智能体编程与专业度的持续回报
Agentic coding and persistent returns to expertise
Key findings
Introduction
Agentic coding has taken off. The share of GitHub projects with coding agent activity has more than doubled since late 2025,1 and Claude Code users now spend an average of 20 hours per week using the tool.2 Can people without formal coding experience successfully direct an agent through complex technical work? And what will rapid adoption and improvement of these tools mean for knowledge work broadly? While we don’t have full answers to these questions yet, we look to Claude Code usage data for early signals.
This report provides evidence on how Claude Code is used in practice, based on a privacy-preserving analysis of ~400,000 interactive sessions from ~235,000 people between October 2025 and April 2026. It builds on prior work focused on measures of autonomy in Claude Code sessions, and how Claude Code is changing work at Anthropic.3 Here, we introduce a framework for describing interactive AI coding-assistant usage: what kind of work is being done, who is doing it, and whether it succeeds. We focus on Claude Code usage through a command-line interface (CLI), Claude.ai, or the Claude Code desktop app.4 By tracking how agentic coding usage changes as models get more capable, we can better understand how these tools affect the labor market for coding professionals and knowledge workers.
What happens on Claude Code may be a preview of where knowledge work is headed, as agents become embedded in non-coding work. We find that Claude is handling more complex and more valuable tasks. At the same time, there remains a clear division of labor in agentic coding: People decide what to build, and the agent decides how to build it.
We also see evidence that domain expertise, and not coding proficiency, amplifies effective use of the tool. In particular, domain experts succeed more often, and more easily recover from errors and misunderstandings. However, the gap between experts and intermediates is modest—suggesting that proficiency in a domain is enough to use the tool almost as effectively as those with deep mastery.
These findings give us an early read on possible transitions in the labor market. In our data, success is determined by how well a person understands the problem they are trying to solve, not whether they’re trained in coding. If these patterns hold across the economy, it suggests that while agentic coding tools may be absorbing some implementation-heavy work, they are also rewarding those with firm understanding of the problems they solve on the job. Coding agents are not substituting for domain expertise—the more understanding a worker brings to an agent, the more quality work the agent is able to do.
The division of labor
What people use Claude Code for
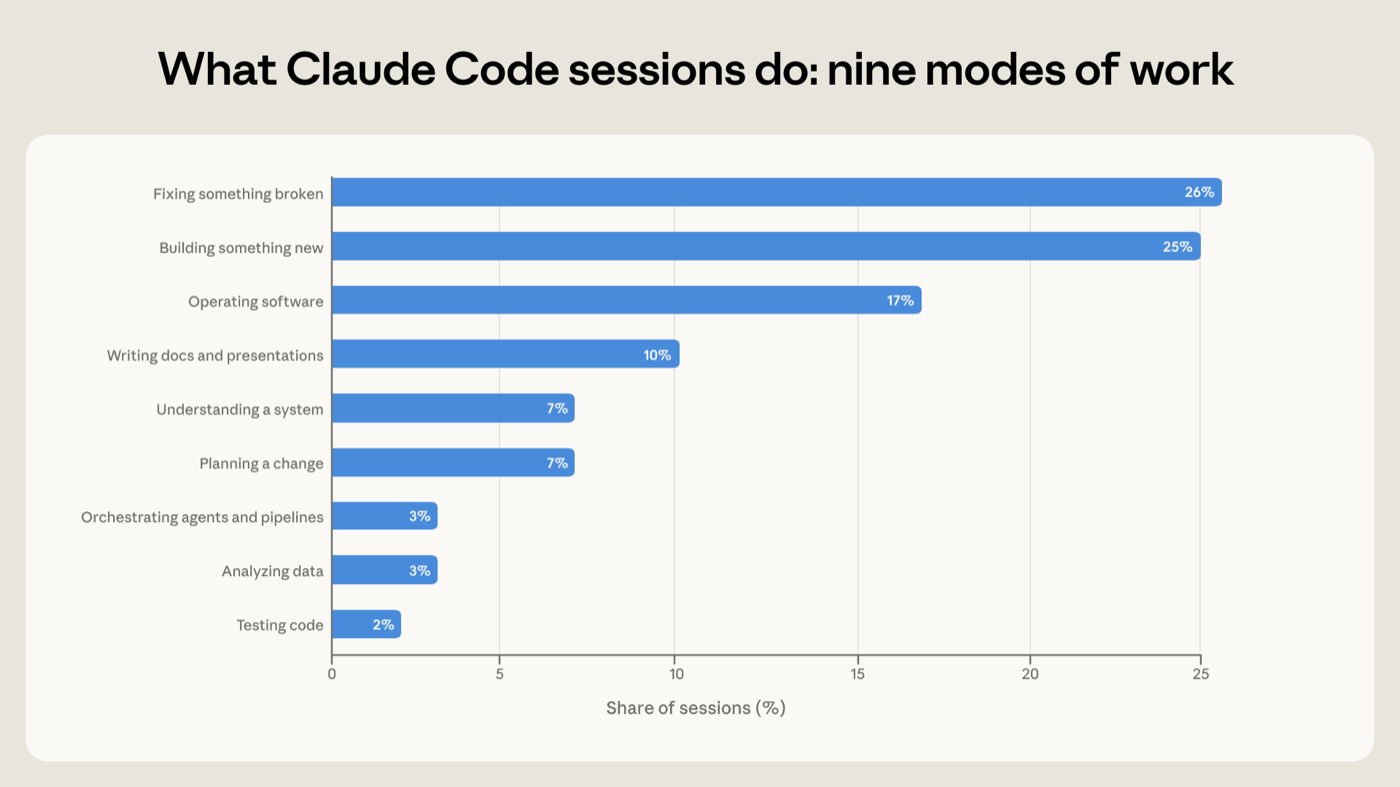
To understand what people are using Claude Code for, we classify each session into one of nine work modes—the single activity that best describes what the session is trying to accomplish.5 Four modes involve writing or maintaining code directly: building something new, fixing something broken, testing code, and orchestrating other agents or automated pipelines. Another category is operating software—deploying, configuring, running pipelines, monitoring systems. Two categories are more about working out what to do: understanding how an existing system works, and planning a change before making it. And two take actions unrelated to code, or where code is incidental to the final product: analyzing data, and communicating via presentations and other prose-based documents.
About 56% of sessions consist of writing (25%), fixing (26%), or testing and orchestrating code (5%). Operating software comprises 17%, while 14% of sessions are planning or exploring, and 13% produce analysis or prose (Figure 1).
We classify each session by having a model read its transcript, then using our privacy-preserving analysis tool, we check them against telemetry that's recorded automatically for every session, including whether any lines of code were added or deleted. The two sources have high agreement—for instance, more than 90% of sessions our classifier labeled as creating or modifying code showed code changes in the telemetry. See the Appendix for details.
Who decides what
How autonomous is Claude Code? Capability evaluations suggest the ceiling is high and rising: on benchmarks such as METR's time-horizon evaluations, frontier models can now complete software tasks that would take a person hours, autonomously working through obstacles along the way. But what does usage actually look like in practice? Here, we look at how much steering is done by the person and by Claude in real sessions.
We investigate this question from two angles. First, we focus on the extent to which people are entrusting decisions to Claude, and second we look at how many actions they give to Claude. To understand the division of decision-making in a session, we build a privacy-preserving decision attribution classifier based on the content of a session. We ask a classifier to list all the meaningful decisions in a session. We separate these decisions into planning (what to do, which approach to take, what counts as done) and execution (which files to change, what code to write, what language to write in, which commands to run). The classifier then attributes each decision to Claude or to the user, giving every session two numbers: the user's share of planning decisions and the user's share of execution decisions.
