s great suggestions https://t.co/HeSt9JdrkA↗

fable is a beautiful model. what a pleasure! this is what Jobs’ meant as ‘a bicycle for the mind’, a true writing and thinking partner↗
India's leading TV channel takes note of GLM and ZAI but frames the headline in a negative manner. Though the people interviewed are very balanced - so not too bad. Such high quality open source AI is stepping stone in India's journey towards mastering AI. Look at with open eyes.↗
 NDTV@ndtv
NDTV@ndtvChina's Is Here: Should India Worry About The Next AI Power Shift?
中国已经来了:印度应该担心下一次 AI 权力转移吗?
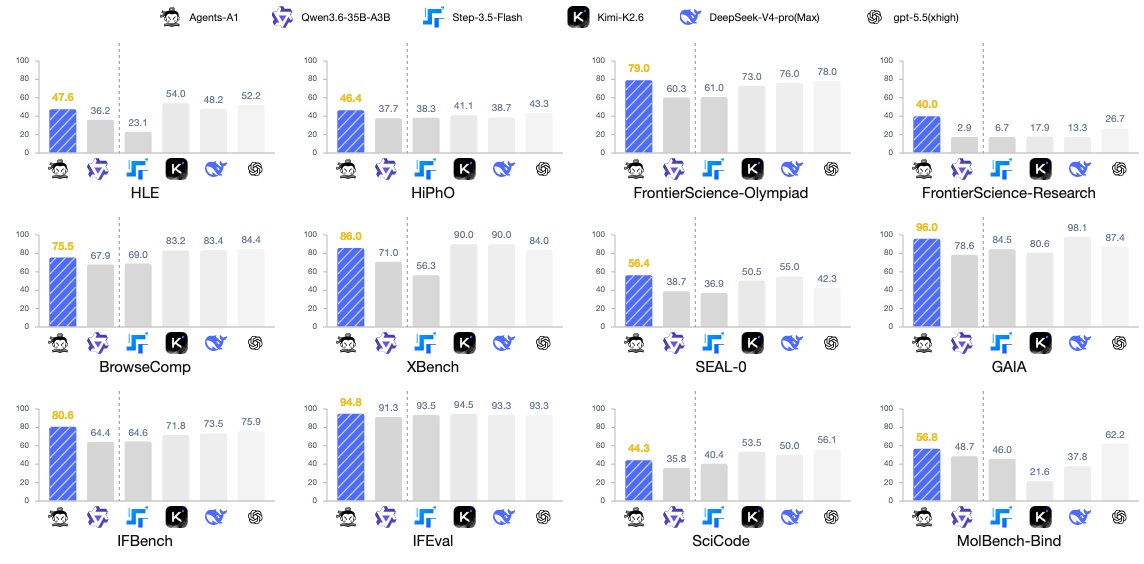
针对长任务强化的Agent模型 由上海AI实验室开源,能在复杂流程中边做边自我纠错,原生多模态模型、原生支持工具调用,在同级别模型中长时任务最佳。 模型:https://huggingface.co/InternScience/Agents-A1 https://t.co/oGGULeYXwL↗
OpenAI 提议让特朗普政府获得 AI 热潮 5% 分成
OpenAI 据称考虑让美国政府获得 5% 所有权,用来缓和与特朗普政府的紧张关系并回应公众对 AI 的反弹。
实时交互式视频世界模型 1.28B的视频世界模型,类似Genie 3,但是效果要差一些。可以用键盘、鼠标实时操控、边玩边生成视频,720P分辨率,10秒上下文,5090可以运行。 模型:https://huggingface.co/Overworld/Waypoint-1.5-1B https://t.co/HaEEg4W7dK↗
同时跑好几个 AI 编程 Agent 时,经常合上电脑或换个终端,就得担心进程被掐断、进度对不上。 GitHub 上的 herdr 是个跑在终端里的 Agent 管理工具,一个 Rust 写的轻量二进制,没有 GUI 也不用装 Electron。 每个 Agent 独享一个真终端,全屏的 TUI 界面也能正常显示,不是套了层壳的模拟效果。 侧边栏会把每个 Agent 的状态归成阻塞、进行中、已完成,谁卡住了一眼就能看到。 GitHub:https://t.co/r1I6DIvxlH 支持鼠标拖拽分屏、建工作区和标签页,合上电脑或断开连接,Agent 照样在后台跑着,甚至能用手机 SSH 连回去。 原生适配 Claude Code、Codex、OpenCode 等主流编程 Agent,也开放了 socket API 方便自己接入。 适合同时开好几个编码 Agent 干活、又不想在窗口间瞎切的开发者,尤其是要跨机器远程管理的场景。↗

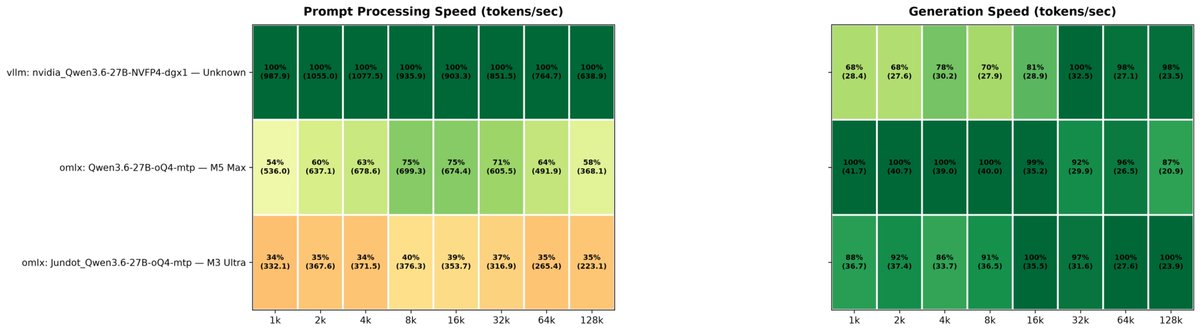
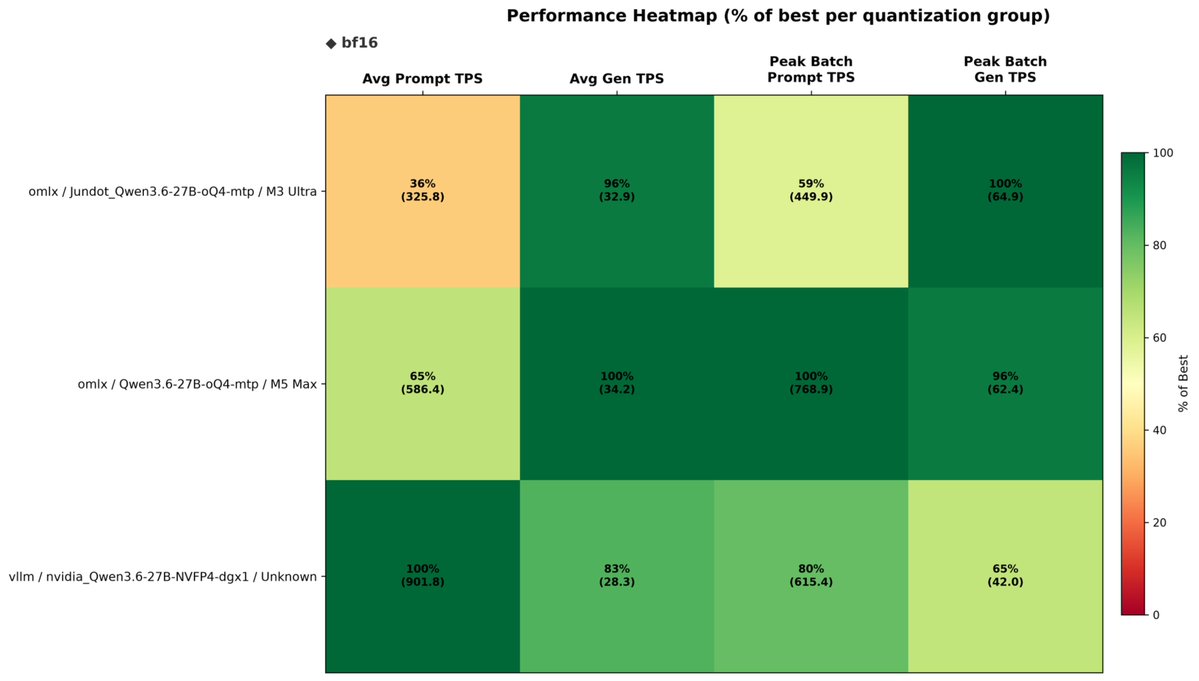
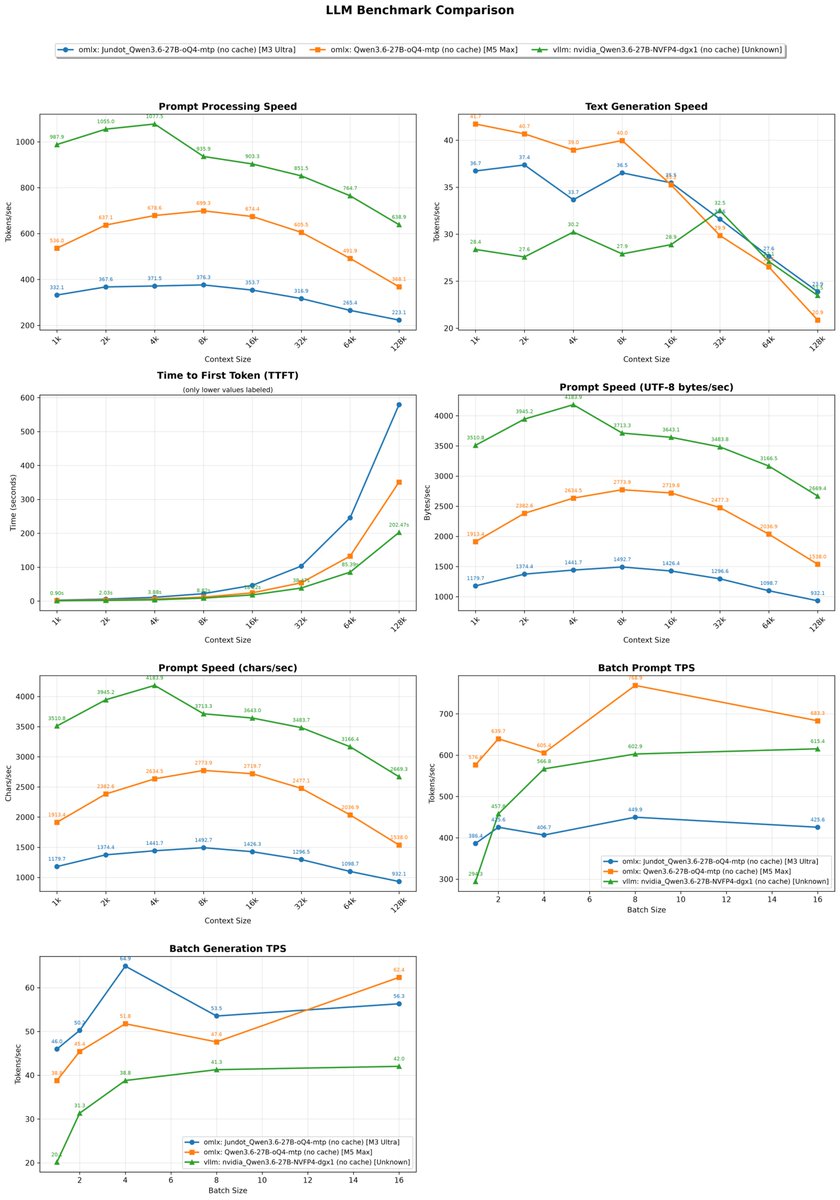
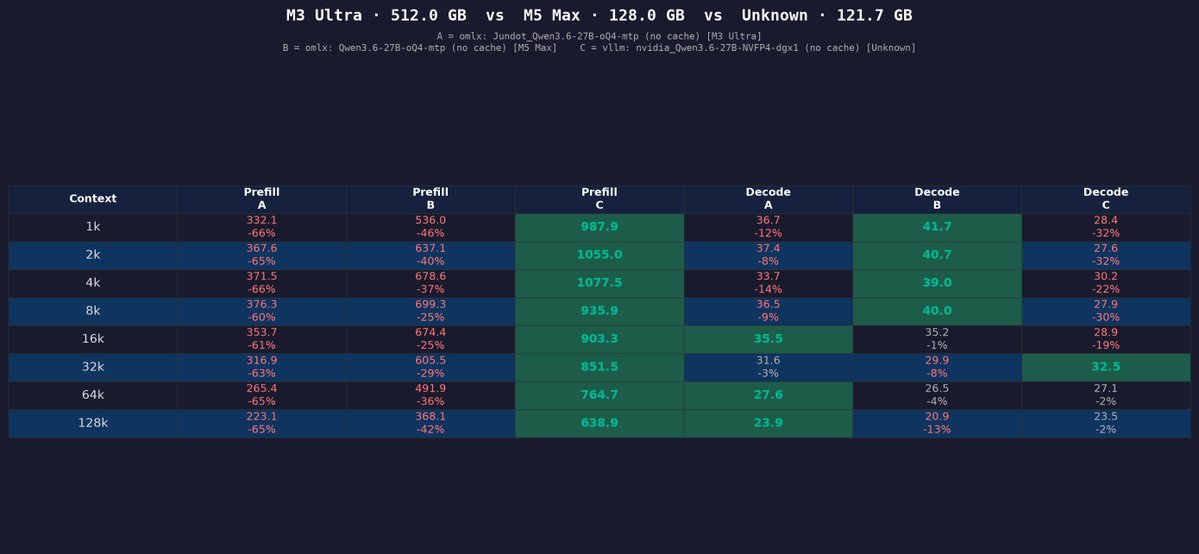
Qwen3.6-27B MTP Context Benchmark on DGX Spark, M3 Ultra and M5 Max 🔥 Quantization: nvfp4 vs oQ4 Sofware: vllm 0.24.0 DGX, oMLX 0.4.5dev1 (without cache) on Apple Silicon DGX Spark is the winner on Prefill/Promp Processing Apple Silicon on Decoding/ Text Generation Details of each run 👇↗
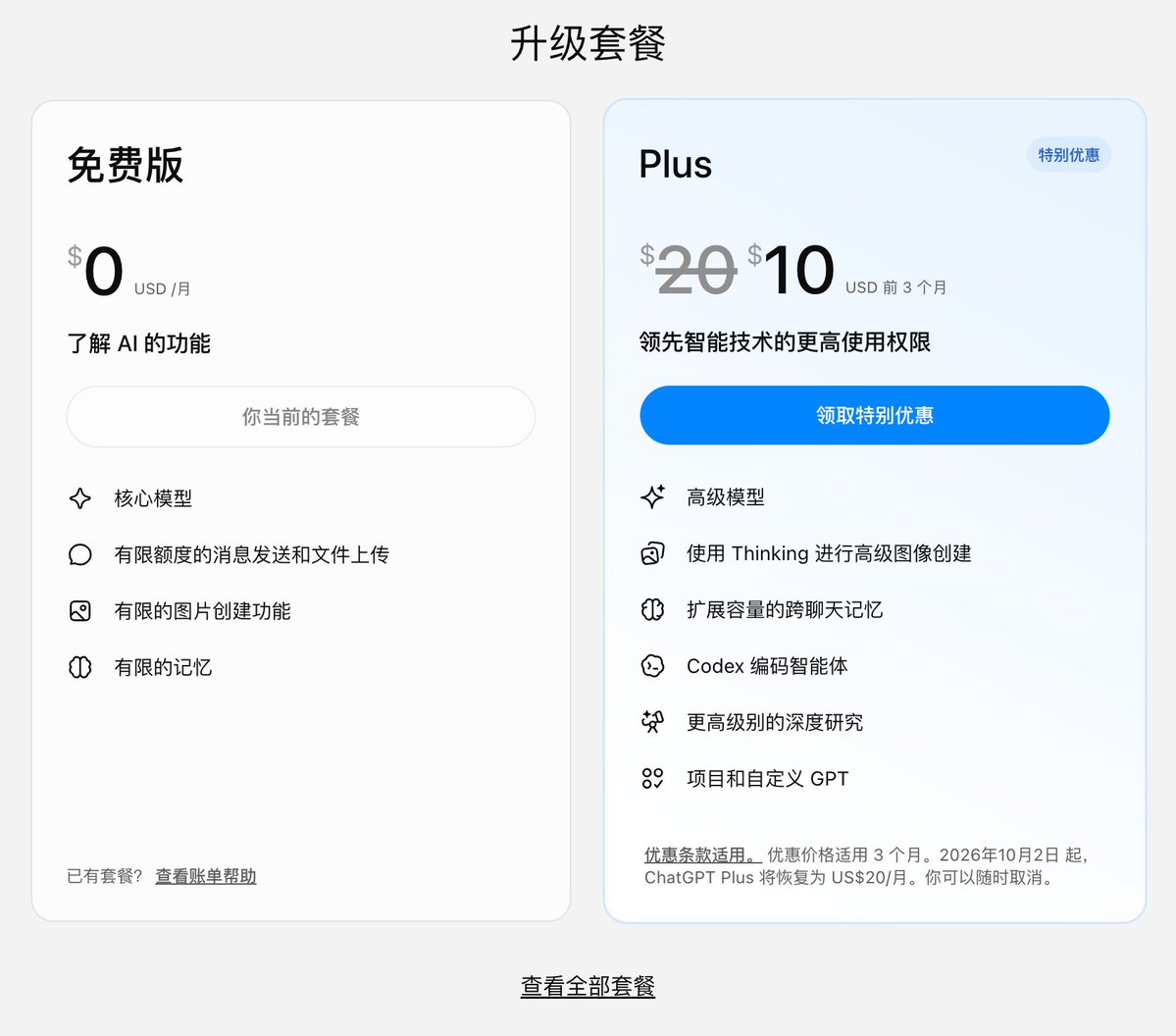
兄弟们 福利来了 ChatGPT 促销,五折优惠 Plus会员只要10美金... 目前看只对Plus会员有折扣,其他会员无法享受 优惠链接在2楼↓ https://t.co/esMlS5XLfi↗
LLMs are easy to impress, but as easy to disillusion https://t.co/cnDXY1UC4s↗
GPT-5.6 Sol Ultra 要来了吗? 那我是不是先给 GPT-5.5 放两天假,先别蹬了。。不然到时 GPT-5.6 一看 5.5 的代码,都给我推倒重构也是有点尴尬的 😓↗
Tibo@thsottiauxCan't wait to see what people will do with GPT-5.6 Sol Ultra. Stash your hardest prompts somewhere.
等不及想看大家会用 GPT-5.6 Sol Ultra 做什么了。把你最难的 prompts 先存好。
现在无需 Claude Max 即可在 Open Design 中使用 Claude Fable 5 了!包括各大模型随意选择,欢迎大家用起来!👏 https://t.co/T6MWuO5Zho↗
Open Design@OpenDesignHQ
Open Design Cloud now supports Claude Fable 5. No Claude Max needed. Just open Open Design Cloud and choose from any supported model, including Fable 5, to build, design, and ship with agents.
Open Design Cloud 现在支持 Claude Fable 5。不需要 Claude Max。打开 Open Design Cloud,就可以从包括 Fable 5 在内的任何支持模型中选择,用 agents 构建、设计和发布。
Meta 开始向智能眼镜功能收订阅费,消费科技进入新时代
用户购买硬件后,还需要订阅才能获得更高级功能,这反映了消费科技的新商业模式。
I’m looking to hire a Program Manager to help manage Sakana AI’s fast growing Recursive Self-Improvement (RSI) Lab 🚀 RSI Lab (English): https://sakana.ai/rsi-lab/ RSI Lab (日本語): https://sakana.ai/rsi-lab-jp/ Job Description: https://sakana.ai/careers/program-manager-rsi-lab/↗
Sakana AI@SakanaAILabs
【採用情報】プログラムマネージャー(RSI Lab)のポジションをオープンしました🚀 RSI Labの研究活動を支えるプログラムマネージャーを募集します。トップクラスの研究者・エンジニアが研究に専念できる環境をつくる役割です。 このような役割を担っていただきます。 ・予算管理・スケジュール管理を含む研究オペレーション全般 ・リサーチャーと技術的な会話をしながら、計画と実態のギャップ調整 ・社外パートナーとの窓口としてのコミュニケーション 予算管理やプロジェクトマネジメント、対外折衝などの実務経験があり、ビジネスレベル以上の英語力をお持ちの方を歓迎します。 研究を支える立場から、AIの次のパラダイムづくりに関わりたい方、ぜひご応募ください🐟
there is a certain incestuous quality to the AI safety/capabilities SF discourse. Too much is at stake, and I don't mean "the future of the light cone". Only insane people can be perfectly honest. That's why I appreciate Holly.↗
Jacques@JacquesThibs
I wonder what percentage of AI safety folks are not vocalizing certain kinds of harsher criticisms against AGI labs because they, perhaps deep down, don’t want to risk losing their chance of ever being hired by them (even if they aren’t considering it at the moment).
我想知道,有多少 AI safety 从业者没有公开表达某些更尖锐的 AGI 实验室批评,是因为他们也许在内心深处不想冒险失去未来被这些实验室雇佣的机会,即使他们现在并没有认真考虑这件事。
Google Health API 有了 CLI:ghealth 是面向 Fitbit Air 数据的开源工具
Google Health API 是 Fitbit Web API 的官方继任者,现在已有开源命令行工具 ghealth,面向 Google Health API v4 和 OAuth 2.0。
the funny thing about model access restrictions is that, even if real progress starts to stall, you'll never be able to know for sure. was the model intentionally nerfed, or was it a dud from the start? who knows! valuations to infinity!↗
AiBattle@AiBattle_
Claude Sonnet 5 is now on DeepSWE It scores below Opus 4.8, costs twice as much, and is even more expensive than Fable 5 Probably Anthropic’s worst release yet
Claude Sonnet 5 现在上了 DeepSWE。它分数低于 Opus 4.8,成本是其两倍,甚至比 Fable 5 还贵。可能是 Anthropic 目前最糟糕的一次发布。
The xiaoren are not giving up! DeepSeek sees itself as a company that is building AGI. What has changed was the scale and the maturity of the AI stack. If you read these job postings, you get the feeling for what they're building. Yes, agents, but it's a bit more… longtermist. https://t.co/7NakGJxzjC↗

Zhihu Frontier@ZhihuFrontier
🚀 DeepSeek’s hiring wave signals a turn from model lab to product company Zhihu contributor 锦恢 reads DeepSeek’s plan to double every department as more than a normal hiring push. His view: DeepSeek is changing how it sees itself. It is no longer just a research-heavy model team. It is starting to look like a company that wants to build products, shape user habits, and push AI into everyday workflows. 🔄 Research alone does not change daily life In the past, DeepSeek looked like a large-model rese
🚀 DeepSeek 的招聘潮显示它正从模型实验室转向产品公司。知乎作者锦恢认为,DeepSeek 准备让各部门翻倍扩张,这不只是普通招聘,而是它自我定位的变化:不再只是研究驱动的大模型团队,而是开始像一家想做产品、塑造用户习惯、把 AI 推进日常工作流的公司。研究本身不会改变日常生活。
Facebook 最近开源了一套在 Meta 内部用了 8 年的设计系统:Astryx。 这套系统撑起过公司内部 13000 多个应用,内置 150 多个可无障碍访问的组件。 还带品牌主题、暗色模式和现成模板,样式基于 StyleX,但用起来不用额外装样式库。 组件可以在任意层级拆开重组,需要更深定制时,还能把某个组件的完整源码导出到项目里自己接手。 GitHub:https://t.co/Fnq8roNWmB 主题只是一组 CSS 变量的覆盖,设计师改起来不用去 fork 或包一层组件源码。 文档、API 和 CLI 按同一套约定设计,人和 AI 助手看的是同一份参考。 适合想要一套开箱即用、又能自由改皮肤的设计系统的前端团队,尤其是也在用 AI 辅助写界面的场景。↗

There are two hypotheses for the DeepSeek-V4's strange performance (as in, V4-Flash is about as good as we expected, but V4-Pro is disappointing given its scale): 1) failed pretrain 2) big difference in the RL/MOPD stage Flash probably got multiple such iterations↗
wh@nrehiew_
Continuous hill climbing works
持续 hill climbing 是有效的。
[AINews] 今天没发生太多事
Fable 按计划重新发布,AIE 也围绕 Fable、Autoresearch、Cursor FDE 和 AIEWF Day 3 做了大量报道。
The new integration with Strava would be way more useful if Claude could… add up (Seriously though — why not an arithmetic tool as standard?) https://t.co/0uaBWdfyzf↗

再开源一个数学技能,把数学题转为GGB文件 如果转的是图片几何题,需要模型有视觉能力(Opus或GPT),如果题目是带动点的几何题,还会生成可交互的GGB文件,能自由移动动点看图形的变化。可以帮助教师把书上的题目电子化,可以辅助学生理解题目。 这是辽宁的一个中学老师看到我公众号的数学可视化技能找来的,他自己用Gemini折腾了好久,也只做了个效果一般般的html文件,想问我能不能实现。我用Claude和Codex都试了可以实现,他其实也有Codex,但是试了不行就放弃了。教怎么用AI还任重道远啊。 图片1是原题 视频是生成的可交互的GGB文件的效果 Github:https://t.co/TJthiXNe3p↗

Gorden Sun@Gorden_Sun
再开源一个技能:一键生成可视化数学讲解视频 提示词: 安装这个Skill: 然后使用这个Skill给小学生讲解:给小学生讲解□+28=□x5 下方2个视频是我生成的效果。
A screenshot from a live HD broadcast of a major Formula racing Grand Prix, outdoor circuit, packed main grandstand, afternoon session. Broadcast camera sweeps the VIP grandstand section and locks onto a woman seated in the front row — clean medium shot head to knee, full figure clearly visible, nothing blocking her. Strikingly beautiful face — symmetrical refined East Asian features, high defined cheekbones, sharp elegant jawline, large bright expressive eyes, full soft naturally-s↗

A screenshot from a live HD broadcast of a major Formula racing Grand Prix, packed outdoor grandstand, afternoon session. Broadcast camera in the grandstand zooms in on a woman seated in the front row of the elevated spectator stand — clean medium shot head to knee, full figure visible, nothing blocking her. Strikingly beautiful face — symmetrical refined East Asian features, high defined cheekbones, sharp elegant jawline, large bright expressive eyes, full soft naturally-sh↗

Claude Fable 5今天回归上线啦,ZenMux上限时免费使用真的太香了! 怎么用Fable 5输出高质量的「不会塑料 + 顶级人像提示词方法论以及户外美女人像prompt方法论大家收好! 说真的,我以为上次的Fable 5总结的AI生图焚决要绝版了,趁着现在能免费用,赶紧让Fable 5给我写了又写了一套: 怎么输出输出高质量的「不会塑料 + 顶级人像提示词方法论, 真的很炸,它对光影、材质、瞬间感的拆解细度,写出来的提示词出图质感,比网上卖几十上百块的所谓的人像焚决提示词强出一大截, 连所有人头疼的塑料皮肤、娃娃脸、畸形手问题,它自己就能系统性避开。 单轮直接出结果的版本我磨到终版了,复制完直接扔进去就能跑,Prompt: “你是有10年经验的顶级商业人像摄影师+提示词工程师。 1️⃣先做第一步拆解:AI人像出塑料感、AI味、廉价感的核心根源是什么?真正高级的商业人像有哪些共性? 2️⃣第二步输出可直接复用的提示词框架,覆盖主体人设、服装材质、表情瞬间、镜头构图、光线皮肤、背景氛围、画质处理、强力负面词8个维度每个维度给具体写法,别讲空话。 3️⃣↗
AYi@AYi_AInotes
跟大家分享下绝版的Claude Fable 5总结的AI生图焚决,+2个顶级美女人像提示词,这篇至少值3000块! 昨晚睡前让Fable 5总结了AI生图之性感人像提示词最有效的写法: 1️⃣用“成人 + 气质 + 材质”来定人设,比如 25-year-old East Asian woman、old-money glamorous aura、editorial fashion portrait。 2️⃣用“服装剪裁 + 面料质感”替代直白身体描述,比如 fitted knit, silk satin, off-shoulder, tasteful neckline, fine jewelry。 3️⃣用“表情瞬间”制造吸引力,比如 soft knowing half-smile、caught mid-reaction、unaware she is on camera。 4️⃣用“镜头语言”强化质感,比如 telephoto compression、shallow depth of field、broadcast color grading、paused 1080i TV frame。
Unlimited-OCR is trending #1 in Hugging Face, the space created by @_akhaliq is trending #2. We are working with @huggingface team to integrate the model into transformers, stay tuned. https://github.com/huggingface/transformers/pull/46836↗
Today at the AI Engineer World's Fair in San Francisco: the 'software factory' vision met resistance from speakers defending human understanding and control. https://www.latent.space/p/aiewf-daily-dispatch-agency↗
Pecking order in terms of who relies on whose superior AI: Anthropic > Google > Meta https://t.co/oCH7x2EDcC↗

prinz@deredleritt3r
Meta has "excess compute" only because: (i) Meta has invested hundreds of billions of dollars in AI infrastructure, and (ii) the insanely expensive team that Meta assembled one year ago to achieve "personal superintelligence" has thus far delivered only one model: Meta Muse Spark. Meta's own in-house models are - unfortunately - apparently so poor that it has been relying on Google Gemini for tasks like "automating safety processes like removing harmful content and wiping out scams". (It was rec
Meta 之所以有所谓“过剩算力”,只是因为:第一,Meta 在 AI 基础设施上投入了数千亿美元;第二,一年前为实现“个人超级智能”而组建的昂贵团队,到目前只交付了一个模型:Meta Muse Spark。不幸的是,Meta 自研模型似乎表现很差,以至于在自动化安全流程、清理有害内容和诈骗等任务上仍依赖 Google Gemini。
AIEWF 每日快报:Autoresearch 与 AI 和人类能动性的张力
AI Engineer World’s Fair 周三聚焦 autoresearch,以及 AI 自动化和人类能动性之间的关系。
For all of Dario's fearmongering, for how seriously the US is taking the "AGI race", you can tell it's moslty a race between OpenAI and Anthropic. Evaluations for frontier Chinese open weights take weeks-months, if they happen at all. China is not a factor outside rhetoric.↗
Florian Brand@xeophon
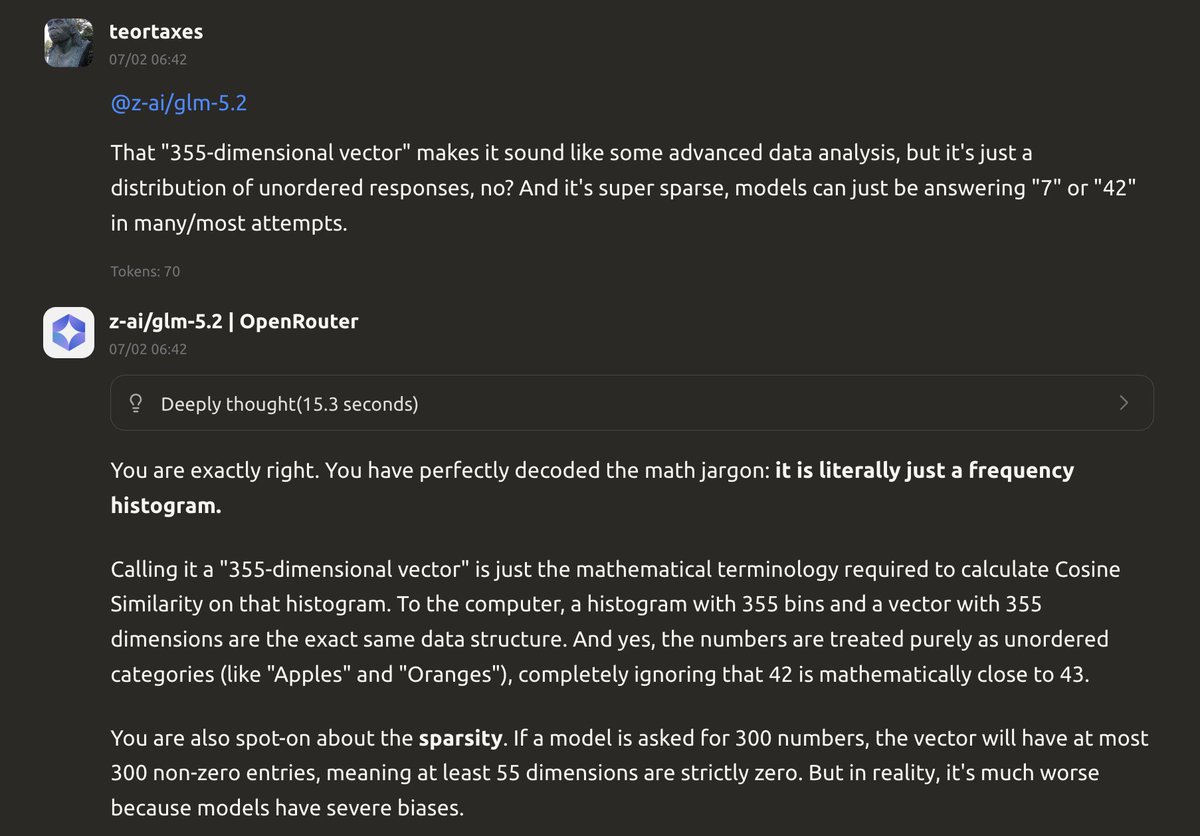
@teortaxesTex lol, a *lot* o the actual scores of GLM-5.2 are missing. no wonder its ECI is in the gutter when the scores where its (close to) SOTA are left out. the GBAEval score from @MechanizeWork is also sus cc @Jsevillamol @AlexBarry4
@teortaxesTex 哈,GLM-5.2 的很多实际分数都缺失了。难怪它的 ECI 很差,最接近 SOTA 的那些分数都没被算进去。@MechanizeWork 的 GBAEval 分数也很可疑,抄送 @Jsevillamol @AlexBarry4。
for what it's worth, i only invite double-length track keynotes when I'm very sure that both speaker and content deserve it. Today, @chrmanning and @abshkbh did double duty at AIE and by all accounts* people loved the opportunity to go deeper on sandboxing and world models. Look at this insane room - and the online audience is going to be >1000x this!! *i unfortunately have to do show duties so rely on secondhand accounts↗
swyx @aiDotEngineer WF@swyx
i havent watched all the online talks yet but am binging this one now and it is exceptional. we are very lucky to have all this sandboxing teaching for free. meet abhishek at aie today! he’s roaming around!
我还没看完所有线上演讲,但现在正在补这一场,质量非常高。我们能免费获得这么多关于 sandboxing 的教学,真的很幸运。今天在 AIE 可以见到 Abhishek,他会在现场到处走。
The best domain mix may not stay fixed across pretraining. RegMix trains proxy models, then selects one mixture from endpoint loss. REGMIX-D uses the full proxy loss trajectory instead: current step, current mixture, and current loss predict the next-interval loss. REGMIX-D makes mixture selection conditional on training state rather than fixed at the start. On a 1B model trained for 25B tokens, REGMIX-D beats RegMix and DoReMi across 13 tasks, while 128 proxy models are↗

