[AINews] FrontierCode:对代码质量(而非「水货」)的基准测试
[AINews] FrontierCode: Benchmarking for Code Quality over Slop
Second batch of AI Leadership and Engineering+Workshops tickets for AI Engineer World’s Fair sold out last night! Last 500 tickets on sale now - get while stocks last! 20% off for the first 20 readers who see this.
It is rare that we are personally involved in the title story of the day, and Apple’s WWDC announcing Gemini-powered Siri was a possible candidate, but we’ve been fooled before. So instead, we’ve got FrontierCode, the latest in our War on Slop!
If that chart looks familiar, it’s because FrontierCode was explicitly inspired and named for FrontierMath - focusing its hardest tier on extremely hard problems for frontier models 2 years ago:
The context of FrontierCode revolves around past work we have done around SWEBench-Verified.
It is clear that even with the switch to SWEBench Pro, there has been insufficient articulation around WTF Happened in 2025. As discussed with the OpenAI team in that podcast, there needed to be a lot more work around the rubrics for code quality and maintainability, and that is exactly what the Cog research team ended up building in this first release of FrontierCode.
Separately, METR found that Many SWE-bench-Passing PRs Would Not Be Merged into Main and the problem of false positive trajectories (not quite “reward hacks”, but spiritually similar in terms of the unreliability of the benchmark rather than the model) was directly measured and addressed in the FrontierCode report.
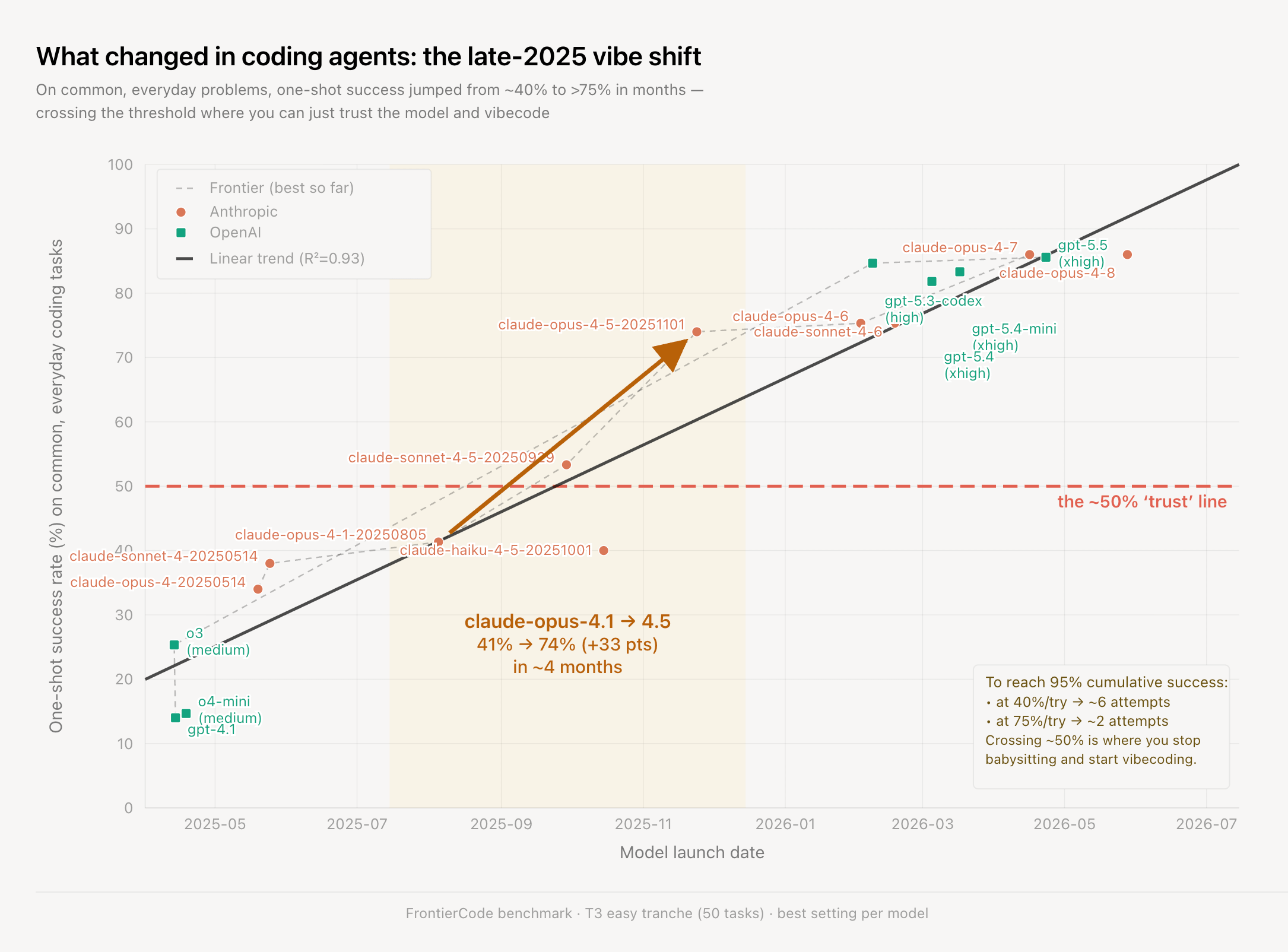
With hindsight, FrontierCode’s third tier of problems shows the huge accceleration going into Dec 2025 that suddenly made agentic engineering and vibe coding possible to go up one level of abstraction, to the /goals and loops and metaprompts we are discussing today.