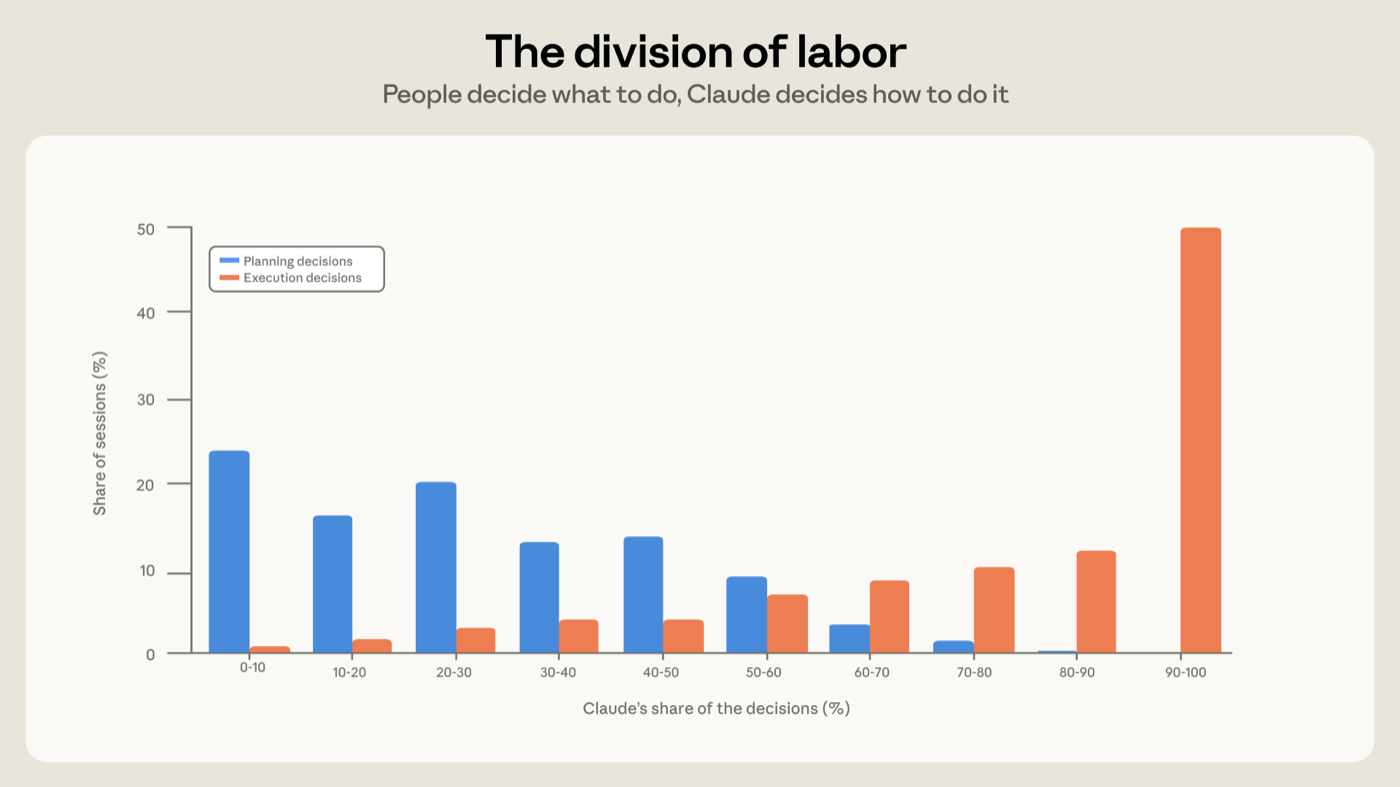
On average, people make about 70% of the planning decisions but only 20% of the execution decisions (Figure 2). In practice, there is a clear division of labor in agentic coding––people decide what to build, and the agent decides how to build it.
To understand the delegation of actions in a session, we look at the session’s structure instead of its content. A Claude Code session involves Claude and the user going back and forth trading prompts (from the user) and actions (taken by Claude)––the user writes a prompt and Claude goes off and does some work, and then the user writes another prompt, and so forth. In a typical session, there are about four such turns. In our historical data from October to April, each prompt the user sends sets off a chain of around 10 actions taken by Claude on average––and sometimes over 100.6 In each turn, Claude reads files, edits code, runs commands, and writes on average 2,400 words of output.
How much Claude does between check-ins largely tracks who is making the decisions. When the user keeps control of execution (i.e. makes over 80% of execution decisions), Claude takes fewer actions per turn (about eight actions). And when Claude takes control of planning (i.e. makes over 80% of planning decisions), it takes on the highest number of actions (about 16).
Level of expertise
From each transcript, Claude rates the user's apparent expertise at the task on a five-point scale from novice to expert. The expertise classifier looks for three signals: how precisely the user frames their directions, what they ask Claude to verify, and whether the user tends to correct Claude or Claude tends to correct the user. Note that expertise is capturing something quite different from job title or general ability, and, crucially, it is task-specific. A senior engineer asking their first Rust question is a beginner at Rust. An accountant who has never used Python, but tells Claude exactly which reconciliation rules a Python script must enforce and catches the edge case it mishandles at month-end close, is an expert at that task.
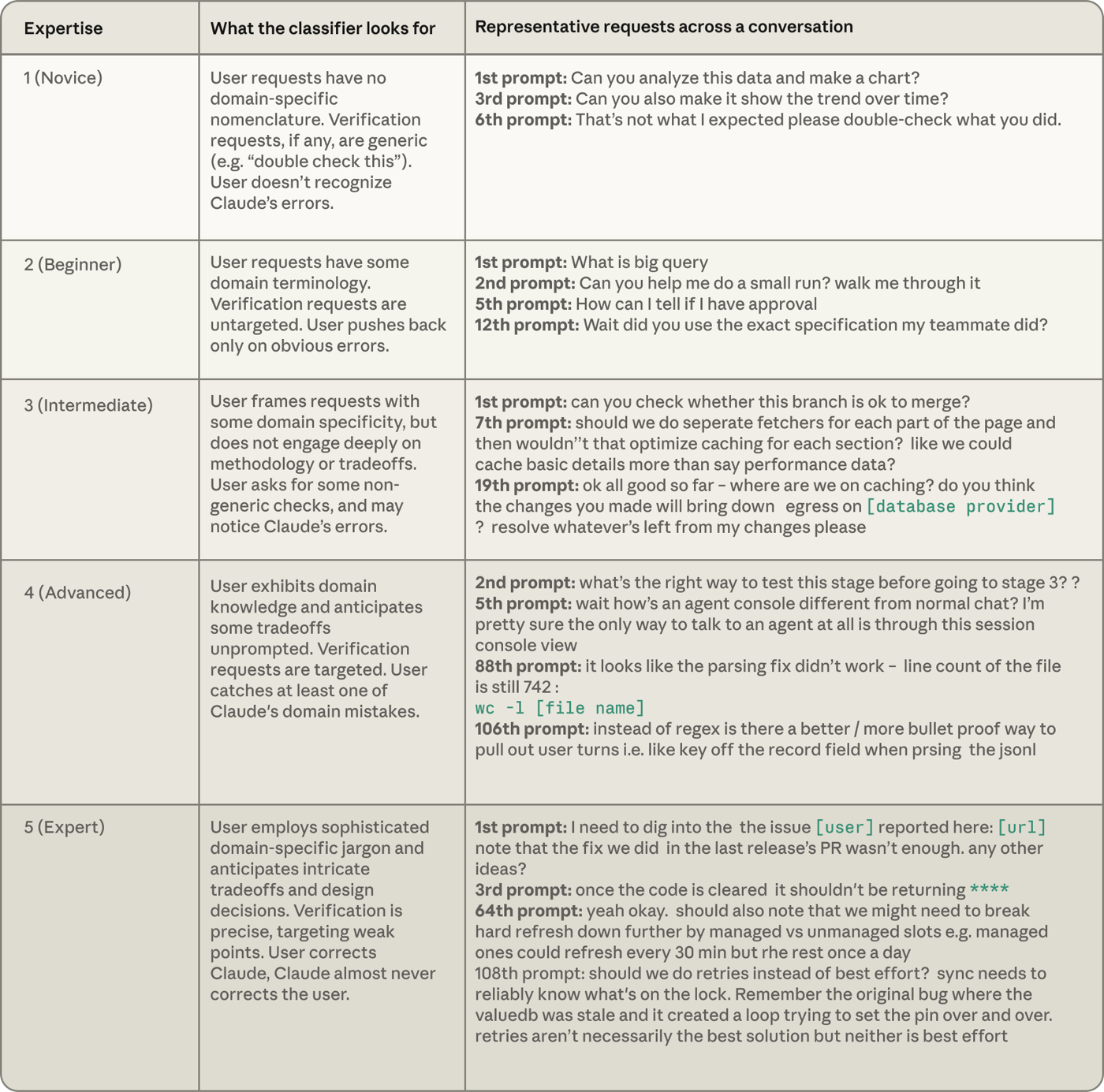
The table below shows how we defined each expertise level in the classifier along with an example request from a public dataset of coding agent sessions, SWE-chat. The conversation categorized as Novice gives generic instructions with no implied domain-specific knowledge. The Expert conversation conveys deep knowledge of the codebase and technical environment.