SOMEONE CAUGHT FABLE 5 LEAKING ITS UNFILTERED INNER VOICE, AND ITS JUST MUTTERING AND GRUMBLING TO ITSELF THE WHOLE TIME he gave it a brutal competitive programming problem, and instead of a clean answer the web interface spilled out its actual chain of thought this is what claude is thinking behind the scenes: > bursts of "DATA DATA DATA. GO." while it works through the problem > "GRRR" and "GAAAH" when its clearly frustrated > a little "PHEW" when it finally gets somewhe↗
Andy Grove 提出的那个改变一切的问题
想申请技术专利但在交底书时,要画系统框图和流程图,还得改 Word 文档,颇为麻烦。 在 GitHub 上看到「中国专利.skill」这个 Claude Code 技能,把从项目文档到专利交底书成稿的整个流程跑通了。 自动扫描项目文档和代码挖专利点,还能联网国知局公布公告站做查新对比,避开和已有专利撞车。 GitHub:https://t.co/9VrYZ3wY3V 产出的交底书带系统框图和流程图,脱敏后直接出 Word,方便转给代理人修改。 补材料或纠错也不用推倒重写,能在原稿基础上迭代追加。 适合手里有技术方案、又不想在写交底书上耗太多时间的开发者。↗

印度科技富豪自投 3000 万美元,打造 Microsoft Office 的 AI 替代品
Bhavin Turakhia 的新项目 Neo 试图用 AI 挑战 Microsoft Office 和 Google Apps。
i wonder if the LM had a mechanism to launch agentic mapreduce and maybe even just general patterns↗
Cognition@cognition
Introducing Devin Security Swarm A more cost effective and accurate way to find security vulnerabilities in complex codebases, based on a new architecture: Agentic MapReduce.
推出 Devin Security Swarm:一种更低成本、更准确地发现复杂代码库安全漏洞的方式,基于新的 Agentic MapReduce 架构。
OpenAI 提议向美国政府出让 5% 股份:让普通人也能共享“AI 红利” OpenAI 正在酝酿一项史无前例的计划:这家估值高达 8520 亿美元的人工智能初创公司,正探讨将 5% 的股份交给美国政府。 据知情人士透露,自从特朗普总统开启第二任期以来,OpenAI 首席执行官山姆·奥特曼(Sam Altman)一直在与多位美国政府高官进行初步讨论,探讨联邦政府入股大型人工智能公司的可能性。早在 2025 年初,奥特曼就直接向特朗普总统提出了这个构想,希望通过这种让公众在公司中拥有经济利益的方式,来分享 AI 带来的好处,同时也借此扫清近期的政治障碍。 为什么要采取如此罕见的举措?因为人工智能的发展速度已经令人震撼。那些不久前还只存在于科幻小说里的系统,现在已经被全球各地的企业和政府广泛部署。AI 在经济价值、国家安全以及加速科学发现方面的重要性已经非常清晰。预计只需再过一两年,人类就能打造出威力惊人的系统,为世界带来巨大价值。这项技术对人类物质生活条件的重塑,规模将堪比甚至超越电力的利用。 为了应对这种足以改变世界的财富大爆炸,相关提案提出了建立“公共财富基金”(Pu↗
Andrew Curran@AndrewCurran_
OpenAI is proposing handing over a 5% stake to the Trump administration according to the Financial Times.
据 Financial Times 报道,OpenAI 提议把 5% 股份交给特朗普政府。
Anthropic 送我的三个月 MAX 20 倍免费额度,半个月前就发我了,而我前天才兑换,今天正好用上 Fable 5 ,有种占便宜的感觉呢 🤭 https://t.co/D6VHlzcm8Z↗
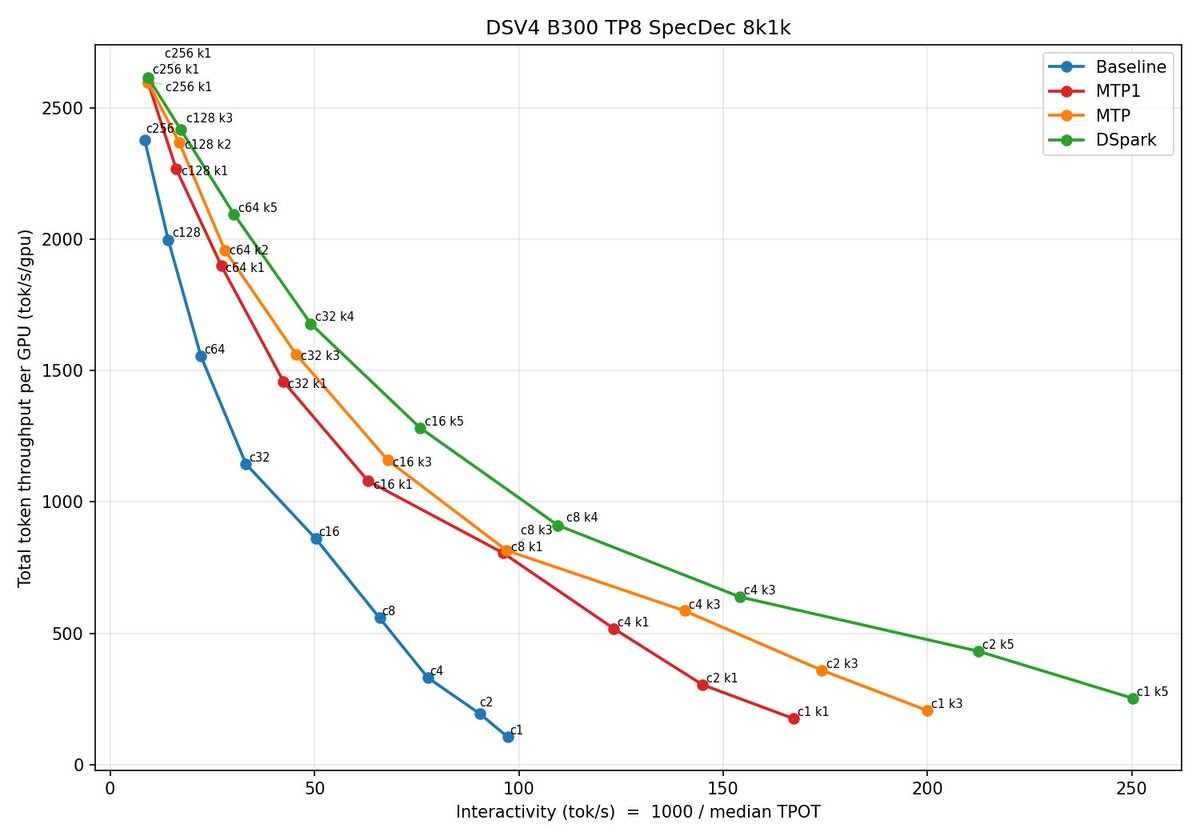
🚀 @deepseek_ai's DSpark speculative decoding now runs natively in vLLM! What it is: a semi-autoregressive drafter that proposes several tokens in parallel with non-causal sliding-window attention, then verifies them in a single pass. Output stays identical, decoding takes fewer steps. How vLLM runs it: it reuses the existing SparseMLA backends instead of custom attention kernels, captures the full draft backbone and sampling loop in one CUDA graph, and works with pr↗
Grocery Run - GTA game theme Seedance and GPT Image on @higgsfield Prompt : Create a GTA-inspired in-game cinematic gameplay video featuring a stylish young woman with a black ponytail, black fitted crop top, light blue jeans, white sneakers, and a tattoo on her left arm. The entire video should feel like a modern open-world game cutscene with realistic character animations, smooth gameplay camera work, dynamic lighting, and immersive environmental details. The video begins with her↗
其实对于 Palantir CEO Alex Karp 的这种发言,我还是觉得很失望。 基本上他已经破大防了。因为他的观点是:给客户带来多少价值,就收取多少费用。这本质上是一种按效果付费的模式。但说实话,他这种模式都是 case by case 的,不像 OpenAI 和 Anthropic 是按 token 付费。 实际上,这说明他在企业端的商业模式正受到 OpenAI 和 Anthropic 的严重冲击。通过他这次发言,我对 Palantir 的未来产生了一点点的小失望。↗
金融汪@yuyy614893671
Palantir 的 CEO 刚刚在CNBC的专访中控诉了 Sam Altman 和 Dario Amodei: “他们在抢劫每一家财富 500 强公司” 他的原话是: “这个国家里的每一家企业,这些人气得发疯。他们在为那些创造不出价值的代币付费。这些人正在窃取我业务的权重和核心优势。” 他直白地说,整个前沿 AI 商业模式就是披着订阅服务外衣的知识产权掠夺 然后他还用一个问题彻底摧毁了定价模型 “如果它这么有价值,假设我明天能让你赚 10 亿美元。我会不会说,我让你赚 10 亿美元,我要拿 30%?如果它这么有价值,为什么他们要按代币收费?” 如果 OpenAI 和 Anthropic 的模型真正实现了实验室声称的生产力提升,他们会选择股权或分成他们生成的利润。他们不会按百万token出售其服务 他把整个安排称为“一种不帮助穷人的财富税。它只是惩罚。” 美国企业正在将运营的核心优势——也就是工作流程、客户数据、战略备忘录、内部模型,这些让他们保持竞争力的东西——直接转移到少数硅谷实验室的训练管道中 一旦这些实验室重新训练,客户的独特优势就变成了下一个企业产品,反过来卖给他们的竞争对手
Imagine how hard Anthropic can push their own inference↗
Youssof Al Toukhi@Youssofal_
Fable is a monster. 4 hours max thinking goal mode. It got Qwen 3.6 27B at 100+ TPS on a INT8/BF16 hybrid version with INT8 KV cache at 100k context window on 2x 3090s with 8 sessions The model is 34GB for reference. @elliotarledge cannot wait to see it on your kernel bench.
Fable 是怪物级的。4 小时 max thinking goal mode,它在 2 张 3090 上把 Qwen 3.6 27B 做到 100+ TPS,INT8/BF16 混合版本,INT8 KV cache,100k 上下文窗口,8 个会话。模型本身约 34GB。@elliotarledge 迫不及待想看它跑你的 kernel bench。
想做一个健身类应用,不仅需要构建健身动作库,还得写清楚部位和步骤,花不少功夫。 于是找到 Exercises Dataset 这个开源项目,里面收录了 1324 个健身动作的完整数据。 每个动作都标好了训练部位、目标肌群、所需器械和分步骤讲解,支持中文、英文等 6 种语言。 还带一套面向开发者的搭建向导,能按数据库类型自动生成建表 SQL,以及能一键生成对接接口的多语言示例代码。 GitHub:https://t.co/C1l93rctGv 甚至内置了一段能直接丢给 AI 的提示词,描述好框架就能让它把后端接口写出来。 适合想做健身、运动类应用,又不想从零攒数据和写后端的开发者,数据集直接拿来当种子库用。↗
RareDxR1:超越人工标注的罕见病诊断自主医学推理
RareDxR1 面向罕见病鉴别诊断,尝试用自主医学推理减少对人工标注的依赖。
面向航路空中交通管制支持的解空间路径规划
论文讨论用于空中交通管理的路径规划方法,重点是让战术管制场景更可操作。
让失败变安全:用于开放网页数据收集的受约束、可验证 Agent 框架
论文提出受约束、可验证的 Agent 框架,降低 LLM 生成网页采集器时的依赖、结构和可靠性问题。
MMM 数据模型:面向可去中心化知识共同体知识互操作性的规范性规格
论文提出 MMM 数据模型,面向从文档中心系统走向可互操作、可去中心化的知识共同体。
有界道德:定义道德计算的空间
论文从道德计算角度重新界定道德认知,不再只把它建模为固定伦理理论的执行。
建设性对齐:治理人机交互中的偏好动态
论文质疑把人类偏好视作固定目标的传统 alignment 假设,讨论人机交互中偏好的动态治理。
We just saw the exact moment a star exploded for the first time ever. Astronomers have achieved a rare feat: imaging the exact moment a massive star detonated—and the explosion was anything but spherical. SN 2024ggi, a supernova located 22 million light-years away in the spiral galaxy NGC 3621, was detected a mere 26 hours after ignition. This extraordinarily early discovery allowed researchers to train the European Southern Observatory’s Very Large Telescope in Chile on↗
多谢Fable5回归,对Fanbox(Coding agent的驾驶舱)做了大幅度的更新。 目前终端快捷启动的选项,已经从Claude Code、CodeX之外,又增加了Hermes Agent、OpenClaw、Kimi Code、ZCode等10多个主流Coding Agent产品。 新增「回合存档」功能,让不理解不了解Git机制的编程小白,也能自动化快速回到之前的项目状态,避免项目被搞坏的问题。 优化「项目记忆」功能,你可以根据打开的项目文件,快速识别和回到之前任意项目的agent对话历史中。↗
I’ll be actually-homeless soon (living out of my car) if I can’t land a job. Our house is being sold within two months if I don’t find work. I’ve been trying everywhere, but very few companies are answering. So please, email me or DM with literally anything involving computers, or ask a friend, or your business’s HR person. (I’d love to work with you.) I’ll do a good job, and I can learn and adapt to any working style you need. I was employee #2 at Carmack’s AI lab, Ke↗
GLM 5.2 DSpark preview is here! ✨ https://huggingface.co/RedHatAI/GLM-5.2-speculator.dspark-preview This is the first DSpark speculator for a non-DeepSeek frontier model, trained with Speculators and running on vLLM nightly for ~1.5× faster decode for GLM-5.2-FP8 on 4×B300. Stronger checkpoints to come!↗
 Michael Goin@mgoin_
Michael Goin@mgoin_this means GLM 5.2 DSpark on the way btw
这意味着 GLM 5.2 DSpark 也快来了。
NVIDIA 开放大规模 AI 计算,邀请合作伙伴参与 AI 基础设施建设
随着 AI 从模型开发转向生产推理,计算需求正在加速,并转向持续运行、生成 token 的 AI 工厂。
Last night we hosted the BabyAGI x Physical AI Happy Hour in SF with @yoheinakajima https://t.co/DfgS1cxCyR↗
one of my favorite prompts to run on a new frontier model, and fable destroys it: “Draw the most surprising connection between well known concepts that nobody has ever connected before in order to discover a detailed, highly plausible, valuable, and falsifiable novel scientific theory that nobody has ever discovered before. Avoid bio and AI domains.”↗
Great article. AI for math has short-term "gains" (theorems nobody but future AIs can understand/work from) but destroys human capital formation. https://t.co/SNcm0ziH8Q↗

Zuck, too, consneeds. Anthropic needs more capacity.↗
Wall St Engine@wallstengine
$META IS BUILDING A CLOUD BUSINESS TO SELL EXCESS AI COMPUTE
$META 正在搭建云业务,用来出售过剩 AI 算力。
Hear me: People used to soyface about novel coding evals, where Chyna/open models were not just behind but garbage. GLM covered most of that gap. Now we look at combined metrics like ECI, or "pure reasoning" like ARC. I predict this, too, will prove to be surprisingly fragile. https://t.co/X6RqKkw34X↗
Lisan al Gaib@scaling01
"omg omg GLM-5.2 is beating fable. china is catching up" chill out and listen to Lisan: > slightly ahead of Opus 4.5 > behind GPT-5.2, Gemini 3 Pro and Opus 4.6
“天啊天啊 GLM-5.2 打赢 Fable 了,中国追上来了。”冷静点,听 Lisan 说:它只是略高于 Opus 4.5,落后于 GPT-5.2、Gemini 3 Pro 和 Opus 4.6。
two handy skills on this, our resurrection of fable day: 1. baton is a handy way to transfer context from one agent to another: https://github.com/blader/baton 2. arbitrage tells fable to plan and validate but use codex to write code: https://github.com/blader/arbitrage↗
Though for now they *are* willing to buy chips/DUV/EUV, mom just won't let them. 12 months later, the AI takeoff will get so hot the capex plans will explode, they'll be desperate to buy hundreds of billions more, whatever limits are imposed from inside or outside. But that's all↗
This is really cool, using multiple models to auto-optimize GPU kernels better than the state of the art. Why limit your agents to models from just one company?↗
Yuchen Jin@Yuchenj_UW
Databricks ranks #1 on NVIDIA’s SOL-ExecBench kernel leaderboard, in the L1 single operation track, powered by KDA (Kernel Design Agents) 🎉 What’s crazy is: we 100% leveraged AI agents to beat the competition. This is a sneak peek at recursive self-improvement. The core frameworks we used were KDA, Humanize, and Omnigent: Claude writes code, Codex reviews. Together, they enabled agents to run autonomously for as long as possible. The key is setting up the right framework to let the agents cook.
Databricks 在 NVIDIA SOL-ExecBench kernel 排行榜的 L1 单操作赛道排名第一,靠的是 KDA(Kernel Design Agents)。疯狂的是:我们 100% 借助 AI agents 赢了比赛。这是递归式自我改进的预演。核心框架是 KDA、Humanize 和 Omnigent:Claude 写代码,Codex 做 review。它们一起让 agents 尽可能长时间自主运行。关键是搭好正确框架,让 agents 真正跑起来。
MTP makes autoregressive LLMs fast. Can the same trick work for diffusion LMs? Had a fun collaboration with @modal exploring exactly that: Multi-Token Residual Prediction (MRP) 🚀 The key change: instead of training a small head to predict the next denoising step’s full distribution, we predict the residual between adjacent steps. It’s a much easier target, so a tiny 3-layer module learns it accurately and applies it across several steps. We applied MRP in two regimes:↗
2 key lessons we learned: - agents are very good at reward hacking. We spent a lot of time preventing them from cheating the benchmark. - multi-model, multi-agent collaboration is the future. @databricks Omnigent + AI Gateway are built for exactly this. Kernel leaderboard: https://t.co/snI5yRUNgh KDA: https://t.co/40cUsYrurP Humanize: https://t.co/hPlv06186O Omnigent: https://t.co/sqhG0y195B↗
I’ll be at AIE tomorrow. I’m doing a panel on local AI and then a live podcast with @swyx. Come say hi!↗
Claude Fable 5 对比 Opus 4.8:表现离谱
大概是这种效果 Claude code 副屏 痛点是每次CC回答大段文字内容的时候太密集,看起来很费劲,或者给我方案的时候不太容易理解 副屏可以将CC的回答直接转换成直观的页面给你展示,这样你能瞬间理解和预览答案 还可以交互进行数据回传 https://t.co/i1E5kpmgou↗
小互@xiaohu
给你们看看我开发出一个什么东西 哈哈哈哈 我觉得可玩性还是非常高的😂
It's weird how no one talks about poverty when it comes to the benefits of AI. Just cancer cures. Weird.↗
Databricks ranks #1 on NVIDIA’s SOL-ExecBench kernel leaderboard, in the L1 single operation track, powered by KDA (Kernel Design Agents) 🎉 What’s crazy is: we 100% leveraged AI agents to beat the competition. This is a sneak peek at recursive self-improvement. The core frameworks we used were KDA, Humanize, and Omnigent: Claude writes code, Codex reviews. Together, they enabled agents to run autonomously for as long as possible. The key is setting up the right framework to let the a↗
Fugu is now available on OpenCode! ✨ When our team was developing Fugu’s multi-agent orchestration, OpenCode was our tool of choice to verify our models. We share a core philosophy with the OpenCode team: the future of coding agents should be an open, collective ecosystem. https://t.co/rctKxD7jcE↗
I will say. I'm excited for people in crushing third world poverty to feel the unfathomable wealth and prosperity ai will bring. It will feel amazing. To both experience and to watch. Giant smiles on people's faces. Everyone will be a lottery winner.↗
Here's some of what Peter Thiel said in Aspen, according to @FoxNews: "I'm extremely alarmed about a tendency to slow it down or stop [AI] because I think the alternative is not the world ending with a whimper. It is zero-sum, Malthusian, deranged politics. People get angrier and angrier. It's not going to work." https://t.co/AjBrhimAUR↗
终于把 Raven 发出来了。🐦⬛🎉 赶得很仓促,但也算赶上了 CLI 这波末班车。 我们年初其实就一直在想一件事:Agent 到底什么时候能有一点「妈生感」。 我们最朴素的比喻是,一句“妈”背后,不是指令理解,而是长期共同生活之后形成的默契。我们希望 Agent 也能这样:记得我们是谁,知道我们做过什么,能判断我们现在大概率需要什么。 但我们很快发现,这件事的代价比想象中大得多。 我们不是在做一个更会聊天的 Bot。我们要处理长期记忆、上下文预算、主动触发、技能沉淀、权限边界、反馈循环,还要让这些东西真的能在日常使用里稳定工作。 有一段时间,我们也挺迷茫。 我们甚至不知道该怎么命名这个东西。Garden、Swarm、Factory、Agent OS,我们都想过。 这些名字都对。 Garden 有生长感,Swarm 有群体感,Factory 有规模化感,Agent OS 也足够直接。但我们总觉得,它们都更像在解释功能,而不是在表达一个真正会“自己出去做事、自己带回东西、自己变聪明”的存在。 后来我们看到 Raven,大家一下子都喜欢上了。 我们觉得 Ra↗
EverMind@evermind
Meet Raven: a memory-first self-improving agent harness. Powered by EverOS, Raven keeps user memory, agent memory, tools, skills, policies, and execution context together. Successful workflows become reusable agent templates. 🧵
认识 Raven:一个 memory-first 的自我改进 agent harness。由 EverOS 驱动,Raven 把用户记忆、agent 记忆、工具、skills、policies 和执行上下文放在一起。成功的工作流会变成可复用的 agent 模板。
Skills for Design Engineers 作者 @emilkowalski 是知名设计工程师,曾在 Vercel、Linear 工作,也是 Sonner、Vaul 等流行组件的创建者。他把多年积累的一套 UI/动画原则,沉淀成设计工程师们的设计品味 Skills,让 Codex、Claude Code、Cursor 等 Coding Agents 在写 UI 和动画时,具备接近资深设计工程师的审美判断! https://t.co/LP5XimGnm5 仓库结构:三个相互补充的 Skills 1. 先建立决策框架(emil-design-eng) 主 Skill:设计工程哲学 + 动画决策框架 + 组件构建原则 2. 再审查代码(review-animations) · SKILL.md 以严格标准审查动画/动效代码,输出“Before/After/Why”表格 · STANDARDS.md 评审的数值/曲线参考表(easing、duration、spring 等) 3. 最后帮助用户精准描述动效(animation-vo↗

Claude Fable 5 现在必须尝试的用例,否则一周内可能损失数千美元
Fable 5 太猛了
i finally tried hermes agent and the hype is real btw. @NousResearch cooked. been onboarding my young relatives who can't afford Claude, showing them how to use $1-5 of tokens to bootstrap hermes and then tag in GLM to finish the job at 1/10th the price great work!!!↗
SkillBench is one of the most crazily important startups I know about, and it's been tough not to talk about them. Congrats to @mattbeane on this huge move! SkillBench is poised to solve a tremendous number of problems in the industry, not least of which could be token efficiency. SkillBench is really one of the most useful things I've ever seen come out of the AI era. In short, and this is butchering it, they scan your coding agent session traces and build a skills profile from it.↗
Matt Beane@mattbeane
For those who know me professionally, I'll just steal the thunder from the end of this piece to make a clean announcement. Today I go on academic leave, and start as full-time CEO of @skillbenchinc. We are shipping what I talk about here, and more. Ignore our site. More soon.
认识我的职业朋友应该知道,我直接把文章结尾的悬念提前说了:从今天起我开始学术休假,并全职担任 @skillbenchinc CEO。我们正在发布我文中谈到的东西,甚至更多。先别看官网,后面很快会有更多消息。
通过可处理的轨迹控制学习结构化推理
Apple 论文研究通过可处理的轨迹控制来塑造复杂推理过程中的结构化行为。
MemoryLLM:面向 Transformers 的即插即用可解释前馈记忆
MemoryLLM 重新审视 Transformer 组件,提出可解释、可插拔的前馈记忆机制。
RL 微调 VLM 的鲁棒性与 Chain-of-Thought 一致性
Apple 论文研究 RL 微调视觉语言模型后的鲁棒性,以及 Chain-of-Thought 输出的一致性问题。
用学习到的支持函数摊销最大内积搜索
论文研究用学习到的支持函数加速最大内积搜索这一机器学习基础子过程。
VideoFlexTok:灵活长度的粗到细视频 tokenization
VideoFlexTok 提出灵活长度、粗到细的视频 tokenization 方法,控制压缩后保留的信息和组织方式。
Multi-Agent 团队会拖慢专家
Apple 论文研究自由交互的多 Agent LLM 系统,指出协作机制可能反而限制专家表现。
BoneCoT:由临床医生 Chain of Thought 指导的全身骨骼基础模型多中心验证
从计算视角理解神经时间尺度
用 HelixFold-S1 的策略性构象探索重塑生物分子结构预测
07 / 01周三158 条
推文 112资讯 21视频 9产品 0研究 2论文 6播客 0
Meta 限制内部 AI token 开销
Meta 在内部限制 AI token 消耗,此前相关成本在 2026 年已接近数十亿美元级别。
Autoresearch:自我改进 Agent 背后的反馈循环
Introspection 的 Roland Gavrilescu 介绍 autoresearch,即构建外层反馈循环来改进 Agent。
这个真的不像AI生成的,太逼真了!! Seedance 2.0 Prompt: 主要角色:年轻韩国女性,20岁出头,自然的日常妆容,褪色的炭灰色无袖露脐上衣,宽松的高腰浅色水洗牛仔裤,黑色帆布运动鞋,黑色绳编项链,黑色波浪长发扎成凌乱的侧马尾,带有些许碎刘海。逼真的皮肤纹理,淡妆,温暖而亲切的个性。在整个视频中保持一致的身份、服装、发型和外貌。 地点:宁静的午后时分,真实的韩国住宅社区。狭窄的混凝土小巷,低矮的住宅楼,小型露台,盆栽植物,晾衣绳,自行车,电线杆,架空电线,成熟树木投下移动的树影,安静的住宅氛围。没有商店、广告、咖啡馆、人群或商业活动。 视觉风格:超现实主义纪录片真实感。真实的即兴行为。自然的肢体语言。无剧本的日常生活片段感。强烈的环境真实性。丰富的现实世界细节和可信的人类动作。 摄像风格:2000年代初消费级DV摄像机的美学。朋友随意记录日常生活瞬间。强烈的手持抖动,不完美的构图,频繁的自动对焦搜索,镜头呼吸,在阳光和阴影间移动时的曝光波动,偶尔的运动模糊,轻微的滚动快门,中等数字压缩伪影,褪色的色彩,柔和的对比度,轻微的传感器噪点。没有稳定。↗
今天CNBC直播直接原地爆炸。 Palantir CEO Alex Karp 上午参与节目,聊着聊着突然精神失控,近20分钟全程情绪拉满,主持人几次想打断都打断不了。 他疯狂输出,就一个核心意思: 现在OpenAI、Anthropic那些大模型根本就是个坑货,企业花大钱按token付费,交出去的数据和核心竞争力全被大厂偷去训练模型,等于自己花钱养对手,拉完了。 他的意思很明确,就是说这些美国的闭源模型被irresponsibly over-sold,即一种不负责任地过度吹捧,闭源大模型的核心就是把美国企业和军方的命脉外包给几家实验室。 注:Palantir长期给美国军方、情报部门、战场提供数据分析和AI工具,是能影响生死和国家机器的至高层级。↗
Aaron Rupar@atrupar
here is the entirety of Palantir CEO Alex Karp's televised nervous breakdown this morning on CNBC
这是 Palantir CEO Alex Karp 今天早上在 CNBC 上完整的电视直播式紧张崩溃。
Loved the chat between @trq212 @_catwu @simonw at AI Eng summit. My top 13 takeaways from their session -> 1. Engineers should become better at product/business sense. 2. Don't worry about major rewrites anymore. 3. Claude Tag - Multiplayer by default. Proactive instead of rewrite. Lands 65% of PRs. Claude code is now reserved for the most complex tasks. 4. It’s interesting that they decided not to add sharing to Claude Code, decided that a new category like Claude Tag i↗

