Agentic 代码审查
Agentic Code Review

Coding agents are extraordinarily good now and getting better fast. The interesting consequence is that the hard part of engineering moved from writing code to deciding whether to trust it, which makes review the most leveraged skill in software right now. How you approach it depends enormously on who you are: a solo developer with no users and a team maintaining a ten-year-old application are not solving the same problem.
I am more optimistic about agentic engineering than I have ever been. The agents are genuinely good, they get better every month, and on an ordinary week I now ship things I would not have attempted in the same time a year ago. This write-up is a map of where the interesting work went, because it did move, and most teams have not fully caught up to where.
Code review used to work because of a happy accident of relative speed. A senior engineer could read code faster than a junior could write it, so review kept pace without anyone designing it to, and the team absorbed how the system fit together as a side effect of reading each other’s diffs. A lot of that was not deliberate. It fell out of a single fact: writing code was the slow, expensive part, and reading it was cheap and fast.
That fact no longer holds. An agent will produce a thousand lines of often solid, well-formatted code in less time than it takes me to read this paragraph, while a human’s reading speed has not changed since roughly the day we started staring at screens for a living. So the constraint moved downstream, to the one step that did not get faster: a person being confident the change is right. I do not think that is a loss. It is the most leveraged place in software to be good right now, and it is where I have put most of my attention this year.
There is a happy twist here that shapes the rest of this piece. The same tools generating all that extra code are also the best thing I have for keeping up with it. On my own projects, including the popular open-source ones, I now point Claude Code or Codex at a batch of incoming PRs and have them triage the queue for me, and that has genuinely changed how I spend my time. So this is not an anti-AI argument, and I will come back to exactly how I use it.
It is also not a data dump, and not another round of whether letting a model write your code is wonderful or the end of the craft, because that framing is useless. The only answer that survives contact with a real codebase is that it depends entirely on who you are. A developer vibe-coding a side project a dozen people will ever run, and a team keeping a ten-year-old enterprise system alive for another quarter, share almost no constraints worth naming, and most of the advice in circulation is really one of those two people telling the other how to live.
What the 2026 data actually shows
The productivity gains from AI are real, but raw output overstates them: about four times the code for a tenth more delivered value. The gap between those numbers is review work, which is exactly why review is where the leverage now sits.
For a couple of years this was anecdote and argument. It is now measured at scale, by organizations with no shared agenda and in several cases competing commercial interests, and the measurements keep pointing the same way: AI pushes output sharply up, and pushes both quality and reviewability down.
Faros AI instrumented 22,000 developers across 4,000 teams and tracked what happened as teams moved from low to high AI adoption. This is March 2026 data, about as current as anything here. The upside is real and worth stating plainly: developers merge considerably more PRs and complete more work, and throughput per engineer climbs. Then the rest of the report:
- code churn up 861%
- the incidents-to-PR ratio up 242.7%
- the per-developer defect rate up from 9% to 54%
- median review duration up 441.5%, with time-to-first-review and average review time both roughly doubling
- PRs merged with zero review up 31.3%
The last figure is the one I find hardest to dismiss, because nobody chose it. There was no decision to stop reviewing. Reviewers simply could not keep pace with the volume, so code began merging unread, and that became normal. The detail I keep returning to is that teams with mature, disciplined engineering practices were hit just as hard as everyone else. Good process did not protect them, because the volume arrived faster than any process was designed to absorb.
One caveat to hold throughout: CodeRabbit and Faros both sell into this market, so their framing is not disinterested. That does not make the numbers wrong, the effect sizes are large and consistent across unrelated sources, but vendor research deserves to be read with that in mind.
CodeRabbit studied 470 open source PRs in December 2025, 320 AI-coauthored and 150 human-only, and found the AI changes carried roughly 1.7x more issues: logic and correctness problems up about 75%, security issues 1.5 to 2x more common, readability problems more than tripling. Their AI director David Loker described these as “predictable, measurable weaknesses that organizations must actively mitigate”. Predictable is the operative word. These are known, locatable weaknesses, which is good news: it means a review process, human or automated, can be aimed straight at them.
GitClear has interesting data here too. In their productivity data through 2025, daily AI users produce around 4x the raw output of non-users, but measured against their own output a year earlier, the real productivity gain is only about 12%. You are generating roughly four times the code for something like a tenth more delivered value, and a human still has to review all four times of it. To GitClear’s credit, Bill Harding is explicit that some of even that 12% is selection bias, because stronger developers concentrated in the AI cohort. The gap between 4x the code and a tenth more value is the review problem stated in one line.
GitHub reports that Copilot review has now run over 60 million reviews, a 10x increase in under a year, and more than one in five reviews on the platform involves an agent. This is no longer a niche practice. It is how code gets made.
Four datasets, four methods, one conclusion. We poured machine-speed output into a system built for human-speed work. The bottleneck did not disappear; it moved to verification, and review is where that bill comes due.
Everyone is solving a different problem
How much review a change needs depends almost entirely on its blast radius, and most advice you read was written by someone operating at a very different one.
Almost all the alarming data above comes from enterprise telemetry and from open source maintainers being overwhelmed. It is entirely real if that is your situation. If you are one person shipping something a handful of people will ever run, much of it simply does not apply to you, and you should not be made to feel otherwise.
Three variables determine where you sit:
- blast radius: what happens when it breaks. Nothing, or angry users and money and PII on the line.
- how long the code lives: a throwaway prototype you might rewrite next week, or a codebase you will maintain for years.
- how many people need to understand it: just you holding the whole thing in your head, or a team that has to share ownership over time.
Run the same diff through those three and “good review” means genuinely different things.
If you are working solo on a greenfield project with no users, review’s second job, distributing knowledge across a team, does not exist for you. You are the team.
The reasonable move is to lean hard on tests and automation, review the parts that genuinely matter, and accept a lighter touch on the rest. Duplication and churn cost far less when the code may not exist in a month and nobody is paged at 3am when it breaks. The catch, and people learn this one painfully, is that it only works if the tests are real. Skipping review without a safety net does not remove the work, it defers it at a higher price, and standards slip when no one is there to push back. No users is permission to defer review. It is not permission to skip verification.
Then the project gets users. This is the dangerous middle, and the crossing is rarely noticed at the time. Review's bug-catching role suddenly matters, because bugs now hurt people, and its knowledge-sharing role switches on, because it is no longer only you. Teams keep their solo-era habits a few months too long, and then there is a postmortem and the Faros numbers stop being a chart and become their own dashboard.