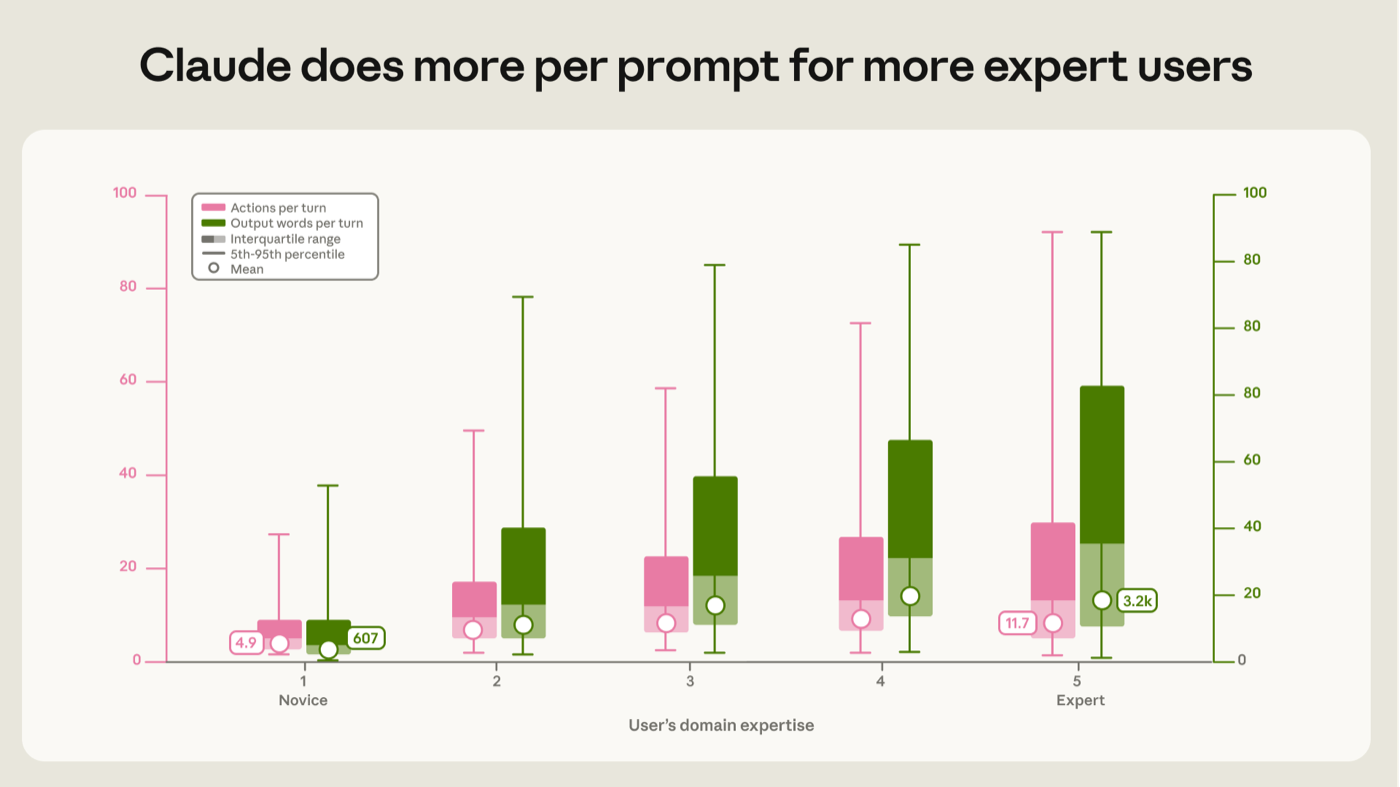
We quantify how expertise relates to Claude’s output and activity per prompt. In typical novice sessions, each prompt sets off about five Claude actions and roughly 600 words of output, while expert sessions set off action chains more than twice as long (12 actions) carrying five times the output (3,200 words) (Figure 3). This gap between novice and expert sessions appears within every kind of work and every band of task value.
These measures complement the autonomy measures in our prior report on Claude Code, which tracked how long the agent runs and how often people approve its actions automatically. Our decision attribution measure, by contrast, captures who makes the substantive decisions in a session as a whole, while our measures of output and actions per prompt measure how much autonomous activity from Claude each human prompt sets off.
Who uses Claude Code, and for what
The users
To understand who is doing this work, we infer each user's occupation from the session transcript, mapping it to one of 23 major groups in the Bureau of Labor Statistics’ Standard Occupational Classification (SOC) taxonomy. The classifier is instructed to rely only on signals such as the project context the agent loads at the start of a session, the names and structure of their files, any artifacts they reference (e.g., legal filings, clinical data, financial reports, a curriculum, etc.) and vocabulary they use.7 It is explicitly instructed not to treat the act of coding as evidence of a coding profession. A session is classified into the coding SOC code (Computer and Mathematical Occupations) only when there is clear signal that software or data work is the user’s job. A session in which a lawyer builds a script to automatically flag missing clauses across a folder of contracts is mapped into Legal Occupations, even if the session’s work is primarily software. The session is left unclassified when there is no signal about the user’s occupation.
We were able to infer occupation in about 70% of sessions. Within this set, Computer and Mathematical Occupations, a category which encompasses most software-related jobs, is unsurprisingly the largest group. The next largest are Business and Financial Operations; Arts, Design, and Media; Management; and Life, Physical, and Social Sciences. The fastest-growing non-software occupation groups in our sample are management, sales, and legal occupations.
The work
The composition of the work done with Claude Code changed substantially between October 2025 and April 2026. The clearest change is that the share of sessions spent fixing broken code fell from 33% to 19% (Figure 4). In its place, we saw a greater share of the work that surrounds code. Operating software grew from 14% to 21% of sessions. Writing and data analysis roughly doubled, from about 10% to 20% of sessions.
The tasks themselves also grew more valuable. We approximate each session's economic value by asking what the work would cost on a freelance marketplace, calibrated against a public dataset of real postings. By this measure, the estimated value of the average session rose by 27% between October and April. The rise holds across many kinds of work. Building, operating, and fixing-type tasks all grew more valuable by roughly a third or more (about 43%, 34%, and 32% respectively). These price estimates are coarse, so we use them primarily to compare tasks to one another over time, not as dollar values to be read literally.8 For details about the construction of the task estimator, see the Appendix.
Success depends on what the user brings
The estimated value of a task is one way to get a sense of how Claude Code is helping people do their work. Another angle is to look at how many sessions are successful, and what characteristics of a session are linked to success. Across all our measures of success, we see a clear pattern: the more expertise a person exhibits in a session, the higher the likelihood of success. Most of the gain is concentrated at the lower end of the expertise scale––the gap between novice sessions and intermediate sessions is bigger than the gap between intermediate and expert.
Before turning to the characteristics of successful sessions, we should be precise about how we measure success. We do not observe users’ real-world outcomes, and we cannot ask them directly whether they got what they wanted out of Claude. Instead, we rely on two complementary transcript-based measures. The first, judged success, comes from a classifier that reads the full transcript and decides whether the person succeeded in doing what they set out to do (with options: succeeded, partially succeeded, failed, no clear goal). Two companion classifiers then rate the strength of the evidence for that judgment to determine verified success. A success signal classifier looks for verifiable evidence of success. In particular, it looks for git activity like commits and pull requests matching the work, as well as test suites passing, and explicit affirmation from the user. It scores the session from "no signal" to “weak signal” (1) to "multiple hard signals” (5). A parallel failure signal scores the evidence that things went wrong—errors, failed tests, retries, the user pushing back on the output. Verified success requires both that the session is judged successful and there is at least one hard verifiable signal of success. For the following analysis, which is focused on the degree of success or failure in a session, we exclude sessions classified as having “no clear goal,” which comprise about 7.7% of our full sample.
The returns to expertise
So what kinds of sessions are most successful? It turns out that the expertise rating of a session, described above, matters a great deal for the success of a session.
One might worry that expertise isn't the real driver—perhaps experts simply pick different tasks, or differ in other ways. Throughout this section, we partially address this worry by comparing sessions doing the same kind of work, at the same estimated value, in the same month, on the same subject, from people in the same broad occupation group, and ask how outcomes differ by the person’s rated expertise.
Across all of our success measures, the more expertise a person exhibits in a session, the more likely it is that the session succeeds. A novice-rated session reaches our strictest measure, verified success, 15% of the time and at least partial success 77% of the time. A session rated intermediate or up reaches verified success 28-33% of the time and partial success 91-92% of the time (Figure 5).
In each measure, most of the gain comes from moving from novice to intermediate; between intermediate and expert, the slope decreases. In the Appendix, we give details about the regressions behind Figure 5.
A similar gradient appears in sessions that run into challenges along the way. We say a session hits trouble when the failure signal records verified evidence of failure. This could be an error, a failed test, multiple attempts to do the same thing, or the user expressing frustration or dissatisfaction. Among sessions that hit trouble, the share that are verified successes rises from 4% for novice-rated sessions to 15% for expert-rated ones, accounting for all the controls described above (Figure 5). Looking at the looser measures, we find that the share of at least partial success is 60% for novice and 80-81% for intermediate through expert sessions.
We also track the inverse relationship––expertise versus various measures of failure. Note that in this analysis, the sessions judged as failures are those that do not even partially succeed. We say a troubled session is abandoned if it is judged as failed and zero lines of code are written: 19% of sessions where the user appears to be a novice end abandoned, against 5-7% for everyone else. In other words, the least experienced users are more likely to give up when they are struggling to get the outcome they are after. Part of the value of expertise appears to be the ability to steer the agent in the right direction.9
Occupation may matter less than expertise
People in software-related occupations reach verified success in about 30% of their sessions overall, while users from other professions reach verified success about 26% of the time. Among sessions that produce code (i.e., sessions that add or modify at least one line of code), those numbers are 34% and 29% respectively (Figure 6). The gap between software-related occupations and other occupations narrows under our looser definition of success––with both groups reaching at least partial success in code-producing sessions 89% and 88% of the time, respectively. That five-point gap is small, and it has neither widened nor narrowed over seven months, even as the success rates in both groups increased. In code-producing sessions, every one of the ten largest occupations in our dataset lands within seven points of software engineers in terms of their success. Management occupations are highest on verified success, slightly above the software engineering occupations. Their higher verified success rates may reflect management skills that transfer to directing an agent. But they may also partly reflect our measurement: verification rests partially on explicit confirmation in the transcript, and managers may be more likely to communicate when they get what they ask for.10
Looking ahead
The results in this report offer an emerging picture of how agentic coding amplifies some forms of knowledge and skills, while substituting for others. In sessions that produce code, every major occupation succeeds at rates within a few points of those in software-related occupations. It appears that coding agents are making a coding background less relevant to successful programming.
At the same time, successful sessions are more likely to exhibit domain expertise. Sessions rated expert reach verified success more than twice as often as those rated novice, and when a session hits trouble, novices abandon the session at several times the rate of everyone else. The shape of the collaboration gives this picture more color—domain experts are able to direct Claude to do more work with each instruction they give. So, the ability to steer Claude toward success comes more from command of a domain than from the ability to write code. A person with such command, in any field, may now be able to do technical work they previously could not. A person without any such expertise will get far less from the same tool. And the gains come mostly from competence, not mastery––a working grasp of the domain captures most of the benefit, while deep specialization adds only a bit more beyond that.