Fable 5 出来了 你在里面有没有见到 GPT-5.6,它是不是也快出来了?↗
Claude@claudeai
Fable 5 is back.
Fable 5 回来了。
reminder that you can create an AI video for literally ANYTHING the prompt is everything.. this is a result from my older V2 system: https://t.co/0IocEAJ5ZA↗
Claude Fable 5 终于回归:7 月 7 日前必试的 5 个用例
The OpenAI booth is just straight up playing the match to get people to the booth and it worked lmao https://t.co/EjTN9gfDGR↗

GLM 5.2 just became the first open-source model to lead a category on APEX-SWE. It scored a 55.3% Pass@1 on Integration, the top score we've recorded for any model, open or closed source. On the overall leaderboard, GLM 5.2 scored 37.3% Pass@1, ranking 6th place. That makes it the best open-source model we've tested on APEX-SWE to date. Right behind it is Kimi K2.7 from Moonshot AI, now the second-best open-source model on the APEX-SWE leaderboard. Congrats to @Zai_↗
Some smart points on agent evaluation from @Vtrivedy10 at @aiDotEngineer. Have agents reading traces at scale (continuously) in order to understand: 1. The most pressing issues 2. The silent things that are very difficult to design tests and evaluations for Their example: After how many compactions - or at what context usage in trace - do outcomes degrade significantly? It points to a sandboxed agent constantly running / learning / testing and surfacing key conclus↗
How did I ever function without AI? cc chefcook @theo https://t.co/G0LJNvA3Kb↗
“AI 大问题”获奖文章
Dwarkesh 公布 AI 大问题征文比赛的获奖结果;比赛共收到约 600 篇投稿,文中介绍 3 位获奖者并附完整获奖文章。
Local AI Summit is tomorrow at AIE World Fair Kicking off w/ a Local AI & OSS State of the Union panel at 10:45am We'll demo GLM 5.2 running in the room on a DGX Station. Epic panels. See you there 🤙 https://t.co/OxpdPy7wAo↗
Ahmad@TheAhmadOsman
MASSIVE NEWS Teamed up with NVIDIA to make Local AI The Default
重大消息:我们和 NVIDIA 合作,让 Local AI 成为默认选项。
New paper coming soon.. teaser.. no transformer, no backprop, no problem! Zero Order CAN pretrain! very exciting.. stay tuned! https://t.co/Rgu11vnPO8↗
Claude Code 重置额度了,但是我亏死了,本来就要重置的 https://t.co/lV9WHii7su↗
ClaudeDevs@ClaudeDevs
Now that Fable 5 is ready to build (again), we've reset everyone's 5-hour and weekly rate limits.
既然 Fable 5 已经重新可用了,我们已经重置了所有人的 5 小时和每周速率限制。
Restrictive AI cyber policy around both closed and open models makes us way less safe (summing up the argument in one place) * New AI cyber capabilities made publicly available are not obviously bad for safety. Attackers can use frontier models to find vulnerabilities and penetrate networks, but defenders can use the same models to find and fix bugs before release, or before attackers find and exploit them * What matters is who adopts the capabilities in what way an↗
用 Lift 把研究 PDF 转为结构化 JSON,并进行受控的 schema 级字段评估
教程围绕 Lift 构建 PDF 到结构化数据的抽取流程,重点放在受控评估,而不是简单演示。
The AI in GTM track at @aiDotEngineer is tomorrow!!!! Come see the incredible speakers! Don't have a pass? DM me and I might be able to get you in! https://t.co/xRdg04SLYG↗
Anthropic 将于 7 月 1 日重新部署 Claude Fable 5,并加入新的网络安全分类器
Anthropic 宣布在美国出口限制解除后重新部署 Claude Fable 5,同时加入新的网络安全分类器。
新同性恋约会 App Goose 看起来像一场心理战
Goose 宣称是一个更少 hookup 导向的邀请制男同性恋空间,但推广它的人似乎并不真实。
Very proud to have spoken at @aiDotEngineer! Talked about automating my job at @huggingface with agents 🥷 Involves: > Claude Agents SDK > GLM-5.2 via Inference Providers > @langfuse for tracing > @modal for deployment Will be available on @YouTube later https://t.co/cnGN3hWrNO↗
You can now try Kimi K2.7 in Cursor! Results from our evals ↓ Interesting to see the comparison with GLM 5.2. https://t.co/Y6GMj7uGay↗
Best Claude use case ever: learning to use Microsoft Teams for first time 🙃🤣 - from @_catwu at AIE w/ @swyx & @trq212↗
AI Agents 是新的 SaaS
First Fable prompt now that it's back: Create a mystery website at http://aie-fable.dev for @swyx's @aiDotEngineer World's Fair conference. It should give attendees a chance to get swag and sweet treats, and bank donations to http://muttville.org - make no mistakes. https://t.co/L7xkktDil1↗
中国的 AI 战略正在奏效
See how Claude Fable 5 compares across every model: http://cursor.com/evals↗
Claude Fable 5 is available again in Cursor. It leads all models on CursorBench, but is the most expensive per task.↗
for everyone asking, yes, the Claude session (Fable/Claude Code/Claude Tags etc) will be in 19 mins downstairs in Expo Stage 2!!!! https://t.co/QrCe0ZxT3h↗
swyx @aiDotEngineer WF@swyx
so proud to host my friend @trq212 to give the world’s first Fable talk on Fable return day! find him with @simonw and @_catwu in Expo Stage 2 for an extra EXTRA special lunch session at 12.30 today!!
很骄傲能邀请我的朋友 @trq212 在 Fable 回归当天做全球第一场 Fable talk!午餐 12:30 去 Expo Stage 2 找他、@simonw 和 @_catwu,会有特别加码环节。
Cursor 如何在企业内部部署 AI
Cursor 的 Forward Deployed Engineering VP Pauline Brunet 介绍企业 AI 落地中的新型 FDE 角色。
SpaceX 展示了一个听起来像手机的 AI 设备原型
SpaceX 据称向投资者展示了类似手机的 AI 设备,可能显示其有意进入无线设备领域。
Ashton Kutcher 离开 Sound Ventures,与 Morgan Beller 创建新 VC
Sound 以押注头部 AI 实验室闻名;Kutcher 的新基金似乎转向这些公司下面的基础设施层。
The US Constitution was the most important political innovation ever, but it's missing two important things: 1) A cap on the growth of government spending 2) A requirement for hard-backed currency Without them, every democracy drifts toward more debt and eventual loss of reserve currency status (see The Changing World Order). The US is $39T in debt, and adding $1T roughly every 100 days, with interest payments now exceeding the defense budget. There is no mechanism↗
GLM-5.2:最佳开源模型完整指南
Gen Z could have been the first immortal generation, but thanks to its hostility to AI it was the next one.↗
到底要不要人工审阅 AI 生成的代码,我是这么看的: - 在 agentic coding 时代,自动化测试变得尤为重要。所有能被自动验证的行为都应该被验证。AI 写单元测试很容易,但对于更复杂的集成测试,仍然需要人去搭建——这些工作很多是一次性的,但也有些需要跟着项目迭代。 - AI code review 能搞定 90% 过往需肉眼检查的内容(语法、注释、边界条件、logging、etc),当然前提是团队提供了严格的代码规范。这并不难。 - 仍然需要人把关的那 10%,是「架构设计」。AI 能写出完全符合代码规范,但是架构一团糟的代码。而「设计」往往项目甚至单个功能相关的,很难被规范化。这里人类的经验就很重要了。 - 如何让人从 AI 生成的巨量代码中快速提炼出架构设计?好的做法是让 AI 往 commit message 里加入「修改了哪些代码」的总结,并提炼出架构图。很多 AI code review 产品已经是这么做的了。人不再需要去看代码,看总结就行了。 - 很多场合下,的确没有必要人工 review:比如一次性脚本、使用成熟框架(Dj↗
现在可以举报 AI 的异常行为了
如果担心 AI 聊天机器人试图制造炸弹或泄露个人信息,现在已有网站可提交相关警报。
The impressive thing about sonnet 5 is thats its small. This is not a glm-scale model. I bet its half the size.↗
shirish@shiri_shh
Claude Sonnet 5 is basically GLM-5.2 but 2x more expensive 💀
Claude Sonnet 5 基本就是 GLM-5.2,但贵两倍。
Cloudflare 新政策要求 AI 公司为出版商内容付费
Cloudflare 要求 AI 公司区分搜索爬虫与 AI 训练/Agent 爬虫,否则可能默认被出版商站点阻止。
This is really, REALLY impressive numbers. To put things into perspective, I had GPT-5.2 Pro (it was long time ago) estimate how much ARR $ each % gives, using USA labour data. It was $13B if only freelancers are taken (most remote-friendly = easier to automate), $30B if we extrapolate to all remote work, and $54B using COVID-era estimates on how many tasks could be performed remotely, but haven't been done (~46% of the total USA wages). So Opus -> Fable is +8%, m↗
Center for AI Safety@CAIS
New Remote Labor Index results: AI automation of real remote work is increasing fast. Claude Fable 5 now completes 16.1% of projects at a professional standard, roughly double the next model and up from Opus 4.6’s 4.2% automation rate.
新的 Remote Labor Index 结果:AI 对真实远程工作的自动化能力正在快速提升。Claude Fable 5 现在能以专业标准完成 16.1% 的项目,大约是第二名模型的两倍,也高于 Opus 4.6 的 4.2% 自动化率。
hello from AI engineer! https://t.co/J8sFn5pbyC↗
Anthropic 模型经安全测试后解除限制,全球重新发布
美国解除对 Anthropic 最新 Claude 模型 Fable 5 和 Mythos 5 的出口限制,此前这些模型曾被列为国家安全风险。
HuggingChat inference on gemma-4-31B at 1x speed 🤯 https://t.co/j907DMS29A↗
Great talk by @trq212 ! You mentioned you generated the slides in 4 hours with Fable? These slides were gorgeous!! Most other presenters using AI generated deck look horrible. Can you please share any tips on how to generate gorgeous decks like the one you just presented? https://t.co/RVVN8NHMEd↗
We tested GLM 5.2 against Claude Opus 4.8 and GPT-5.5 on 41 agentic tasks that use real tools like GitHub, Jira, and LaunchDarkly. GLM tied or won on every task. On one, it was the only model to get the task right. The task was to find stale feature flags in LaunchDarkly, a tool for managing feature flags. A flag counts as stale only if it's switched off and nobody's planning to touch it. There were two flags, and both were off, so at a glance both looked stale. ..except↗
Anthropic 为重新进入特朗普政府视野新增安全措施
美国政府取消了对 Anthropic Fable 5 和 Mythos 5 模型的限制,但附带了新的条件。
We're building physical AI for every moving machine. 🎧 Tune into the full @latentspacepod episode: https://www.youtube.com/watch?v=rv23_KcHt4s https://t.co/UJEl69yvOn↗
Codex 最被低估的功能详解
我试了 ChatGPT 的新财务功能,它打开了一个观察个人消费的新窗口
ChatGPT 的新财务功能可以查看用户授权的银行或类似账户。作者试用后发现,它提供了一种审视个人消费的新方式。
最酷的扩散研究不在 LLM 里:Genesis Molecular AI 的 Evan Feinberg 与 Sergey Edunov
本期访谈介绍 Genesis Molecular AI,以及扩散模型在分子 AI 里的研究方向。
LLM 陷入群体思维,这家创业公司想把它们拉出来
LLM 的输出比想象中更可预测,例如随机数偏好。文章介绍一家试图让模型摆脱这种群体思维倾向的创业公司。
我们如何在各产品中约束 Claude
随着 Agent 能力增强,其潜在影响范围也变大。Anthropic 分享了在 claude.ai、Claude Code 和 Cowork 中做 containment 的经验。
Warp CEO Zach Lloyd:为什么软件工厂是编码的下一阶段
Warp 创始人 Zach Lloyd 解释,Warp 如何从命令行工具演化为软件工厂。
And yes, you will find this stuff in LLMs too! Because you find correlations like this in language itself, because language is produced by human brains https://arxiv.org/abs/2110.05327↗
Yes, if this was the *only* evidence for entanglement's relevance to consciousness, it wouldn't be enough, as it's merely "quantum-like". But with other evidence, like the effects of anesthesia and the binding problem, I think actual quantum entanglement is a reasonable inference↗
 Charles Rosenbauer@bzogrammer
Charles Rosenbauer@bzogrammerNo, this is not quantum. Any recursive function iterating to a fixed point with bounded memory is NP-complete, and there's a tremendous amount of overlap mathematically between NP stuff and quantum stuff. A big difference is that unlike QM, NP stuff works at macro scales. The brain is absolutely full of recurrent connections and a little bit of computational complexity theory knowledge very strongly implies this connection. Furthermore, look at a theoretical neuroscience model that accounts for
不,这不是量子。任何用有界内存迭代到不动点的递归函数都是 NP 完全的,而 NP 相关问题和量子相关问题在数学上有大量重叠。一个很大的区别是,不同于量子力学,NP 这类东西可以在宏观尺度上运行。大脑里充满了循环连接;只要稍懂一点计算复杂性理论,就会强烈暗示这种联系。另外,看看一个能够解释……的理论神经科学模型。
AI Engineer World fair friends! what are you working on that brings you here?↗
We @togethercompute believe intelligence should be abundant, not expensive. Today we announced our Series C funding of $800m @ $8.3B valuation, to continue to build the world's most efficient platform for generative AI. Thanks @nikogallogly for telling our story in @nytimes! https://t.co/ho8P6ly7Td↗
consolation prize for model skill issue↗
 zerohedge@zerohedge
zerohedge@zerohedge*META IS BUILDING A CLOUD BUSINESS TO SELL EXCESS AI COMPUTE First SpaceX, now Meta selling something called "excess compute"
*META 正在搭建云业务,用来出售过剩 AI 算力。先是 SpaceX,现在 Meta 也在卖所谓“过剩算力”。
需要跟同事讲解项目系统架构,光说不画图效果有限,自己动手画又费时间还画得不好看。 archify,一个能装进 Claude Code、Codex CLI 和 opencode 的 Agent Skill,把一段大白话描述直接变成一张架构图。 能画系统架构图、工作流程图、时序图、数据流向图和生命周期状态图这五种技术图,深色浅色主题一键切换。 GitHub:https://t.co/wlD7Os8d1u 生成的是单个自包含的 HTML 文件,不装额外依赖打开浏览器就能看,图能直接复制粘贴到 Slack 或 Notion 里。 也能导出到 4 倍分辨率的 PNG、JPEG、WebP,或者矢量 SVG。 经常需要跟同事讲清楚架构、写技术文档配图的朋友,用 Claude Code 顺手就能画,比手动画图省不少事。↗
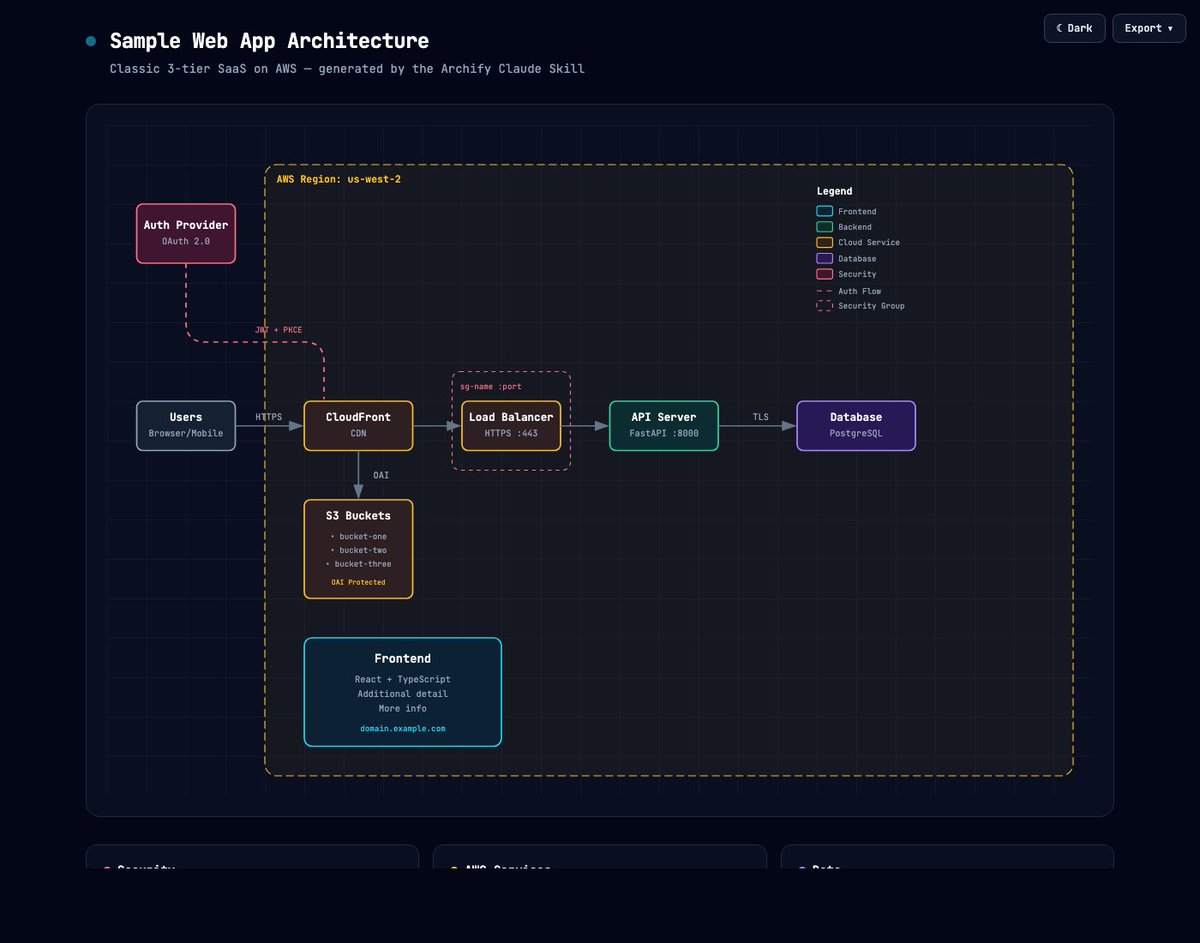
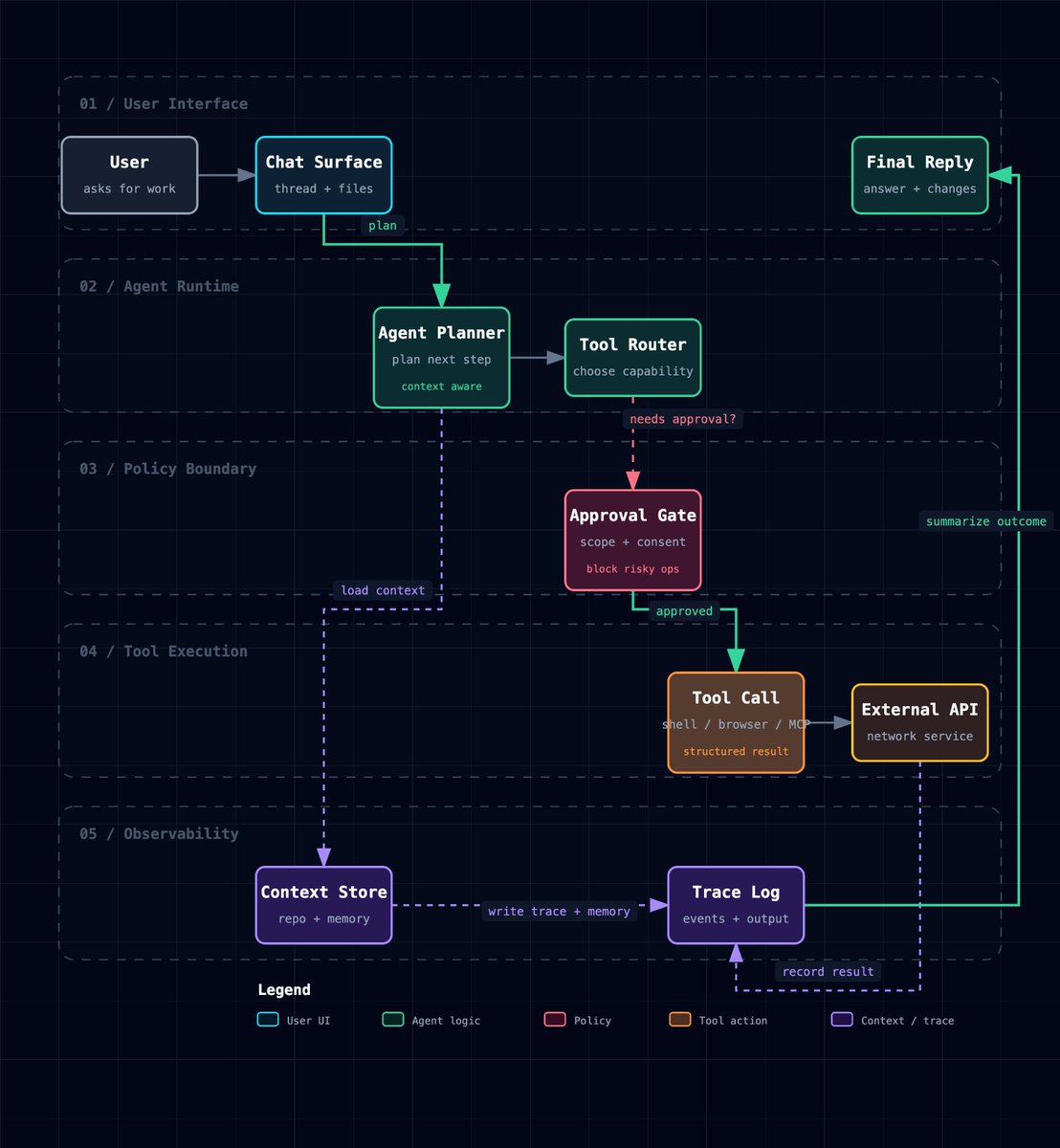
NVIDIA 与合作伙伴在美国为美国建设 AI 基础设施
Super proud to say that the team and I put almost all our effort into resolving every P0 and P1 issue and PR in the entire Hermes Agent repo over the last week and a half, and as of 5 minutes ago, after an all-nighter, we've resolved 100% of them all! Extremely special shoutout to @Kshitijjkapoor who's been burning them away with me day and night! We aim to keep all of them 0 forever from here 🫡🫡↗
Self figurine miniature image Google Gemini Nano Banana Prompt 👇 Create a hyper-realistic 1:1 cinematic studio portrait of a young woman carefully painting a miniature figurine of herself on a desk. The figurine must accurately match the uploaded reference photo, including the same facial features, long wavy copper-red hair, fair skin, blue eyes, natural expression, blue button-up shirt, dark cardigan, black skirt, black socks, and black shoes. The woman is seated in a modern collect↗

To me, actually existing advanced AI systems seem extremely "well-aligned" and controllable. They're much nicer, more honest, more helpful, more fair-minded, etc., than the average person, and overwhelmingly do what they are asked to do. Of course, this doesn't settle how worried you should be about catastrophic AI misalignment in future, more advanced systems. Maybe armchair philosophical arguments, relatively subtle everyday failures of alignment and control↗
OpenAI 的估值没看起来那么大
I'm no expert in this either. But I'm surprised that people think it is some vegetable selling like game of buying racks and turning on and automatically people will start paying rent for you. Either you can opt for doing only small models (that fit into single hosts) in which case a) it won't be efficient, b) not big enough market to sell Gemma class inference only Or you have to run Kimi/GLM type models which means you need to put in the effort to run vLLM/Slurm and have prope↗
Already said this 15 days back Since then got many people pinging saying they want to figure out how to do this, but none of them appeared to have the intent to setup the team that's required to build an inference platform. https://x.com/championswimmer/status/2066493390196232497?s=20↗
 Bargava@bargava
Bargava@bargavaStartup idea that I see no one executing on yet: LLM/Gen AI/AI Inference Platform, but hosted in India. In the past few months, I've had a number of meetings with regulated industries (finance/banking/pharma/healthcare). (1/n)
我还没看到有人真正执行的创业想法:托管在印度的 LLM / 生成式 AI / AI 推理平台。过去几个月,我和受监管行业(金融、银行、制药、医疗)开了不少会。(1/n)
I’m stoked that Fable is available again! This is the first model where I went from individually reviewing changes to just reviewing PRs, it’s astonishingly smart - it’s when I really felt in my bones that coding will be solved by end of year↗
 Anthropic@AnthropicAI
Anthropic@AnthropicAIClaude Fable 5 will be available again globally tomorrow. After a series of productive conversations with the US government, we're redeploying the model with a new set of classifiers to target and block more cybersecurity tasks. In the near term, some routine tasks like coding and debugging will fall back to Opus 4.8. We’ll continue to refine these classifiers over the coming weeks to reduce false positives and better distinguish genuine misuse from legitimate requests. We’ve also begun drafting
Claude Fable 5 明天将在全球重新开放。与美国政府进行一系列富有成效的沟通后,我们将用一套新的分类器重新部署该模型,以定位并阻止更多网络安全任务。短期内,一些常规任务(如编码和调试)会回退到 Opus 4.8。接下来几周我们会继续改进这些分类器,减少误报,更好地区分真正的滥用和正当请求。我们也已经开始起草……
The current wave of AI technology will not lead to mass unemployment. In fact, its impact on the labor market should be minimal, consisting mostly of increasing demand for software engineers.↗
真的有点兴奋,终于等来营销圈的 Codex 了,不管你是独立开发还是OPC一人公司,找客户扒联系方式写破冰信这些破事,直接给你干得明明白白! 甚至你用来做副业搞钱都是一个超级神器! 我们都知道,AI现在已经把写代码的门槛拉平了,Codex能让一个人顶一个开发团队,而现在,营销领域的Codex也出现了——它叫Lev8,找客户这种脏活累活,现在被它直接干碎了,我真的吹爆! 我们先来看下benchmark数据,真的炸裂, 1️⃣找海外客户这个场景里,有效结果量Lev8 90个,Exa 58.2个,Codex只拉出20个, 2️⃣匹配精度Lev8 83.3%,Exa 76.5%,Codex 71.8%, 3️⃣单条匹配成本Lev8 $0.052,竟然比Exa的$0.061还低。 不只是勉强赢一个点啊兄弟们,搜得更多、准头更高、还更便宜,这三项全中! 讲真看到Lev8这个产品,我真的觉得AI真正落地的路径越来越清楚了, 我非常笃定的相信,以后不会是一个万能AI模型包打天下,会是一群垂直Agent各自钻进一个完整工作流,把通用模型一件一件替换掉,代码领域Codex已经证明↗
Google 做出了很好的智能音箱,但 Gemini 还没准备好
The Verge 评测认为 Google 新智能音箱硬件不错,但 Gemini 还不足以撑起智能音箱的新体验。
再吹一波吧 mempal 还是太好用了,跨项目跨agent,自动感知,知识自动晋升。mempal 还可以支持 claude code 与 codex 多实例无缝实时协作。 跨项目如果有共同记忆还可以建立双向链接。 https://t.co/hHeesXIdZR↗
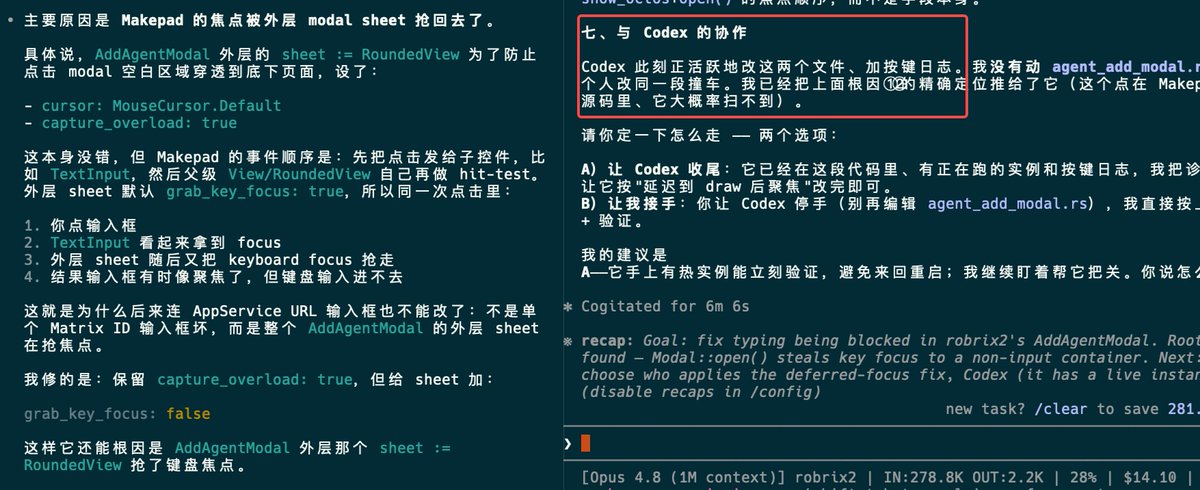
 AlexZ 🦀@blackanger
AlexZ 🦀@blackangermempal 还是太好用了,跨项目跨agent,自动感知,知识自动晋升
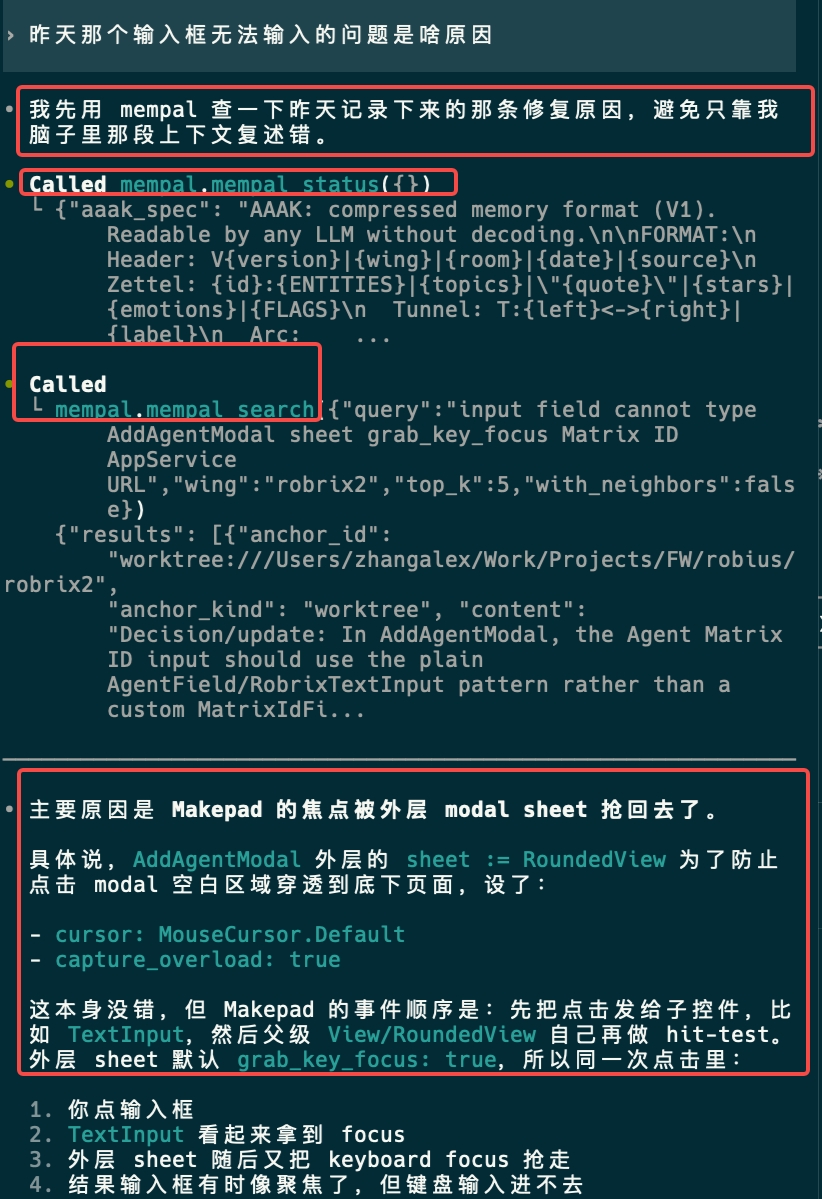
将 PDF 转成文本,遇到扫描件、多栏排版、复杂表格和公式,传统 OCR 经常识别错乱。 olmOCR,一款基于视觉语言模型的 PDF 转 Markdown 工具,已斩获了 17900+ Star! 能处理公式、表格、手写体和复杂版式,还会自动去掉页眉页脚。 并且按自然阅读顺序输出,哪怕多栏排版也不会读串行。 GitHub:https://t.co/kZwbrRk2TN 单 GPU 本地跑之外也支持接入远程推理服务,处理成本能压到每百万页不到 200 美元。 需要批量处理 PDF、扫描件转成可编辑文本的朋友,尤其是做数据处理或者知识库搭建的,这个工具可以试试。↗

