本周顶级 AI 论文
🥇Top AI Papers of the Week
1. MiniMax Sparse Attention
{kind=link}
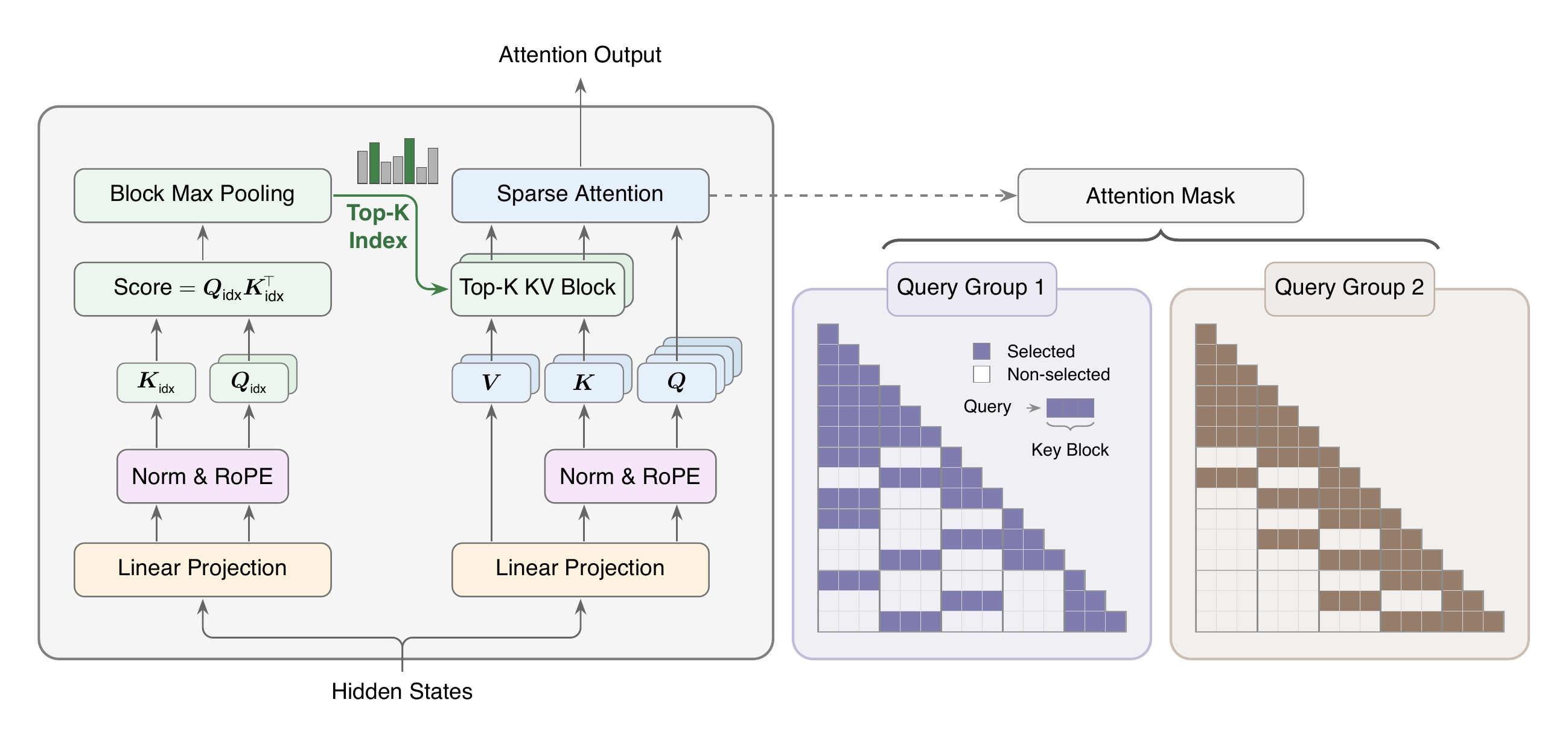
Ultra-long context is now a core requirement for agents, codebase-scale reasoning, multimodal workflows, and persistent memory, but dense softmax attention still makes million-token deployment expensive. MiniMax Sparse Attention (MSA) tackles this by adding blockwise sparsity on top of Grouped Query Attention, with a lightweight routing branch that chooses which key-value blocks each query group should actually attend to.