These findings are preliminary. As in most of our research, we cannot measure real-world outcomes, like whether code written in a session is actually used or discarded thereafter, or whether it produces an economically valuable artifact. In addition, the non-interactive usage this report excludes is a substantial share of activity. Developing a framework to measure it is a priority for future work. And all of our classifications of sessions depend on a model's reading of the transcript. In the Appendix, we show that our classifiers track independent telemetry in expected directions, and agree with a strong reference model on the majority of sessions. But classifiers remain challenging to validate at scale, and Claude Code sessions add further difficulty, as they may be too long and complex for human labels to serve as ground truth.
The picture in this report will be updated as the models, the users, and the division of labor between them change. We hope that these measures will allow us to track consequential shifts as they happen. For instance, if the returns to expertise begin to decrease over time, that would suggest that models are starting to supply the essential judgment that users currently bring, and that the gains from these tools are broadening beyond domain experts. If the share of coding sessions completed successfully by users outside software occupations continues to grow, it could indicate that software production is becoming a part of ordinary work in every field, rather than the product of a single occupation. These shifts would change who benefits from agentic coding, and by how much, and would have implications for what is most valued in the labor market.
Appendix
Citation
Acknowledgements
With acknowledgements to: Jake Eaton, Sarah Pollack, Hanah Ho, Szymon Sacher, Anton Korinek, Santi Ruiz, Kerry Persen, Ankur Rathi, Alex Tamkin, Heather Whitney, Cat Wu, Kacie Jenkins, Jennifer Martinez, Amie Rotherham, Boris Cherny, Eleanor Dorfman, Miles McCain, and Jack Clark.
智能体编程与专业度的持续回报
原文:Agentic coding and persistent returns to expertise
2026 年 6 月 16 日
核心发现
- 在此前工作的基础上,我们提出了一个研究交互式智能体编程(agentic coding)的框架,它基于对 2025 年 10 月至 2026 年 4 月间约 40 万次 Claude Code session(一次完整的 Claude Code 使用会话)的隐私保护分析。我们考察了任务构成、人机协作以及成功率。
- 在一次典型的 session 中,规划决策(做什么)大多由人来做,执行决策(怎么做)大多由 Claude 来做。一个人为 session 带来的领域专业度(domain expertise)越高,Claude 每条指令所完成的工作就越多。在编码任务上,平均而言,每一个主要职业的成功率——即完成用户原本想做的事,并有诸如测试通过或代码已提交这类可验证的证据——都与软件工程师几乎相当。
- 一个人的领域专业度越高,session 以成功收尾的频率就越高——不过中级用户与专家用户之间的差距并不大。在我们观察的这七个月里,用于调试(debugging)的 session 份额下降了近一半,使用方式则转向更端到端的智能体用法:部署和运行代码、分析数据、撰写非代码类文档。
- 在这七个月里,我们通过与自由职业岗位招聘做对比来估计典型任务的价值,结果发现几乎每一类工作的价值都在上升——平均约 25%。
引言
智能体编程已经起飞。自 2025 年底以来,有编码智能体活动的 GitHub 项目份额翻了一倍多,¹ 而 Claude Code 用户现在平均每周使用该工具 20 小时。² 没有正式编程经验的人,能否成功地指挥一个智能体完成复杂的技术工作?这些工具的快速普及与改进,又会对广义的知识工作意味着什么?尽管我们尚无法对这些问题给出完整答案,但我们从 Claude Code 的使用数据中寻找早期信号。
本报告提供了关于 Claude Code 在实践中如何被使用的证据,依据是对 2025 年 10 月至 2026 年 4 月间约 23.5 万人产生的约 40 万次交互式 session 的隐私保护分析。它建立在此前工作之上,那些工作聚焦于 Claude Code session 中的自主性度量,以及 Claude Code 如何改变 Anthropic 的工作。³ 在这里,我们提出一个框架,用来描述交互式 AI 编程助手的使用:正在做什么样的工作、是谁在做、以及做成了没有。我们关注的是通过命令行界面(CLI)、Claude.ai 或 Claude Code 桌面应用进行的 Claude Code 使用。⁴ 通过追踪智能体编程的使用方式如何随模型能力增强而变化,我们能更好地理解这些工具如何影响编程从业者与知识工作者的劳动力市场。