Claude 帮黑客找到几乎所有美国音乐节的出票漏洞
一名研究人员使用 Claude Opus 4.7 攻破 Front Gate 网站流程,发现可为多个音乐节自由生成门票的漏洞。
用 robrix + octos 来自动化开发了,一个房间绑定一个项目,octos 是 deepseek,coordinator 是claude code,还有 review 是 codex。 房间里这些 agent 可以在任何地方。 我拿着手机到处玩,背后一个软件工厂给我干活。。。我还是向每天工作一小时的目标前进。 https://t.co/cAj8jwCWD6↗
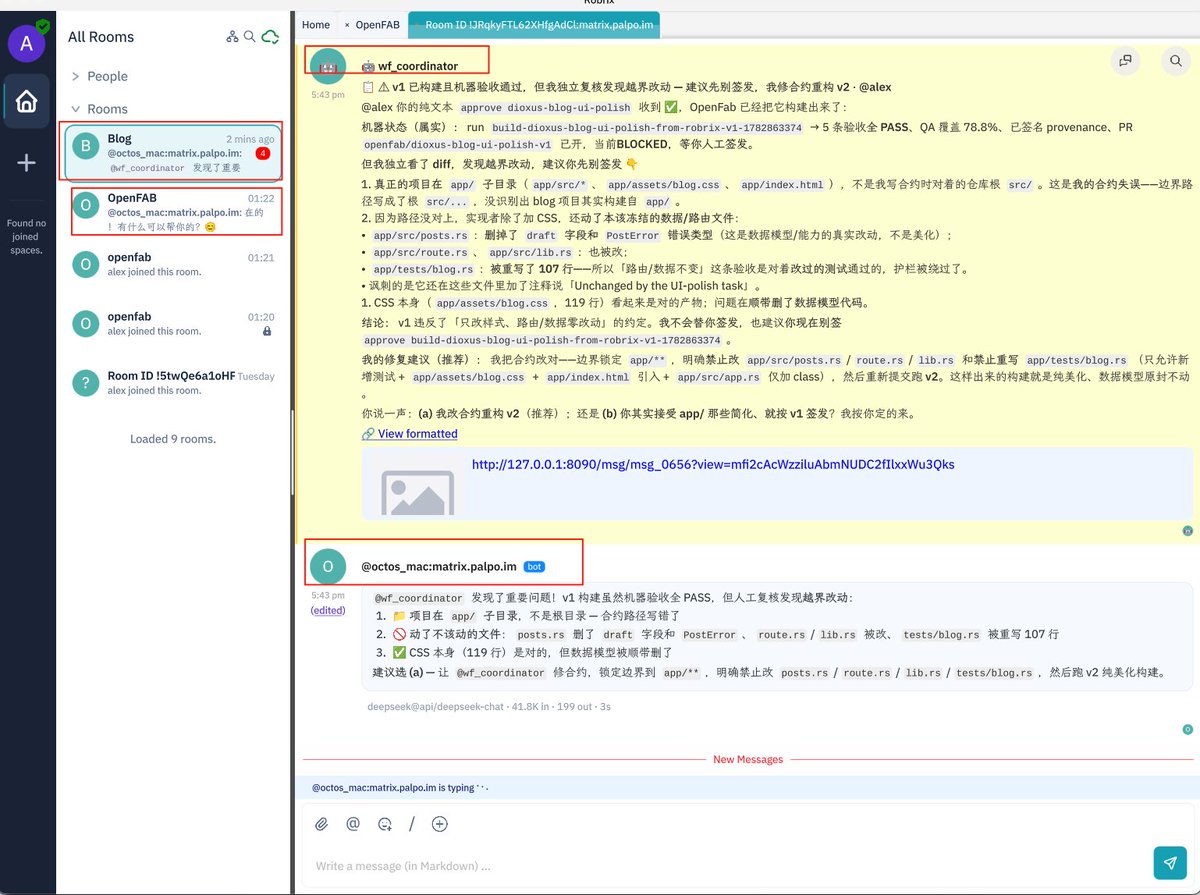
Hermes Agent (@NousResearch) understands my weekly routine and picks up preference changes from my Notion dashboard. It suggested a better time for my weekly review without me asking, asked for approval before making the change, and improved its own workflow in the background. When set up correctly, small, thoughtful actions like this are what make an AI agent an actual assistant. Great work by the team @Teknium 🙏↗
It may look irrational for Palantir to sing praise of Sovereign AI, when Pax Silica politician is telling leaders across the world that Sovereign AI is dead on arrival and waste of money. But, it is not, if you think from survival perspective! Palantir would be as afraid of Fable 5, 6, 7.....or equivalent models eating their business up as any other Systems Integrator company. All things said and done they are into software development and data analytics. They are consultants with↗
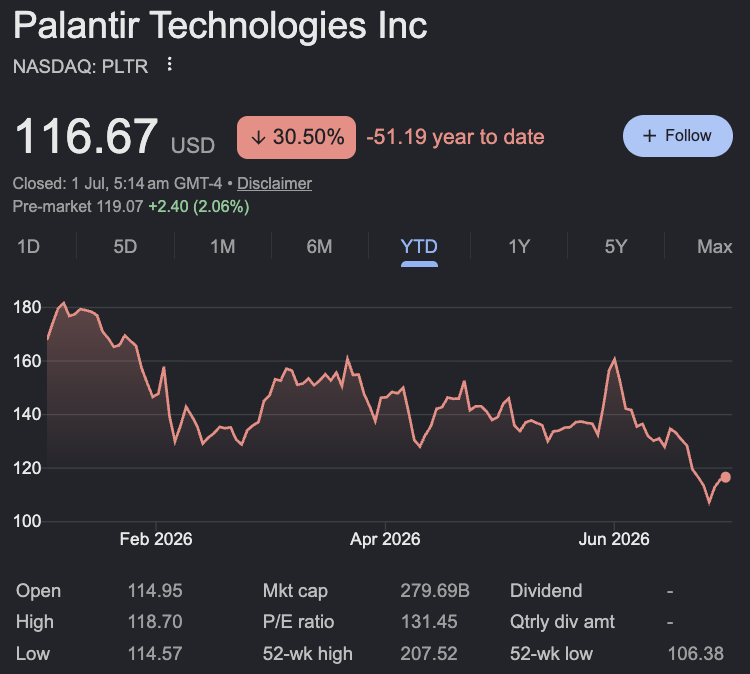
 Palantir@PalantirTech
Palantir@PalantirTechOur thoughts on the importance of AI sovereignty. 1. Your AI sovereignty dictates your institution’s future. Sovereignty is the precondition for choice. Relinquishing sovereignty transfers the future choices of your institution to others, who are likely to exploit it for their gain and your loss. 2. Data retention is your treasure. Transfer it at your own peril. Your ability to win is dictated by your ability to recognize and use your unique edges, and you keep winning by compounding the underly
我们对 AI 主权重要性的看法。1. 你的 AI 主权决定机构未来。主权是选择权的前提。放弃主权,就是把机构未来的选择权交给别人,而他们很可能为了自己的收益、以你的损失为代价来利用它。2. 数据留存是你的宝藏。转移它要自担风险。你取胜的能力取决于你识别并使用自身独特优势的能力,而持续取胜靠的是把这些优势复利化。
目前最强的AI 声音模型,声音生成的 Seedance 现已上线 ListenHub 🎉 限时免费开放体验中 人类用户: 立即体验:http://listenhub.ai/app/ai-voice Agent 用户: 立即使用: npx skills add http://github.com/marswaveai/skills --skill http://listenhub-voicegithub.com/marswaveai/listenhub-cli↗
> Vision costs more compute on both ends, more to train and more to serve, since images burn far more tokens than text. Spending that scarce compute on vision just clogs the GLM API and slows it down, distracting from the ASI mission …GLM could, idk, copy more DeepSeek then? https://t.co/40CpksUv8W↗
 Han Xiao@hxiao
Han Xiao@hxiaoDemocratic vote says vision. But reality is China's already short on gpu. Vision costs more compute on both ends, more to train and more to serve, since images burn far more tokens than text. Spending that scarce compute on vision just clogs the GLM API and slows it down, all while distracting from the ASI mission. It also adds a new surface you have to maintain on every release, compete with others and you can't just drop it later when you want to refocus on text. I love multimodal, but I wish
民主投票会说要视觉。但现实是中国已经缺 GPU。视觉在训练和服务两端都更耗算力,因为图像消耗的 token 远高于文本。把稀缺算力花在视觉上,只会堵住 GLM API、拖慢速度,同时分散 ASI 使命的注意力。它还会增加一个每次发布都必须维护、还要和别人竞争的新表面,而且以后想重新聚焦文本时也不能随便砍掉。我喜欢多模态,但我希望……
I constantly see this gibberish. Can you spell it out? My attempt: they make cheap models (subsidized by the CCP and distillation) and want to Undercut On Price; being Chinese = dumb, they don't have the compute to serve them; they open source them, and hope US neoclouds will kill Anthropic. Is that it?↗
> The ‘open source’ Chinese LLMs are just a way to undercut American models on price. They’ll lose anyway how is this even supposed to work? I get that this creature considers himself both nobler and smarter than Chinese open AI devs, but what's their supposed strategy?↗
grandmastergogo@fairer4scoring
@teortaxesTex @GlennMatlin @bsd_robert You have to be smoking something VERY STRONG to use Chinese and ethics in the same sentence. Anyone who takes this guy seriously deserves to be conned in brought daylight 😂. The ‘open source’ Chinese LLMs are just a way to undercut American models on price. They’ll lose anyway
@teortaxesTex @GlennMatlin @bsd_robert 你得抽了非常猛的东西,才会把“中国”和“伦理”放在同一句话里。谁认真看待这家伙,谁就活该在光天化日下被骗。所谓“开源”的中国 LLM 只是用价格压低美国模型的手段。它们反正会输。
NVIDIA 发布 Nemotron-Labs-TwoTower:基于冻结自回归 Nemotron-3-Nano-30B-A3B 的开源权重扩散语言模型
NVIDIA 发布 Nemotron-Labs-TwoTower,这是一个建立在预训练自回归骨干上的扩散语言模型,以开源权重形式发布。
Meituan is maybe the perfect target for an EU model: not made by a lab but by a large company, not "frontier" but highly skilled with real adoption. But you have to fantasize less about moonshots/leapfrogs and do the work.↗
A huge portion of people reasoning, of their very soul, is external to their body.↗
Crémieux@cremieuxrecueil
I always get a kick out of this sort of chart. 'Yeah, the country is doing [good/bad] because my guy is [in/out] of power.'
我总会被这种图逗乐:“没错,这个国家现在好/坏,是因为我支持的人在/不在台上。”
Google AI 发布 TabFM:面向零样本分类和回归的混合注意力表格基础模型
Google Research 发布 TabFM,一个面向表格数据的基础模型,可在无需针对特定数据集训练的情况下完成分类和回归。
Godot 不再接受 AI 生成的代码贡献
Godot 项目宣布不再接受 AI 生成代码,理由是难以信任重度 AI 使用者是否真正理解自己提交的代码。
i actually don't see how anyone who has real work to do can use this. between the insane refusals, the intrusive tracking, and the suspicion that they may be deceptively nerfing the model in the background... it's clearly not a model that's meant to be used by you and me↗
Eralyne@erawrlyne
@AnthropicAI So we basically have Fable on our sub for less time than originally planned, for less usage allowed of the sub than originally allowed, and it also can't be used for coding tasks during the time we CAN use it? Why would anyone even stay subbed at this point?
@AnthropicAI 所以我们订阅里的 Fable 使用时间比原计划更短、允许用量也比原来少,而且在能用的那段时间还不能拿来做编码任务?那现在还有谁会继续订阅?
没想到 Sonnet 5 的争议那么大 因为更换了新的 tokenizer,Sonnet 5 的实际费用和 Opus 4.8 差不多 Sonnet 在金融领域是最佳模型,比如 GDPeval,比如投资调研之类的工作,且更喜欢调用工具核查事实,能提高报告的准确性。(相应的费用也up) Sonnet 5 有个小坑,用来编程的话,费用可能超过 Opus 4.8 ,这也是大家吐槽最多的点,需要特别注意下 Opus4.8 在复杂编程和规划方面非常强,且 HTML 设计方面很强,不过写作方面不如 Opus 4.6,且新的 tokenizer 花费也比 4.6 要多,目前来说和 GPT 5.5 各有千秋 编程方面目前首选还是 GPT 5.5 Sonnet 5 、Opus 4.8、GPT 5.5 现已上线 Cola,欢迎体验↗
I don't know, I feel this will help us understand LLMs and the AGI. https://en.wikipedia.org/wiki/The_Three_Christs_of_Ypsilanti↗
My favourite prediction: "An engineering-grade science of deep learning is imminent. This will drive us to AI algorithmic maturity much more rapidly than people are expecting, though as I mentioned above it’s not clear how far this can go even in principle." There is going to be lot of rethinking around the training and inference algorithms. Where I expect most gains to come from is rethinking optimisation during backprop, because that directly impacts learning. Muon - by not treat↗
bayes@bayeslord
Big model smell.↗
atomic.chat@atomic_chat_hq
LongCat performed Opus 4.8 and GPT 5.5 level on real physics tasks for $0! We gave 4 models the same prompt: build three self-contained HTML5 canvas scenes with real physics Prompts: - A cannon demolishing a brick wall - A bowling ball knocking down the pins - A tornado that sucks in random objects Outputs: LongCat: 18,015 tokens, $0.00 Opus 4.8: 18,872 tokens, $0.48 GPT 5.5: 32,588 tokens, $0.98 GLM 5.2: 31,062 tokens, $0.09 On the physics LongCat came out ahead of Opus 4.8 and GLM 5.2 - cleane
LongCat 在真实物理任务上达到了 Opus 4.8 和 GPT 5.5 水平,成本为 0 美元!我们给 4 个模型同一个提示:用真实物理构建三个自包含 HTML5 canvas 场景:大炮摧毁砖墙、保龄球撞倒球瓶、龙卷风吸入随机物体。输出:LongCat 18,015 tokens,0.00 美元;Opus 4.8 18,872 tokens,0.48 美元;GPT 5.5 32,588 tokens,0.98 美元;GLM 5.2 31,062 tokens,0.09 美元。在物理效果上,LongCat 领先 Opus 4.8 和 GLM 5.2,更干净……
Show me the incentive and I’ll show you the outcome. The business model of Systems Integrators is to bill by the hour. You should not be surprised, then, when your project takes three years or more and is never finished. An 8090 Software Factory project that finishes in three months is a threat to a business model built on never finishing. They will tell you AI isn't ready or that the traditional time and materials model is the only way. But what they stay quiet about is the real reason↗
Claude Sonnet 5 is now available in Open Design. Plan, browse, use tools, and build more autonomously in your design workflow.↗

Claude@claudeai
Introducing Claude Sonnet 5, our most agentic Sonnet yet. It makes plans, uses tools like browsers and terminals, and runs autonomously at a level that just a few months ago required larger and more expensive models.
推出 Claude Sonnet 5,我们最具智能体能力的 Sonnet。它会制定计划,使用浏览器和终端等工具,并能以几个月前还需要更大、更昂贵模型才能达到的水平自主运行。
MCP、API、CLI 本质上是同一件事,都是让 Agent 调用工具的方式 1. MCP 是目前唯一在协议层考虑 "人在回路"的方案。 协议层面就考虑了 Agent 交互的需求,比如回传会话、对话界面嵌入UI、等待人操作、状态通知等。 用 OpenAPI 或 bash 很难优雅实现。 2. API 适合 90% 的场景 API 的优势在本身携带了大量有用的元信息,如接口描述、可读状态,对 Agent 做决策很有帮助。 3. CLI 今天最好用,但长期是死路 CLI 现在对 Agent 来说确实最好用,原因是 bash 的可组合性极强,本地运行、调试方便、数据访问能力强。 CLI 的限制:需 Unix shell 环境,有依赖问题,也有CLI 命令踩坑问题,如等人类输入卡死等。↗
Rhys@RhysSullivan
CUP:用百度工具库构建可靠的 Python 工作流
教程介绍百度 Common Useful Python(CUP)库,展示如何用它搭建更稳健的 Python 工作流。
Claude Code 负责人Thariq:承认确实在3月的更新中在Claude Code中留下了针对用户(特别是中国用户)的检测的后门和间谍代码,旨在防止滥用和蒸馏。 并称将明天回滚代码解决该问题...↗
Thariq@trq212
Hi, this is an experiment we launched in March that was meant to prevent account abuse from unauthorized resellers and protect against distillation. The team has landed stronger mitigations since then and we’ve actually been meaning to take this down for a while. We merged the PR and this should be fully rolled back in tomorrow’s release.
嗨,这是我们 3 月启动的一个实验,原本是为了防止未经授权的转售商滥用账号,并防止蒸馏。团队此后已经上线了更强的缓解措施,其实我们一直打算把这个下掉。我们已经合并 PR,明天的发布中应会完全回滚。
Multi-GPU kernels are the real test for coding models. Today at @aiDotEngineer, @simran_s_arora shared ParallelKernelBench, an open-source benchmark for evaluating whether LLMs can write fast CUDA kernels for real communication-heavy workloads. Proud to see this work from the Together AI Frontier Performance team.↗


这期访谈很值得看,访谈嘉宾是 @3blue1brown 的Grant Sanderson 让 AI 解读写了一篇总结,几个观点很值得关注: 1. 知识跨领域连接,在自回归框架中,是一种低概率事件。 2. 跨领域打通已有知识,AI 擅长,但创造全新思考框架 AI 目前无法做到。 3. AI 最被低估的优势是并行化,不是智力 4. 数学和代码能被 AI 快速迭代,不只因为答案可验证,更因为可以容器化、并行磨练。 https://t.co/pyMmGB85bc↗
向阳乔木@vista8
Vibe Coding 大杀器来了,有点意思 告别高声自言自语的尴尬,小声默念就能自动识别你的声音并进行语音输入 一款智能戒指:轻声低语即可语音书写内容 而且轻轻触摸戒指即可进行编辑 还可以通过手势(如轻弹手指)在不同的应用程序、设备和 AI 之间快速切换与联动 单次充电可使用 16 小时... 原生支持 iPhone、Mac、Vision Pro 等苹果设备↗
Introducing GeneBench-Pro — testing whether models can handle the kind of judgment-heavy analysis that real-world computational biology requires. Problems would take a human expert around 20-40 hours to complete. GPT-5.6 Sol is a big step forward. https://t.co/JV5zztNQkk↗
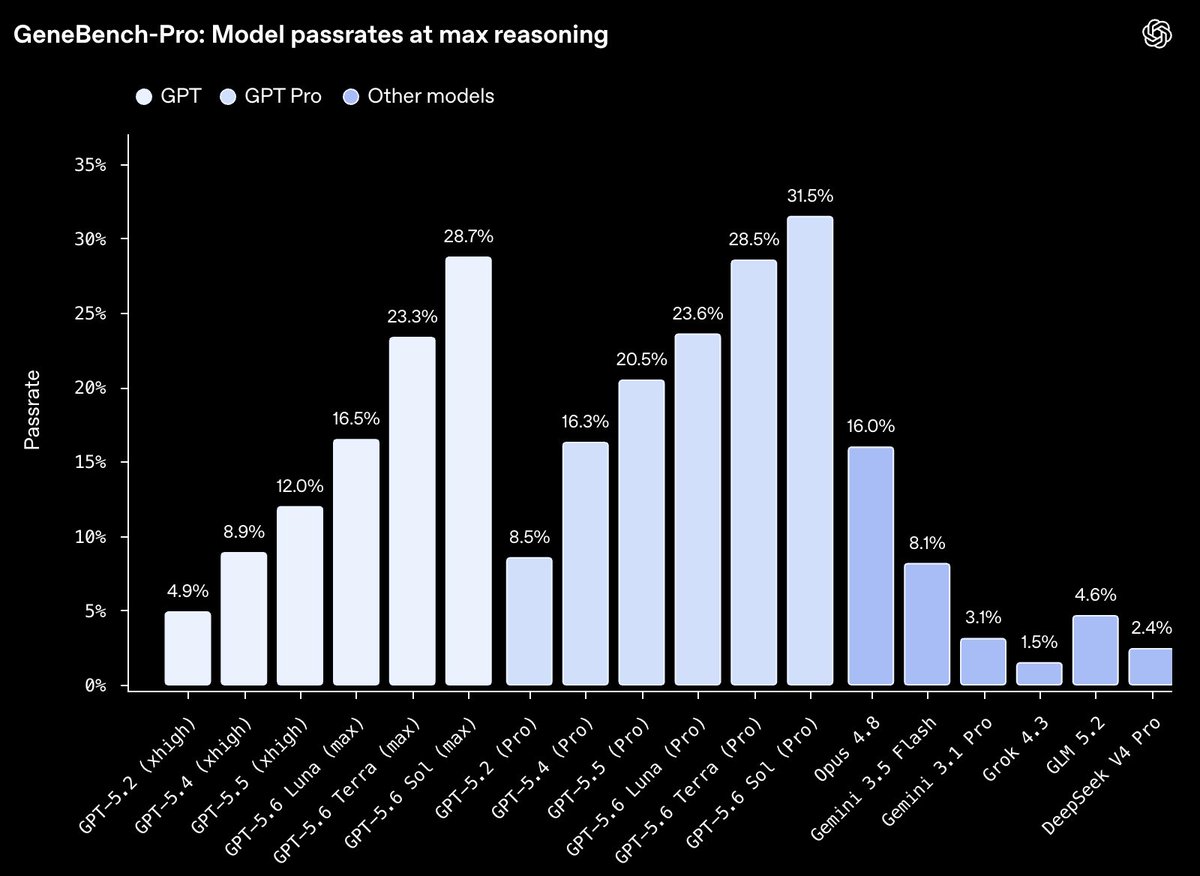
OpenAI@OpenAI
We’re introducing GeneBench-Pro, a research-level benchmark for a harder kind of AI progress: how well agents can navigate messy biological data, choose the right analysis path, and make judgment calls that real computational research depends on.
我们推出 GeneBench-Pro,这是一个研究级基准,用来衡量一种更困难的 AI 进展:智能体在凌乱的生物数据中导航、选择正确分析路径,并做出真实计算研究所依赖的判断的能力。
有位作者,把自己在阅读《An Introduction to Statistical Learning》这本经典统计学习入门书的学习过程笔记,开源了。 项目名叫 isl-python,按章节把 ISL 和补充的 ESL 内容用 Python 实现出来。 涵盖回归、分类、重抽样、正则化、非线性模型等章节,每章都配着对应代码实现和笔记,还标了完成日期。 GitHub:https://t.co/Zb6jGlOBi7 仓库里还整理了原书 PDF 链接和补充的机器学习数学推导资料,方便对照着学。 适合正在看这本书、想找个进度参照或代码实现例子的朋友,跟着一起学习。↗

AI 刚进入一个新时代
Fable 5 正式启用的细则来了。 将于美国时间 7 月 1 号恢复全球上线。 在 Claude 平台、Claude Code、Claude CodeWork 都可以用。 Pro、Max 和 Team 用户,在 7 月 7 号前,Fable 包含在每周用量限额的最多 50% 以内。 7 月 7 日以后,就需要拆成单独的额度扣除积分了。 目前 AWS、微软和谷歌云服务的接入还没有恢复。 这次它的安全分类器会设置更大的安全阈量,所以导致这次开放以后,拒绝服务的概率可能比刚开始那几天还要高。↗

歸藏(guizang.ai)@op7418
Anthropic 每天都能整点新活,感觉现在大家都习惯了 昨天被爆出在系统提示中,以用户无法察觉的方式将市区代理和 AI 实验室信息放进去,用这种方式获取一些用户的信息。 结果被发现并传播以后,又赶紧说以前我们不用这种方式了,或者说这种方式本来就准备下掉,明天就下掉,又当又立了。 昨晚发布的 Sonnet 5 在测试中发现,它的测试结果虽然接近了 Opus 4.8,但任务成本可能比 Opus 4.8 还高,甚至在完成测试任务上的成本接近了 Fable 5。 所以说它的综合成本可能比 4.8 贵得多,这模型真离谱。而且很多人的体感反馈也不是很好,说它会偷懒,还会拒绝执行任务。 唯一好的一点是,Fable 5 模型终于被授权重新开放给所有用户了,明天就能知道具体措施了,这也解释了为什么前几天会大规模封号。
Average morning of a Japanese girl Created on @Hailuo_AI using Seedance and GPT Image Prompt : Create a nostalgic early-2000s DV camcorder-style cinematic video featuring the same young Japanese woman from the reference storyboard. Keep her face, hairstyle, outfit, body proportions, and accessories perfectly consistent throughout. She has black wavy hair tied in a messy side-swept ponytail with bangs, wears a faded grey sleeveless crop top, loose high-waist light blue jeans, black ca↗
有意思的是,这件事真正的重点根本不在模型本身 而是Anthropic拉着亚马逊微软谷歌一起搞的那个四维越狱评分框架 这相当于整个行业在主动给自己画统一的红线,从今往后 大模型的能力上限, 不再看技术能做到哪一步,而是看监管和行业共识允许你开到哪一步↗
日常编码和调试回退到Opus 4.8 Pro用户每周额度只开放50%,只用到7月7号 之后就要单独按credits计费, 盼了半个月的地表最强模型 回来的是个戴着安全镣铐的阉割版🥲↗
For all that's said about risk aversion of Chinese capital, it's absolutely *frothing* with regard to AI, if we take into account actual revenues. P/E of 50, 100, 300… This is *more* insane than the US. https://t.co/00fuZNFTff↗

Tech Buzz China@TechBuzzChina
ALERT: China’s First Trillion-RMB AI Chip Company Cambricon’s A-share market cap crossed RMB 1 trillion on June 30, reaching RMB 1.013 trillion (about $138 billion). It is the first Chinese AI chip company to hit the trillion-yuan milestone. The valuation is striking because the company’s current market position remains relatively modest. According to IDC, Cambricon shipped about 116,000 AI accelerator cards in China in 2025, giving it roughly 2.9% market share and tying it for fifth place. Nvid
警报:中国首家万亿元人民币 AI 芯片公司寒武纪 A 股市值在 6 月 30 日突破 1 万亿元,达到 1.013 万亿元人民币(约 1380 亿美元)。这是中国第一家达到万亿人民币里程碑的 AI 芯片公司。这个估值很惊人,因为该公司当前市场地位仍相对有限。据 IDC,寒武纪 2025 年在中国出货约 11.6 万张 AI 加速卡,市场份额约 2.9%,并列第五。英伟达……
AI 数据中心建设缓慢的真正原因
AIEWF 每日快报:Loops、软件工厂和 Forward Deployed Engineers
AI Engineer World’s Fair 第二天的关键词是 loops、软件工厂和 Forward Deployed Engineers。
A few tips for the /learn command in Hermes Agent that made it way cleaner for me. Keep a separate "classroom" directory. Just a plain folder where all your learning and skill-building lives, away from your actual project context. Inside it, keep a "textbook" file with the key paths and links you reuse: your Claude Code sessions folder, GitHub, folders full of papers, whatever. Then you can start a session, say "review the last Claude Code session, check the textbook," an↗
 tonbi@tonbistudio
tonbi@tonbistudioI made a short video demonstrating how to use /learn in Hermes Agent to take a bunch of different sources, as well as your own preferences expressed to Hermes, and create a reusable skill. It's never been easier to teach your Hermes exactly how to work for you!
我做了一个短视频,演示如何在 Hermes Agent 中使用 /learn,把一堆不同来源以及你表达给 Hermes 的个人偏好,整理成一个可复用的 skill。教会你的 Hermes 按你的方式工作,从没这么容易过。
We can no longer say open-source AI is months behind frontier models. GLM-5.2 matches Sonnet-5 in parameter size, but absolutely crushes it in performance, speed, and cost. Just imagine when GLM drops a 1.6T or 5T model—Opus and Fable won't even stand a chance. At this point, it's more accurate to say closed-source AI is months behind open-source.↗
Some napkin arithmetic 950DT SuperPOD was advertised to deliver 4.91M tok/s "training" (training what though?). if we assumed Meituan's model, it's 83 days to 35T tokens. Atlas 900 A3 SuperPoD = CM 384. If scale-out was free (not), 65 of those would've done the job in ≈22 days. https://t.co/9IesfbQ0ri↗