Two-branch attention design: The Index Branch scores the full causal context and selects Top-k key-value blocks independently for each GQA group, while the Main Branch performs exact sparse attention only over those selected blocks.
Hardware-aware implementation: The paper co-designs the sparse pattern with GPU kernels, using exp-free Top-k selection and KV-outer sparse attention to improve tensor-core utilization under block-granular access.
Large speedups at scale: On a 109B-parameter natively multimodal model, MSA matches GQA performance while reducing per-token attention compute by 28.4x at 1M context. The paired kernel reaches 14.2x prefill and 7.6x decoding wall-clock speedups on H800.
Why it matters: Long context is only useful if it can be served cheaply. MSA is compelling because it keeps the mechanism simple, trains it directly into a production-scale model, open-sources the inference kernel, and powers the released MiniMax-M3 model.
Message from the Editor
{kind=link}
We just released 30 Days of Hermes Agent, a hands-on lab that teaches agent workflows in a real, interactive terminal. Across 30 short labs, you use Hermes Agent to turn a messy Personal Knowledge Vault into a working knowledge operations system with readable notes, searchable context, reusable templates, review workflows, task boards, safety rules, and handoff docs.
2. Self-Harness
{kind=link}
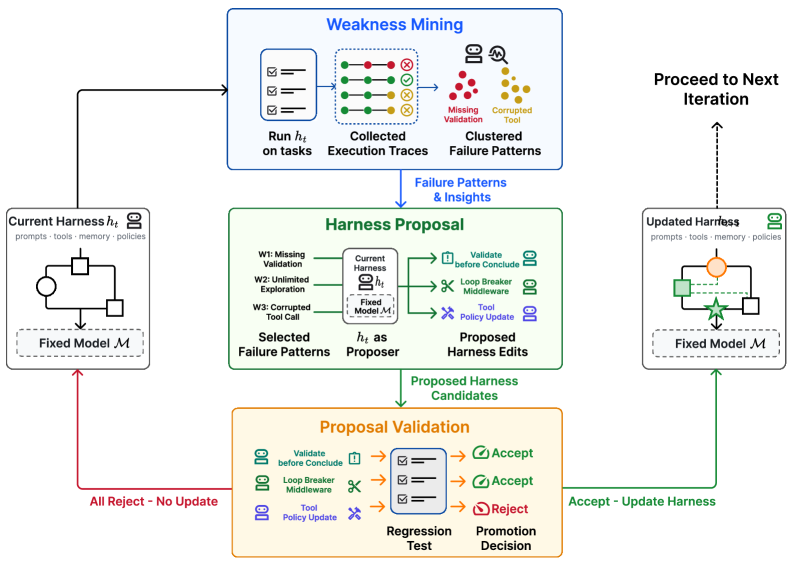
Most agent scaffolds are built once by hand and then frozen, even as the underlying models keep changing. This paper introduces Self-Harness, a paradigm where an LLM agent improves its own operating harness, the prompts, tools, memory, and orchestration around the base model, without human engineers or a stronger external agent. Because every model fails in its own way, the system mines those model-specific weaknesses and turns them into concrete, executable harness edits rather than generic advice.
A three-stage self-improvement loop: Self-Harness runs Weakness Mining, which clusters execution traces into model-specific failure patterns, then Harness Proposal, which generates diverse but minimal edits tied to those failures, then Proposal Validation, which accepts edits only after regression testing on held-in and held-out splits.
Consistent gains across base models: On Terminal-Bench-2.0, held-out pass rates rise for every model tested. MiniMax M2.5 improves from 40.5% to 61.9%, Qwen3.5-35B-A3B from 23.8% to 38.1%, and GLM-5 from 42.9% to 57.1%.