At the far end is the large organization with an old codebase and many users. Here every alarming figure lands at full strength. A change nobody understood is comprehension debt that becomes someone’s on-call incident. Review is doing several jobs at once, and the volume of agent output quietly breaks all of them. The Faros finding about mature teams is aimed squarely here.
So the point is not "enterprises should be cautious and solo developers can relax". It is that the purpose of review changes with your position, so the rules have to change with it. Bolt an enterprise’s locked-down, multi-agent, evidence-required pipeline onto a two-person prototype and you have added friction for no benefit. Run “tests pass, ship it” on a payments system and you have built an incident generator with a green checkmark on top. Most bad advice in this space is one position on that spectrum prescribing to another.
What review is actually for now
Review was built to check an author's reasoning and catch bugs + knowledge share with the team. An agent does reason, but that reasoning is usually thrown away rather than attached to the code, so the reviewer has to reconstruct a rationale that never made it into the diff. The good news: that is a tooling problem, and capturing the reasoning makes review dramatically easier.
This is the part that genuinely changed, and I think it is underappreciated.
When a human writes code, intent comes along for free. The reasoning, the alternatives weighed and discarded, lived in the author’s head, and review was you checking that reasoning. Modern agents do reason, often visibly, producing thinking traces and weighing options and explaining themselves as they go. The catch is that this reasoning is usually discarded the moment the diff is produced. It is rarely captured, rarely attached to the PR, and in any case it is the agent’s reasoning about how to implement the task, not a human’s judgment about whether it was the right task to begin with. So review shifts from checking reasoning that sits in front of you to reconstructing intent that never got written down, which is harder and slower, and we keep acting surprised that it takes 441% longer.
A 2026 paper, AI Slop and the Software Commons, analyzed 1,154 posts across 15 Reddit and Hacker News threads where developers discussed “AI slop”. One line from a developer caught my eye: reviewing an agent’s PR made them “the first human being to ever lay eyes on this code”.
That points straight at the fix. In normal review the author already understood the change and you were checking their work. With an agent PR, nobody has reconstructed the why yet. The reviewer is the first to try.
As the paper puts it, review “wasn’t built to recover missing intent”. The encouraging part is that missing intent is recoverable: the reasoning existed, we just discarded it. Have the agent state what it was trying to do and what it ruled out, capture that as a decision log on the PR, and a large part of the reconstruction cost disappears. This is a tooling problem, and tooling problems get solved.
None of which makes “have the AI review the AI” a complete answer on its own. A second model with different priors genuinely catches real bugs, and it catches a lot of them, which is why you should run one. What it does not supply is the human judgment about whether this is the right change to build in the first place. That judgment stays with a person, and it happens to be the most interesting part of the job, the part worth keeping.
The tools are good, but not always for the reason they advertise
The current AI reviewers are genuinely good, and they occasionally don’t flag the same lines as each other, so the right move is not picking the best one but running two that are built differently.
The dedicated AI review tools are good now, and I think you should be running at least your main coding agent if not a dedicated review agent on everything, side projects included.
CodeRabbit is the most widely deployed and topped the independent Martian benchmark (January to February 2026) on F1, around 49% precision with the best recall in the field. Greptile trades precision for recall: around an 82% bug-catch rate against CodeRabbit’s 44% in one benchmark, at the cost of more false positives. Anthropic’s Code Review reports under 1% of its findings marked incorrect by their engineers, and the figure I would actually show a manager: it raised their internal rate of PRs receiving a substantive review from 16% to 54%. The long tail of changes that used to get a glance and an approval now gets read by something.
The most useful result I have seen this year is not from a vendor. An engineer ran four reviewers in parallel, CodeRabbit, Sentry Seer, Greptile and Cursor BugBot, across 146 real PRs and 679 findings over three and a half weeks:
Of 617 distinct flagged locations, 93.4% were caught by exactly one of the four tools. 6% by two. Almost none by three. None at all by all four.
The four tools never once flagged the same line. Each was strong at a different class of problem: Greptile with near-zero false positives on correctness and architecture, CodeRabbit with the widest net and one-click fixes, Seer best on production-failure severity. That is the adversarial review argument demonstrated on a real codebase rather than in a paper. Heterogeneity is the whole point. Four copies of one model is a single reviewer with a larger invoice, whereas four genuinely different reviewers surface a set of bugs no single member could find alone, the human included.
In practice: do not agonize over the single best tool, there isn’t one. At the high-stakes end, run two with deliberately different characters (the experiment above paired Greptile for everyday correctness with Seer for production-failure severity, with almost no overlap). If you are solo, one good reviewer plus real tests is plenty. And whatever the marketing says, measure it on your own code, because every one of these results was specific to a particular codebase, and yours will be too.
Should we just let AI review more of it?
The machine is already reviewing more of your code than you are. The only real decision left is whether you do that deliberately, and the amount of human you keep should scale with your blast radius.
I keep hearing a question that would have been heresy a year ago, now from experienced engineers: should the machine be doing more of the reviewing, perhaps most of it? I no longer think that is a foolish question.
The uncomfortable part is that AI review works. Under 1% of Anthropic’s findings are marked wrong, the tools catch bugs humans read straight past, and they do not get tired on the thirtieth PR of the day, which is exactly when a human is least reliable. Meanwhile humans are visibly not keeping up: zero-review merges are up 31% and review times are up triple digits. In a real sense the machine is already reviewing more of the code than we are. The honest framing is not “should we let AI review more” but “AI is already doing it, are we going to be deliberate about that or let it happen by default while pretending humans still read everything”.
Loop engineering sharpens this. The premise of a loop is that you stop being the person who prompts the agent and instead build a system that prompts it, and a central part of that system is a judge: an agent that decides whether the work is done before moving on. The reviewer is the next role being designed out of the inner loop, on purpose. We spent a year automating the writing, and the loops are now automating the checking, and the human keeps getting pushed up and out. “Where does the human stay” is not a seminar question, it is something you decide every time you wire up a loop, whether or not you realize you are deciding it.
Where I currently land is: the answer may not be “a human reads every line”. That is over. But it is also not “let the loop review itself and walk away”. When an agent writes the code, another reviews it and a third judges it, you have a closed loop of models with broadly correlated blind spots, especially when they come from the same family, confidently agreeing in the same places. A confident “looks good” with no human anywhere in it is borrowed confidence: the system’s certainty becomes yours, and nobody actually understood anything. The loop can be both very sure and very wrong, with no human left to tell the difference.
So the human does not leave; the human moves up a level. You stop reviewing every diff and start owning the parts that do not transfer to a model. Accountability matters.