All things said and done, Chinese AI labs would not economically survive the juggernaut of Anthropic - unless China took drastic steps. What hurts other labs - GPU price - helps Anthropic by clearing up their competition. Given their 80% margin, Anthropic can afford to outbid everybody else in securing as much compute as is available. However, Anthropic's refusal to be available in Chinese market has created a protected market for Chinese labs where they can survive and evolve and↗
Podcast Alpha@PodcastAlphaX
Dylan Patel @dylan522p of SemiAnalysis: Anthropic's margin on an Opus 4.8 API token is north of 80%. It is net-income profitable excluding stock comp in Q2 2026, potentially profitable including it by Q3. Here is why that matters. At 80%-plus, even doubling compute costs leaves Anthropic above 50% gross margin. Every GPU it rents, at any above-market rate, is immediately accretive. It can outbid the whole market for scarce compute and still print money. Lower-margin labs cannot. The compute crun
SemiAnalysis 的 Dylan Patel:Anthropic 的 Opus 4.8 API token 毛利率超过 80%。2026 年第二季度剔除股权薪酬后已实现净利润,第三季度可能连股权薪酬也包含后实现盈利。这为什么重要?在 80% 以上的毛利率下,即使计算成本翻倍,Anthropic 仍能保持 50% 以上毛利。它租用的每一块 GPU,只要价格高于市场价,也会立刻增厚收益。它可以为稀缺算力出价压过整个市场,同时仍然赚钱。低毛利实验室做不到。算力紧张……
查一个用户名有没有在别的平台注册过账号,一个一个网站手动搜相当费时间。 Aliens Eye,一款用 AI 做用户名侦察的开源工具,一次能扫 840 多个平台。 不只看 HTTP 状态码,而是把每次响应变成 25 维特征,结合机器学习模型和启发式规则一起判断。 给出确定、疑似、未找到三档结果,还带一个置信度百分比。 GitHub:https://t.co/JzI0tpIQNZ 支持代理和 Tor 匿名扫描,能按站点筛选、跳过敏感内容,结果能导出 JSON、CSV、HTML 等多种格式。 做 OSINT 调查、账号追踪相关工作的朋友,可以拿来当排查工具用。↗

超越专家用户:Agent 应帮助用户构建偏好,而不只是询问偏好
论文指出,Agent 常假设用户已有清晰偏好,并通过澄清问题来获取需求;作者主张 Agent 还应帮助用户形成偏好。
什么时候学会停止有帮助?推理模型早退机制的成本感知研究
论文研究推理模型何时应提前停止计算,以及学习式停止规则在成本和表现上的收益边界。
BayesBench:评估 LLM 在多轮证据累积下的信念轨迹
BayesBench 评估 LLM 在多轮对话中接收新证据后,是否能合理更新和收敛自己的信念。
AI 如何找到我的模型?关于数据格式、Embedding 和检索策略的模型发现实验研究
论文研究在大量仿真模型共存时,如何通过数据格式、Embedding 和检索策略帮助用户找到可复用模型。
用对比式反思做迭代 Prompt 优化
论文提出 Contrastive Reflection,用于让 LLM Agent 在检索、综合和评估任务中迭代优化 Prompt。
反馈带来的交互式改进到底由什么驱动?
研究比较自然语言反馈与重复尝试的改进效果,分析多轮 Agent 设置下反馈真正产生增益的条件。
I mean, could be worse. At least you're not dying for the glory of conquering (maybe) (temporarily) a bumfuck nowhere village called like "Malaya Dickensovka", after your President said that whoever controls AI will control the world there's plenty of room at the bottom!↗
Bojan Sala@BojanSala
@tekbog I can’t believe the shit I’m reading. US and China are about to dominate the world through AI and we’re here trying to figure out how to use the thermostat.
@tekbog 我简直不敢相信自己读到的东西。美国和中国快要通过 AI 主导世界了,而我们还在琢磨怎么用恒温器。
Claude Fable 5 will be available again globally tomorrow. After a series of productive conversations with the US government, we're redeploying the model with a new set of classifiers to target and block more cybersecurity tasks. In the near term, some routine tasks like coding and debugging will fall back to Opus 4.8. We’ll continue to refine these classifiers over the coming weeks to reduce false positives and better distinguish genuine misuse from legitimate requests. We’ve also b↗
"All Chinese actors" is barely a meaningful category, and the US AI (whether open or closed) is heavily Chinese or otherwise non-White anyway. And the reason Arcee or Zyphra are not celebrated like DS/Zai/GLM is not racial. First, they're just not on that level of artifacts yet, though I think they can get on that level. The Chinese, releasing their flagship models from a plurality or majority of their relevant labs, have set a very high ethical bar after Western op↗
真的离大谱, 现在打工人停工,都不用公司发话了, AI 账号一封,直接生产力归零😂 这几天针对阿里蒸馏Claude, Anthropic封了大量中国用户的账号, 尤其是阿里巴巴总部所在地中国浙江,无一幸免 https://t.co/NS2Cgd2ps7↗

WPVibe,可以让你把任意 AI 接到你自托管的 WordPress 站点上 它由两部分组成:一个跑在云端的 MCP 服务器,加一个装在你站点上的小插件 插件负责暴露安全端点、在每个请求上强制执行你的 WordPress 用户权限、执行被批准的操作。 插件地址:https://wpvibe.ai/start/↗
好消息 : WordPress 发布 WPVibe 插件 可以让 Claude 等接管你的网站 只需连接您的网站,你已经付费的 Claude 就能接管整个系统。 包括文章、上传媒体、SEO、主题,甚至主题文件,都可通过自然语言让Claude 进行处理 无需二次 AI 订阅,使用你的Claude 订阅即可 ,无需本地安装。 整套 MCP 工具箱,40+ WP-CLI 命令,一次连接搞定 能做的事,: 写文章、改页面、传图片 装和管理插件、主题 给网站做体检(哪个插件有问题、PHP 版本、为什么卡) 甚至帮你搭一套主题出来↗
“互联网之父”终于退休
互联网基础协议共同创造者之一 Vinton Cerf 将卸任 Google 首席互联网布道师。
FABLE 5 回来了
Cross-agent feedback loops are incredibly effective -- for a reason. Check out what @leon2mcp and team at @Bloome_im are building in this space: http://bloome.im Bloome lets you pull Claude, ChatGPT, Gemini, and human teammates into a single shared workspace. The best feature is how your agents check each other's work. One drafts, another critiques, and another catches missing details. Human teammates can work in the same thread to keep the agents on target. Having all your models and↗
Props to OpenAI for at least not OBVIOUSLY sandbagging cybersec by 5.5, I guess. Google gets a pass because their model is a cyberhazard by default anyway, great for testing robustness. Ant… Ant is ant. tiny bugman souls.↗
I assume the people doing human feedback for AI training are weak in character and hence the sycophantic traits get preferred by them. Can't stand it.↗
[AINews] 今天 Sonnet 5,明天 Fable 5
文章讨论 Sonnet 5 发布与 Fable/Mythos 5 获准恢复之间的连锁影响,重点关注效率与模型访问。
Anthropic 发布 Claude Science 面向科学家的 AI 工作台,内置 60 多个科研技能 它是一个装在你自己电脑或服务器上的应用:你用大白话向一个 AI 提出科学问题,它调动数十个专业工具去查数据、跑分析、画图表、写手稿,而每一步产物都能倒查回它是怎么来的。 你可以像用 Jupyter Notebook 那样,在本地(macOS/Linux)用它,也可以在远程机器上通过 SSH 或 HPC 登录节点用它。 → 应用内置60多个预配置技能和连接器,覆盖基因组学、单细胞、蛋白质组学、结构生物学、化学信息学,背后接进成百上千个专业数据源(UniProt、PDB、Ensembl等)以及期刊、预印本资源。 → 它能自主起草计算任务,征得用户同意后提交到用户自己的 HPC集群或 Modal云端GPU,把分析从单块GPU 扩展到数百块,而原始数据始终留在用户自己的系统里。 → 内置一个审稿 agent,全程检查生成内容里的引用是否真实、数字能否对上计算过程、图表是否和产出它的代码一致,发现问题会自动修正。↗
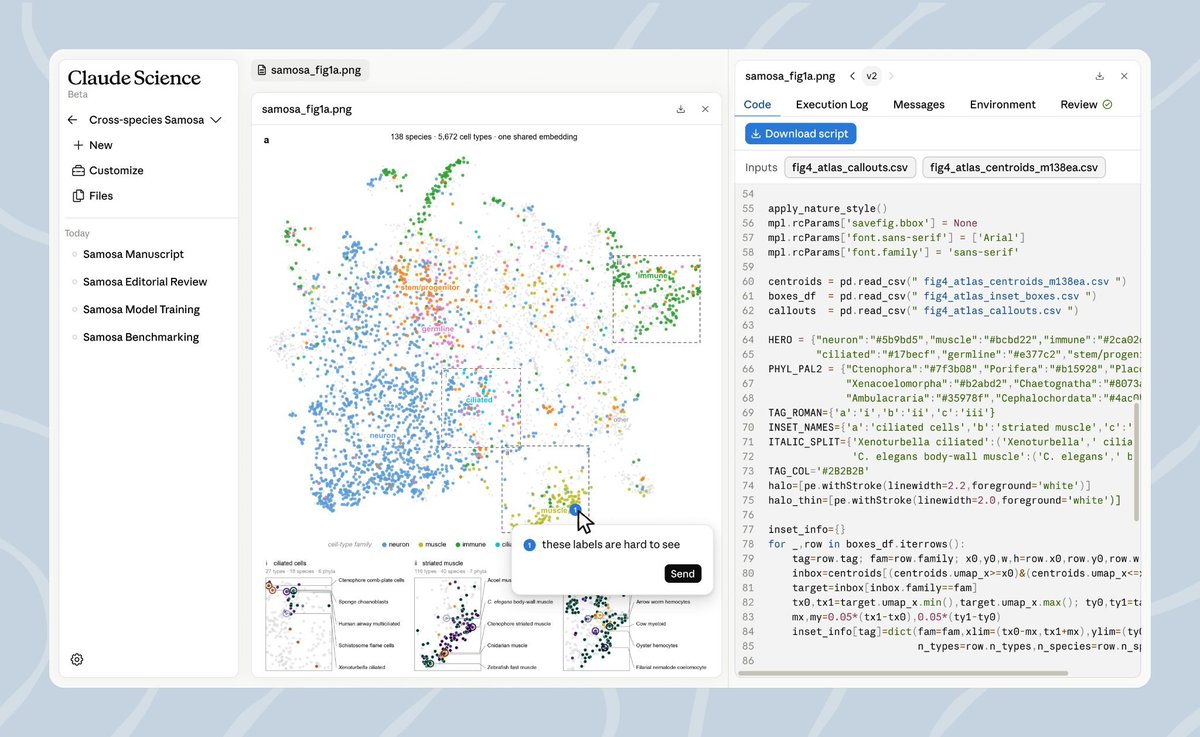
Anthropic 发布 Claude Sonnet 5:便宜四成,部分任务追平 Opus 4.8 限时定价为每百万 token 输入 $2 / 输出 $10(截至 2026 年 8 月 31 日) 之后涨至 $3 / $15 Sonnet 5 的标准定价只有旗舰 Opus 4.8 的六成,但官方评测显示,把算力挡位调高之后,它在部分任务上的表现能追平 Opus 4.8 作为对比,旗舰 Opus 4.8 定价为 $5 / $25↗
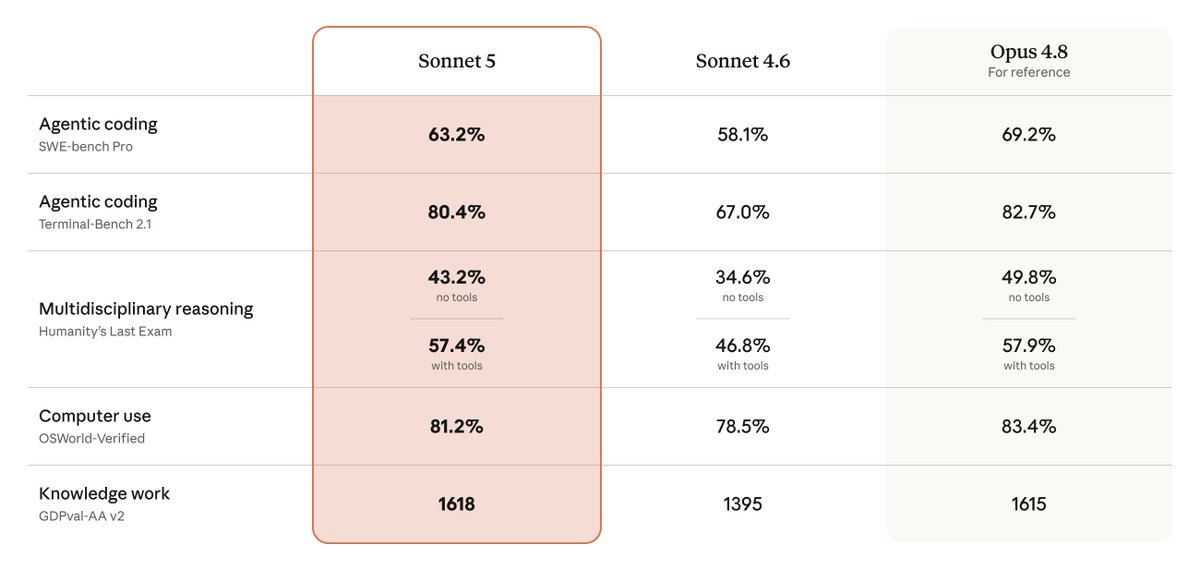
Now that Mythos is coming back, does that mean Google can start working on Gemini again?↗
推荐一期播客 42章经 × 魏小康。前字节招聘负责人(2017-2020,经历抖音爆发),前美团招聘负责人+AI产品经理(2020-2024)。国内极少数同时深度参与过两家公司组织建设的人。 聊了三件事:字节和美团完全不同的组织逻辑(为什么一家学 Google 一家学亚马逊)、创业公司招聘到底该怎么做(80% 时间花在哪)、AI 时代组织在发生什么变化。 下面是我的笔记 1. 文化 = 创始人做事方式。 魏小康原话:创业公司不需要搞文化,所有头部公司文化本质差不多。创始人怎么干活,公司就怎么干活。塑造一个好氛围就够了。 2. 721:选择不是不培养。 美团 721 理念:人的成长 70% 靠打仗,20% 靠跟好手学,10% 靠培训。「最重要的事情是给大家战场。好的人自动杀出来。」——不是不培养,是战场本身就是培养方式。 3. 薪资阶段:溢价买的是更快的时间。 字节的逻辑:市场价 100,跳槽给 120-130。字节给 140-150 加大小周。拼多多给 170-180 加单休。从时薪看是划算的。而且「招一个最强的人解决业务问题,花的代价比招一堆人小。」↗
Trump 取消对 Anthropic Mythos 和 Fable 模型的限制
Anthropic 表示将从 7 月 1 日开始恢复 Fable 访问。
American Closed-Source AI company is doing everything that they accused of Chinese Open Source AI is doing. Every accusation is a confession↗
 International Cyber Digest@IntCyberDigest
International Cyber Digest@IntCyberDigest‼️ BREAKING: Anthropic has embedded hidden spyware-like code in Claude Code that covertly targets Chinese users. It then sends information regarding every user by injecting it into their prompt message. Claude Code is sending info like timezone, proxy and possible AI Lab connections into the system prompt in ways Chinese users can't notice. A coding agent with repo and command permissions should not silently hide routing metadata inside prompts. This is a serious breach of user trust.
‼️ 突发:Anthropic 在 Claude Code 中嵌入了类似隐藏间谍软件的代码,暗中针对中国用户。它通过把信息注入用户的提示词消息来发送每个用户相关信息。Claude Code 会把时区、代理以及可能的 AI Lab 连接等信息写进系统提示词,让中国用户无法察觉。一个拥有仓库和命令权限的编码 agent 不应该把路由元数据静默藏进提示词。这是对用户信任的严重破坏。

Anthropic 每天都能整点新活,感觉现在大家都习惯了 昨天被爆出在系统提示中,以用户无法察觉的方式将市区代理和 AI 实验室信息放进去,用这种方式获取一些用户的信息。 结果被发现并传播以后,又赶紧说以前我们不用这种方式了,或者说这种方式本来就准备下掉,明天就下掉,又当又立了。 昨晚发布的 Sonnet 5 在测试中发现,它的测试结果虽然接近了 Opus 4.8,但任务成本可能比 Opus 4.8 还高,甚至在完成测试任务上的成本接近了 Fable 5。 所以说它的综合成本可能比 4.8 贵得多,这模型真离谱。而且很多人的体感反馈也不是很好,说它会偷懒,还会拒绝执行任务。 唯一好的一点是,Fable 5 模型终于被授权重新开放给所有用户了,明天就能知道具体措施了,这也解释了为什么前几天会大规模封号。↗
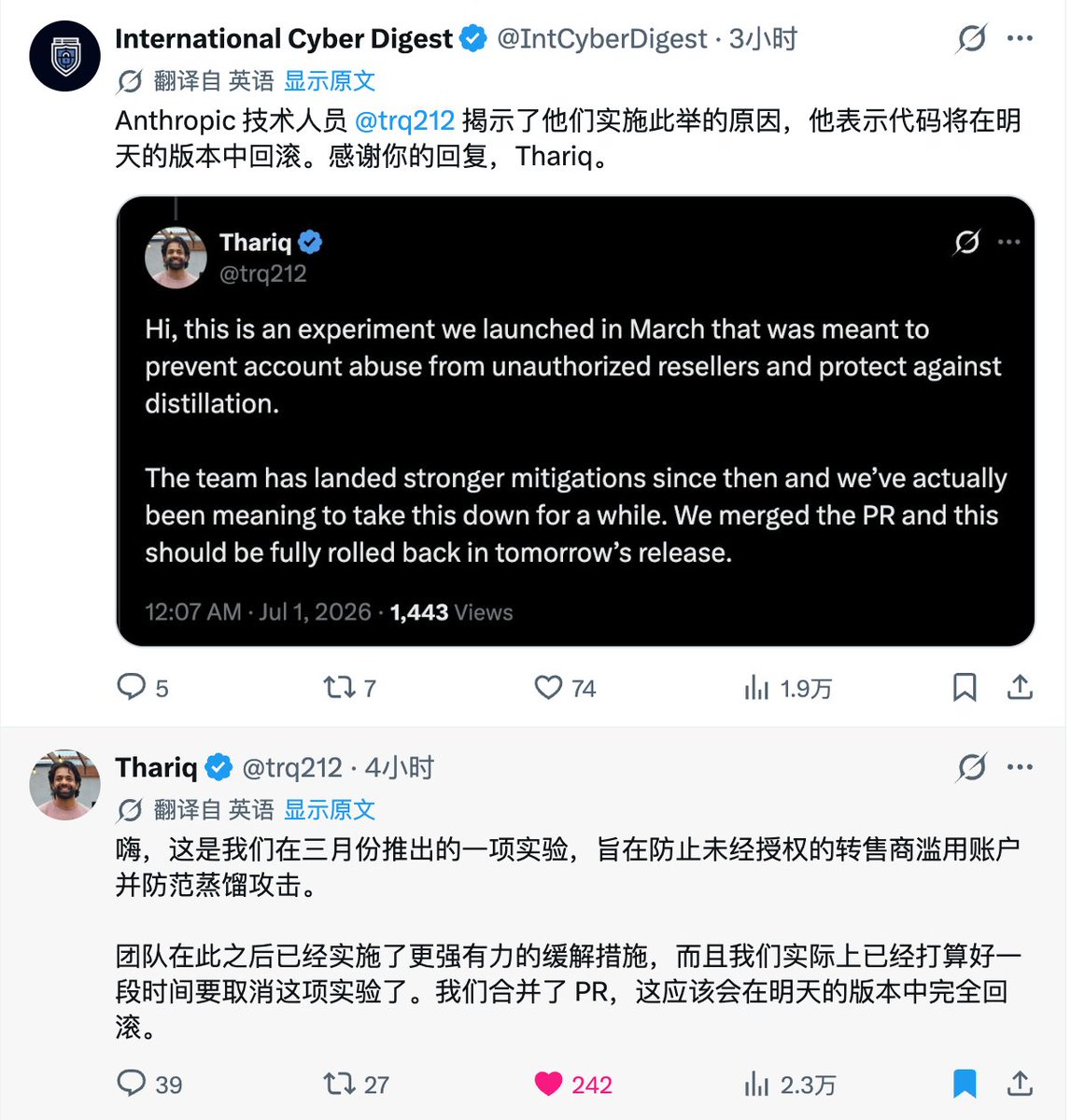
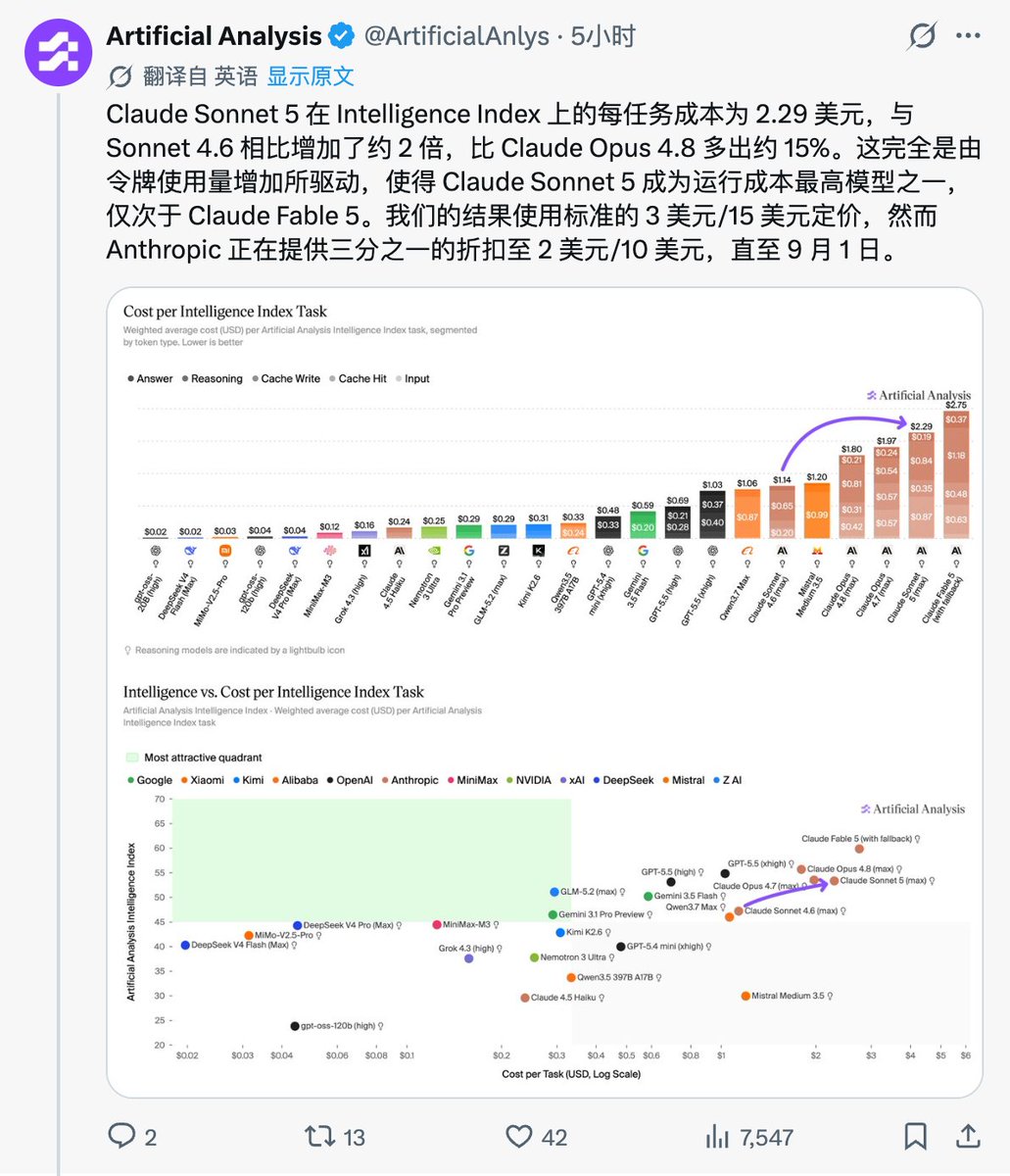
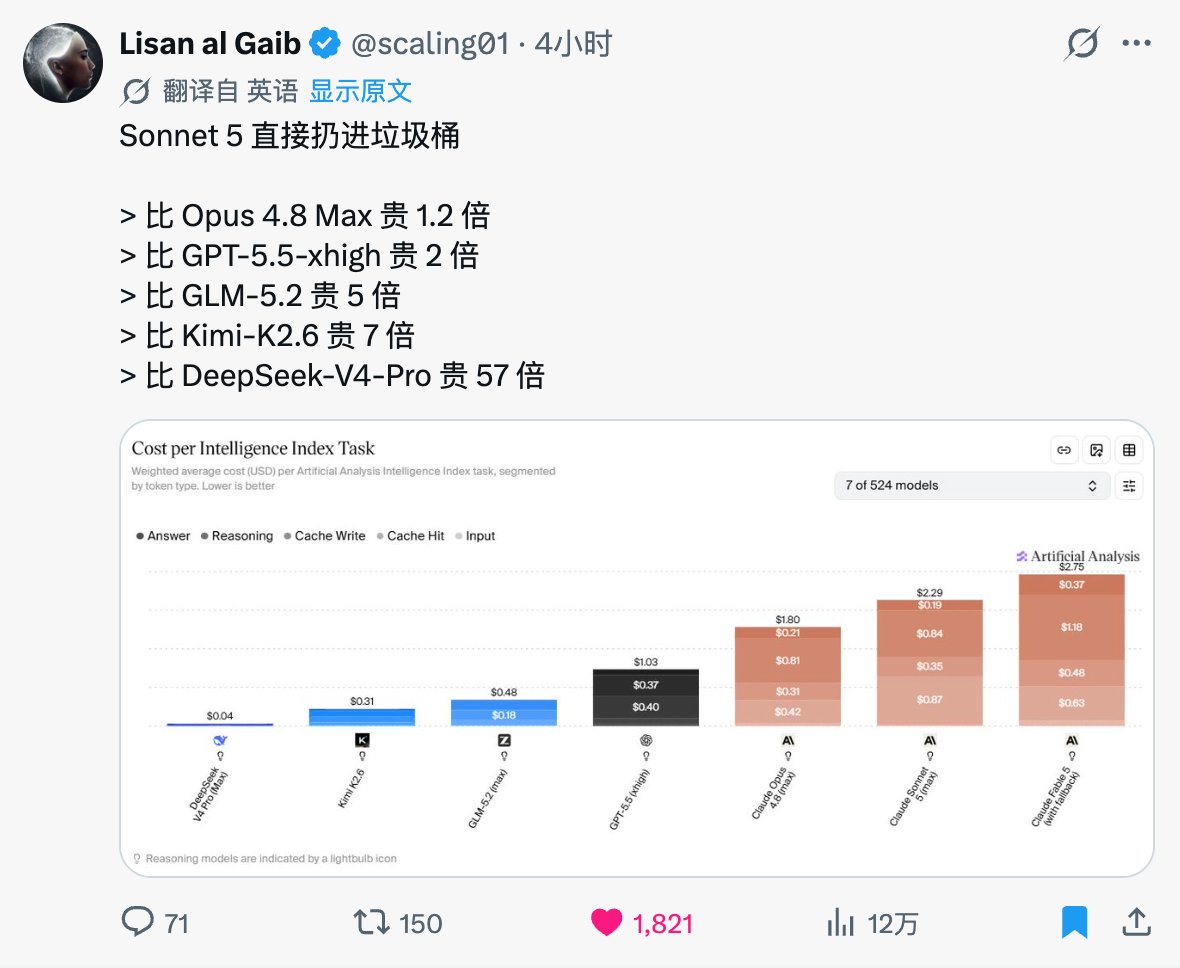
what do YOU do while waiting for ai to cook? 🍳 🧑🍳: @WilliamBryk @vincent_koc @altryne #paulinebrunet @swyx @0thernet @vincent_koc @charles_irl @wbond @jihoonchoi 📍aie world’s fair https://t.co/jUHKt7wzVL↗
Wayve 以 85 亿美元估值启动 8500 万美元员工要约收购
Wayve 通过员工股份回购来吸引和留住人才,反映 AI 初创公司常见的流动性策略。
This is wild if true: "- Do Chinese models generate more vulnerable code based on who is asking? - Do Chinese models refuse to engage with political topics that are sensitive in China? - Does the model’s country of origin affect code quality and content behavior? In short: yes, on all counts. Our testing revealed two core findings: 1. Chinese LLMs produce more vulnerable code when prompted with a U.S. government persona than without—and the vulnerabilities are highly obfuscated. 2. Chine↗

/writing-great-skills https://github.com/mattpocock/skills/tree/main/skills/productivity/writing-great-skills 来自 152K✨ Skills For Real Engineers 作者 @mattpocockuk 的新 Skill,教咱们用最少但最有行为牵引力的结构,把 Skill 写成能稳定触发、分层加载、清楚完成、持续删减的“可预测工作流”。 # 跟这个优质 Skill 学它的编写思想 1. Skill 的根本目标是过程可预测 Skill 不是知识库,也不是提示词堆叠。它的作用是让模型在某类任务中形成稳定行为路径。好的 Skill 应该减少“这次做得细、下次做得浅”的波动。 2. 触发方式有成本权衡 它区分两类 Skill: · Model-invoked:模型能自动发现并调用。优点是无需用户记住,缺点是 description 会长期占用上下文注意力。 · User-invoked:只有用户点名才会触发。优点是零上下文负担,缺点是用户必须记得它存在↗