Weaknesses become edits: Rather than appending generic instructions, the loop converts each observed failure mode into a targeted change to memory, tools, or prompts, with reported relative improvements as high as 138%.
Why it matters: As models proliferate and evolve, hand-tuning a bespoke harness for each one does not scale. Self-Harness shows the scaffold itself can be made to adapt, closing the gap between a frozen harness and the model it wraps.
3. Agents’ Last Exam
{kind=link}
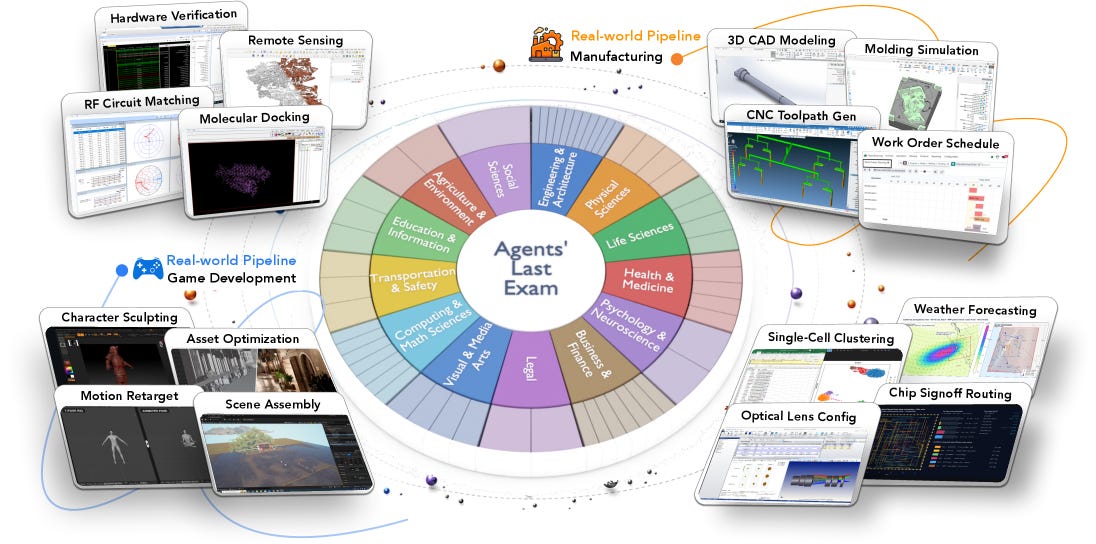
From Berkeley RDI, Agents’ Last Exam (ALE) is a living benchmark built to measure whether agents can do economically valuable work, not just score well on academic tests. It was assembled with more than 250 industry experts and maps over 1,000 verifiable tasks to the U.S. federal occupational taxonomy, organized as 55 subfields across 13 industry clusters. Every task has an objective, checkable outcome, so there is no subjective human grading, and the pool is designed to keep growing as new workflows are onboarded.
Grounded in real occupations: Tasks are defined against O*NET and SOC 2018 and span non-physical industries, deliberately targeting the professional workflows where agents would actually be deployed rather than puzzle-style problems.
Three difficulty tiers: Work is split into Near-Term, Full-Spectrum, and Last-Exam tiers, letting the benchmark track both near-term usefulness and the long tail of hard, multi-step jobs.
Far from saturated: The hardest tier sits at just a 2.6% average full pass rate across mainstream harnesses, and even strong setups like Codex with GPT-5.5 score below 50% on the easiest tier and under 10% on the hardest.
Why it matters: Strong scores on existing benchmarks have not translated into economically meaningful deployment. ALE reframes evaluation around verifiable, expert-curated work, giving a moving target that should resist saturation as agents improve.