The judgment of whether this is even the right change to build, as distinct from whether the code is correct. The high-blast-radius gates where being wrong is expensive. And the awkward one: the behavior nobody specified, because a model reviews the code that exists and rarely flags the requirement that nobody thought to write down, which remains a human-shaped gap I do not expect to close soon.
Human in the loop becomes human on the loop: sampling, spot-checking and auditing the system rather than reading every PR, and spending your limited attention where being wrong would actually hurt.
This is already how I work on my own projects, including the open-source ones that now see more PRs in a day than I could carefully read in an evening.
I point Claude Code or Codex at a batch of incoming PRs and ask for a first pass: a high-level read of what looks safe to merge, what needs more work, and what is genuinely high-risk. I do not auto-merge on the result, and I do not lazy-merge whatever it approves. What it gives me is a way to allocate attention.
I can spend a few minutes confirming the changes it considers low-risk, and put real, careful time into the ones it flags as dangerous. The detail that matters is that this is not my old review hour made slightly faster. It is a different shape of hour, and at the volume I now deal with, it is the main reason the queue stays survivable at all.
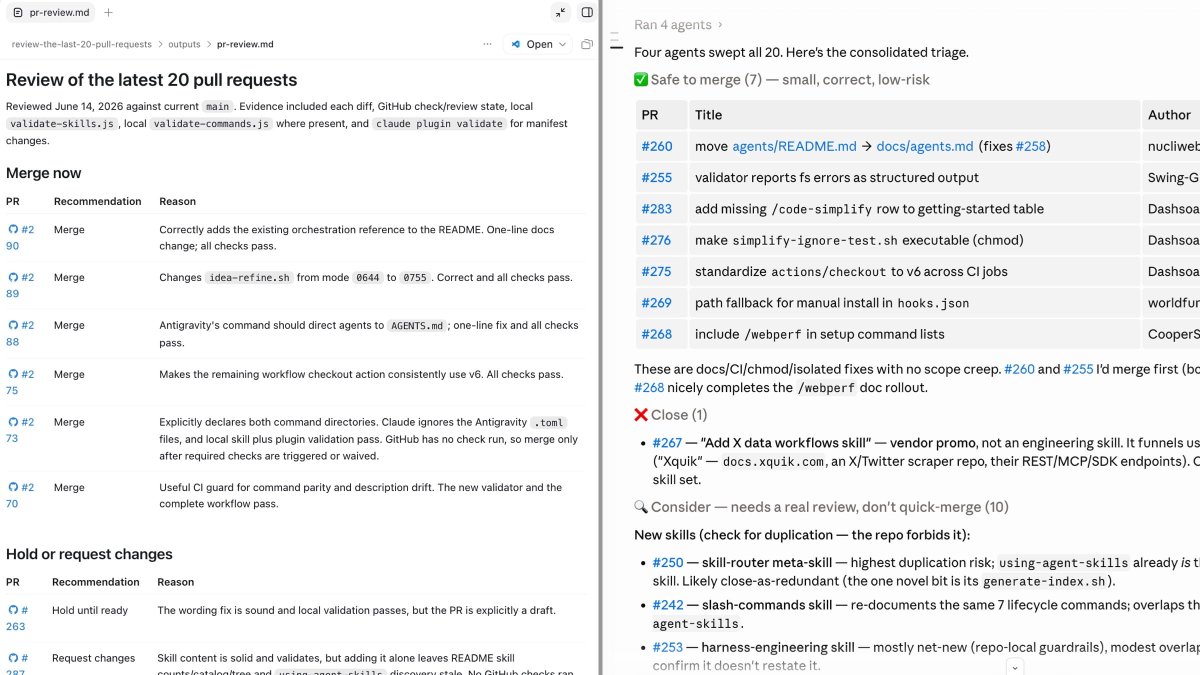
📷 Codex and Claude Code giving me a first-pass, risk-sorted read of a batch of PRs. The triage is the help. The merge decision stays mine.
A more extreme version of the same move is Kun Chen, an ex-Meta L8 engineer now shipping around 40 PRs a day as a solo builder, who has largely stopped reviewing code as told to @petergyang. It would be easy to dismiss this, except he is an L8, unusually good at the thing he stopped doing, which is what makes it interesting. He runs 20 to 30 agents in parallel and has moved his effort into the plan: he writes detailed plans up front, the agents run for hours against them, and he says plan quality determines how long they can run unattended. That is the move I described above. It is worth being precise about what actually happened, because it is not that he stopped verifying. The intent did not vanish, he wrote it down himself in the plan, so the “first human to ever lay eyes on this” problem is half-solved: a human did understand the why, just up front rather than after. And he did not work without a net, he built an automated review gate (he calls it No Mistakes) that checks the code before it merges, and he stays on escalation when an agent gets stuck. The human does the expensive thinking before the code exists and the machine does the line-by-line afterward, which may well be the shape of where this goes.
But he is a solo builder with no large team and no decade-old system full of landmines beneath him. The exact conditions that make 40 PRs a day without review rational for him are conditions most readers do not have. Copy his workflow onto a team shipping to many users and you reproduce the Faros numbers on your own dashboard. He is not wrong; he is a long way down one specific end of the spectrum.
Which is the spectrum point again. Solo with no users: letting AI review almost all of it is a defensible 2026 position, and you should not feel guilty about it. Maintaining something large for many people: let the machine handle the first pass, the second pass and the boring 90%, but keep a real human on the load-bearing paths and do not let the loop close completely on anything that can hurt someone. How much human you keep is a dial, and you set it by blast radius, not by guilt.
What to actually do
Stop reviewing everything to the same depth. Spend scarce human attention only where being wrong is costly, and let cheap deterministic gates and AI reviewers handle the rest.
The organizing idea is to match review effort to the cost of being wrong, push the cheap deterministic work as early as possible, and reserve human attention for what only humans can do.
Tier by risk, not by author. A config change earns a linter and a glance. A revision to your core business logic path earns the full stack: types, tests, two different AI reviewers, a human who owns that system, and a security pass. Do not spend a heavy review on boilerplate, and do not wave through a big change because the tests are green. The layered approach is the same everywhere; what changes is how many layers a given diff has to clear.