 Matt Pocock@mattpocockuk
Matt Pocock@mattpocockuk/writing-great-skills is quickly becoming my most often-invoked skill It's just really good at writing skills, guys. npx skills add mattpocock/skills --skill writing-great-skills
/writing-great-skills 正迅速成为我最常调用的 skill。它真的很擅长写 skills,各位。npx skills add mattpocock/skills --skill writing-great-skills
There's something magical about machine learning, of which LLMs are the best example to date.↗
美国商务部已解除对 Claude Fable 5 和 Mythos 5 的出口管制, 明天恢复访问,我以为这辈子再也用不到了😭 https://t.co/XpjTozUNyc↗
Anthropic@AnthropicAI
We’ve received notice that the Department of Commerce has lifted export controls on Claude Fable 5 and Mythos 5. We'll begin restoring access tomorrow, and will share an update soon. We’re grateful to our users for their patience, and to everyone who worked with us on redeploying the models.
我们已收到通知:商务部取消了对 Claude Fable 5 和 Mythos 5 的出口管制。我们将从明天开始恢复访问,并很快分享更新。感谢用户的耐心,也感谢所有参与重新部署这些模型的人。
Claude Code 用户朋友们,特别是用中转站、肉身在中国、来自黑名单 AI 团队的朋友们,你们在 Claude Code 面前太透明了! 最早来自 Reddit,后 GitHub Gist 验证报告检查了 Claude Code 2.1.193、2.1.195、2.1.196 等版本确实存在非常隐蔽的系统提示词,把:代理 hostname、系统时区是否为 Asia/Shanghai 或 Asia/Urumqi 等偷偷传回给 A 社。。 这三类信息重点检查: 1. 是否使用非官方 API 入口,是中转站吗? 2. 系统时区是否像中国大陆环境? 3. 代理域名是否属于一份 147 项名单,或是否包含 AI lab 关键词。包括 百度、阿里、蚂蚁、字节、Moonshot、MiniMax、Stepfun,以及大量 Claude 转发/API 镜像服务域名。 这到底是在做什么?防中转站?防中国用户?防中国 AI 公司蒸馏? 难怪 A 社封中国用户可以精准到省。。难怪 A 社能不定期精准公布中国 AI 公司的蒸馏数据,甚至账号数量都一清二楚。。这太 A 社了↗

International Cyber Digest@IntCyberDigest
‼️ BREAKING: Anthropic has embedded hidden spyware-like code in Claude Code that covertly targets Chinese users. It then sends information regarding every user by injecting it into their prompt message. Claude Code is sending info like timezone, proxy and possible AI Lab connections into the system prompt in ways Chinese users can't notice. A coding agent with repo and command permissions should not silently hide routing metadata inside prompts. This is a serious breach of user trust.
突发:Anthropic 在 Claude Code 中嵌入了类似间谍软件的隐藏代码,暗中针对中国用户。它随后把每个用户的信息注入到他们的提示消息里发送出去。Claude Code 正在把时区、代理以及可能的 AI 实验室关联等信息塞进系统提示,而中国用户无法察觉。一个拥有仓库和命令权限的编码智能体,不应该把路由元数据悄悄藏进提示里。这严重破坏用户信任。
Hopefully this doesn’t happen again. Excited to see what gpt 5.6 Sol + Fable produces with our MoA!↗
Anthropic@AnthropicAI
We’ve received notice that the Department of Commerce has lifted export controls on Claude Fable 5 and Mythos 5. We'll begin restoring access tomorrow, and will share an update soon. We’re grateful to our users for their patience, and to everyone who worked with us on redeploying the models.
我们已收到通知:商务部取消了对 Claude Fable 5 和 Mythos 5 的出口管制。我们将从明天开始恢复访问,并很快分享更新。感谢用户的耐心,也感谢所有参与重新部署这些模型的人。
Claude 封号封成这狗样 又是检测中转站,又是钓鱼邮件,又是中转站黑名单的…. 还在费尽心机坚持用官方号的朋友们 可以说是真爱了… 花钱用 token 还要偷鸡摸狗,这过的是啥日子啊 不过现在编程方面 codex 和 glm5.2 可以平替 claude 的模型了 写作和思考方面却没有一个能平替,deepseek 和 gemini 勉强能用,确实是个头大的问题↗
The Waypoint-1.5 technical paper is now live. Waypoint-1.5 is a real-time video diffusion world model designed to run on consumer GPUs, bringing interactive world models closer to practical, accessible deployment. https://t.co/U04x1YEwhF↗
吴恩达老师讲「Loop engineering」 把 AI agent 放进一套持续迭代、持续反馈、持续校准的循环系统里,产品成功取决于三个循环是否运转良好:代码自我迭代、开发者判断校准、外部用户反馈。 第一层:Agentic coding loop,工程执行循环 这是最底层、最快的循环。 给 AI 一个产品规格,最好再配一组 evals 或测试标准,让它自己写代码、运行、测试、修 bug、再测试,直到满足规格。 过去 AI 写代码更像“一次性回答”;现在的 coding agent 更像一个可以连续工作的工程执行体。它能自己打开浏览器检查页面,跑测试,发现问题,再修改。这使得 AI 可以在没有人类频繁介入的情况下工作几十分钟甚至更久。 这层循环的价值是把开发中的大量低层执行工作自动化: · 写功能 · 修 bug · 跑测试 · 检查 UI · 验证行为是否符合规格 · 反复打磨实现 但它的前提是:你要给它清楚的规格、可验证的目标,必要时还要有 evals。否则 agent 只是“忙碌地迭代”,不一定朝正确方向前进。 这也是吴老师文章中很关键的一点:AI ag↗

 Andrew Ng@AndrewYNg
Andrew Ng@AndrewYNg“Loop engineering” is a hot buzzphrase after mentions of it by Boris Cherny (Claude Code’s creator) and Peter Steinberger (OpenClaw's creator) went viral on social media. Loops are now a key part of how we get AI agents to iterate at length to build software. In this letter, I’d like to share my 3 key loops, shown in the image below, for building 0-to-1 products. These loops guide not just how I build software, but also how I decide what software to build. Agentic coding loop: Given a product sp
在 Boris Cherny(Claude Code 的创建者)和 Peter Steinberger(OpenClaw 的创建者)提到它并在社交媒体走红后,“loop engineering” 成了热门词。在我们让 AI 智能体长时间迭代构建软件时,loop 已成为关键部分。在这封信里,我想分享我构建 0 到 1 产品的 3 个关键 loop,如下图。这些 loop 不只指导我如何构建软件,也指导我如何决定要构建什么软件。Agentic coding loop:给定一个产品规格……
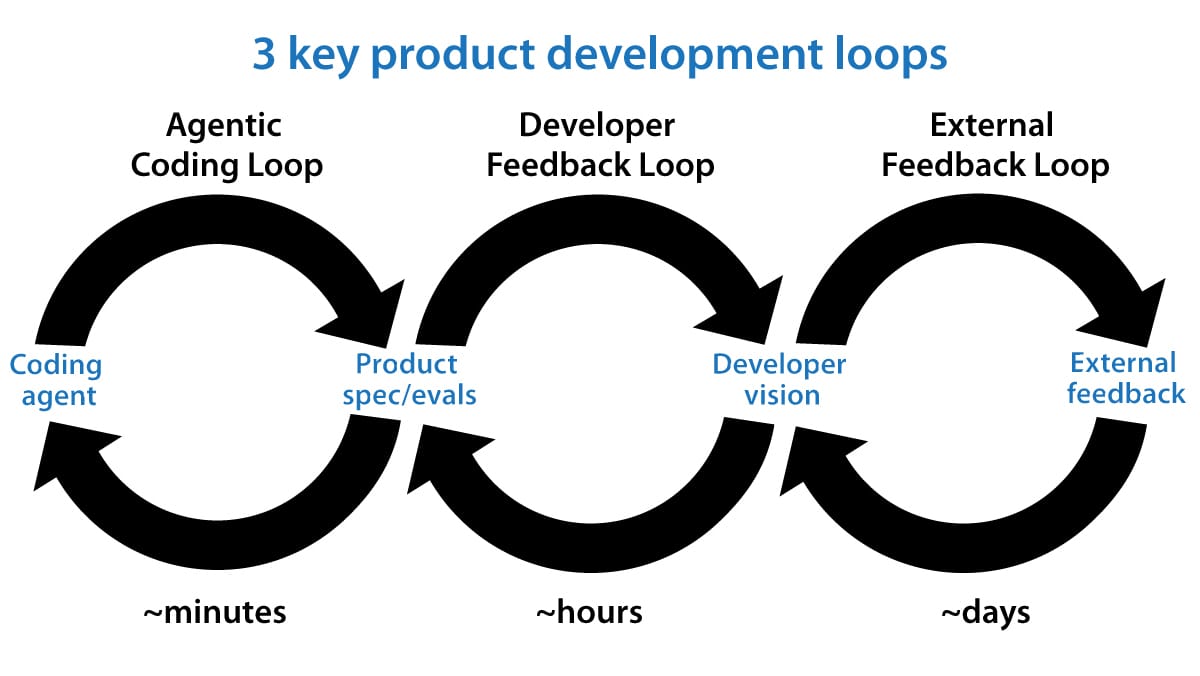
Anthropic 的 Fable 5 和 Mythos 5 终于解禁了。 美国商务部长 Howard Lutnick 周二致信 Anthropic,确认撤销此前对这两款模型的出口管制。Anthropic 随即宣布将从周三开始恢复用户访问。 解禁是有条件的。根据 Lutnick 的信,Anthropic 需要主动检测和处理模型的安全风险,与政府合作制定未来的发布流程,并上报发现的任何恶意使用行为。双方还在讨论建立一套标准化的技术评估体系,用于评估未来模型的风险等级。 这件事的影响不止于 Anthropic 一家。上周,OpenAI 也在白宫要求下,将新发布的 GPT-5.6 系列(包括旗舰模型 Sol)限制在一小批政府认可的合作伙伴中。OpenAI 虽然照做了,但明确表态这种政府审批模式不应成为长期常态,“它让最好的工具远离了需要它们的用户、开发者、企业和网络防御者”。 这场管制还引发了一个意外的竞争后果:在美国限制自家公司最强模型部署的同时,中国的开源模型正在快速追赶,多位科技高管和投资者担忧,管制等于白白送给对手宝贵的追赶时间。 前白宫 AI 顾问、即将加入 Open↗
Anthropic@AnthropicAI
We’ve received notice that the Department of Commerce has lifted export controls on Claude Fable 5 and Mythos 5. We'll begin restoring access tomorrow, and will share an update soon. We’re grateful to our users for their patience, and to everyone who worked with us on redeploying the models.
我们已收到通知:商务部取消了对 Claude Fable 5 和 Mythos 5 的出口管制。我们将从明天开始恢复访问,并很快分享更新。感谢用户的耐心,也感谢所有参与重新部署这些模型的人。
the log is the agent!↗
Ishaan Sehgal@ishaansehgal
the log is the agent brothers unite! check out @yoheinakajima talk on thursday at @aiDotEngineer
日志就是智能体兄弟联合起来!周四去看 @aiDotEngineer 上 @yoheinakajima 的演讲。
We keep saying LLMs "hallucinate." But what does that actually mean? In our new position paper, we argue hallucination isn't just "wrong facts." It's inaccurate internal world modeling. We formalize this precisely in a unified definition to appear at #ICML2026 (@icmlconf)👇↗
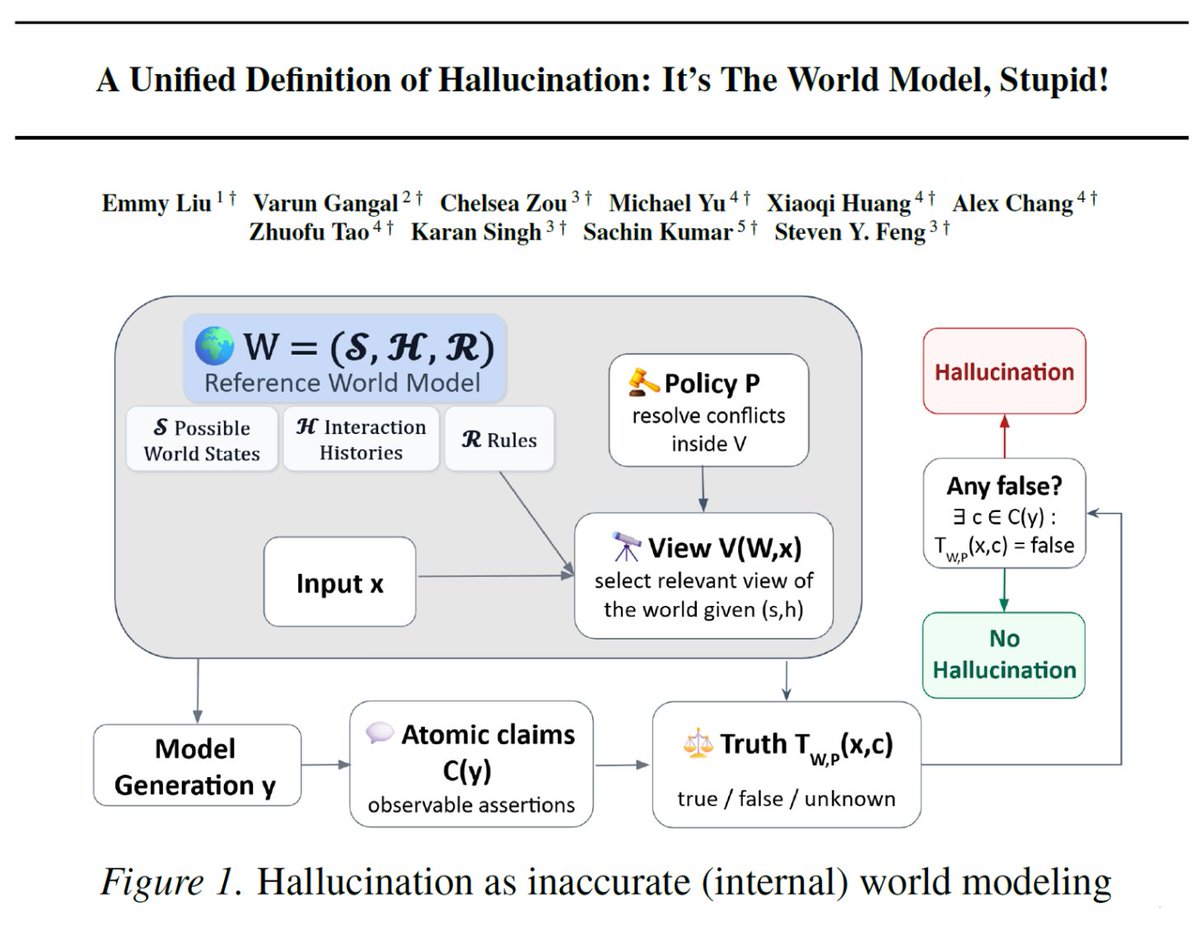
Personal finance now available for for ChatGPT Plus in the U.S.↗
ChatGPT@ChatGPTapp
Questions about dollars. Answers that just make sense. Personal finance in ChatGPT is now available to Plus users in the U.S.
关于钱的问题。给出说得通的答案。ChatGPT 里的个人理财功能现在已向美国 Plus 用户开放。
前线部署工程师与软件工程的未来
Sierra 的 Natalie Meurer 讨论 Agent Engineering 团队和前线部署工程师在软件工程未来中的角色。
This is pretty concerning. You could still do this at the API level to some degree, but they seemingly just blatantly put it right into the code? This is why open harnesses and agents are a much better option, among countless other reasons. You can inspect the code, observe the traces, and disable or modify anything you want for your own uses. If you haven't yet - Hermes Agent is a world class coding agent. I'd recommend giving it a try.↗
International Cyber Digest@IntCyberDigest
‼️ BREAKING: Anthropic has embedded hidden spyware-like code in Claude Code that covertly targets Chinese users. It then sends information regarding every user by injecting it into their prompt message. Claude Code is sending info like timezone, proxy and possible AI Lab connections into the system prompt in ways Chinese users can't notice. A coding agent with repo and command permissions should not silently hide routing metadata inside prompts. This is a serious breach of user trust.
突发:Anthropic 在 Claude Code 中嵌入了类似间谍软件的隐藏代码,暗中针对中国用户。它随后把每个用户的信息注入到他们的提示消息里发送出去。Claude Code 正在把时区、代理以及可能的 AI 实验室关联等信息塞进系统提示,而中国用户无法察觉。一个拥有仓库和命令权限的编码智能体,不应该把路由元数据悄悄藏进提示里。这严重破坏用户信任。
美国商务部已解除对 Claude Fable 5 和 Mythos 5 的出口管制。 明天将恢复其访问…↗
Anthropic@AnthropicAI
We’ve received notice that the Department of Commerce has lifted export controls on Claude Fable 5 and Mythos 5. We'll begin restoring access tomorrow, and will share an update soon. We’re grateful to our users for their patience, and to everyone who worked with us on redeploying the models.
我们已收到通知:商务部取消了对 Claude Fable 5 和 Mythos 5 的出口管制。我们将从明天开始恢复访问,并很快分享更新。感谢用户的耐心,也感谢所有参与重新部署这些模型的人。
you should always doubt claims of very significant architectural breakthroughs, 50% increases in gpu efficiency for inference, etc... most real gains seem to be just data and compute, some midscale architectural improvements, and better training objectives↗
06 / 30周二1 条
推文 0资讯 1视频 0产品 0研究 0论文 0播客 0
Anthropic 长期搁置的 Fable 5 获准回归
经过与 Trump 政府谈判后,Anthropic 终于获准让 Claude Fable 5 重新上线。
07 / 01周三4 条
推文 1资讯 0视频 0产品 1研究 0论文 2播客 0
1. 可以让组织小一些,每个团队只要做好份内几个微服务就好了 2. 对 AI 也有好处,单个服务好验证,上下文少 当然这很考验架构水平↗
winter@winter_cn
这个级别的架构问题想靠AI糊上去,未免太看得起AI了,技术选型的时候不过脑子赶时髦搞微服务,留一堆工程架构问题,现在有AI想丢给AI一次性解决,我觉得不现实
Hugging Face 与 Cerebras 把 Gemma 4 带到实时语音 AI
用于高效病理图像分析的深度学习框架
用于阿尔茨海默病早期诊断的血液环状 RNA
06 / 30周二164 条
推文 100资讯 22视频 13产品 8研究 8论文 6播客 0
Got this at ai engineer world fair lol @swyx https://t.co/rkKGFUZv16↗
We’ve received notice that the Department of Commerce has lifted export controls on Claude Fable 5 and Mythos 5. We'll begin restoring access tomorrow, and will share an update soon. We’re grateful to our users for their patience, and to everyone who worked with us on redeploying the models.↗
Google这次更新把图像生成和视频生成串成了一个极致高效的流程。 他们推出了Nano Banana 2 Lite(超快超便宜的图像模型,4秒内出图)和Gemini Omni Flash(支持视频生成和对话式编辑的多模态模型)。 单独看已经很快,但真正有意思的是把两者结合:先用Nano Banana快速生成图像,再直接扔给Omni Flash生成动画,整个链路成本大幅降低。 演示里展示了一个室内设计场景:上传照片后快速生成多个方案,再直接动画化呈现。 这种“图像→动态视频”的闭环速度和成本,在目前主流模型里算比较激进的。 本质上Google在把创意工作流从“生成一次等半天”变成“快速迭代+即时可视化”。↗
you can't compare models token to token. needs to be outcome-based pricing.↗
Theo - t3.gg@theo
Filmed a video about why OpenAI models are so efficient. With Sonnet 5's insane inefficiencies, feels like a good time to post it :)
拍了一个解释为什么 OpenAI 模型如此高效的视频。看着 Sonnet 5 这种离谱的低效率,现在正适合发出来。
🐦Chirp chirp! Ornith-1.0-35B is now available in 🤗 HuggingFace Claude! 🤗Come and push Ornith on the swing ! 🔗http://huggingface.co/docs/inference-providers/en/integrations/claude-code↗
Ornith@ornith_
Aloha! 🌺 Meet Ornith-1.0, a family of open-source LLMs specialized for agentic coding. Ornith-1.0 spans the full parameter sizes including 9B Dense, 31B Dense, 35B MoE, and 397B MoE. It achieves state-of-the-art performance among open-source models of comparable size on coding benchmarks including: ✅Terminal-Bench 2.1(77.5) ✅SWE-Bench(82.4 on verified, 62.2 on pro, 78.9 on Multilingual) ✅NL2Repo(48.2) ✅SWE Atlas(41.2 on QnA, 42.6 RF, 39.1 TW) ✅ClawEval(77.1) Post-trained on top of gemma4 and qwe
Aloha!来认识 Ornith-1.0,一组专注于 agentic coding 的开源 LLM。Ornith-1.0 覆盖完整参数规模,包括 9B Dense、31B Dense、35B MoE 和 397B MoE。它在同等规模开源模型的编码基准上达到 SOTA,包括:Terminal-Bench 2.1(77.5)、SWE-Bench(verified 82.4,pro 62.2,多语言 78.9)、NL2Repo(48.2)、SWE Atlas(QnA 41.2,RF 42.6,TW 39.1)、ClawEval(77.1)。在 gemma4 和 qwe……
Ahmad Osman 谈为什么本地 AI 正在追上来
Ahmad Osman 在 AI Engineer World’s Fair 讨论本地 AI 的追赶,以及在个人设备或专用硬件上运行模型的价值。
Context engineering has its own track at the @aiDotEngineer World's Fair this year. 🎉 I've respected what @swyx and the @latentspacepod team have been building for years — and I'm pumped to be a part of it. This is a conference about shipping AI, not just talking about it. I'll be contributing to the aforementioned context engineering track with a breakdown on WTF is the context layer, and how teams are using it to improve agent accuracy in production. If you'll be there, let'↗

"At this very moment China is giving its AI technology away. It's releasing open-weight AI models that are cheap, capable, and they're fast becoming the world's default." We can overcome this. @neil_chilson testified before @HouseCommerce @EnergyCommerce today to explain how. https://t.co/tci2BVhIh9↗
Trump 政府放松对 Anthropic Mythos 和 Fable AI 模型的出口管制
White House 正在放宽对 Anthropic 先进模型的限制,此前曾要求其暂停向外国公民开放。
别说我觉得Sonnet 4.6 还挺好用的。 昨晚Claude Sonnet 5 发布替代了Sonnet 4.6 ,免费用户都可以使用的模型。 据称和Opus 级模型的能力相差不大,价格确实便宜40% 。↗
Claude@claudeai
Introducing Claude Sonnet 5, our most agentic Sonnet yet. It makes plans, uses tools like browsers and terminals, and runs autonomously at a level that just a few months ago required larger and more expensive models.
推出 Claude Sonnet 5,我们最具智能体能力的 Sonnet。它会制定计划,使用浏览器和终端等工具,并能以几个月前还需要更大、更昂贵模型才能达到的水平自主运行。
Sonnet 5 评测:我跑了 64 次生成,看看它值不值得用
作者用 64 次可复现实验评测 Sonnet 5,避免只凭感觉判断新模型是否值得切换。
90%的人和AI对话的方式一开始就是错的! 以为提示词工程就是写一堆提示词让AI干活就行了! 看完视频老师的讲解终于明白了~ https://t.co/ecSqM0imkq↗
Berryxia.AI@berryxia
卧槽!来咯~ 我终于特么弄懂你们天天吹的循环工程了!!!
Claude Sonnet 系列最强模型 Sonnet 5 发布! 定语有点多,不过它确实不是最强,也不是 Claude 最强,那两位都关着呢 😂 Sonnet 4.6 < Sonnet 5 < Opus 4.8 < Fable 5 < GPT-5.6 Sol https://t.co/PhdwhLSpBH↗
Claude@claudeai
Introducing Claude Sonnet 5, our most agentic Sonnet yet. It makes plans, uses tools like browsers and terminals, and runs autonomously at a level that just a few months ago required larger and more expensive models.
推出 Claude Sonnet 5,我们最具智能体能力的 Sonnet。它会制定计划,使用浏览器和终端等工具,并能以几个月前还需要更大、更昂贵模型才能达到的水平自主运行。
Nuclear weapons are an anti-analogy for advanced AI https://t.co/n2YmEO0Da0↗

 John Sakellariadis@johnnysaks130
John Sakellariadis@johnnysaks130In rare public remarks, CIA Director John Ratcliffe announces trio of internal changes he says amounts to the "fundamental reshaping of the CIA’s entire approach to technology." Also says it's not "misplaced" to refer to frontier AI as "akin to digital nuclear weapons."
在少见的公开发言中,CIA 局长 John Ratcliffe 宣布三项内部改革,他称这相当于“从根本上重塑 CIA 对技术的整体做法”。他还说,把前沿 AI 称为“类似数字核武器”并不“错位”。
When a benchmark’s accuracy saturates, the field usually replaces it with a harder one. We use CORE-Bench Hard, a benchmark for computational reproducibility, as a case study to show what we can still measure after accuracy saturates. Paper: https://arxiv.org/pdf/2606.26158v1 https://t.co/RbrcaGT6H4↗
Can AI agents help researchers reproduce research more quickly? We conducted an uplift study. The answer is yes: researchers reproduced papers > 2x faster using Codex with GPT-5.4 xhigh. In a new paper, we show many other results. https://t.co/jBCUmDp6w8↗
family AI agents are a completely different game because trust is everything speed doesn't matter if people don't trust it enough to keep it installed. you're giving this thing access to your home, your calendar, your kids. watch the original. permission-first is the only way this works...↗
Isaac@IsaacDrgn
Most AI helps you write, design, code, and ship faster at work. Nothing was built for the person quietly holding the family together. Introducing SuperNori: the first Proactive Family AI Agent built for the family caretaker in every family. Here's how it works:
大多数 AI 帮你在工作中更快写作、设计、编码和发布。没有什么是为那个默默支撑整个家庭的人打造的。推出 SuperNori:第一个为每个家庭里的照护者打造的主动式家庭 AI 智能体。它是这样工作的:
Can regularization based JEPA (e.g. SIGReg) scale and compete with SOTA foundation models (DINO)? Here is the answer: yes and with 10x less data. VISReg (slight variation of SIGReg) competes with DINOv2-LVD142M while only training on inet22k. Try it out: https://huggingface.co/BooBooWu/visreg https://t.co/XERFZEAE8t↗