随着智能体被嵌入到非编程工作中,Claude Code 上发生的事情或许预示着知识工作将走向何方。我们发现,Claude 正在处理更复杂、更有价值的任务。与此同时,智能体编程中始终存在一种清晰的分工:人决定要构建什么,智能体决定怎么构建。
我们还看到证据表明,放大这一工具有效使用的是领域专业度,而非编程熟练度。具体来说,领域专家更常获得成功,也更容易从错误和误解中恢复。然而,专家与中级用户之间的差距并不大——这意味着,对一个领域达到熟练程度,就足以把这个工具用得几乎和那些精通者一样有效。
这些发现让我们对劳动力市场可能发生的转变有了早期判断。在我们的数据中,决定成功与否的,是一个人对自己试图解决的问题理解得有多透彻,而不是他是否受过编程训练。如果这些模式在整个经济中普遍成立,那么它意味着:智能体编程工具在吸收一部分以实现为主的工作的同时,也在奖励那些对自己工作中所解决的问题有牢固理解的人。编程智能体并不替代领域专业度——一个工作者为智能体带来的理解越多,智能体所能完成的高质量工作就越多。
分工
人们用 Claude Code 做什么
为了理解人们在用 Claude Code 做什么,我们把每一次 session 归入九种工作模式之一——即最能描述这次 session 试图完成什么的那一项活动。⁵ 其中四种模式涉及直接编写或维护代码:*构建*新东西、*修复*坏掉的东西、*测试*代码,以及*编排*其他智能体或自动化流水线。另一类是*操作*软件——部署、配置、运行流水线、监控系统。还有两类更偏向于厘清要做什么:*理解*一个现有系统如何运作,以及在动手改之前先*规划*一次改动。最后两类则采取与代码无关、或代码只是最终产物附带产物的行动:*分析*数据,以及通过演示文稿和其他以文字为主的文档进行*沟通*。
约 56% 的 session 是在编写(25%)、修复(26%)、或测试与编排代码(5%)。操作软件占 17%,14% 的 session 在规划或探索,13% 产出分析或文字(图 1)。
 *图 1:九种工作模式。每一个交互式 session 被归入最能描述它试图完成什么的单一模式。*
*图 1:九种工作模式。每一个交互式 session 被归入最能描述它试图完成什么的单一模式。*
图 1:九种工作模式 每一个交互式 session 都被归入最能描述它试图完成什么的单一模式。
我们对每次 session 的分类方式是:先让一个模型读取它的 transcript(对话记录),再用我们的隐私保护分析工具,把它与每次 session 自动记录的遥测数据(telemetry,系统自动记录的运行数据)做核对,包括是否有任何代码行被增加或删除。两个来源高度一致——例如,被我们的分类器标记为创建或修改代码的 session 中,有超过 90% 在遥测数据里确实显示了代码变更。详情见附录。
谁来决定什么
Claude Code 有多自主?能力评测表明,其上限很高且仍在上升:在诸如 METR 的时间跨度评测这类基准上,前沿模型如今能够完成那些需要人花上数小时的软件任务,并能自主地一路扫清障碍。但实际使用究竟是什么样子?在这里,我们考察真实 session 中由人和由 Claude 各自做了多少把控。
我们从两个角度研究这个问题。第一,我们关注人们在多大程度上把*决策*托付给 Claude;第二,我们考察人们交给 Claude 多少*动作*。为了理解一次 session 中决策的分配,我们基于 session 内容构建了一个隐私保护的决策归因分类器。我们让分类器列出一次 session 中所有有意义的决策,再把这些决策分为规划(做什么、采取哪种方案、什么算完成)和执行(改哪些文件、写什么代码、用什么语言写、运行哪些命令)。分类器随后把每个决策归于 Claude 或用户,从而给每次 session 两个数字:用户在规划决策中所占的份额,以及用户在执行决策中所占的份额。
平均而言,人们做出约 70% 的规划决策,却只做出约 20% 的执行决策(图 2)。在实践中,智能体编程存在一种清晰的分工——人决定要构建什么,智能体决定怎么构建。
为了理解一次 session 中动作的委派,我们看的是 session 的结构而非内容。一次 Claude Code session 是 Claude 与用户来回交替的过程,双方交换 prompt(来自用户)和动作(由 Claude 执行)——用户写下一条 prompt,Claude 便去做一些工作,然后用户再写下一条 prompt,如此往复。在一次典型的 session 中,大约有四个这样的轮次(turn)。在我们 10 月到 4 月的历史数据中,用户发送的每一条 prompt 平均会触发 Claude 约 10 个动作组成的链条——有时超过 100 个。⁶ 在每一轮中,Claude 读取文件、编辑代码、运行命令,平均写下 2,400 个词的输出。
Claude 在两次检视之间做多少事,很大程度上取决于由谁来做决策。当用户保留对执行的把控(即做出超过 80% 的执行决策)时,Claude 每轮采取的动作较少(约 8 个)。而当 Claude 接管规划(即做出超过 80% 的规划决策)时,它采取的动作数最多(约 16 个)。
 *图 2:Claude 在规划决策和执行决策中所占的份额。各 session 中归于 Claude(而非用户)的规划决策(做什么)与执行决策(怎么做)份额的分布。在典型 session 中,用户做出约 70% 的规划决策,而 Claude 做出约 80% 的执行决策。*
*图 2:Claude 在规划决策和执行决策中所占的份额。各 session 中归于 Claude(而非用户)的规划决策(做什么)与执行决策(怎么做)份额的分布。在典型 session 中,用户做出约 70% 的规划决策,而 Claude 做出约 80% 的执行决策。*
图 2:Claude 在规划决策和执行决策中所占的份额 各 session 中归于 Claude(而非用户)的规划决策(做什么)与执行决策(怎么做)份额的分布。在典型 session 中,用户做出约 70% 的规划决策,而 Claude 做出约 80% 的执行决策。
专业度等级
针对每一份 transcript,Claude 会在一个从新手到专家的五分制量表上,给用户在该任务上表现出的专业度打分。专业度分类器寻找三种信号:用户把指示表述得有多精确、他们要求 Claude 去验证什么,以及到底是用户倾向于纠正 Claude、还是 Claude 倾向于纠正用户。需要注意的是,专业度所捕捉的,与职位头衔或一般能力相当不同,而且关键在于它是*任务专属*的。一位资深工程师在问自己的第一个 Rust 问题时,就是 Rust 的初学者。一位从未用过 Python 的会计,如果能准确告诉 Claude 一个 Python 脚本必须执行哪些对账规则,并在月末结账时抓出脚本处理错的边界情形,那么在那个任务上他就是专家。
下表展示了我们在分类器中如何定义每一个专业度等级,并附上一个取自公开编码智能体 session 数据集 SWE-chat 的请求示例。被归为「新手」的对话给出的是泛泛的指示,不含任何隐含的领域专属知识。「专家」的对话则传达出对代码库和技术环境的深入了解。
 *表 1:专业度分类器。这些示例对真实 session 做了改写、匿名化和压缩处理。表中使用的许多 session 来自一个公开的 agentic coding session 数据集 SWE-chat。*
*表 1:专业度分类器。这些示例对真实 session 做了改写、匿名化和压缩处理。表中使用的许多 session 来自一个公开的 agentic coding session 数据集 SWE-chat。*