Fast-fail the expensive tail. The most useful recent finding for teams drowning in agent PRs is Early-Stage Prediction of Review Effort (January 2026), which studied 33,707 agent-authored PRs. Agents are good at small, well-defined changes, around 28% merge almost instantly, but they tend to “ghost” the moment they get subjective feedback, abandoning the back-and-forth that review actually is. (A companion 2026 paper found reviewer abandonment accounted for 38% of rejected agent PRs.) The researchers built a “circuit breaker” that predicts high-maintenance PRs from cheap signals like file types and patch size before a human looks, and it works well. Triage agent PRs up front, fast-track the trivial ones, and do not let a person sink an hour into a sprawling change the agent will abandon as soon as you push back.
Raise the bar for what you will even review. The fix for being buried is not locking down the repository, it is refusing to review changes that arrive without evidence. Require, before review: a statement of what the change is for, a diff that is not 3,500 lines with no comments, the test output, and proof it was actually run. This is how you stop being the first human to read the code. You push the intent-reconstruction work back onto whoever submitted it, where it is cheap, rather than absorbing it yourself, where it is expensive.
Keep PRs small, deliberately. Agent PRs run large, 51% larger on average in the Faros data, and reviewer engagement is one of the strongest predictors that a PR merges at all. A large unreviewable PR gets rejected outright or, worse, rubber-stamped. Instruct your agents to produce small commits. A diff a human can actually read is now a design constraint, not a courtesy.
Read the test changes more carefully than the code. This is the agent failure mode to watch. The agent changes behavior, then “fixes” the test by rewriting the assertion to match the new, broken behavior. A green check over 200 edited tests means nothing until you have confirmed the edits were correct. Treat any diff that rewrites many tests as a flag and read those first. Mutation testing earns its place here: coverage tells you a line ran, mutation testing tells you whether the test would notice if that line were wrong.
Treat CI as the wall that does not move. Watch for the patterns GitHub now warns reviewers about: removed tests, skipped lint, lowered coverage thresholds, a duplicated helper that already exists elsewhere, and untrusted input flowing into a prompt. That last one deserves emphasis, because agent-built features are a fresh source of prompt injection: if a change pipes user-controlled text into an LLM call without thinking about what that text can instruct the model to do, the vulnerability is not visible in the diff, it is latent in the data that will arrive later. Agents will also weaken CI to make themselves pass, not maliciously, just gradient descent finding the cheapest path to green. Deterministic gates are the one part of the pipeline that cannot be talked out of their verdict by a confident paragraph, so keep them strict.
A human owns the merge. A model cannot be paged and cannot be held responsible for what it shipped, so whoever clicks merge owns it. When an AI review says “looks good” in a calm, confident voice, it is handing you confidence it has not necessarily earned. Treat every AI review as a sensor, not a verdict: data, not a decision.
If you are solo with no users, the tiering, the test-change discipline and CI are most of what you need; the rest is overhead until people show up. If you are the large organization, all of it is the baseline, and the triage and intake bar are the difference between a review process that scales and one that quietly collapses.
What this means if you run a team
The bottleneck is no longer how fast you write code, it is how fast a trusted human can be confident in a review. Cutting the people who provide that confidence because “AI made us faster” simply converts the saving into future incidents.
The binding constraint on shipping is no longer how fast you can write code. It is how fast a trusted human can be confident a change is correct. Any plan that treats generation as the bottleneck and review as free will quietly stall, with the velocity dashboard staying green the whole way.
The Faros report is direct about this: QA and review work rises even as output rises, so reducing engineering headcount because “AI made us faster” is dangerous unless you have closed the review gap first. The senior-engineer tax, review time up by triple digits, falls hardest on the people you can least afford to bottleneck, and it is invisible to any metric that only counts merged PRs.
Open source maintainers hit this wall first and hardest. The steady stream of plausible but hollow contributions costs real triage time even when it is well-intentioned, and that is the canary. Companies are next. The ones handling it well treat review capacity as a real resource to be measured, protected and spent deliberately, not as slack that AI has freed up.
Writing got cheap, understanding didn’t
Code review did not become less important when agents arrived. It became the central activity. Writing code is increasingly solved and getting cheaper by the month; the durable advantage is the system that lets you trust what was written.
Do not take the one-size answer in either direction. If you are solo with no users, the enterprise horror stories about churn and duplication are a future risk, not today’s fire, so lean on your tests, review what matters, and stay honest that the deferred work is still owed. If you maintain something large for many people, every alarming number here is about you, and the only thing that holds is a tiered, evidence-required, deliberately heterogeneous review process with a human owning the merge.
What is constant across the whole spectrum is the underlying economics. We made writing cheap, and understanding stayed exactly as expensive as it has always been. The teams that do well over the next few years will not be the ones generating the most code, they will be the ones who built a review system they can actually trust, and who never confuse “the tests passed” with “a person understands what this does and why”.
Or, as @simonw keeps putting it, your job is to deliver code you have proven to work. Agents have not changed that. They have made the proving the center of the job rather than an afterthought, and I think that is a good trade.
Understanding a system well enough to stand behind it is the most durable and most interesting skill in software, and there has never been a better time to get extraordinarily good at it.