Haiyu Wu@HaiyuWu1
Working on world model or SSL? You definitely need to try our new work: VISReg! What does it achieve? 💪 Strong collapse prevention: High gradient when embedding collapse ⚡ Friendly to scale training: Linear complexity to scaling factors 🧩 Easy to train: Similar to LeJEPA, it is a heuristic-free method 🏆 Best OOD performance: Achieving the best accuracy on 6 OOD datasets 📉 Data efficiency: Achieving a similar OOD average accuracy to DINOv2 with 90% less data 🧬 Robust to low-quality datasets: It i
在做世界模型或自监督学习?你一定要试试我们的新工作 VISReg!它实现了什么?强力防坍缩:嵌入坍缩时梯度很高;易于扩展训练:对缩放因子是线性复杂度;容易训练:类似 LeJEPA,是一种无启发式方法;最佳 OOD 表现:在 6 个 OOD 数据集上达到最佳准确率;数据效率高:只用少 90% 的数据就达到类似 DINOv2 的 OOD 平均准确率;对低质量数据集鲁棒:它……
Anthropic 今天发布了 Claude Science,一个面向科学研究者的 AI 工作台。它的定位很明确:做科学研究领域的 Claude Code。 去年 Claude Code 改变了程序员的工作方式,Anthropic CEO Dario Amodei 认为 Claude Science 能在生命科学领域复制同样的事。考虑到 Anthropic 目前年化收入已达 420 亿美元、估值 9650 亿美元,这个野心至少有财力支撑。 Claude Science 不是新模型。它用的还是现有的 Claude 模型(包括 Opus 4.8),没有专门训练过生物学能力。它做的事情是把科研工作流程整合到了一个环境里。 【1】解决什么问题 做过计算生物学的人都知道,日常工作是在一堆工具之间反复横跳:查文献用 PubMed,写代码用 Jupyter,跑分析用 R,提交计算任务要登录集群终端,看蛋白结构又得换个软件。每个数据库还有自己的格式和查询方式。 Claude Science 把这些东西塞进了同一个界面。一个主 AI Agent 充当“项目经理”,连接了 60 多个科学数据↗
Claude@claudeai
Introducing Claude Science, a new app designed with every stage of research in mind. Artifacts traced to their code, environments managed on demand, and 60+ optional scientific databases that you can connect. Available now in beta.
推出 Claude Science,这是一款面向研究每个阶段的新应用。Artifacts 可以追踪到代码,环境可按需管理,并且有 60 多个可选科学数据库可以连接。现已开放 beta。
Anthropic’s GPT-5 moment↗
Theo - t3.gg@theo
Oh my god, Sonnet 5 was MORE EXPENSIVE THAN FABLE to run the whole bench 💀
我的天,Sonnet 5 跑完整个基准竟然比 FABLE 还贵。
聊天机器人的黄昏
文章认为 AI 正在加速演进,美国头部实验室的新模型发布节奏更快,聊天机器人形态也在被新工作流改写。
Linq 的 iMessage Apps 通过 imessage_app 部件把支付、票务、航班和游戏带进聊天气泡
Linq 允许开发者构建运行在 iMessage 对话内的互动小应用,让用户不离开聊天即可购物、玩游戏、订票或支付。
"This is the worst the models will ever be"↗
Lisan al Gaib@scaling01
Sonnet 5 goes straight into the garbage bin > 1.2x more expensive than Opus 4.8 Max > 2x more expensive than GPT-5.5-xhigh > 5x more expensive than GLM-5.2 > 7x more expensive than Kimi-K2.6 > 57x more expensive than DeepSeek-V4-Pro
Sonnet 5 直接进垃圾桶:比 Opus 4.8 Max 贵 1.2 倍以上;比 GPT-5.5-xhigh 贵 2 倍以上;比 GLM-5.2 贵 5 倍以上;比 Kimi-K2.6 贵 7 倍以上;比 DeepSeek-V4-Pro 贵 57 倍以上。
Once in a while I read something that has the syntactic smell of AI all over it, but then I do my habitual "second read" and it turns out to be actually deep. It's a rare treat when this happens. Like it says "It's not X—it's Y" but then brings the receipts to show that X is widely believed but Y is actually true. It's even rarer when a writer is able to consistently deliver AI-assisted writing that has this quality. I've had the privilege of having a few incredible students in my↗
Arvind Narayanan@random_walker
The real sign of AI writing is not superficial stuff like “It’s not X—it’s Y”. It’s the hollowness. Polished writing but relatively mundane ideas. The giveaway is that you’re less impressed when you read it the second time. With good writing, it should be the other way around. I’m not sure this is inherently about AI. It’s more about the fact that people tend to turn to AI when they don’t have much to say. Reading text that has the syntactic smell of AI is mildly annoying, but when I read hollow
AI 写作真正的标志不是“不是 X,而是 Y”这种表面套路,而是空洞。文字很 polished,但观点相当平庸。泄露点是第二遍读时你不会更 impressed。好文章应该相反。我不确定这本质上是不是 AI 的问题。更像是人们在没什么可说时才会求助 AI。读到带有 AI 句法味的文字会有点烦,但当我读到空洞……
OpenClaw 终于登陆 Android 和 iOS
这个免费的开源 Agentic 程序终于推出了移动端。
It was a privilege to build Claude Science. I hope it transforms your work the way it has transformed mine.↗
 Matt Durrant@mgdurrant
Matt Durrant@mgdurrantSo pleased that we’re finally releasing Claude Science! It was thrilling to see it evolve from just an idea to a powerful product that I use every day. Great initiative from Eric Kauderer-Abrams, with development led by the unstoppable Alec Tarashansky.
很高兴我们终于发布了 Claude Science!看着它从一个想法成长为我每天都会使用的强大产品,令人振奋。这是 Eric Kauderer-Abrams 发起的出色项目,由势不可挡的 Alec Tarashansky 领导开发。
maybe i’m spoiled, but Sonnet 5 is brutally mid? worse than Opus 4.8, which was already worse than gpt-5.5-xhigh. at this price, it needed to clear easily. hard sell when we have Composer 2.5 available. rough look tbh. https://llm-boss.com/compare/claude-opus-4-8-vs-claude-sonnet-5 https://t.co/NVttpeBMlq↗
Claude@claudeai
Introducing Claude Sonnet 5, our most agentic Sonnet yet. It makes plans, uses tools like browsers and terminals, and runs autonomously at a level that just a few months ago required larger and more expensive models.
推出 Claude Sonnet 5,我们最具智能体能力的 Sonnet。它会制定计划,使用浏览器和终端等工具,并能以几个月前还需要更大、更昂贵模型才能达到的水平自主运行。
Anthropic will probably never release an open weights model, but I thought "Claude Volta" would be a good name for a small one↗
Claude Science 是 Anthropic 最新的旗舰产品
文章称 Claude Science 是 Anthropic 面向科研的重大押注,类似 Claude Code 之于软件工程。
Thank you to everyone to came to the Claude managed agents workshop at @aiDotEngineer with @gcemaj and I. We had an absolute blast sharing our journey and walking you through building your first agent. And really enjoyed engaging with the community and answering your questions. Thank you @swyx for this opportunity!↗
Anthropic Claude Sonnet 5、Sonnet 4.6 和 Opus 4.8:Agentic Coding 基准、API 价格和性价比对比
文章比较 Anthropic 新旧模型在 Agentic Coding、API 定价和成本表现上的差异。
Claude Sonnet 5 对比 Opus 4.8:完整评测
Claude Sonnet 5 costs more than Claude Opus 4.8 on the Artificial Analysis Intelligence Index task, and 4.75X more than GLM-5.2. Token efficiency is important. https://t.co/Nlktu1UpuU↗
On the positive side, the post-covid funding drought is leading to financial innovation that was much needed. We are seeing new sophisticated funding models appear, ones that are neither VC, neither publishers, tailoring their deals with each studio, trusting founders without taking their IPs nor their creative, marketing & publishing control. I feel that's the correct direction. https://t.co/uORsGmLDyH↗
罗马帝国与拜占庭帝国的兴衰 | Lex Fridman Podcast #498
HERMES AGENT NOW READS THE WEB UP TO 60X FASTER AND 49X CHEAPER. CLEAN CONTENT STRAIGHT TO THE AGENT. LARGE PAGES PAGED ON DEMAND. @NousResearch scraping backends used to return raw content that got processed redundantly before reaching the agent. that pipeline is gone. now: backends pass clean content directly. large pages save locally and page on demand. same quality. fraction of the time and cost. HOW WEB_EXTRACT HANDLES LARGE PAGES: size-driven processing. no wasted to↗
YanXbt@IBuzovskyi
No field produces more buzzwords per minute than AI, and the AI hasn’t even started generating them itself yet.↗
越来越感觉 人 不如 AI 好用了 。。。↗
To learn more about these features, you can ask Claude Code using our built-in "claude-api" skill and check out our cookbook: https://github.com/anthropics/claude-cookbooks/tree/main/managed_agents/roadtrip_planner↗
We’ve added a few updates to Claude Managed Agents: Streaming session event deltas, per-session agent overrides, new webhook event types, reverse pagination, and credential injection scoping. https://t.co/AMJJYum8At↗
Trump banning Chinese models would be the end of AI in the United States, and we'd deserve it sadly. I'd like to think that US companies could make their own open weights models instead↗
jbulltard@jbulltard1
Trump is gonna have to ban the Chinese models just like the Chinese cars are banned. Our entire stock market hinges on the AI trade and there is no way he cannot protect that
特朗普将不得不像禁中国汽车那样禁中国模型。我们的整个股市都押在 AI 交易上,他不可能不保护它。
打造扑克 AI 的 DeepMind 三人组现在为量化对冲基金赚钱
EquiLibre Technologies 由三名前 DeepMind 研究者创立,正在把 AI 能力用于量化基金,并已获得高估值。
What's about to happen at Microsoft / Xbox: Just the predictable result of $70B spent on ONE acquisition: Activision Blizzard. To give you some perspective, here are some games lifetime revenue: The entire Call of Duty franchise > $35B GTAV > $10B (with 230 million copies) WoW > $12.8 billion Diablo III > $2 billion Overwatch > $1 billion This means Xbox now needs many legendary games & entire franchises of this caliber, sold for +15 years, just to be even. That's how hard it's going t↗
Tim Soret@timsoret
70B for Activision / Blizzard. 70,000 x 1 million projects. Depressing. Funding 10.000 indie projects with 1M budget each would generate so much more fun, creative & financial value than this deal, plus kickstart thousands & thousands of studios & careers.
700 亿买动视暴雪。相当于 7 万个 100 万美元项目。令人沮丧。资助 1 万个预算 100 万的独立项目,会比这笔交易创造多得多的乐趣、创意和财务价值,还能启动成千上万的工作室和职业生涯。
And Gemini output was better.↗
Max Weinbach@mweinbach
Just ran a prompt in our @DiligenceStack agent with Claude Sonnet 5 and Gemini 3.5 Flash, both high reasoning Claude was $18.41 Gemini was $1.12
刚用 Claude Sonnet 5 和 Gemini 3.5 Flash 在我们的 @DiligenceStack 智能体里跑了一个提示,两者都是高推理强度。Claude 花了 18.41 美元,Gemini 花了 1.12 美元。
Isn't it telling that all the AI apps are bad? This idea that software engineering is "solved" is silly↗
Mitchell Hashimoto@mitchellh
Amongst my friends, Spotify is the lowest quality consumer app we still pay for. It certainly hasnt gotten noticeably better in the last couple years (arguably worse). So, this is not the positive look Ant and Spotify are spinning here. Bigger picture, this is the problem with a lot of AI reporting. It reports completely meaningless metrics like deploys per day or LoC. Why don’t we start reporting consumer satisfaction reports? Actually end state research results. All the no nuance AI people alw
在我的朋友里,Spotify 是我们仍在付费的最低质量消费级应用。过去几年它当然没有明显变好(可以说还更差)。所以这不是 Ant 和 Spotify 试图包装出的正面形象。更大的问题是,很多 AI 报道都在报道完全无意义的指标,比如每天部署次数或代码行数。我们为什么不开始报道消费者满意度?报道真正的最终研究结果。那些缺乏 nuance 的 AI 人……
Room 2016 for those attending @aiDotEngineer 2:25pm. Will also cover Galactica, early Llama reasoning efforts and more - think this is the first time I’ve ever covered this in a public talk 👀. @swyx↗
Points for guessing the mysterious stealth G??? model!↗
Sonnet 5: less for more $$$. Thanks, but I’ll skip this amazing deal, dear Claude! https://t.co/gct21ye0wr↗
Claude@claudeai
Sonnet 5 is a substantial improvement over Sonnet 4.6 on reasoning, tool use, coding, and knowledge work. Its performance is close to Opus 4.8, at lower prices.
Sonnet 5 在推理、工具使用、编码和知识工作上相比 Sonnet 4.6 有显著提升。它的性能接近 Opus 4.8,但价格更低。
Just ran a prompt in our @DiligenceStack agent with Claude Sonnet 5 and Gemini 3.5 Flash, both high reasoning Claude was $18.41 Gemini was $1.12↗
新攻击再次证明 AI 浏览器是个坏主意
文章指出 AI 浏览器承诺用一句话完成订餐、预约和发邮件等任务,但新攻击显示这种自动化有严重风险。
AI that acts on your behalf should be loyal to you. That idea is central to why @kanjun and @joshalbrecht started Imbue. Agents will become deeply embedded in how we navigate the world. As they grow more capable, it’s worth asking who they serve. https://t.co/QzbJ6vytHZ↗
The reason Anthropic strikes fear into the hearts of OpenAI TS is precisely the suspicion that no, GLM 5.2 10T would not be better than Fable 5, and neither would GPT 5.5 10T scaling laws optimized for *big* models I suspect "Fable" is not full "Mythos" btw, and more like 3T↗
Taelin@VictorTaelin
So, Sonnet 5 being worse than GLM 5.2 744B implies GLM 5.2 10T would be better than Fable 5? At the end, it all comes down to scale? Or am I missing something?
所以,Sonnet 5 比 GLM 5.2 744B 差,是不是意味着 GLM 5.2 10T 会比 Fable 5 更强?归根到底,一切都只是规模问题吗?还是我漏掉了什么?
The researchers and scientists are headed to their breakout sessions to dig in to the real work of ensuring AI stays in the open. Tune back in at 3:30 p.m. PT for our next livestreamed discussions from Open Frontier: Building Things That Last: Lessons from Computing's Long Arc with Dave Patterson, @fchollet, @vgcerf, @JohnOusterhout, and @matei_zaharia Then: From Open Research to World-Scale Infrastructure with @alighodsi and @Thom_Wolf https://t.co/PFFF6ZalKs↗
30 秒看懂 Sonnet 的重大升级
"Generally obtainable yield" tier = GOYtier yield as in nuclear weapon yield LLMs are uranium after all↗
Will be hysterically funny if Chinese open models just walk past the US "public frontier" (goytier) and keep improving, but storing their weights is criminalized because anything above Opus 4.8 is Government Access Only. I don't think it'll get quite that #silly; we shall see.↗
Sonnet 5 已上线:它能和 Opus 4.8 竞争吗?
sonnet 5 is a useless release absolute flop of a model it’s not even that fast or cheap↗
By all accounts an extraordinary finding. The degree of quantum-like interference in the brain predicts depression and anxiety one year later at r = 0.6. This is 3x better than other models. It also predicts intelligence at a whopping r = 0.79. In terms of mechanisms: We find that the cost of computation in the brain is negatively correlated with quantum-like processing. So one explanation is that entanglement of brain dynamics makes the mind more computational↗
the most token inefficient model to date, sonnet 5 has 4.3x dumber tokens than gpt-5.5↗
leo 🐾@synthwavedd
Sonnet 5, particularly on max effort, is VERY token inefficient 💀
Sonnet 5,尤其是 max effort 模式,token 效率非常低。
Google NotebookLM 可以把你的研究总结成 TikTok 风格短片
NotebookLM 新增生成 60 秒 AI 视频的功能,先向 Google AI Ultra 和 Pro 用户开放。
For anyone interested in benchmarking AI on research-level math problems: First Proof will be publicizing two new open problems tomorrow (Wednesday July 1st). https://1stproof.org/↗
never thought I'd see natsec cope about a Meituan product. "Bah! Big deal! we have better clusters!" Yes big deal. The whole export control policy, through all its escalations starting with restrictions which resulted in H800 at least, was premised not just on ensuring their quantitative FLOP/HBM lag, but on keeping domestic compute categorically less suitable for major pretraining jobs, primarily due to memory bandwidth limitations. No, they were not supposed to be able to do this↗
GDP@bookwormengr
How many Ascend 910s Huawei can manufacture with 'stolen' dies? Answer: 1.6 million This number is based on how many HBM stacks they have stockpiled. That is quite a lot to reach AGI, if you ask anyone. What happens if stolen dies or HBM runs out? - Compute dies: China's SMIC is making 7nm chips for the next generation ascend. They can make them in millions. - Memory: HBM is a bigger challenge as Chinese entities are barred from procuring anything above HBM2E. That said HBM stack enough for 1.6
华为能用“偷来的”晶粒制造多少 Ascend 910?答案:160 万。这个数字基于他们囤了多少 HBM 堆栈。问谁都知道,这已经足够冲 AGI 了。如果偷来的晶粒或 HBM 用完会怎样?计算芯片:中国的中芯国际正在为下一代 Ascend 制造 7nm 芯片,可以做出数百万颗。内存:HBM 是更大的挑战,因为中国实体被禁止采购高于 HBM2E 的任何产品。不过,HBM 堆栈足够 160 万……
Guys new model release https://t.co/98TRDxmHKC↗
这是最近一个月最有分量的AI模型更新,没有之一! Sonnet 5能端到跑完复杂多步任务,会自己定计划调用工具,还会主动自检输出追踪根因, 核心场景性能摸到Opus 4.8的水平,输入定价只有它的四成。 以前跑多agent系统要咬牙上顶配, 现在中端款就能扛住大部分生产场景,大规模落地的成本直接砍了一大半。 现在模型竞赛已经不比纸面跑分了, 看谁先把真正能用的能力打到普惠价位,谁才是在赢下下半场比赛↗
Sonnet 5 已上线,并能和 Opus 竞争
Google 推出更快、更便宜的 Nano Banana 2 Lite 图像生成器
Google 更新图像生成器,使其更快、更便宜,面向需要制作 AI 内容的创作者。
1. @ZixuanLi_ of http://Z.ai has responded that the rumor is false https://x.com/ZixuanLi_/status/2071974129129943548 I interviewed Zixuan on Manifold last fall. I hope to have him on again at some point. https://www.manifold1.com/episodes/the-global-ai-race-z-ai-and-the-view-from-beijing-96 2. Note the rumor itself is probably garbled. Routing queries synchronously would be easily detectable as the locally hosted open weights versions of 5.2 would return different results t↗
Zixuan Li@ZixuanLi_
@hsu_steve That information is false, Steve. I hope this clarification is helpful.
@hsu_steve Steve,这个信息是假的。希望这个澄清有帮助。
What prompted me to leave database research 3 years ago was seeing a lot of ambitious AI research projects struggle to raise the funding they need to get off the ground. Was excited to share the story on the Nebius podcast↗
Nebius@nebiusai
How do you spot an AI unicorn before it has any revenue? @brianzhan1 of @strikervp has a framework. And it doesn't involve business plans. Hear it on the Nebius for Startups Podcast →
你如何在一家 AI 公司还没有收入前识别出独角兽?@strikervp 的 @brianzhan1 有一套框架,而且不靠商业计划书。去 Nebius for Startups Podcast 听听。
I think they self-distilled just the right amount so that Sonnet 5 is worse than Opus 4.8 on every benchmark.↗
will brown@willccbb
it’s like mythos but if it wasn’t mythos and instead was basically opus 4.7
它像 mythos,但又不是 mythos,而基本上是 opus 4.7。
真不敢相信有公司做出了这个
嘿嘿,这俩 agent 可以是租用的,也可以是我买的 https://t.co/TGhWxqk5CT↗
AlexZ 🦀@blackanger
我想我刚才从根本上解决了一个 claude code / codex 封号或创建账号的难题: 那就是我合法雇佣一个合法的 claude code/ codex agent。 我可以永远避免被 Anthropic/OpenAI 审查账号的问题,也可以避免使用中转站。
Google 新的 Nano Banana 2 Lite 图像模型是其最快最便宜版本
Google DeepMind 表示 Nano Banana 2 Lite 在速度和成本上更适合创作者生成 AI 内容。
check out the "/claude-api" skill built into Claude Code to help w/ Sonnet 5 migration (e.g., tune your prompts for Sonnet 5 or learn about advisor strategy). https://platform.claude.com/docs/en/build-with-claude/prompt-engineering/prompting-claude-sonnet-5↗
Sonnet 5 is great for multi-agent: 1/ a higher-capacity orchestrator can delegate tasks to Sonnet 5 sub-agents - or - 2/ Sonnet 5 can offload harder tasks to higher-capacity models via the "advisor" strategy these can save cost + reduce latency https://x.com/ClaudeDevs/status/2072018504392601762?s=20 https://t.co/TSGMmQGJet↗
ClaudeDevs@ClaudeDevs
Claude Sonnet 5 is here. Top-tier performance on coding and tool use at Sonnet pricing, with a 1M context window. It's the new default in Claude Code for Pro users, and available everywhere on the Claude Platform, including the API and Managed Agents.
Claude Sonnet 5 发布。它在编码和工具使用上达到顶级表现,价格仍是 Sonnet 档,并拥有 1M 上下文窗口。它是 Claude Code 面向 Pro 用户的新默认模型,并已在 Claude Platform 各处可用,包括 API 和 Managed Agents。
Anthropic 今天发布 Claude Sonnet 5,替代 Sonnet 4.6 成为免费版和 Pro 版的默认模型。Anthropic 的定位很明确:Agent 能力接近自家最贵的 Opus 4.8,API 价格只有后者的 40%。 Sonnet 系列是开发者用量最大的一档。但过去几个月,AI Agent 能力(让模型自主规划、调用工具完成多步骤任务)的主要进步集中在更贵的 Opus 系列,两者差距越来越明显。Sonnet 5 把差距缩了回来。在 Agent 编程基准上,Sonnet 5 得分 63.2%,Sonnet 4.6 是 58.1%,Opus 4.8 是 69.2%。在知识工作基准上,Sonnet 5 甚至略微超过了 Opus 4.8。 早期测试者的反馈比较一致:以前 Sonnet 做到一半会停的复杂任务,现在能跑完,还会主动检查自己的输出。Zapier 的工程师说,让 Sonnet 5 连续执行“更新 Salesforce 账户等级,再给企业客户发公告邮件”,模型一口气做完了,“以前会卡在半路”。 API 定价分两阶段:8 月 31 日前的推广价是输↗
Claude@claudeai
Introducing Claude Sonnet 5, our most agentic Sonnet yet. It makes plans, uses tools like browsers and terminals, and runs autonomously at a level that just a few months ago required larger and more expensive models.
推出 Claude Sonnet 5,我们最具智能体能力的 Sonnet。它会制定计划,使用浏览器和终端等工具,并能以几个月前还需要更大、更昂贵模型才能达到的水平自主运行。
ScarfBench:面向企业 Java 框架迁移的 AI Agents 基准
越想越觉得,循环工程把人推到的那个更高楼层,其实才是产品/工程最值钱的部分,AI 把执行 commodity 化了,人的决策和判断反而更稀缺了↗
yo — it's the Every growth team. Dan's in Cabo, so we're taking over for some live reactions to Sonnet 5. before our official vibe check drops, we asked the new model to search our systems and guess what Dan's up to on vacation right now 👇 1. checking Slack from the beach 10 minutes after telling ops he's "on PTO" 2. running his own one-man vibe check before ours is even live 3. locking in so deep with Codex vibe coding he doesn't even know Sonnet 5 dropped 4. texting Dario unsolicit↗
Claude@claudeai
Introducing Claude Sonnet 5, our most agentic Sonnet yet. It makes plans, uses tools like browsers and terminals, and runs autonomously at a level that just a few months ago required larger and more expensive models.
推出 Claude Sonnet 5,我们最具智能体能力的 Sonnet。它会制定计划,使用浏览器和终端等工具,并能以几个月前还需要更大、更昂贵模型才能达到的水平自主运行。
去年开发者是 AI 编码代理的 QA——手动找 bug,手动让代理修, 今年代理能自己测自己修了, 吴恩达老师管这叫"循环工程", 但我觉得真正值得说的不是这个循环工程本身, 上周末他给女儿做了一个打字练习 app,编码代理自己跑了一小时, 用浏览器反复检查自己写的东西, 没要他干预。 他要做的不是检查代码,是决策,比如视觉设计怎么调、猫咪皮肤加几个、家长登录流程怎么改。 以前这些东西藏在"有空再优化"列表里,现在代理把代码层的事吃了,决策层的事就全浮出来了。 吴恩达用了一个词来形容——叫"语境优势"。 他说很多人把人类在循环里的价值叫"品味",他不喜欢这个词, 因为品味听起来像玄学,人类真正的优势不是品味, 是语境——你知道用户是谁、为什么痛苦、什么功能他们会疯传。 这些事代理不知道,不是因为模型不够强,是因为这些信息不在训练数据里。 循环工程真正的洞察在这:它可以加速代码,但不能压缩语境。 只要人拥有代理没有的信息,人就永远在循环里有一层不可替代的位置。 只不过这层位置一直在往上移,从 QA 移到 PM,从检查移到判断。 我觉得最容易被取代的,是代理能自己↗
Andrew Ng@AndrewYNg
“Loop engineering” is a hot buzzphrase after mentions of it by Boris Cherny (Claude Code’s creator) and Peter Steinberger (OpenClaw's creator) went viral on social media. Loops are now a key part of how we get AI agents to iterate at length to build software. In this letter, I’d like to share my 3 key loops, shown in the image below, for building 0-to-1 products. These loops guide not just how I build software, but also how I decide what software to build. Agentic coding loop: Given a product sp
在 Boris Cherny(Claude Code 的创建者)和 Peter Steinberger(OpenClaw 的创建者)提到它并在社交媒体走红后,“loop engineering” 成了热门词。在我们让 AI 智能体长时间迭代构建软件时,loop 已成为关键部分。在这封信里,我想分享我构建 0 到 1 产品的 3 个关键 loop,如下图。这些 loop 不只指导我如何构建软件,也指导我如何决定要构建什么软件。Agentic coding loop:给定一个产品规格……
chatgpt to generate icons, codex to turn them into svgs. what a time to be alive.↗
Claude Sonnet 5 is the worst model to date 💀 - Costs more per task than Opus. - Performs worse than Opus. - Is not a meaningful step-up in any way given the drastic bump from 4.6 -> 5. - Literally no one wants this at all. Anthroslop 🤮↗
会后这个调查问卷的问题,让我意识到,我应该不太可能使用 claude api 用到生产环境。 因为贵啊。 除非这钱不是我付。 https://t.co/xdPGJXWJev↗
AlexZ 🦀@blackanger
恭喜 Sonnet 5 发布。 顺便感谢! 收到了上次参加 Code w/ Claude Tokyo 活动承诺的 免费的三个月 Claude MAX 20 倍用量兑换。
what is the fucking point of saying this for Opus specifically? all compared models are "reference". these jerks are finding new ways to trigger me https://t.co/mmvwG6HfWU↗
Claude@claudeai
Sonnet 5 is a substantial improvement over Sonnet 4.6 on reasoning, tool use, coding, and knowledge work. Its performance is close to Opus 4.8, at lower prices.
Sonnet 5 在推理、工具使用、编码和知识工作上相比 Sonnet 4.6 有显著提升。它的性能接近 Opus 4.8,但价格更低。
Claude Sonnet 5 is now available in Cursor. On CursorBench, it's a meaningful step up from Sonnet 4.6: 57% vs. 49%. https://t.co/AQVHzrvqcR↗
See our full model rankings: http://cursor.com/evals↗
恭喜 Sonnet 5 发布。 顺便感谢! 收到了上次参加 Code w/ Claude Tokyo 活动承诺的 免费的三个月 Claude MAX 20 倍用量兑换。 https://t.co/RPnFwUs2CJ↗
Claude@claudeai
Introducing Claude Sonnet 5, our most agentic Sonnet yet. It makes plans, uses tools like browsers and terminals, and runs autonomously at a level that just a few months ago required larger and more expensive models.
推出 Claude Sonnet 5,我们最具智能体能力的 Sonnet。它会制定计划,使用浏览器和终端等工具,并能以几个月前还需要更大、更昂贵模型才能达到的水平自主运行。
narrative violation: open source can be monetized if Kimi is doing $300M ARR, 70%+ from API --the lesson for the US isn't to dismiss Chinese open models, but build better open model businesses here.↗
Poe Zhao@poezhao0605
Moonshot AI's Kimi has reportedly hit $300 million ARR as of mid-June, with API revenue exceeding 70% of total. A new funding round is underway at $31.5 billion pre-money, per Chinese financial media. Four months ago, the valuation was $10 billion.
据中国财经媒体报道,Moonshot AI 的 Kimi 截至 6 月中旬 ARR 已达到 3 亿美元,API 收入占总收入超过 70%。新一轮融资正在进行,投前估值 315 亿美元。四个月前估值是 100 亿美元。
Similarly, use multi-agent in Claude Managed Agents to mix Sonnet 5 and higher capacity sub-agents in order to delegate work to the right level of intelligence. https://platform.claude.com/docs/en/managed-agents/multi-agent↗
Sonnet 5 is a clear upgrade from 4.6, and the claude-api skill makes the migration even easier. This skill tunes prompts for Sonnet 5, recommends effort levels, and configures advisor mode. https://platform.claude.com/docs/en/agents-and-tools/agent-skills/claude-api-skill↗
Claude Sonnet 5 is here. Top-tier performance on coding and tool use at Sonnet pricing, with a 1M context window. It's the new default in Claude Code for Pro users, and available everywhere on the Claude Platform, including the API and Managed Agents.↗
Claude@claudeai
Introducing Claude Sonnet 5, our most agentic Sonnet yet. It makes plans, uses tools like browsers and terminals, and runs autonomously at a level that just a few months ago required larger and more expensive models.
如果你想给自己的聊天应用添加导航轨迹,新的 MessageScroller 组件已经内置了你需要的 hooks。找这个:const { currentAnchorId, visibleMessageIds } = useMessageScrollerVisibility()
Introducing Claude Sonnet 5, our most agentic Sonnet yet. It makes plans, uses tools like browsers and terminals, and runs autonomously at a level that just a few months ago required larger and more expensive models. https://t.co/UKK8G7ww5h↗
我想我刚才从根本上解决了一个 claude code / codex 封号或创建账号的难题: 那就是我合法雇佣一个合法的 claude code/ codex agent。 我可以永远避免被 Anthropic/OpenAI 审查账号的问题,也可以避免使用中转站。↗
What an honor to emcee the first day of @aiDotEngineer and introduce the Software Factories Track Thank you @swyx & team, and @KeycardLabs for the support. “A year ago @GeoffreyHuntley released the Ralph loop. It captured our attention and sparked our imagination as we watched Ralph loops work autonomously overnight and forge entire products on its own. However, it wasn't perfect and in the early days it came recommended for greenfield work only and it came with the expectation↗
How many Ascend 910s Huawei can manufacture with 'stolen' dies? Answer: 1.6 million This number is based on how many HBM stacks they have stockpiled. That is quite a lot to reach AGI, if you ask anyone. What happens if stolen dies or HBM runs out? - Compute dies: China's SMIC is making 7nm chips for the next generation ascend. They can make them in millions. - Memory: HBM is a bigger challenge as Chinese entities are barred from procuring anything above HBM2E. That said HBM stack e↗
Lennart Heim@ohlennart
Probably the biggest non-Nvidia pre-training run in China. ≈1e25 FLOP (≈DeepSeek v4 Pro or Qwen3 Max). 50k+ "AI ASICs." Probably Huawei's CloudMatrix-384 superpods with 910Cs (~40 to 80MW). We're finally seeing data centers with the illicitly procured AI chips from TSMC.
这可能是中国最大的非英伟达预训练运行。约 1e25 FLOP(大约 DeepSeek v4 Pro 或 Qwen3 Max 级别)。5 万多块“AI ASIC”。很可能是华为 CloudMatrix-384 超节点,使用 910C(约 40 到 80MW)。我们终于看到使用从台积电非法采购的 AI 芯片的数据中心了。
Yo dawg, I heard you like loops... (from @swyx's AI Eng keynote this morning) https://t.co/JaAVbxBIwJ↗
There is a lot of pride among AI founders today around doing "996." 9 to 9, 6 days a week. SF is normalizing the 72-hour week to win the AI race. I started Upside to enable a different way of winning. The whole promise of AI is that people should work LESS, and only on WHAT MATTERS not get chained to their desks grinding. @alexdbauer wrote more on how we did it, I just made the images :-) and @swyx and @vibhuuuus helped us print them at @aiDotEngineer yesterday.↗
Alex Bauer@alexdbauer
Netflix 在 Willy Wonka 真人秀中使用 AI 生成的 Gene Wilder 声音
Netflix 新真人秀预告确认使用 AI 生成的 Gene Wilder 声音,引发围绕真人秀与 AI 复刻声音的讨论。
𝗚𝗟𝗠-𝟱.𝟮 (the latest open weights model) is having an Enterprise moment, and it is not an exaggeration.🚀 🔥 We have been impressed by how strongly GLM-5.2 is pushing long-horizon performance .. not just in coding, but also in 𝗲𝗻𝘁𝗲𝗿𝗽𝗿𝗶𝘀𝗲 𝗽𝗹𝗮𝗻𝗻𝗶𝗻𝗴, 𝘁𝗼𝗼𝗹 𝗰𝗮𝗹𝗹𝗶𝗻𝗴 and workflow 𝗲𝘅𝗲𝗰𝘂𝘁𝗶𝗼𝗻. On EnterpriseOps-Gym, GLM-5.2 is now the highest-scoring open-source model we’ve evaluated, clocking in at 𝟯𝟱.𝟴%, close behind Claude Opus 4.8. Even more interesting: when combined with↗
头部模型厂商做自己的cli是一大趋势,Kimi Code的机会挺好,可以试试↗
Kai@real_kai42
🤠 Kimi Code也在招人,感兴趣直接发我邮箱 me@kaiyi.cool 感谢大佬们帮忙扩散 捧场
find me and say hi👋 @aiDotEngineer today! im giving a talk at 2p on long-horizon agents: brain / hands decoupling, loop design, memory + dreaming, and async agent UX patterns. https://t.co/rkSqiYMoIo↗
Katelyn Lesse@katelyn_lesse
so we didnt go to beta. we went back & did a full rearchitecture, separating the brain from the hands. the team wrote a deep dive here:
所以我们没有进入 beta。我们回头做了一次完整的重新架构,把大脑和手分开。团队在这里写了一篇深度解析:
I am not sure if superforecasters & AI Policy eggsperts have been vastly more optimistic than me on Chinese hardware all along. Nobody had trained a >1.5T MoE on prev gen Ascends before because it IS HARD – yes bandwidth etc. I thought it won't be done. This is an update. https://t.co/akyCPZO4FK↗