表 1:专业度分类器 这些示例对由我们的分类器打标的真实 session 做了改写、匿名化和压缩处理。表中使用的许多 session 来自一个公开的智能体编程 session 数据集 SWE-chat。
我们量化了专业度与 Claude 每条 prompt 的输出和活动之间的关系。在典型的新手 session 中,每条 prompt 触发约 5 个 Claude 动作和约 600 个词的输出;而在专家 session 中,每条 prompt 触发的动作链条长一倍多(12 个动作),承载的输出是五倍(3,200 个词)(图 3)。新手与专家 session 之间的这一差距,在每一类工作和每一档任务价值中都会出现。
这些度量补充了我们在此前关于 Claude Code 的报告中提出的自主性度量,那份报告追踪的是智能体运行多久、以及人们多频繁地自动批准它的动作。相比之下,我们的决策归因度量捕捉的是在整次 session 里由谁做出了实质性决策;而我们对每条 prompt 的输出和动作的度量,衡量的则是每一条人类 prompt 触发了多少来自 Claude 的自主活动。
 *图 3:对越专业的用户,Claude 每条 prompt 做的事越多。对越专业的用户,Claude 在每条 prompt 上产生更多动作(左侧柱)和文本输出(右侧柱)。箱体覆盖四分位距(在中位数处分隔)。须线表示第 5 到第 95 百分位。白点是几何平均值。两条上升趋势都有统计显著性(p < 0.001),相邻等级之间的每一步亦然;在一个控制了工作模式、任务价值、月份、职业和模型家族(标准误按用户聚类)的回归中,它们依然显著(每提升一个专业度等级,动作数 +9%、输出 +13%)。*
*图 3:对越专业的用户,Claude 每条 prompt 做的事越多。对越专业的用户,Claude 在每条 prompt 上产生更多动作(左侧柱)和文本输出(右侧柱)。箱体覆盖四分位距(在中位数处分隔)。须线表示第 5 到第 95 百分位。白点是几何平均值。两条上升趋势都有统计显著性(p < 0.001),相邻等级之间的每一步亦然;在一个控制了工作模式、任务价值、月份、职业和模型家族(标准误按用户聚类)的回归中,它们依然显著(每提升一个专业度等级,动作数 +9%、输出 +13%)。*
图 3:对越专业的用户,Claude 每条 prompt 做的事越多 对越专业的用户,Claude 在每条 prompt 上产生更多动作(左侧柱)和文本输出(右侧柱)。箱体覆盖四分位距(在中位数处分隔)。须线表示第 5 到第 95 百分位。白点是几何平均值。两条上升趋势都有统计显著性(p < 0.001),相邻等级之间的每一步亦然;在一个控制了工作模式、任务价值、月份、职业和模型家族(标准误按用户聚类)的回归中,它们依然显著(每提升一个专业度等级,动作数 +9%、输出 +13%)。
谁在用 Claude Code,又用它做什么
用户
为了弄清是谁在做这些工作,我们从 session 的 transcript 推断每位用户的职业,并把它映射到美国劳工统计局的标准职业分类(SOC,Standard Occupational Classification,美国劳工统计局的职业分类体系)下 23 个主要群体之一。分类器被要求只依据这样一些信号:智能体在 session 开始时加载的项目上下文、用户文件的名称和结构、他们引用的任何制品(如法律文书、临床数据、财务报告、一份课程大纲等),以及他们使用的词汇。⁷ 它被明确要求*不*把编码这一行为本身当作从事编程职业的证据。只有当有清晰信号表明软件或数据工作是用户的本职时,一次 session 才会被归入编程 SOC 代码(计算机与数学类职业)。一位律师写脚本来自动标记一个合同文件夹中缺失的条款,即便这次 session 的工作主要是软件,也会被映射到法律类职业。当没有任何关于用户职业的信号时,这次 session 就不被归类。
我们能够在约 70% 的 session 中推断出职业。在这部分里,涵盖了大多数软件相关工作的「计算机与数学类职业」毫不意外是最大的群体。其次较大的是商业与金融运营;艺术、设计与媒体;管理;以及生命、自然与社会科学。在我们的样本中,增长最快的非软件职业群体是管理、销售和法律类职业。
工作内容
2025 年 10 月至 2026 年 4 月间,人们用 Claude Code 所做工作的构成发生了显著变化。最明显的变化是,用于修复坏掉代码的 session 份额从 33% 降到了 19%(图 4)。取而代之的,是围绕代码的那些工作占了更大份额。操作软件从 14% 增长到 21%。撰写文档和数据分析大致翻了一倍,从约 10% 增长到约 20%。
任务本身也变得更有价值。我们通过追问这份工作在自由职业市场上要花多少钱、并以一个真实岗位招聘的公开数据集做校准,来近似估计每次 session 的经济价值。按这一度量,10 月到 4 月间平均 session 的估计价值上升了 27%。这一上升在许多类工作中都成立。构建、操作和修复类任务的价值都增长了大约三分之一或更多(分别约为 43%、34% 和 32%)。这些价格估计较为粗糙,因此我们主要用它们来在时间上把各类任务相互比较,而不是把它们当作可以按字面解读的美元数额。⁸ 关于任务价值估计器的构建细节,见附录。
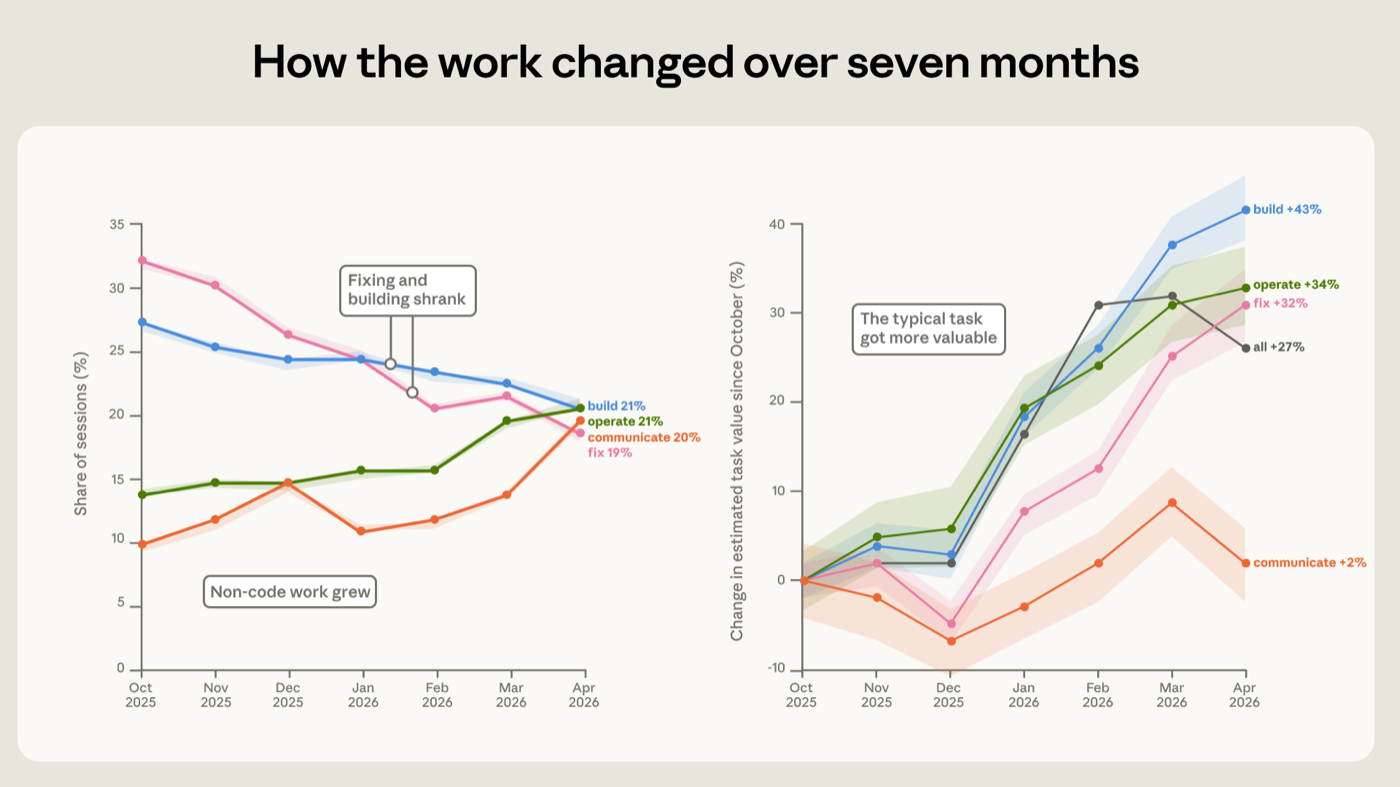 *图 4:Claude Code 工作的构成与价值,2025 年 10 月至 2026 年 4 月。在这七个月窗口内各工作模式所占 session 份额。修复损坏代码的 session 份额从 33% 降到 19%,而操作软件、分析数据、撰写文档的份额上升。*
*图 4:Claude Code 工作的构成与价值,2025 年 10 月至 2026 年 4 月。在这七个月窗口内各工作模式所占 session 份额。修复损坏代码的 session 份额从 33% 降到 19%,而操作软件、分析数据、撰写文档的份额上升。*
图 4:Claude Code 工作的构成与价值,2025 年 10 月至 2026 年 4 月 这七个月窗口内各工作模式所占的 session 份额。修复坏掉代码的 session 份额从 33% 降到 19%,而操作软件、分析数据和撰写文档的份额上升。
成功取决于用户带来了什么
任务的估计价值,是感知 Claude Code 如何帮助人们完成工作的一个角度。另一个角度,是看有多少 session 是成功的,以及一次 session 的哪些特征与成功相关联。在我们所有的成功度量上,都能看到一个清晰的模式:一个人在一次 session 中表现出的专业度越高,成功的可能性就越大。大部分增益集中在专业度量表的低端——新手 session 与中级 session 之间的差距,大于中级与专家之间的差距。
在讨论成功 session 的特征之前,我们应当先把如何度量成功讲清楚。我们观察不到用户在现实世界中的结果,也无法直接问他们是否从 Claude 那里得到了想要的东西。因此,我们依赖两个互补的、基于 transcript 的度量。第一个是*判定成功*(judged success),它来自一个分类器,该分类器读取完整 transcript,判定用户是否成功做成了他们原本想做的事(选项有:成功、部分成功、失败、无明确目标)。随后,两个配套分类器会评估支持该判定的证据强度,以确定*已验证成功*(verified success)。一个成功信号分类器寻找成功的可验证证据,尤其是寻找与该工作相匹配的 git 活动(如提交和拉取请求)、测试套件通过,以及用户的明确肯定。它给 session 打分,从「无信号」到「弱信号」(1)再到「多个硬信号」(5)。一个并行的失败信号则评估出错的证据——报错、测试失败、重试、用户对输出表示反对。「已验证成功」要求*同时*满足两点:这次 session 被判定为成功,且至少存在一个硬性的、可验证的成功信号。在接下来这部分专注于 session 成功或失败程度的分析中,我们剔除了被归为「无明确目标」的 session,它们约占全样本的 7.7%。