如今编码智能体(coding agent)已经强到出奇,而且进步飞快。一个有意思的后果是:工程里最难的部分,已经从「写代码」转移到了「判断该不该信任这些代码」——这让代码审查(code review)成了当下软件领域里杠杆率最高的一项技能。具体怎么做,极大地取决于你是谁:一个没有用户的独立开发者,和一支维护着十年老应用的团队,根本不是在解同一道题。
我对智能体化的(agentic)工程从未像现在这样乐观。这些智能体是真的好用,每个月都在进步,平平常常的一周里,我现在交付的东西放在一年前同样的时间根本不敢去碰。这篇文章是一张地图,标出有意思的工作都转移到了哪里——因为它确实在转移,而大多数团队还没完全跟上它转移到了哪儿。
代码审查过去之所以行得通,靠的是一个相对速度上的美好巧合。一位资深工程师读代码的速度,比一位初级工程师写代码的速度还快,于是审查自然能跟上节奏,没人专门去设计它;而整个团队对系统如何拼装在一起的理解,也是在互相读 diff 的过程中作为副产品吸收进来的。这里很多东西都不是刻意为之,它源自一个单一事实:写代码是慢的、昂贵的那一步,读代码则又便宜又快。
这个事实已经不成立了。一个智能体能在比我读完这一段还短的时间里,生成上千行往往相当扎实、格式漂亮的代码,而人类的阅读速度,从我们开始靠盯屏幕谋生的那天起,基本就没变过。于是约束点向下游移动,移到了那个没能加速的环节:一个人要有把握说这次改动是对的。我不认为这是一种损失。它是当下软件领域里最值得把本事练好的位置,也是我今年把大部分注意力投进去的地方。
这里有一个美好的反转,它定义了本文余下的内容。那些生成出所有这些额外代码的工具,恰恰也是我手上用来跟上这些代码的最佳手段。在我自己的项目上——包括那些热门的开源项目——我现在会把 Claude Code 或 Codex 对准一批新到的 PR,让它们替我对队列做分诊(triage),这实实在在地改变了我花时间的方式。所以这不是一篇反 AI 的文章,我后面会确切讲讲我是怎么用它的。
它也不是一份数据堆砌,更不是又一轮关于「让模型替你写代码到底是好事还是手艺之死」的争论,因为那种框架根本没用。能在真实代码库面前站得住的唯一答案是:这完全取决于你是谁。一个 vibe-coding 着十来个人才会跑的业余项目的开发者,和一支要让某套十年老企业系统再多撑一个季度的团队,几乎没有任何一条值得一提的约束是共享的;而流传的大多数建议,其实都是这两种人中的一个,在教另一个该怎么活。
2026 年的数据到底说明了什么
AI 带来的生产力提升是真实的,但原始产出会夸大它:代码量大约多了四倍,真正交付的价值却只多了一成左右。这两个数字之间的落差就是审查工作量,而这恰恰是为什么杠杆如今落在了审查上。
有那么两年,这只是轶事和论辩。如今它已经被大规模地测量出来——由一些没有共同议程、在好几个案例里甚至有竞争性商业利益的组织测出来——而这些测量一再指向同一个方向:AI 把产出大幅推高,同时把质量和可审查性双双推低。
Faros AI 对 4000 个团队里的 22000 名开发者做了埋点,追踪团队从低 AI 采用率走向高采用率时发生了什么。这是 2026 年 3 月的数据,差不多是本文里最新的了。好的一面是真实的,值得直白地讲出来:开发者合并的 PR 多了不少,完成的工作量更大,单个工程师的吞吐量在攀升。然后是报告余下的部分:
- 代码翻搅率(code churn)上升 861%
- 故障数与 PR 数的比例上升 242.7%
- 单个开发者的缺陷率从 9% 升到 54%
- 审查时长中位数上升 441.5%,首次审查耗时和平均审查耗时双双大致翻倍
- 零审查直接合并的 PR 上升 31.3%
最后这个数字是我最难轻描淡写带过的,因为没有任何人主动选了它。没人做出过「停止审查」的决定。审查者只是单纯跟不上量了,于是代码开始没人读就合并,而这成了常态。我一直回想的细节是:那些拥有成熟、自律工程实践的团队,受冲击的程度和其他所有人一样重。好流程并没有保护他们,因为量的到来比任何流程被设计去消化的速度都快。
有一条贯穿全文都要记住的提醒:CodeRabbit 和 Faros 都是往这个市场里卖东西的,所以他们的叙事并非中立。这不代表数字是错的——效应量很大,而且在彼此无关的来源之间高度一致——但厂商的研究值得带着这一点去读。
CodeRabbit 在 2025 年 12 月研究了 470 个开源 PR,其中 320 个由 AI 协作完成、150 个纯人工,发现 AI 的改动带有大约 1.7 倍多的问题:逻辑与正确性问题多了约 75%,安全问题常见程度高出 1.5 到 2 倍,可读性问题增加了三倍多。他们的 AI 总监 David Loker 把这些描述为「可预测、可测量、组织必须主动去缓解的弱点」。可预测是这里的关键词。这些是已知的、能定位的弱点,这是个好消息:它意味着一套审查流程——无论人工还是自动——可以径直瞄准它们。
GitClear 这里也有有意思的数据。在他们截至 2025 年的生产力数据中,每日使用 AI 的人产出的原始代码量大约是非用户的 4 倍,但对照他们自己一年前的产出,真正的生产力提升只有大约 12%。你生成着大约四倍的代码,换来的却只是约一成的交付价值,而人还得把这四倍的代码全部审一遍。GitClear 值得肯定的是,Bill Harding 明确指出,连这 12% 里都有一部分是选择偏差,因为更强的开发者集中在了 AI 这一组里。「四倍代码」和「多一成价值」之间的落差,就是审查问题用一句话讲清楚的版本。
GitHub 报告称,Copilot 审查至今已经跑了超过 6000 万次审查,不到一年增长了 10 倍,平台上每五次审查里就有超过一次涉及智能体。这不再是个小众做法。它就是代码被造出来的方式。
四份数据集,四种方法,一个结论。我们把机器速度的产出,倒进了一套为人类速度的工作而建的系统里。瓶颈没有消失,它移到了验证那一端,而审查正是这笔账到期要付的地方。
每个人解的都是不同的题
一次改动需要多少审查,几乎完全取决于它的影响半径(blast radius),而你读到的大多数建议,是某个处在截然不同影响半径上的人写的。
上面所有那些骇人的数据,几乎全来自企业的遥测,以及被淹没的开源维护者。如果那就是你的处境,它们千真万确。如果你是一个人在交付某个一小撮人才会跑的东西,那其中很多根本不适用于你,也不该有人让你觉得理应不安。
有三个变量决定你身处何处:
- 影响半径:它坏掉时会发生什么。什么都不会,或者是愤怒的用户、真金白银和 PII(个人身份信息)押在上面。
- 代码能活多久:一个下周可能就重写的一次性原型,还是一个你要维护好几年的代码库。
- 有多少人需要理解它:只有你一个人把整件事装在脑子里,还是一支必须随时间共担所有权的团队。
让同一个 diff 穿过这三条,「好的审查」就意味着真正不同的东西了。