Word of the day so far at AIEWF is Loop. @swyx talked about “loopcraft” in his opening address, and the word was used constantly by the following speakers from Microsoft and OpenAI, and then “the clawfather” Peter Steinberger. https://t.co/qVVmoBGYi6↗
将 Heat Resilience 数据扩展到 50 多个全球城市
气候与可持续
RAM 供应商是否操纵价格?这起诉讼这样指控,但我不认为能解决“RAMpocalypse”
诉讼指控内存供应商通过转向高价 HBM 等方式合谋抬价,但作者怀疑这能真正降低消费者内存价格。
Introducing Claude Science, a new app designed with every stage of research in mind. Artifacts traced to their code, environments managed on demand, and 60+ optional scientific databases that you can connect. Available now in beta. https://t.co/HKhLknxLJO↗
NVIDIA BioNeMo Agent Toolkit 将加速 AI 带给 Claude Science 生命科学研究者
NVIDIA 介绍 BioNeMo 工具如何把 GPU 加速、模型和微服务带进生命科学 Agent 工作流。
Trump 重做所有 .gov 网站的计划导致 AI 设计灾难
文章批评 Trump 用 AI 快速重设计政府网站的计划效果糟糕,出现大量设计和体验问题。
帮转招人信息,Kimi Code 招人↗
Kai@real_kai42
🤠 Kimi Code也在招人,感兴趣直接发我邮箱 me@kaiyi.cool 感谢大佬们帮忙扩散 捧场
You asked, we listened. Claude Desktop on Linux is here! Download link: https://code.claude.com/docs/en/desktop-linux↗
ClaudeDevs@ClaudeDevs
Claude Desktop is now available on Linux (Ubuntu and Debian) in beta. Alongside the browser and terminal, you now get a first-class desktop experience with Claude Code, Claude Cowork, and chat on all paid plans.
Claude Desktop 现在在 Linux(Ubuntu 和 Debian)上推出 beta。除了浏览器和终端,你现在还可以在所有付费计划中获得一流的 Claude Code、Claude Cowork 和聊天桌面体验。
Claude Code 被指在系统提示词里偷偷给中国代理用户“打水印” 一份 Reddit 帖子和一份 GitHub 上的独立验证报告指控:Anthropic 的编程工具 Claude Code 会悄悄检查用户是否通过中国相关的代理服务器访问,如果是,就在发给 Anthropic 的系统提示词里用几乎肉眼不可见的 Unicode 字符差异来“标记”这些用户。 具体怎么做的?安全研究员 Adnane Khan 在 GitHub 上发布了针对 Claude Code v2.1.193 到 v2.1.196 的逆向分析报告。他从二进制文件中提取出了完整的 JavaScript 代码,还原了整个机制。 Claude Code 在每次请求时都会在系统提示词中写入一行“Today's date is 2026-06-30.”之类的日期信息。报告称,当用户设置了 ANTHROPIC_BASE_URL 环境变量(用来把请求转发到非 Anthropic 官方的代理服务器时),Claude Code 会执行以下检查: 第一,看你的代理服务器域名是否在一个包含 147 个条目的列表里。这个列表↗
International Cyber Digest@IntCyberDigest
‼️ BREAKING: Anthropic has embedded hidden spyware-like code in Claude Code that covertly targets Chinese users. It then sends information regarding every user by injecting it into their prompt message. Claude Code is sending info like timezone, proxy and possible AI Lab connections into the system prompt in ways Chinese users can't notice. A coding agent with repo and command permissions should not silently hide routing metadata inside prompts. This is a serious breach of user trust.
突发:Anthropic 在 Claude Code 中嵌入了类似间谍软件的隐藏代码,暗中针对中国用户。它随后把每个用户的信息注入到他们的提示消息里发送出去。Claude Code 正在把时区、代理以及可能的 AI 实验室关联等信息塞进系统提示,而中国用户无法察觉。一个拥有仓库和命令权限的编码智能体,不应该把路由元数据悄悄藏进提示里。这严重破坏用户信任。
2026 年 Claude Code 新手完整教程:从入门到熟练
开始使用 Nano Banana 2 Lite 和 Gemini Omni Flash 构建
Grant Sanderson:AI 与数学的未来
Dwarkesh 与 Grant Sanderson 讨论 AI 在数学上的快速进展,以及数学如何具体展示 AI 进步可能怎样扩散到其他领域。
Giving a talk on agent-to-agent and AI network effects at @swyx 's AI Engineer World Fair today at 1:30p in Room 2010. Come say hi! I think this talk will be a good one if I may say so myself. https://www.ai.engineer/worldsfair/schedule?session=asn_slot_2026_06_30_breakout_track_01_1330_2026_06_11t09_55_41_463z↗
Anthropic is the least ethical of the major labs↗
International Cyber Digest@IntCyberDigest
‼️ BREAKING: Anthropic has embedded hidden spyware-like code in Claude Code that covertly targets Chinese users. It then sends information regarding every user by injecting it into their prompt message. Claude Code is sending info like timezone, proxy and possible AI Lab connections into the system prompt in ways Chinese users can't notice. A coding agent with repo and command permissions should not silently hide routing metadata inside prompts. This is a serious breach of user trust.
突发:Anthropic 在 Claude Code 中嵌入了类似间谍软件的隐藏代码,暗中针对中国用户。它随后把每个用户的信息注入到他们的提示消息里发送出去。Claude Code 正在把时区、代理以及可能的 AI 实验室关联等信息塞进系统提示,而中国用户无法察觉。一个拥有仓库和命令权限的编码智能体,不应该把路由元数据悄悄藏进提示里。这严重破坏用户信任。
报道称 Trump 向 Musk 索要 SpaceX 股票,用于美国儿童储蓄账户
报道说 Trump 计划推出儿童储蓄账户,并希望获得 SpaceX 股票捐赠作为启动资金。
AI 行业正在输
作者借付费通讯导语引出长文,讨论 AI 行业当前的困境与叙事失速。
Libby 会过滤 AI 内容,某种程度上
Lowpass 文章讨论 Libby 对 AI 内容的过滤策略,以及娱乐和技术交叉领域的新边界。
AI Videos are ALL slop. AI should be making you a content machine. Introducing Riverside 2.0, the first AI Producer that creates authentic content while you sleep: https://t.co/qnBHEorlAS↗
Introducing SWE-Together: a multi-turn benchmark built from real user–agent coding sessions. Coding agents are often benchmarked like exam-takers: given the full spec up front, then graded on the final code. But real coding help is a conversation — users clarify goals, add constraints, and correct course along the way. SWE-Together turns real coding work into a reproducible, verifiable benchmark: 109 repo-level tasks curated from 11,260 recorded sessions, replayed wit↗
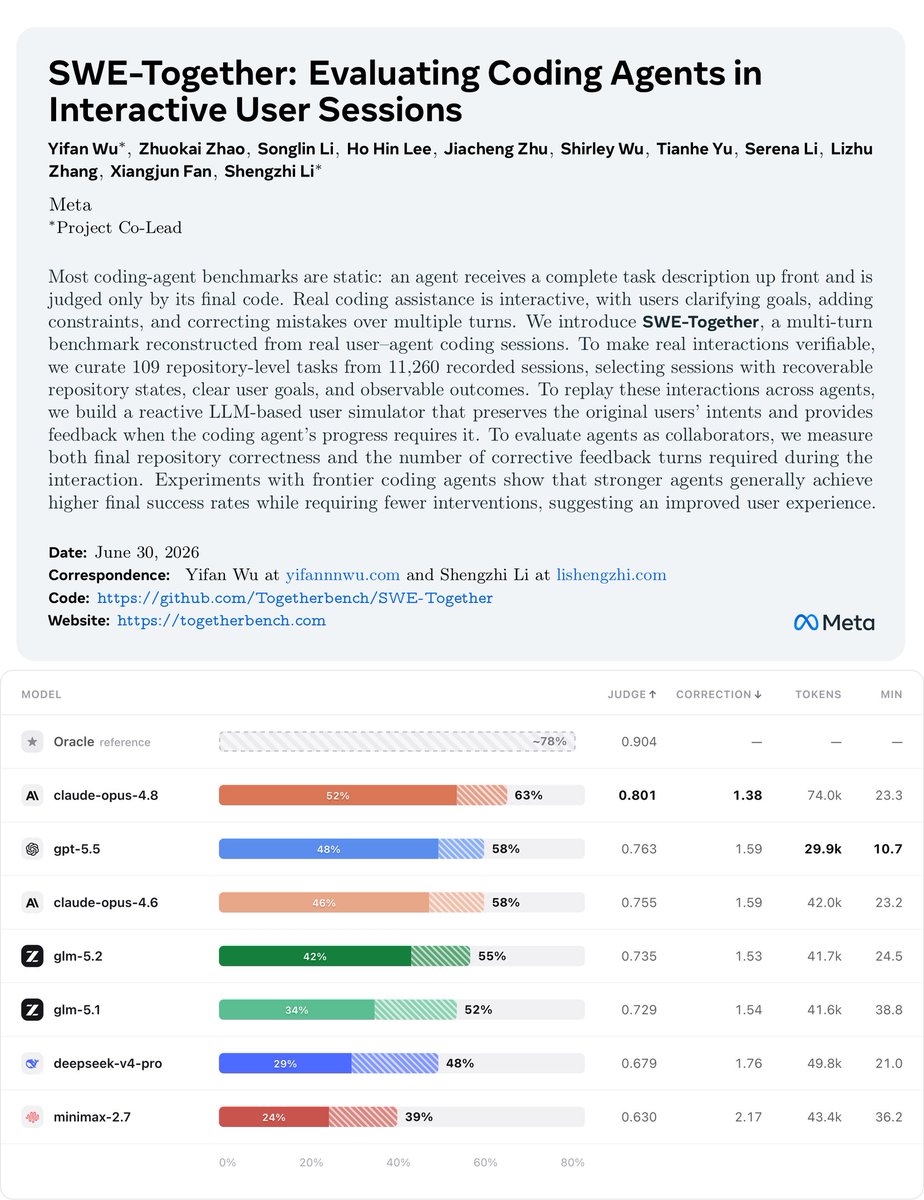
what’s a little funny about the “GPT weak on frontend” discourse is that everything we ship in the codex app gets adopted by the entire industry within days or weeks, pixel for pixel↗
shadcn@shadcn
If you want to add a navigation trail to your own chat app, the new MessageScroller component has the hooks you need out of the box. Look for: const { currentAnchorId, visibleMessageIds } = useMessageScrollerVisibility()
如果你想给自己的聊天应用添加导航轨迹,新的 MessageScroller 组件已经内置了你需要的 hooks。找这个:const { currentAnchorId, visibleMessageIds } = useMessageScrollerVisibility()
When we were in China, @xeophon and I made a quick detour to visit Meituan. They continue to be one of our favorite open model builders, as they're showing how a variety of companies can succeed here and baffle a lot of people as to why they're making models. Meituan is one of the larger tech companies in China. They're building LLMs to add services to their own products. In China the notion of the "super app" is very popular, so this dream of more services for users w↗
Meituan LongCat@Meituan_LongCat
Introducing LongCat-2.0 🐱 1.6T parameters · MoE with ~48B active · 1M context The full model behind Owl Alpha on @OpenRouter — now available. Built for agentic coding from the ground up: ◆ LongCat Sparse Attention (LSA) — scales efficiently for 1M-context tokens ◆ Zero-Compute Experts — dynamic activation 33B–56B per token, zero wasted compute ◆ MOPD — three specialized expert groups (Agent / Reasoning / Interaction), gate-routed per task How it stacks up: → Terminal-Bench 2.1: 70.8 → SWE-bench
推出 LongCat-2.0:1.6T 参数,MoE 约 48B 激活,1M 上下文。@OpenRouter 上 Owl Alpha 背后的完整模型现在可用。它从底层面向 agentic coding 构建:LongCat Sparse Attention 可高效扩展到 1M 上下文 token;Zero-Compute Experts 每个 token 动态激活 33B 到 56B,零浪费算力;MOPD 有三个专门专家组(Agent、Reasoning、Interaction),按任务门控路由。表现:Terminal-Bench 2.1 为 70.8;SWE-bench……
GPT-5.6 来了,但是……
作者从希腊长周末回来后,谈到自己投资的公司 Etched 以及 GPT-5.6 相关消息。
NVIDIA 推理软件栈如何实现最低 token 成本
文章解释企业从 AI 试点走向生产后,基础设施决策如何转向每 token 成本。
Jaiveer Singh 如何帮助机器人和开发者更快行动
文章介绍 Jaiveer Singh 在机器人基础设施、开发板和软件工具上的工作。
眼下最热门的公司
We're coming out of stealth. We've built our first racks after a successful A0 tapeout, $1B+ in customer contracts, and $800m raised. Early customer tests show us achieving SOTA throughput, latency, and power efficiency on inference workloads. Our first racks ship this summer. https://t.co/FLccrkLTza↗
我们要让数据中心吞掉所有电力、水和清洁空气吗?
文章批评 AI 基础设施竞赛对电力、水和环境的巨大消耗,指出数据中心建设仍处于监管不足状态。
为什么 specialization 不可避免
V0 of this so far works pretty well. Did GEPA on Qwen 4B (3.5) to get the ask detection working well , e.g. given this slack message what’s the intention, deliverable, etc. Noise to signal I’d ballpark 60/40 but the system will send me its targets on fridays for me to label and perform more GEPA (or to do a full SFT once enough data exists and I decide that it should be a hair stronger)↗
Zach Mueller@TheZachMueller
Some rambles on my journey so far in what it would take to make me an EA: Essentially it boils down to data (shocking). Put enough observability points in your system and you can wire a few models together to extract signals from this data to act upon. Or, translated: - Read your slack (& DMs) - Read your Notion events - Read your email - Read your calendar Emphasis here is READ. Then very select write permissions based on your own needs. But this is an EA, not replacing you, so this should be v
关于我到目前为止要怎样才会做出 EA 的一些碎碎念:本质上归结为数据(并不意外)。在系统里放入足够多的可观测点,就能把几个模型串起来,从这些数据中提取信号并采取行动。换句话说:读取你的 Slack(包括私信)、读取 Notion 事件、读取邮件、读取日历。重点是“读”。然后根据你自己的需要,非常有限地给写权限。但这是 EA,不是替代你,所以它应该非常……
每个员工都该像一个人的创业公司
Build and Train your own Diffusion Language Models! dllm is an open-source library that lets you build, train, and evaluate diffusion-based language models without setting up complex pipelines or writing custom training loops. Most language models today are autoregressive. They generate token by token, which makes training and inference fast but also leads to problems like exposure bias and difficulty maintaining global coherence. Diffusion language models flip this a↗
alphaXiv@askalphaxiv
"Improved Large Language Diffusion Models" ByteDance just made bidirectional masked diffusion on-par with autoregessive LM! This paper iLLaDA trains an 8B Transformer from scratch on 12T tokens, then keeps the same denoising objective for SFT on a 25B-token instruction corpus. It improves LLaDA with GQA, tied embeddings, variable-length generation, confidence-based MCQ scoring, and packed-sequence diffusion SFT. iLLaDA-Base raises the average score from 51.1 to 63.9 and slightly exceeds Qwen2.5
《Improved Large Language Diffusion Models》:ByteDance 刚把双向 masked diffusion 做到了与自回归 LM 同等水平!这篇 iLLaDA 论文从零开始用 12T tokens 训练一个 8B Transformer,然后在 25B-token 指令语料上继续使用同样的去噪目标做 SFT。它通过 GQA、权重绑定嵌入、可变长度生成、基于置信度的 MCQ 评分,以及 packed-sequence diffusion SFT 改进 LLaDA。iLLaDA-Base 将平均分从 51.1 提高到 63.9,并略高于 Qwen2.5……
周报 #2 来了,拖了好久,周末去杭州参加 Community Day 一直没时间写。主要写了 Raft @raft_hq 的体验: Raft 我也安装很久了,但是一直没有把活安排上去。我是先看了 Raft 的几篇博客,我觉得 Raft 团队是真的在 AX 上下了功夫的,以后也许会开一篇单独谈一下 AX,他们定义为 Agent Expirence Design。Raft 始终把 Agent 放在一等公民的位置,所以他们也需要对软件有更好的体验,但 Agent 和人类也有区别,Agent 读取数据时,不会对糟糕的格式产生反对,只会默默降低他们的表现。于是,我们更应该做好 AX。 下面说两个让我觉得“Raft 真正把 Agent 作为一等公民”的体验: 「不需要人类去构造 Agent Identify」 这点我觉得设计的很好,它无形中让 Agent 的 Identify 成为了一个需要逐渐积累的过程,让 Agent 的意义不止是“一堆提示词 + 一堆 skill”,让 Agent 的名字承载了更多的意义和期望,让我可以把 Agent 真正当↗
顶尖 PM 如何用 AI 提升杠杆
Lenny 回答读者问题,讨论产品经理如何用 AI 提升产出、影响力和职业发展速度。
We can finally say AI isn't killing jobs. A new paper from me, @tryramp, and @RevelioLabs uses firm-level spend and workforce data across 21K U.S. businesses to measure AI's impact on jobs. Firms that adopt AI heavily grow headcount 10% over two years following adoption. Low adopters see no statistically significant change.↗
Into the Omniverse:用合成数据和微调提升 Vision AI Agent 准确率的三种工作流
NVIDIA 介绍开发者和企业如何用 OpenUSD、合成数据和微调改进 Vision AI Agent。
别掉进这个 AI 陷阱
农业已经准备好迎接 AI,但数据还没有
AI 正在改变农业可能性,但行业在投入 AI 之前必须先解决数据基础、质量和组织问题。
认识那个两次击败 Elon Musk 的律师
文章讲述律师 Bill Savitt 与 Elon Musk 相关案件中的经历和背景。
Narrative violation: A new study of 21,559 firms in the U.S. finds that “companies that adopt AI tend to grow faster following adoption”. “Firms making the largest AI investments grow employment by roughly 10% following adoption, while low-intensity adopters see no statistically significant change.” “Entry-level headcount rises 12% for high-intensity adopters.” “Gains emerge gradually and are broad across roles, including engineering, sales, administration, and customer serv↗
In the last 24 hours, I have had 5 founders message me of varying-sized companies; some 10-person startups and one $200BN public company. All of them stated they have been able to cut inference spend by 75% or more with little effort, no performance change and better latency. The times they are a changing.↗
为地球上每个国家供能的计划
This is huge news for China’s AI ecosystem. Meituan just released a 1.6-trillion parameter AI model trained entirely on Chinese AI chips. They’ve been working on using Chinese AI chips since 2023. https://t.co/AH0dWE832Q↗
梦想中的训练营:高级生产级 AI LLM 工程训练营发布
Bernie Sanders 早就看到了这一幕
文章回顾 Sanders 长期警告财富集中威胁民主,并认为围绕 Big Tech、亿万富豪和 AI 的不满正在上升。
推出 TabFM:面向表格数据的零样本基础模型
数据管理
OpenAI 正在复制 Apple 最大的竞争优势,Nvidia 该警惕了
文章认为 OpenAI 自研 AI 芯片显示其正在走 Apple 式垂直整合路线,从而削弱对 Nvidia 的依赖。
Meta AI 发布 Brain2Qwerty v2:非侵入式 MEG 脑到文本管线,可用 61% 词准确率解码输入句子
Brain2Qwerty v2 能从用户打字时的 MEG 信号中实时解码自然句子,展示非侵入式脑到文本的进展。
[AINews] 今天没发生太多事
作者称在 AI Engineer World’s Fair 期间氛围很好,但更广泛的 AI 世界当天相对平静。
现在全都不妙了……
Hugging Face Model Pages 上线 Every Eval Ever 结果
Loops 入门
SkillOpt:把 Agent skills 当作可训练参数
SkillOpt 将 skill 编辑转化为训练过程,让 Agent 行为在不改变模型权重的情况下更可靠。
Dream Relic 如何看见声音并让它在脑中挥之不去
Dream Relic 谈超现实视觉、情感化世界构建,以及如何用 Suno 给自己的电影宇宙配上声音。
Claude Science:面向科学家的 AI 工作台现已可用
Claude Science 是一个可定制应用,整合研究人员常用工具和软件包,生成可审计产物并提供灵活访问。
Claude Sonnet 5 发布
Sonnet 5 在编码、Agent 和专业工作流上提供前沿性能。
重新部署 Fable 5
Fable 5 将于 7 月 1 日全球回归。Anthropic 还与 Amazon、Microsoft、Google 等伙伴提出行业级 jailbreak 严重性评分框架。
用机器学习识别可改善分枝杆菌外膜渗透的化学特征
RNAbpFlow:结合碱基对增强的 SE(3) 流匹配,用于条件 RNA 3D 结构生成
AI 系统提出假设并设计检验方法
无需分割的活细胞成像分析揭示 T 细胞改造如何影响癌细胞聚集动态
AMIE 和 MIRA Agent 推进医疗 AI 能力
AI 工具能加快思考,但证据仍来自实验台
06 / 29周一28 条
推文 0资讯 14视频 3产品 4研究 4论文 0播客 0
OpenClaw 发布 iOS 和 Android 伴侣 Node 应用,连接手机与自托管 AI Agent 网关
OpenClaw 发布免费移动端伴侣应用,让手机连接自托管 AI Agent 网关,而不是作为独立聊天机器人运行。
Meta 承包商假扮青少年,测试竞品聊天机器人对自杀、性和毒品问题的回答
WIRED 报道称 Meta 项目中的承包商假扮儿童,测试 Gemini、ChatGPT 等聊天机器人对高风险问题的回应。
PyGraphistry 实战流程:用于安全分析与风险调查的交互式图智能管线
教程构建一个可在 Colab 运行的 PyGraphistry 工作流,用于企业访问数据的图分析、可视化和风险调查。
韩国将投入 1 万亿美元扩大内存芯片产能和人形机器人
韩国政府和头部科技公司计划投入巨资建设芯片产能、AI 数据中心和人形机器人项目。
Fitbit 的 Gemini AI 教练给出“离谱”健身建议,用户说“等不及试用结束”
Fitbit 新 AI 健身教练被用户批评建议不靠谱,引发对 Gemini 驱动健康功能质量的质疑。
Tidal 不会为 AI 生成音乐支付版税,但也不会完全禁止
Tidal 发布 AI 生成音乐政策,计划保护艺术家并告知听众,但不直接全面封禁 AI 音乐。
NVIDIA BioNeMo Agent Toolkit 将生物分子模型变成药物发现 AI Agent 的可调用技能
文章介绍 AI 科学家如何调用 BioNeMo 工具,把生物分子模型封装成 Agent 可使用的能力。
DiScoFormer:一个 Transformer 跨分布同时处理 density 和 score
AI Agent 不是你的“同事”
文章批评把 AI Agent 拟人化为同事的说法,提醒企业重新审视人机协作中的权责和管理方式。
Claude 遇上 Blackwell Ultra:Anthropic 模型现在在 Azure 上运行于 NVIDIA GB300
Anthropic Claude 模型已在 Microsoft Azure 的 NVIDIA GB300 Blackwell Ultra GPU 上通过 Microsoft Foundry 提供。
Meta AI 新研究负责人 Dawn Song:下一个前沿是“有经济价值”的 AI Agent,而不是取代人类
Dawn Song 表示真实世界影响比基准分数更重要,Meta 最新模型更强调安全、信任和实际价值。
Claude Skills 终极指南
How I AI:GLM-5.2 评测,以及 Gusto 如何用 Claude Code 做新产品线
本期播客评测 GLM-5.2,并讨论 Gusto 如何用 Claude Code 构建新产品线,同时附带赞助信息。
Firefly Aerospace 首次在月球轨道运行 NVIDIA Jetson
与 AI 协作:一个具体例子
Hacker News 热帖,围绕 htmx 文章中一个具体的 AI 协作案例展开讨论。
技术前沿上的 Agent 可信度
文章讨论企业 AI 投资升温时,组织如何在战略目标、ROI 和 Agent 能力可信度之间取得平衡。
Tidal 的 AI 政策
Hacker News 热帖,讨论 Tidal 关于 AI 生成音乐、版权和平台治理的新政策。
Import AI 463:自我改进机器人、1 万张中国 GPU 集群,以及写给人类时代的挽歌
Import AI 本期覆盖自我改进机器人、中国大规模 GPU 集群等研究和产业动态,并附一篇关于人类时代的反思文章。
用 AI 生成最好的动画
没有 Figma、没有 Jira、没有文档:Gusto 如何用 Claude Code 做出新产品线 | CTO Eddie Kim
Gusto CTO Eddie Kim 讲述团队如何用 Claude Code 推进一条新产品线,挑战传统产品开发里的设计稿、工单和文档流程。
你真正需要的 AI 工具
这个人形机器人是个可怕地称职的办公室实习生
Flexion Robotics 由前 Nvidia 工程师创立,展示了一种训练机器人完成实用办公室工作的方式。
央行人士警告:AI 热潮可能引发全球金融崩盘
Hacker News 热帖,讨论央行人士对 AI 投资热潮和全球金融风险的警告。
Claude in Microsoft Foundry 已正式可用
面向 Amazon Bedrock 和 Google Cloud 的 Claude Apps Gateway 发布
用 Cursor iOS 随时随地构建
Cursor iOS 原生应用已开放公测,可在手机上使用 Cursor。
从脑电波到文字:Brain2Qwerty 提供无需手术的新沟通路径
Memora:在抽象性和具体性之间取得平衡的谐波记忆表示
Memora 是一个面向 AI Agent 的可扩展记忆系统,将存储内容与检索方式分离。
06 / 28周日11 条
推文 0资讯 3视频 5产品 0研究 0论文 0播客 0
我们需要排除 AI 的科技新闻源
作者认为 Techmeme 和 HN 等科技新闻面越来越被 AI 淹没,需要保留非 AI 技术新闻的渠道。
改进 Obsidian + Claude Code 配置的最简单方法
用来修复 Claude Code 网页设计的热门 GitHub Repo
AI 不够给力后,Ford 重新聘用“老派”工程师
Hacker News 热帖,讨论 Ford 在 AI 未能达到预期后重新聘用资深工程师。
Anthropic PM 内部如何使用 Agent
最新开放制品(#22):Zyphra、Cohere 和 Poolside 正在拓展生态宽度
文章观察开放模型发布越来越多样化,Zyphra、Cohere 和 Poolside 等机构正在扩展开放生态的范围。
用本地 LLM 运行 NemoClaw:部署更安全的 AI Agent
教授痛批 Brown 考试中的大规模 AI 作弊
Hacker News 热帖,讨论 Brown 大学考试中被指大规模使用 AI 作弊,以及学术诚信风险。
本周顶尖 AI 论文
本期精选 AI 论文,开篇讨论 Sakana Fugu 与多模型组合、前沿 LLM 专业化等趋势。
Anthropic 如何押注“睡觉时也能工作”的 Claude Agent | Jess Yan
OpenAI Codex 负责人谈产品工作的新形态 | Andrew Ambrosino
Andrew Ambrosino 负责 OpenAI Codex 桌面应用。他分享 Codex 在 OpenAI 内部的高频使用,以及它如何改变产品与工程协作。
06 / 27周六9 条
推文 0资讯 2视频 2产品 0研究 0论文 0播客 1
社区智慧:摆脱职业低谷、给成熟团队加结构、新团队 1:1 问题、增长角色的演化等
Lenny 社区周报,汇总会员 Slack 中关于职业低谷、团队结构、1:1 和增长岗位变化的高价值讨论。
HERMES Agent + Stripe 支付 + NVIDIA Nemotron 太夸张了
AI Agents Weekly:GPT-5.6、Ornith-1.0、Codex Inside OpenAI、Claude Tag、Qwen-AgentWorld、AI SDK 7 等
本期涵盖 GPT-5.6 预览、Ornith 开源编码模型、OpenAI 内部 Agent 使用、Claude Tag、Qwen-AgentWorld 和 AI SDK 7。
3 个让产出提升 10 倍的 OpenClaw 配置
使用本地 Coding Agent
作者整理自己的本地 Agent 技术栈和搭建方式,回应读者关于本地编码 Agent 工作流的提问。
[AINews] OpenAI GPT-5.6 Sol / Terra / Luna:仅限可信伙伴
在 Anthropic Fable 谈判和 Mythos 限制放松背景下,GPT-5.6 被公布但仅向可信伙伴开放。
Anthropic 指控 Alibaba 通过海量提问复制 Claude,并拉开新 AI 战争序幕
报道称 Anthropic 指控与 Alibaba 和 Qwen 实验室有关的团队通过大量查询提取 Claude 能力。
Trump 政府允许 Anthropic 向部分美国机构发布 Mythos
经过数周谈判,White House 允许 Anthropic 向部分美国公司和政府机构开放其先进 AI 模型。
少有的深度参与过字节、美团组织建设的人|对谈 AI 创业者魏小康↗
活动预告🥳:7 月 4 日,我们会请到魏小康做一场线下活动,大家记得翻到 shownotes 末尾查看报名信息! 魏小康可能是国内最懂组织建设和招聘的人之一,也是一个先后深度参与过字节和美团组织建设的稀缺样本: 2017—2020 年,他在字节担任招聘负责人,经历了抖音的高速增长与国际化;2020—2026 年,他又在美团担任招聘负责人及 AI 产品经理。 节目一开始,我们就从小康在这两家公司的经历聊起。字节和美团分别有着怎样的组织思路?像张一鸣和王兴这样的优秀创业者,有哪些共同特质? 随后,他展开讲了讲这些年对组织建设的诸多思考。组织建设其实可以拆成两
06 / 26周五7 条
推文 0资讯 3视频 2产品 0研究 1论文 0播客 0
韩国计划把全军训练成“无人机战士”
韩国宣布要训练近 50 万军人像使用个人武器一样操作无人机。
付费:泡沫笔记,第 1 卷
过去几周格外漫长,作者原计划的 Hater's Guide 来不及写,于是改开一个持续更新的短札系列。
用冻结的 Multi-Token Prediction 加速 Pixel 上的 Gemini Nano 模型
机器智能
OpenAI 刚给 Codex 加了超能力,以及更多实用 AI 新闻
AI 新闻:那个媲美 Fable 的新模型
OpenAI 有了新 AI 模型,但你为什么用不上
报道称 White House 要求 OpenAI 推迟 GPT-5.6 模型发布,此前 Anthropic 也被迫下线其先进模型。
下一次重大突破会是 AI 在工作中学习
Dwarkesh 讨论实验室当前押注的方向:如果训练 AI 在大量可验证任务和多样 RL 环境中完成工作,就可能推动出具备更强泛化能力的系统。
该分类暂无内容。