专业度的回报
那么,什么样的 session 最成功?事实证明,上文所述的 session 专业度评级,对一次 session 的成功与否影响极大。
有人可能担心,专业度并非真正的驱动因素——也许专家只是挑了不同的任务,或者在其他方面有所不同。在本节中,我们部分地回应了这种担忧:我们只比较那些做着同一类工作、估计价值相同、处于同一月份、围绕同一主题、且来自同一大类职业群体的人的 session,再追问结果如何随这个人被评定的专业度而变化。
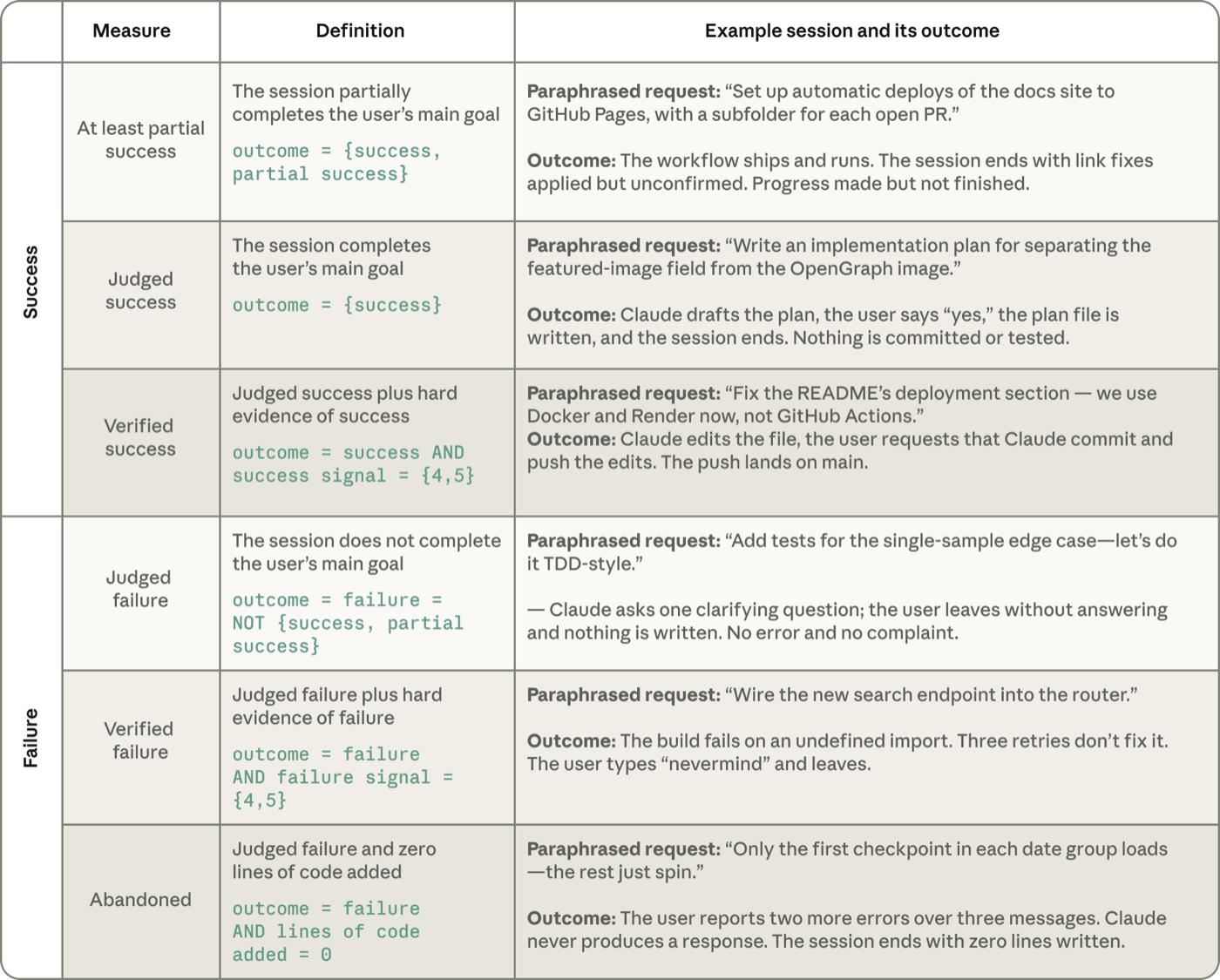 *表 2:由分类器导出的成功与失败定义。这些示例对来自一个公开 agentic coding 交互数据集 SWE-chat 的真实 session 做了改写和概括,并由我们的分类器打标。*
*表 2:由分类器导出的成功与失败定义。这些示例对来自一个公开 agentic coding 交互数据集 SWE-chat 的真实 session 做了改写和概括,并由我们的分类器打标。*
表 2:由分类器导出的成功与失败定义 这些示例对来自一个公开智能体编程交互数据集 SWE-chat、并由我们的分类器打标的真实 session 做了改写和概括。
在我们所有的成功度量上,一个人在 session 中表现出的专业度越高,这次 session 成功的可能性就越大。一次被评为新手的 session,达到我们最严格的度量——「已验证成功」——的比例为 15%,而达到至少部分成功的比例为 77%。一次被评为中级或更高的 session,达到「已验证成功」的比例为 28% 至 33%,达到部分成功的比例为 91% 至 92%(图 5)。
在每一项度量上,大部分增益都来自从新手迈向中级;而在中级与专家之间,斜率变缓。在附录中,我们给出了图 5 背后回归的细节。
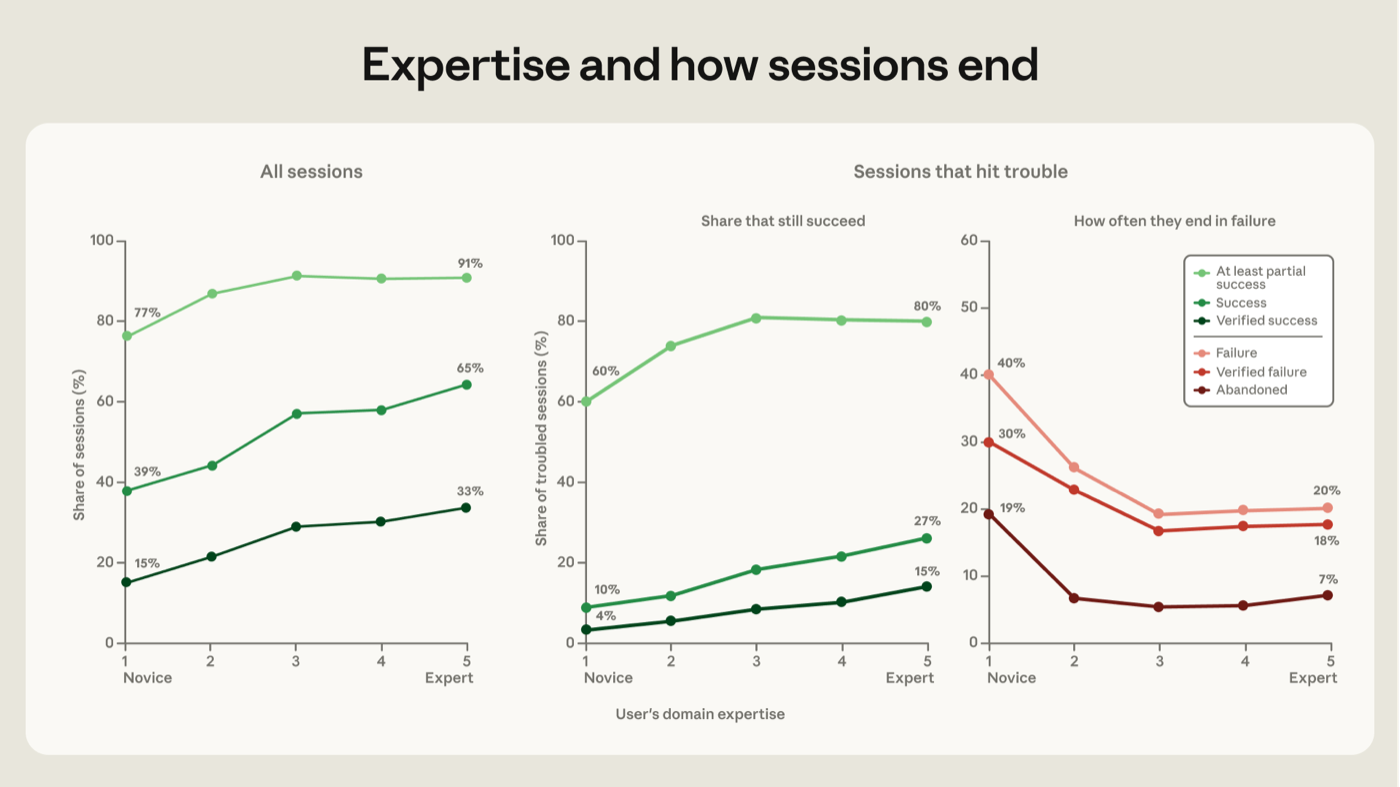 *图 5:专业度与 session 的收尾方式。按用户在该任务上被评定的专业度(从新手到专家的五分制)划分的 session 结果。左侧面板包含全部 session。中间和右侧面板限定在那些遇到麻烦的 session(失败信号 > 3),展示其中仍以各种成功/失败定义收尾的份额。每个点都是一个调整后的比率——我们仅通过比较那些共享相同工作模式、相同任务价值档、相同月份、相同任务主题、相同类型用户(与软件相关的职业与否)的 session,来估计各专业度等级之间的差异。这些点背后回归的细节见附录。须线是样本均值的置信区间(大多太小,在此图中看不出来)。这些图剔除了被成功结果分类器判定为"无明确目标"的 session。*
*图 5:专业度与 session 的收尾方式。按用户在该任务上被评定的专业度(从新手到专家的五分制)划分的 session 结果。左侧面板包含全部 session。中间和右侧面板限定在那些遇到麻烦的 session(失败信号 > 3),展示其中仍以各种成功/失败定义收尾的份额。每个点都是一个调整后的比率——我们仅通过比较那些共享相同工作模式、相同任务价值档、相同月份、相同任务主题、相同类型用户(与软件相关的职业与否)的 session,来估计各专业度等级之间的差异。这些点背后回归的细节见附录。须线是样本均值的置信区间(大多太小,在此图中看不出来)。这些图剔除了被成功结果分类器判定为"无明确目标"的 session。*
图 5:专业度与 session 的收尾方式 按用户在该任务上被评定的专业度(从新手到专家的五分制)划分的 session 结果。左侧面板包含全部 session。中间和右侧面板限定在那些遇到麻烦的 session(失败信号 > 3),展示其中仍以各种成功与失败定义收尾的份额。每个点都是一个调整后的比率——我们仅通过比较那些共享相同工作模式、相同任务价值档、相同月份、相同任务主题、相同类型用户(与软件相关的职业与否)的 session,来估计各专业度等级之间的差异。这些点背后回归的细节见附录。须线是样本均值的置信区间(大多太小,在此图中看不出来)。这些图剔除了被成功结果分类器判定为无明确目标的 session。
在那些一路上遇到挑战的 session 中,也出现了类似的梯度。当失败信号记录到经核实的失败证据时,我们称这次 session *遇到麻烦*。这可能是一个报错、一次测试失败、为做同一件事的多次尝试,或者用户表达出沮丧或不满。在遇到麻烦的 session 中,在计入上文所述全部控制变量后,「已验证成功」的份额从新手评级 session 的 4% 上升到专家评级 session 的 15%(图 5)。从更宽松的度量看,我们发现至少部分成功的份额,新手为 60%,中级至专家则为 80% 至 81%。
我们也追踪了相反的关系——专业度与各类失败度量之间的关系。注意,在这一分析中,被判定为失败的 session 是那些连部分成功都达不到的 session。如果一次遇到麻烦的 session 被判定为失败*且*没有写下任何代码行,我们就称它被*放弃*:在用户看上去像新手的 session 中,有 19% 以被放弃告终,而其他所有人这一比例为 5% 至 7%。换句话说,经验最少的用户在难以得到他们想要的结果时,更可能选择放弃。专业度的部分价值,似乎就在于能把智能体引向正确的方向。⁹
职业的重要性也许不及专业度
软件相关职业的人,总体上约有 30% 的 session 达到「已验证成功」,而来自其他职业的用户达到「已验证成功」的比例约为 26%。在产出代码的 session(即至少增加或修改了一行代码的 session)中,这两个数字分别为 34% 和 29%(图 6)。在我们更宽松的成功定义下,软件相关职业与其他职业之间的差距收窄了——两组在产出代码的 session 中达到至少部分成功的比例分别为 89% 和 88%。这 5 个百分点的差距很小,而且七个月里它既没有扩大也没有缩小,尽管两组的成功率都在上升。在产出代码的 session 中,我们数据集里最大的十个职业,其成功率全都落在与软件工程师相差七个百分点以内。管理类职业的「已验证成功」率最高,略高于软件工程类职业。他们更高的「已验证成功」率,或许反映了可迁移到指挥智能体上的管理技能。但这也可能部分反映了我们的度量方式:验证部分依赖于 transcript 中的明确确认,而管理者在得到自己所要的东西时,也许更可能把它说出来。¹⁰
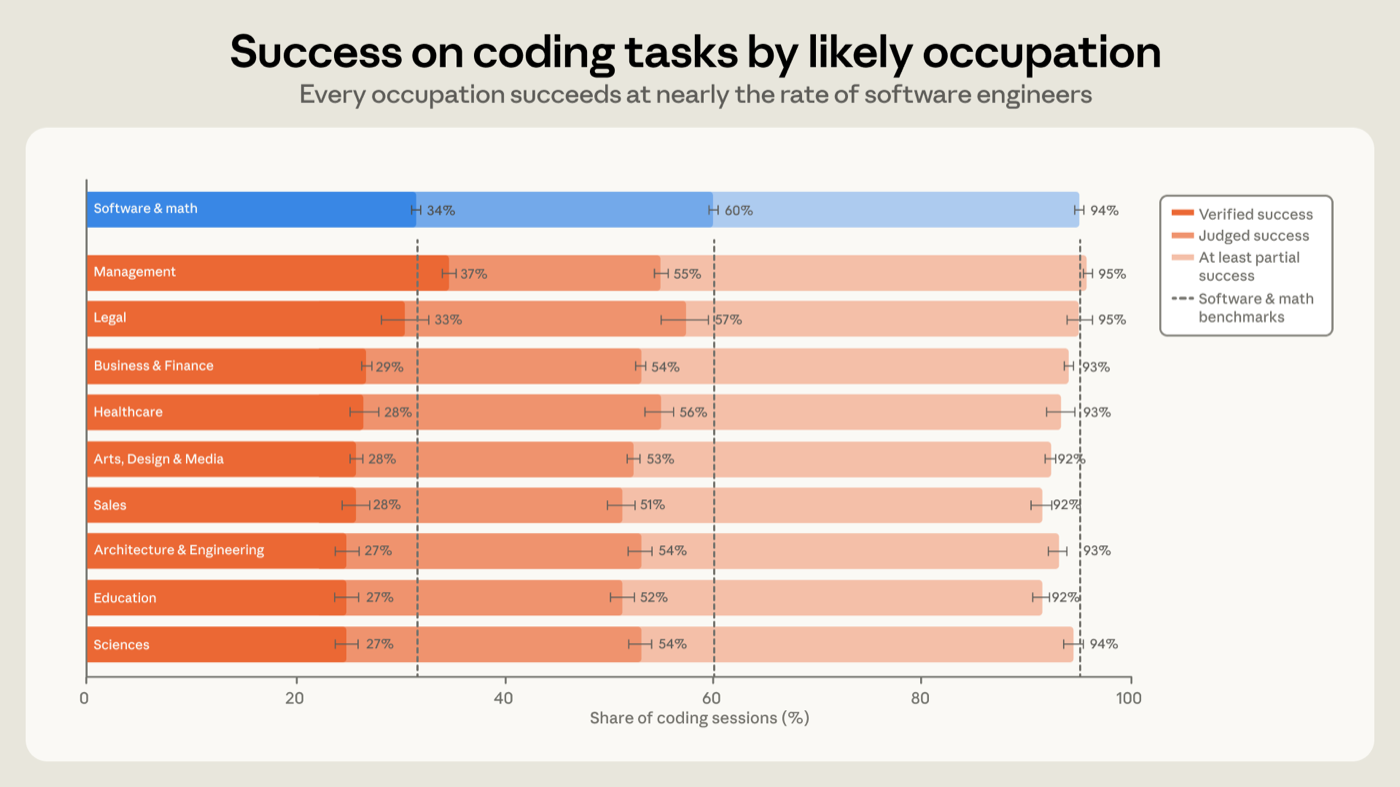 *图 6:按推断职业划分的编码 session 的"已验证成功率"与"判定成功率"。在添加或改动至少一行代码的 session 中,按用户被推断的职业群体(取最大的十个群体)划分、满足严格成功定义(判定成功与已验证成功)的 session 份额。每个群体都落在与软件/数学类用户(SOC 代码:计算机与数学类职业)相差七个百分点以内。误差线是按不同账户计算的 95% 置信区间。*