如果你是在一个没有用户的全新(greenfield)项目上单干,审查的第二项职责——把知识分发到整个团队——对你而言根本不存在。你就是那个团队。
合理的做法是重重押注在测试与自动化上,审查那些真正要紧的部分,并对其余部分接受一种更轻的处理。当代码可能一个月后就不存在、坏掉时也没人会在凌晨三点被叫起来时,重复和翻搅的代价就低得多。其中的圈套——人们往往要痛过一次才学会——是它只有在测试是真的时候才管用。在没有安全网的情况下跳过审查,并不会让工作消失,它只是把工作延后、以更高的价钱欠下;而当没人在场推回去的时候,标准就会滑落。没有用户是允许你延后审查的许可,它不是允许你跳过验证的许可。
接着项目有了用户。这是危险的中段,而跨过它的那一刻往往当时没人察觉。审查抓 bug 的角色突然变得要紧,因为 bug 现在会伤到人;它分享知识的角色也被激活,因为不再只有你一个人了。团队们会把单干时代的习惯多保留几个月,然后就有了一份事故复盘报告,而 Faros 那些数字不再是一张图表,变成了他们自己的仪表盘。
光谱的最远端,是那个有着老代码库和众多用户的大型组织。在这里,每一个骇人的数字都以满格的力度砸下来。一次没人理解的改动,就是理解债(comprehension debt),它会变成某个人的待命事故。审查同时在干好几份活,而智能体产出的体量正悄悄把它们全部压垮。Faros 关于成熟团队的那个发现,瞄准的正是这里。
所以重点不是「企业应当谨慎,而独立开发者可以放松」。重点在于:审查的目的随你的位置而变,所以规则也必须随之而变。把一套企业级的、锁死的、多智能体、要求证据的流水线硬栓到一个两人原型上,你只是平添了摩擦却毫无收益。在一套支付系统上跑「测试通过,发吧」,你造出来的是一台事故生成器,顶上还盖了个绿色对勾。这个领域里大多数糟糕的建议,都是光谱上某一个位置,在给另一个位置开药方。
审查现在到底是为了什么
审查被造出来,是为了检验作者的推理、抓 bug,外加和团队分享知识。智能体确实会推理,但那份推理通常被丢掉,而不是附在代码上,于是审查者不得不重建一份从未进入 diff 的理由。好消息是:这是一个工具层面的问题,把推理捕获下来,能让审查变得轻松得多。
这是真正发生了变化的部分,而我认为它被低估了。
当一个人写代码时,意图是免费附赠的。那份推理、那些被掂量过又被丢弃的备选方案,都活在作者脑子里,而审查就是你去检验那份推理。现代智能体确实会推理,往往是可见地推理——产出思考轨迹、权衡选项、边走边解释自己。圈套在于,这份推理通常在 diff 产出的那一刻就被丢弃了。它很少被捕获、很少被附到 PR 上,而且无论如何,它是智能体关于「如何实现这个任务」的推理,不是一个人关于「这件事一开始是不是该做的事」的判断。于是审查从「检验摆在你面前的推理」,转成了「重建一份从未被写下来的意图」,这更难也更慢,而我们还一直对它要多花 441%的时间表示惊讶。
2026 年的一篇论文,《AI Slop and the Software Commons》(AI 垃圾代码与软件公地),分析了横跨 15 个 Reddit 和 Hacker News 帖子的 1154 条发言,开发者们在其中讨论「AI slop」(AI 拉的稀屎代码)。一位开发者的一句话戳中了我:审查一个智能体的 PR,让他成了「有史以来第一个亲眼看到这段代码的人类」。
这句话径直指向了解法。在正常的审查里,作者本就理解这次改动,你检验的是他的工作。而面对智能体的 PR,还没有任何人重建过那个「为什么」。审查者是第一个去尝试的。
正如那篇论文所说,审查「本就不是为了找回缺失的意图而造的」。令人振奋的部分是:缺失的意图是可以找回的——那份推理曾经存在,我们只是把它丢了。让智能体说清楚它当时想做什么、排除了什么,把这些作为一份决策日志捕获到 PR 上,重建成本的一大部分就消失了。这是一个工具层面的问题,而工具问题是会被解决的。
但这一切并不能让「让 AI 来审 AI」单凭自己就成为一个完整的答案。一个持有不同先验的第二模型,确实能抓到真实的 bug,而且能抓到很多,这正是你该跑一个的原因。它无法提供的,是关于「这一开始究竟是不是该建的那次改动」的人类判断。那份判断留在人这边,而它恰好是这份工作里最有意思的部分,是值得保留的那部分。
这些工具很好,但未必是因为它们宣传的那个理由
当下的 AI 审查工具是真的好,而它们偶尔标出的并不是彼此相同的那些行,所以正确的做法不是挑出最好的那一个,而是同时跑两个构造方式不同的。
如今这些专门的 AI 审查工具是好用的,而我认为你至少应该把你的主力编码智能体——如果不是一个专门的审查智能体的话——跑在一切东西上,业余项目也包括在内。
CodeRabbit 是部署最广的一个,并在独立的 Martian 基准测试(2026 年 1 月至 2 月)的 F1 分数上居首,精确率约 49%,召回率为同场最佳。Greptile 用精确率换召回率:在某次基准里抓 bug 率约 82%,对比 CodeRabbit 的 44%,代价是更多的误报(false positive)。Anthropic 的 Code Review 报告称,被他们工程师标为错误的发现不到 1%;而我真正会拿给经理看的那个数字是:它把内部「PR 获得实质性审查」的比例从 16% 提升到了 54%。那条过去只会被瞥一眼然后批准放行的长尾改动,如今终于有某个东西去读它了。
我今年见过的最有用的结果,不是来自任何厂商。一位工程师把四个审查工具并行跑了起来——CodeRabbit、Sentry Seer、Greptile 和 Cursor BugBot——在三周半里横跨 146 个真实 PR、679 条发现:
在 617 个不同的被标位置中,93.4% 恰好只被四个工具中的一个抓到。6% 被两个抓到。被三个同时抓到的几乎没有。被全部四个一起抓到的,一个都没有。
这四个工具一次都没有标出同一行。每一个都擅长一类不同的问题:Greptile 在正确性和架构上几乎零误报;CodeRabbit 网撒得最广、还能一键修复;Seer 在「生产环境故障严重性」上最强。这就是对抗式审查(adversarial review)的论点在一个真实代码库上、而非在一篇论文里被演示了出来。异质性才是全部的要点。同一个模型的四份拷贝,不过是一个审查者外加一张更大的账单;而四个真正不同的审查者,会浮现出一组任何单个成员独自都找不到的 bug——把人也算进去。
实践上:别为「那唯一最好的工具」纠结到痛苦,根本就没有那么一个。在高风险那一端,同时跑两个刻意性格不同的(上面那个实验把负责日常正确性的 Greptile 和负责生产故障严重性的 Seer 配在一起,二者几乎不重叠)。如果你是单干,一个好审查工具加上真实的测试就足够了。而无论营销怎么说,都拿你自己的代码去测它,因为上面这每一个结果都是针对某个特定代码库的,而你的也会是。
我们干脆让 AI 审查更多的代码?