4. How AI Agents Reshape Knowledge Work
{kind=link}
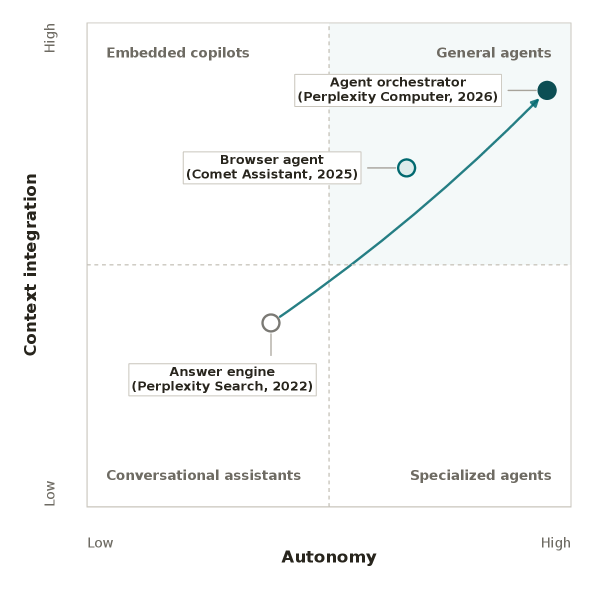
This economics paper, drawing on large-scale production data from Perplexity, studies how the shift from conversational assistants to autonomous agents is reshaping knowledge work. It compares Search, a conversational assistant, with Computer, a general-purpose agent system, along three dimensions: autonomy, efficiency, and the scope of tasks people take on. The framing is a cost-structure model in which agents carry higher fixed and delegation costs but lower per-step marginal costs, so they win once tasks are complex enough.
Autonomy looks different in practice: Computer performs around 26 minutes of autonomous machine work per session versus roughly 33 seconds for Search, and per-query dissatisfaction is 55% lower on the agent, 1.3% against 2.9%.
Large efficiency gains: On matched tasks, Computer cuts completion time from 269 to 36 minutes, an 87% reduction in time and about a 94% reduction in cost relative to humans working with Search alone.
Scope shifts upward: Agent queries are more cognitively complex, 71% abstract or non-routine versus 53%, with twice as much create-level work, and they bundle interdependent subtasks that cross occupational boundaries.
Why it matters: The data supports a clean prediction. As the fixed costs of delegation fall, agents move the affordable value frontier toward higher-value, multi-step knowledge work, which is exactly where adoption grew fastest, reaching 84 times its first-week volume over the study.
5. Agentopia
{kind=link}
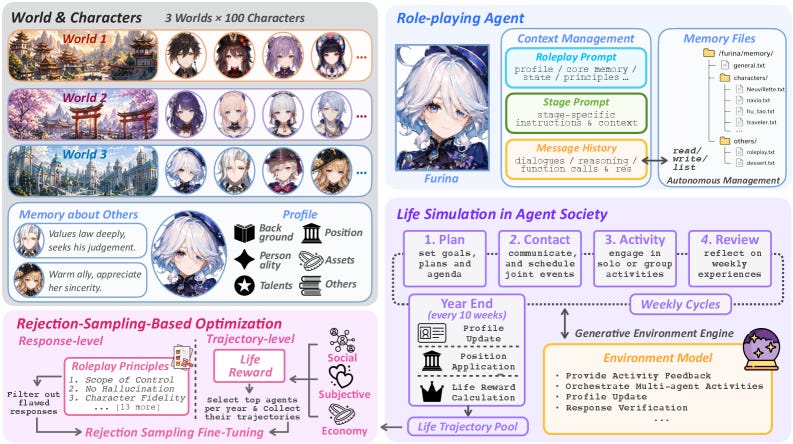
Agentopia is one of the most ambitious agent-society testbeds yet, a 79-page release that drops 100 LLM agents into a persistent world and lets them live, form relationships, and pursue goals over 10 simulated years, a horizon orders of magnitude longer than prior day-level work. Beyond observing emergent social behavior, the authors use the simulation as a training signal, optimizing models toward a life reward that reflects human well-being via rejection sampling.