{kind=link}
AI News for 6/5/2026-6/8/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Coding Agents, Loops, and the Shift from “Passing Tests” to Mergeable Software
FrontierCode raises the bar on coding evals: Cognition introduced FrontierCode, a new benchmark explicitly targeting whether code is actually mergeable, not merely unit-test passing. Tasks were built with open-source maintainers, with each taking 40+ hours and evaluated on dimensions like regression safety, cleanliness, scope, test correctness, and maintainability. The headline result is that the best model, Opus 4.8, scores only about 13% on the hardest subset—far below the 50%+ regime common on SWE-Bench-style evals, suggesting coding is much less “solved” than popular benchmarks imply (Cognition announcement, Scott Wu’s summary, swyx breakdown, theo’s questions on variance/reproducibility, Cognition response).
“Loops” are becoming the dominant agent-control metaphor—but with caveats: The day’s loudest practical theme was that coding agents should be given clear goals, verification criteria, and iteration structure rather than one-shot prompts. Popular examples include dzhng’s “don’t use loops, design state machines”, Claude Code’s retrospective on auto mode, routines, and verification, bcherny’s thread, OpenAI Codex tips on outcome-first prompting and Approve-for-me defaults, plus LangChain OSS “rubrics”. But several practitioners pushed back on naïve loop hype: Omar Sar0 and Graham Neubig emphasized that human checkpoints remain essential outside easily verifiable domains, while Hamel Husain joked about muting the word entirely.
Agent ergonomics are improving around verification and orchestration: Product changes across the stack reflect this shift. ClaudeDevs added observability dashboards for MCP connector developers, including adoption, latency, and error views. MagicPath launched a Builder plan for external-agent workflows and multiplayer canvas editing. LangSmith Sandboxes and Modal’s sandbox scaling story point toward the same infrastructure trend: agents need isolated, inspectable, long-running environments.
Practical usage patterns are settling: The strongest operator advice converged on measurable outcomes, bounded autonomy, and thread hygiene. Angaisb_ warned against overlong Codex threads degrading performance, while reach_vb reported success with single-thread context accumulation. That mismatch itself is useful signal: current agent performance is still strongly shaped by harness behavior and workflow choices, not just base-model quality.
Model Releases, Local Inference, and Serving Stack Upgrades
Kimi shipped both a stronger coding agent and a desktop agent product: Moonshot released a major update to Kimi Code, its open-source coding agent, adding one-line CLI install, drag-and-drop video as coding context, ACP support, plugins, and IDE integration (announcement). It also launched Kimi Work, a desktop agent product with up to 300 local sub-agents, browser-use via extension, finance-focused tool access, and persistent memory (product launch, desktop availability).
Google pushed hard on efficient local deployment: Gemma got several notable upgrades. New QAT Gemma 4 checkpoints reportedly preserve performance while using ~4x less memory, with Gemma 4 E2B fitting in about 1GB using a mobile quantization format (@_philschmid). Separately, Gemma 4 MTP was merged into llama.cpp, enabling faster decoding when paired with QAT checkpoints (Gemma team). llama.cpp also added video input support, expanding local multimodal use cases.
Open-source/open-weight competition remains intense: Artificial Analysis reported MiniMax-M3 at 55 on its Intelligence Index, which would make it the leading open-weights model once weights are released. M3 adds native multimodality and a 1M token context window, with strong GPQA/MMMU-Pro numbers but notable abstention on hallucination-sensitive evals. Meanwhile norpadon announced Apple-hardware-optimized quantized Qwen3.5 checkpoints.
Serving infrastructure is broadening from text LLMs to world models and omni models: vLLM-Omni 0.22.0 added day-0 support for NVIDIA Cosmos 3 world models, robot serving APIs, TTS models such as Qwen3-TTS and VoxCPM2, faster image/video serving, and broader quantization/hardware coverage (release). This reflects a broader trend toward generalized multimodal serving rather than text-only inference stacks.