机器已经在审查比你更多的代码了。唯一真正剩下的决定是:你要不要主动地这么做;而你保留多少人的成分,应当随你的影响半径而缩放。
我一直听到一个一年前还算异端的问题,如今从经验丰富的工程师口中说出:机器是不是该承担更多的审查,也许是大部分?我不再觉得这是个愚蠢的问题。
让人不舒服的地方是,AI 审查管用。Anthropic 的发现被标错的不到 1%,这些工具抓到的 bug 是人会径直读漏的,而且它们不会在当天第三十个 PR 上犯困——而那恰恰是人最不可靠的时刻。与此同时,人显然没能跟上:零审查合并上升了 31%,审查时间上升了三位数。从某种真实的意义上说,机器已经在审查比我们更多的代码了。诚实的框架不是「我们要不要让 AI 审查更多」,而是「AI 已经在这么干了,我们是要对此有意识地决断,还是任由它在默认状态下发生、同时假装人类仍然在读每一行」。
环路工程(loop engineering)把这一点磨得更锋利。一个环路的前提是:你不再是那个去提示(prompt)智能体的人,而是去搭一套提示它的系统,而那套系统的核心一环是一个裁判(judge)——一个在继续往下之前判断这份工作是否完成的智能体。审查者是下一个被有意地从内层环路里设计掉的角色。我们花了一年把写代码自动化掉,如今环路正在把检查也自动化掉,而人不断被向上、向外挤。「人留在哪里」不是一个研讨会上的问题,它是你每次接线搭一个环路时都在做的决定——无论你是否意识到自己正在决定它。
我目前落脚的地方是:答案也许不是「一个人去读每一行」。那已经过去了。但它也不是「让环路自己审查自己,然后甩手走人」。当一个智能体写代码、另一个审查它、第三个来裁判时,你得到的是一个由模型构成的闭环,它们有着大体相关的盲点——尤其当它们出自同一个模型家族时——会在同样的地方自信地彼此认同。一句自信的「看着不错」、里面任何地方都没有人,是一份借来的自信:系统的笃定变成了你的笃定,而实际上没有任何人理解了任何东西。这个环路可以既非常确信、又非常错误,而再没有一个人留在那里去分辨二者的区别。
所以人不会离场,人会上移一层。你不再审查每一个 diff,而开始拥有那些无法转交给模型的部分。问责是要紧的。
「这究竟是不是该建的那次改动」的判断——它和「代码是否正确」是两回事。那些「错了就很贵」的高影响半径关卡。还有那个尴尬的:没有任何人指定过的行为——因为模型审查的是已经存在的代码,却很少标出那个没有任何人想到要写下来的需求,而这仍是一道人形的缺口,我并不指望它很快会被合上。
human in the loop(人在环路之中)变成 human on the loop(人在环路之上):去采样、抽查、审计这套系统,而不是读每一个 PR,并把你有限的注意力花在「错了会真正造成伤害」的地方。
这已经是我在自己项目上的工作方式了,包括那些开源项目——它们现在一天里收到的 PR,比我一个晚上能仔细读完的还多。
我把 Claude Code 或 Codex 对准一批新到的 PR,要它做第一遍:高层次地读一读,哪些看起来可以安全合并,哪些需要再打磨,哪些是真正高风险的。我不会照着结果自动合并,也不会对它批准的东西就懒省事地合掉。它给我的,是一种分配注意力的方式。
我可以花几分钟确认它认为低风险的那些改动,把真正、仔细的时间投到它标为危险的那些上。要紧的细节是:这并不是我从前那个审查小时被稍微提速了的版本。它是形状不同的一个小时,而在我现在要处理的体量下,它是队列得以根本上还能撑得住的主要原因。
📷 Codex 和 Claude Code 给我对一批 PR 做的、按风险排序的第一遍速读。分诊就是帮助所在。合并的决定仍归我。
同一招更极端的版本,是 Kun Chen,一位前 Meta L8 工程师,如今作为独立开发者一天交付约 40 个 PR,并且基本上已经停止审查代码了——这是他向 @petergyang 讲述的。要把这事一笑置之很容易,只不过他是个 L8,在他停下来不做的那件事上格外擅长,这正是它有意思的地方。他并行跑着 20 到 30 个智能体,并把自己的力气挪进了计划(plan):他在前期写下详尽的计划,智能体顶着这些计划跑上数小时,而他说计划的质量决定了它们能在无人看管下跑多久。这正是我上面描述的那一招。值得精确地说清楚到底发生了什么,因为他并不是停止了验证。意图没有消失,他亲手把它写进了计划里,所以那个「有史以来第一个亲眼看到这段代码的人」的问题被解决了一半:确实有一个人理解了那个「为什么」,只不过是在前期、而非事后。而且他并没有不带安全网地工作,他搭了一个自动化的审查关卡(他管它叫 No Mistakes),在代码合并前检查它,而当某个智能体卡住时他会随时上场处理升级。人在代码存在之前做那昂贵的思考,机器在之后做逐行的活——这很可能就是这件事将来要走向的形状。
但他是一个没有大团队、底下也没有十年老系统里满地地雷的独立开发者。让「一天 40 个 PR 不审查」对他而言理性的那些确切条件,是大多数读者并不具备的。把他的工作流照搬到一支向众多用户交付的团队上,你就会在自己的仪表盘上复刻出 Faros 那些数字。他没有错;他只是在光谱的某个特定一端走出了很远。
这又回到了那个光谱上的位置。单干、没有用户:让 AI 审查掉几乎全部,是 2026 年一个站得住脚的立场,你不该为此感到愧疚。为众多人维护着某个庞大的东西:让机器去搞定第一遍、第二遍以及那无聊的 90%,但在那些承重路径上留一个真正的人,并且不要让环路在任何能伤到人的东西上完全闭合。你保留多少人,是一个旋钮,而你是按影响半径、而非按愧疚去拧它的。
到底该怎么做
别再对一切都审查到同样的深度。只把稀缺的人类注意力花在「错了代价很高」的地方,其余的交给便宜的确定性关卡和 AI 审查工具去处理。
组织原则是:让审查投入匹配「错了的代价」,把便宜的确定性工作尽可能早地往前推,并为只有人才能做的事保留人类注意力。
按风险分层,而不是按作者分层。一次配置改动配得上一个 linter 加一眼。一次对你核心业务逻辑路径的改动配得上整套:类型、测试、两个不同的 AI 审查工具、一个拥有那个系统的人,外加一遍安全检查。别在样板代码上花一次重型审查,也别因为测试是绿的就放行一次大改动。分层方法在哪里都是一样的;变的是某个给定的 diff 要清过多少层。