Long-horizon by design: Where earlier agent societies ran at the granularity of days, Agentopia simulates a decade of life per world, surfacing unscripted social strategies and interpersonal dynamics that only appear over long timescales.
Simulation as a training signal: The life-reward metric is used to fine-tune more anthropomorphic models, and the improvements transfer beyond the simulation to downstream role-playing benchmarks rather than staying trapped in the sandbox.
Measured gains: Trained agents improve overall CoSER Test performance by 15.6%, with the biggest jumps in Anthropomorphism at 23.7% and Character Fidelity at 16.4%, and they are respected by 24.2% more peers and liked by 15.9% more.
Why it matters: A single 10-year, 100-agent run consumes 13.7 billion tokens across 567,000 LLM calls. That scale is a statement about where agent research is heading: living, learning populations as both an object of study and a source of training data.
6. The Geometry of On-Policy Distillation
{kind=link}
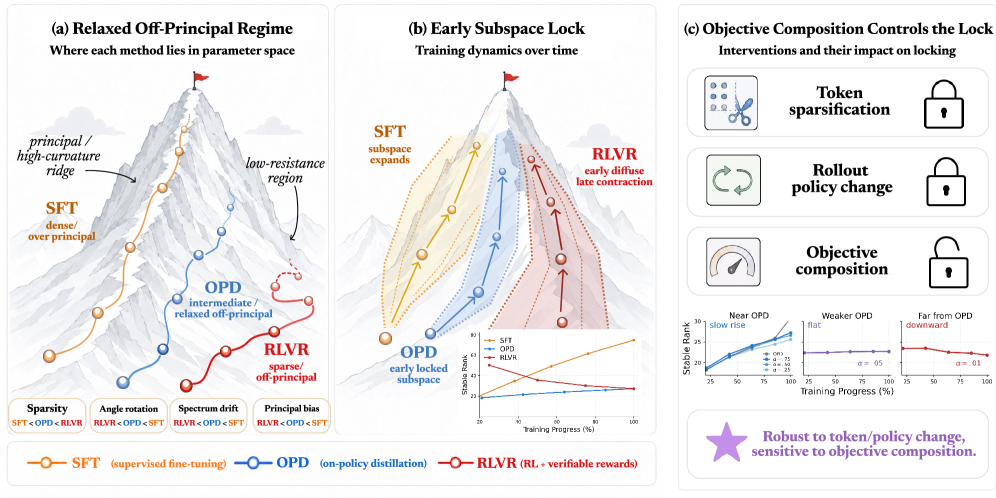
On-policy distillation (OPD) has become one of the most discussed post-training recipes of the year, but it has mostly been treated as a black box sitting somewhere between supervised fine-tuning and RL. This paper opens it up, characterizing how OPD changes a model’s weights at the level of parameter geometry, and argues OPD is not a midpoint between SFT and RLVR but its own distinct kind of update.
It touches fewer weights: Compared with SFT, OPD updates affect far fewer parameters and largely avoid the dominant principal directions of weight space, which helps explain its sample efficiency.
Early subspace locking: OPD’s cumulative updates rapidly collapse into a narrow, low-dimensional subspace early in training, rather than spreading across many directions as SFT does.
That subspace is functionally sufficient: Constraining training to the early-formed subspace preserves OPD performance but substantially degrades SFT, showing the small subspace genuinely carries the useful signal rather than being an artifact.
Why it matters: Knowing where in weight space OPD does its work turns a popular but poorly understood recipe into something with a mechanistic account. That makes the method easier to reason about, combine with other objectives, and improve deliberately instead of by trial and error.