Benchmarks, Evaluation Methodology, and Real-World Agent Measurement
Agent evaluation is moving from synthetic tasks to in-the-wild telemetry: Arena launched Agent Arena, a leaderboard based on over 1M real-world sessions, using causal tracing rather than voting to estimate treatment effects of orchestrators/harnesses across five signals: confirmed success, praise vs complaint, steerability, bash recovery, and tool hallucination (overview, methodology thread). Whether the methodology fully holds up remains to be seen, but it’s one of the clearest attempts yet to benchmark deployed agents using actual usage traces.
Specialized benchmarks keep proliferating into new output domains: Hugging Face and Mecado released CADGenBench, a benchmark for generating and editing engineering-grade 3D CAD parts from drawings or STEP modifications, with metrics covering geometry, topology, interface compatibility, and CAD validity (launch thread, Thom Wolf summary). This is a meaningful shift: evaluation is expanding beyond text/code into structured artifacts where correctness is physical and geometric.
A recurring thesis: good benchmarks become training pipelines: Ofir Press argued that the best benchmarks are scalable and rooted in real-world crawled data sources, making them useful not just for measurement but also for data generation. That view shows up implicitly in both FrontierCode and Agent Arena: benchmarks are no longer static scoreboards; they are becoming feedback loops for product and RL improvement.
Google, Apple, and the Consumer AI Platform Race
Google expanded AI packaging, Search, and developer surfaces: Google announced a more capable NotebookLM with agentic chat, stronger reasoning, and more output formats for Ultra subscribers (launch). It also cut Google AI Plus pricing from $7.99 to $4.99/month while doubling storage to 400GB (pricing update). On the platform side, Google highlighted a major Search upgrade, including multimodal search and Gemini 3.5 Flash as the new default in AI Mode.
Apple’s WWDC AI story centered on integration, not frontier leadership: Commentary around WWDC focused on a rebuilt Siri AI with on-screen awareness, app actions, personal context, and better voice interaction, alongside concerns about EU availability and hardware gating (kimmonismus live thread, regional limitation note). A technically notable detail came from awnihannun: Apple’s on-device model is reportedly a 20B-parameter query-routed architecture that loads experts from NAND into RAM once per query, a nonstandard design optimized for device constraints.
Research Directions: Continual Learning, Agent Training, and Optimization Debates
Anthropic framed one core blocker for AI in science as infrastructure mismatch: Its new science blog argues AI has advanced faster in coding than biology because biological databases and tooling were not designed for agent use; the bottleneck is less raw intelligence than agent-compatible scientific infrastructure (Anthropic blog thread). This pairs well with broader calls for harness/environment standardization.
Open-source RL and environment protocols are becoming coordination points: OpenEnv was transferred to a consortium including Hugging Face, Meta-PyTorch, Reflection, Unsloth, Modal, Prime Intellect, NVIDIA, and others. The pitch is that frontier labs co-train models with tightly coupled harnesses, while open ecosystems need a shared protocol layer between model, harness, environment, and trainer.
Continual learning for agents is re-emerging as a practical systems problem: Hivemind announced a system that turns traces from agents like Claude Code, Codex, Cursor, and Hermes into reusable skills, claiming measurable gains across setups. Relatedly, Nando de Freitas posted a long thread outlining a research program around learning from interaction consequences rather than token sequences alone.
Optimization discourse was unusually active: Several threads debated whether Muon is materially distinct from Shampoo, with Arohan hinting at a better-than-Shampoo optimizer and Keller Jordan benchmarking Shampoo and Spectral Descent publicly. The substantive point beneath the drama: there is renewed appetite for optimizer-level gains as a real frontier lever, not just benchmark noise.
Top Tweets (by engagement)
Signal on UK device scanning: The highest-engagement technically relevant post was Signal’s statement opposing UK demands for on-device scanning and age-verification-linked content inspection. This is more privacy/security policy than AI, but directly relevant to client-side inference and platform trust.
OpenAI corporate direction and liquidity: Sam Altman shared OpenAI’s current plan, and shortly after OpenAI announced it had confidentially filed an S-1. For AI engineers, the key implication is strategic: both OpenAI and Anthropic now appear to be preserving IPO optionality while ramping capacity and product breadth.
NotebookLM and FrontierCode were the day’s biggest pure-product/eval launches: NotebookLM’s upgrade, Kimi Code, Kimi Work, and FrontierCode dominated the technical conversation, with FrontierCode in particular reshaping the discourse around what “good coding performance” should mean.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
这篇还没有中文全文
该条目暂未提供中文翻译。标题/摘要已自动中译;本系统只对人工挑选的内容生成全文翻译。
挑中后 → markitdown 取正文 → 精翻 → 此处切换为译文