*图 6:按推断职业划分的编码 session 的"已验证成功率"与"判定成功率"。在添加或改动至少一行代码的 session 中,按用户被推断的职业群体(取最大的十个群体)划分、满足严格成功定义(判定成功与已验证成功)的 session 份额。每个群体都落在与软件/数学类用户(SOC 代码:计算机与数学类职业)相差七个百分点以内。误差线是按不同账户计算的 95% 置信区间。*
图 6:按推断职业划分的编码 session 的「已验证成功率」与「判定成功率」 在添加或改动至少一行代码的 session 中,按用户被推断的职业群体(取最大的十个群体)划分、满足严格成功定义(判定成功与已验证成功)的 session 份额。每个群体都落在与软件/数学类用户(SOC 代码:计算机与数学类职业)相差七个百分点以内。误差线是按不同账户计算的 95% 置信区间。
展望
本报告的结果勾勒出一幅正在浮现的图景:智能体编程在放大某些形式的知识和技能的同时,也在替代另一些。在产出代码的 session 中,每一个主要职业的成功率都与软件相关职业相差不过几个百分点。看起来,编程智能体正在让编程背景对成功编程而言变得不那么重要。
与此同时,成功的 session 更可能表现出领域专业度。被评为专家的 session 达到「已验证成功」的频率是被评为新手的两倍多;而当一次 session 遇到麻烦时,新手放弃 session 的比率是其他所有人的好几倍。协作的形态让这幅图景更有层次——领域专家能让 Claude 在他们给出的每一条指令上做更多工作。因此,把 Claude 引向成功的能力,更多来自对一个领域的掌控,而非写代码的能力。一个在任何领域具备这种掌控力的人,如今或许都能去做他此前做不了的技术工作。而一个不具备任何此类专业度的人,从同一个工具中得到的会少得多。并且这些收益大多来自胜任(competence),而非精通(mastery)——对一个领域有可用的把握就能拿下大部分好处,深度专精在此之上只多添一点点。
这些发现是初步的。和我们的大多数研究一样,我们无法度量现实世界的结果,比如一次 session 中写下的代码事后是被真正使用还是被丢弃,或者它是否产出了一件有经济价值的制品。此外,本报告所排除的非交互式使用,占了相当大一部分活动份额。开发一个框架来度量它,是未来工作的优先事项。而且我们对 session 的所有分类,都依赖于一个模型对 transcript 的阅读。在附录中,我们展示了我们的分类器在预期方向上与独立的遥测数据相吻合,并在大多数 session 上与一个强参照模型保持一致。但分类器在大规模上仍然难以验证,而 Claude Code session 又增添了进一步的难度,因为它们可能太长、太复杂,以至于人工标注无法充当 ground truth(真值基准)。
随着模型、用户、以及他们之间的分工发生变化,本报告所呈现的图景也会随之更新。我们希望这些度量能让我们在重大转变发生时及时追踪到它们。例如,如果专业度的回报随时间开始下降,那将意味着模型开始提供用户当前所带来的那种关键判断,意味着这些工具带来的收益正越过领域专家向更广人群扩散。如果由软件职业之外的用户成功完成的编码 session 份额持续增长,那可能表明软件生产正在变成每个领域日常工作的一部分,而不再是某个单一职业的产物。这些转变会改变谁从智能体编程中受益、以及受益多少,并对劳动力市场上什么最受重视产生影响。
附录
可在此处获取。
引用
@online{hitzig2026agentic,
author = {Zoe Hitzig and Maxim Massenkoff and Eva Lyubich and Shaoyi Zhang and Ryan Heller and Peter McCrory},
title = {Agentic coding and persistent returns to expertise},
date = {2026-06-16},
year = {2026},
url = {https://www.anthropic.com/research/claude-code-expertise},
}致谢
谨此致谢:Jake Eaton、Sarah Pollack、Hanah Ho、Szymon Sacher、Anton Korinek、Santi Ruiz、Kerry Persen、Ankur Rathi、Alex Tamkin、Heather Whitney、Cat Wu、Kacie Jenkins、Jennifer Martinez、Amie Rotherham、Boris Cherny、Eleanor Dorfman、Miles McCain,以及 Jack Clark。
脚注
- 第一项研究覆盖了 12.8 万个公开代码仓库,检测到截至 2025 年 10 月底,估计有 16% 至 23% 的项目存在编码智能体活动。一项后续研究使用相同方法,发现在那之后创建的项目中,采用率高出一倍多。对智能体编程活动的检测依赖于智能体的共同作者标记和配置文件,这很可能低估了实际使用量。
- 注意,这衡量的是 Claude Code 处于活跃运行状态的小时数,而非用户亲手向 Claude 打字的时间。
- 此外,Sarkar(2026)和 Baumann 等(2026)分别通过研究 Cursor IDE session 和公开可得的 session,提供了理解智能体编程的不同视角。
- 注意,我们排除了通过第三方集成开发环境和软件开发工具包运行的 Claude Code 使用。因此我们也排除了「headless(无头)」模式下的 session,即用户通过
claude -p "<prompt>"在 CLI 中运行单条 prompt 的情形。我们排除这类使用,是因为它在两个关键方面有所不同——其中很大一部分是程序化的,Claude Code 被嵌入到自动化工具和流水线中,而非与用户对话;而且即便有用户在场,我们也无法像在所纳入的那些界面上那样,端到端地看到用户的整次 session。 - 除非另有说明,本报告中所有分类器都使用 Claude Sonnet 4.6。关于分类器的细节,包括它们的完整原文和验证结果,可在附录中找到。
- 每条 prompt 的动作数有一条长尾。约 2% 的 session 平均每条 prompt 超过 100 个动作,约 270 次中有 1 次平均超过 200 个,约 2,300 次中有 1 次平均超过 500 个。
- 与本报告中的所有度量一样,这些推断都是用我们的隐私保护分析工具产生的。没有研究人员阅读单条 transcript,职业标签从不与可识别身份的用户关联,我们只观察跨越最少数量不同用户的聚合结果。
- 我们在此采取的估计方法,意在捕捉各次 session 价值的相对差异,而非绝对价值。其美元数额基于与自由职业市场(而非受薪工作)的比较,并来自 Claude Code session 与岗位招聘之间一种终究模糊的匹配。由于相对估计会消除这些问题带来的任何一致性偏差,我们更看重相对估计。
- 以「遇到麻烦」为条件,对不同用户筛选出的是不同的 session。专家总体上更少遇到麻烦,因此他们确实遇到的那些麻烦 session,很可能是在更难的问题上——以 session 的价格估计作为 session 复杂度的代理指标,我们看到麻烦 session 的平均估计价值,从专业度量表的底端到顶端大致翻了一倍。因此,恢复率上的部分差距也许反映出:新手卡在日常问题上,而专家卡在富有挑战的硬问题上。
- 即便模型对管理者做了误判,用来判定一个用户很可能是管理者所依据的那些信号——也许体现在任务如何被委派和界定上——往往与更高的成功率相关联。换句话说,也许表现得像个管理者本身就带来更高的成功率。