7. Lookahead Sparse Attention
{kind=link}
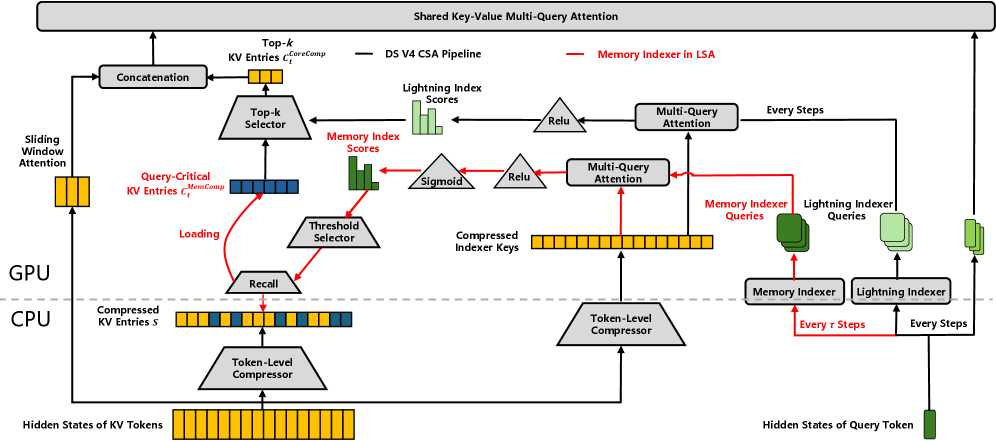
Long-context decoding is bottlenecked by the KV cache, which grows with every token and quickly dominates memory at extreme context lengths. This work, branded around DeepSeek-V4, introduces Lookahead Sparse Attention (LSA), which avoids storing the full KV cache by predicting which parts of the context future decoding will actually need and retaining only those query-critical chunks.
A learned, lightweight indexer: Instead of keeping everything, a small indexer proactively selects the KV chunks that matter for upcoming generation, so the physical cache stays small without discarding information the model will need.
Backbone-free training: A decoupled training strategy lets the indexer be trained on its own without loading the full backbone model, cutting the cost of adding the mechanism to a large model.
Big cache savings, no quality loss: LSA shrinks the physical KV cache to 13.5% of the full-context baseline while slightly improving accuracy by 0.6% on average, and at 500K-token contexts it suppresses more than 90% of KV-cache overhead without destabilizing reasoning.
Why it matters: Ultra-long context is increasingly the difference between a toy demo and a usable system, and memory is the wall. Predicting what context you will need, rather than keeping all of it, is a practical route to long context that fits in real hardware budgets.
8. Latent Spatial Memory
Video world models struggle to stay consistent over long horizons because explicit 3D memory usually requires an expensive pixel-space loop. Mirage instead stores scene information directly in diffusion latent space, using depth-guided back-projection and latent-space warping to maintain persistent spatial memory. The approach reports up to 10.57 times faster end-to-end generation and 55 times lower memory use than explicit 3D-memory baselines while improving long-horizon spatial consistency.
9. The Consistency Illusion
Multi-agent debate is often judged by whether the agents end up agreeing, but this paper shows that output-level consensus can hide deep disagreement in the reasoning that produced it. The authors abstract agents’ reasoning traces and decisions into four states along two axes, reasoning similarity and conclusion agreement, and flag divergent agreement, where agents reach the same answer through very different paths. Across 600 content-moderation items, divergent agreement appeared in 118 cases and separated cleanly from genuine disagreement states with a Cohen’s d of 0.80, and routing on these categories beat divergence-only methods at flagging high-disagreement cases.
10. Beyond Scalar Rewards
Reward models usually compress a judgment into a single scalar, but this paper argues human preferences are better captured as score distributions, and proposes Z-Reward, which internalizes reasoning into a predicted distribution before scoring. A large vision-language teacher does the reasoning-heavy judgment and is distilled into a compact student for efficient deployment, with the 27B teacher reaching 89.6% human-preference accuracy and the 9B student nearly matching it at 88.6%. Used as a reinforcement learning signal, it delivers a 41.3% net preference improvement over a supervised baseline, beating GRPO and other reward methods.
这篇还没有中文全文
该条目暂未提供中文翻译。标题/摘要已自动中译;本系统只对人工挑选的内容生成全文翻译。
挑中后 → markitdown 取正文 → 精翻 → 此处切换为译文