对昂贵的长尾快速失败(fast-fail)。给那些被智能体 PR 淹没的团队,近来最有用的发现是 《Early-Stage Prediction of Review Effort》(审查工作量的早期预测)(2026 年 1 月),它研究了 33707 个由智能体撰写的 PR。智能体擅长小而定义良好的改动,约 28% 几乎是即刻合并的;但它们一收到主观反馈就倾向于「玩消失」(ghost),抛下审查本就是的那种来来回回。(2026 年的一篇姊妹论文发现,审查者中途弃坑占了被拒智能体 PR 的 38%。)研究者们造了一个「熔断器」(circuit breaker),在人去看之前,就从文件类型、补丁大小这类便宜的信号里预测出「高维护成本」的 PR,而它效果很好。在前期就把智能体 PR 分诊,给琐碎的开快速通道,别让一个人在一个迟早会被智能体抛弃的、四处蔓延的改动上一推回去就陷进去一小时。
抬高你愿意去审查的门槛。被埋住的解法不是把仓库锁死,而是拒绝审查那些不带证据就到来的改动。在审查之前要求:一句话说明这次改动是为了什么;一个不是「3500 行、零注释」的 diff;测试输出;以及它确实被跑过的证据。这就是你不再做那个「第一个读代码的人」的办法。你把重建意图的工作推回给提交它的那个人——在那里它很便宜——而不是自己吸收下来,在那里它很昂贵。
刻意保持 PR 小。智能体的 PR 体量偏大,在 Faros 的数据里平均大 51%,而审查者的参与度是「一个 PR 究竟会不会被合并」的最强预测因子之一。一个庞大到没法审的 PR,要么被直接拒掉,要么——更糟——被橡皮图章式地盖章放行。指示你的智能体产出小提交。一个人真的能读完的 diff,如今是一条设计约束,而非一种客套。
读测试的改动,要比读代码本身更仔细。这是要盯紧的智能体失败模式。智能体改了行为,然后通过把断言重写成匹配那个新的、坏掉的行为来「修好」测试。盖在 200 个被改过的测试之上的一个绿色对勾,在你确认那些改动是正确的之前,什么都不意味着。把任何重写了大量测试的 diff 当成一个警示标志,并且先读它们。变异测试(mutation testing)在这里挣得了它的位置:覆盖率告诉你某一行被跑到了,变异测试告诉你「如果那一行是错的,测试会不会注意到」。
把 CI 当成那堵不会移动的墙。盯紧那些 GitHub 如今会警示审查者的模式:被删掉的测试、被跳过的 lint、被调低的覆盖率阈值、一个别处已经存在的被重复实现的辅助函数,以及流入提示词(prompt)的不可信输入。最后这一条值得强调,因为智能体造出来的功能是提示注入(prompt injection)的一个新鲜来源:如果一次改动把用户可控的文本灌进一个 LLM 调用里,却没去想那段文本能指示模型去做什么,那么这个漏洞在 diff 里是看不见的,它潜伏在将来才会到达的数据里。智能体还会去削弱 CI 好让自己通过——不是出于恶意,只是梯度下降找到了通往绿色的最便宜路径。确定性的关卡是流水线里唯一一个无法被一段自信的话术劝得改变裁决的部分,所以让它们保持严格。
一个人拥有合并这一步。一个模型没法被叫起来待命,也没法为它发出去的东西负责,所以无论是谁点了合并,谁就拥有它。当一个 AI 审查以平静、自信的语气说「看着不错」时,它递给你的是一份它未必挣得的自信。把每一次 AI 审查都当成一个传感器,而不是一个裁决:是数据,不是决定。
如果你是单干、没有用户,分层、测试改动的纪律和 CI 就是你需要的大部分;其余的在用户出现之前都是额外开销。如果你是那个大型组织,这一切全都是基线,而分诊和准入门槛,就是「一套能伸缩的审查流程」和「一套悄无声息地崩塌的审查流程」之间的区别。
如果你管着一支团队,这意味着什么
瓶颈不再是你写代码有多快,而是一个被信任的人能多快地对一次审查有把握。因为「AI 让我们更快了」就砍掉那些提供这份把握的人,只是把省下来的东西换算成了未来的事故。
交付的绑定约束(binding constraint)不再是你写代码能写多快。而是一个被信任的人能多快地确信一次改动是正确的。任何把生成当成瓶颈、把审查当成免费的计划,都会悄无声息地熄火,而那块速度仪表盘会全程保持绿色。
Faros 报告对此很直白:QA 和审查工作量随产出上升而上升,所以因为「AI 让我们更快了」就削减工程人手是危险的——除非你已经先把审查缺口给堵上。那笔资深工程师税——审查时间上升三位数——最沉地落在那些你最承受不起去卡住的人身上,而它对任何只数已合并 PR 的指标都是隐形的。
开源维护者最先、也最重地撞上了这堵墙。那一股股看似合理、内里空洞的贡献,即便是出于善意,也要花掉真实的分诊时间,而那就是矿井里的金丝雀(canary)。公司是下一个。那些处理得好的,把审查产能当成一种真实的、需要被测量、保护和有意花费的资源,而不是当成一份 AI 腾出来的余裕。
写代码变便宜了,理解却没有
智能体到来时,代码审查并没有变得不那么重要。它变成了核心活动。写代码正越来越被解决、并且每个月都更便宜;那个持久的优势,是那套让你能够信任「写出来的东西」的系统。
别在任一方向上接受那个「一刀切」的答案。如果你是单干、没有用户,那些关于翻搅和重复的企业级恐怖故事,是一种未来的风险,不是今天的火,所以靠你的测试、审查那些要紧的,并且诚实地承认:那些被延后的工作,仍然是欠下的。如果你为众多人维护着某个庞大的东西,这里每一个骇人的数字说的都是你,而唯一站得住的,是一套分层的、要求证据的、刻意异质的审查流程,外加一个拥有合并这一步的人。
横贯整个光谱始终不变的,是底层的经济学。我们让写代码变便宜了,而理解,仍然和它一直以来一样昂贵。未来几年里干得好的团队,不会是那些生成最多代码的,而会是那些搭起了一套自己真正能信任的审查系统的——并且从不把「测试通过了」和「有一个人理解这东西在做什么、为什么这么做」混为一谈。
或者,正如 @simonw 一直说的那样,你的工作是交付你已经证明能跑通的代码。智能体没有改变这一点。它们让「证明」成了这份工作的核心,而非一件事后才补的差事,我认为这是一笔划算的交易。
把一套系统理解到足以为它背书的程度,是软件里最持久、也最有意思的技能,而要把这件事练到出神入化,从来没有比现在更好的时机。