这位前 Meta L8 工程师为何不再逐行审查自己的代码
Why this ex-Meta L8 engineer stopped reviewing his own code

这条视频还没有中文字幕
该条目暂未提供中文字幕。本系统只对人工挑选的内容生成翻译。
挑中后 → 取 YouTube 字幕 → 精翻 → 此处切换为双语字幕
前 Meta 首席工程师陈坤:我一天发 40 个 PR,但从不逐行审代码
2026 年 6 月初,主持人彼得·杨(Peter Yang)在自己的播客《Behind the Craft》里请来一位老朋友——陈坤(Kun Chen),前 Meta、微软、Atlassian 的 L8 首席工程师,如今从大厂离职、一个人在家做独立开发者。彼得说自己"问了他一大堆关于这套打法的蠢问题",所以这期干脆让他打开终端、现场演示一遍:他到底怎么用智能体(agent)一天产出几十个合并请求(PR)。
这期节目落在一个微妙的时间点上。就在两周前,做出 SWE-bench 的同一拨人扔出了一个叫 ProgramBench 的新基准:让智能体在断网、只给一个编译好的可执行文件和文档的条件下,从零重建 ffmpeg、SQLite、PHP 解释器这类真实程序。发布当天,排行榜上每一个前沿模型都是 0 分;一周后 GPT-5.5 才成为第一个攻下单个任务的模型。一边是"顶级模型连一个 ffmpeg 都重建不出来",另一边是这位坐在镜头前、声称一天发 40 个 PR 还从不逐行看代码的人。这之间的张力,就是整期节目真正值得看的地方。
要点速览
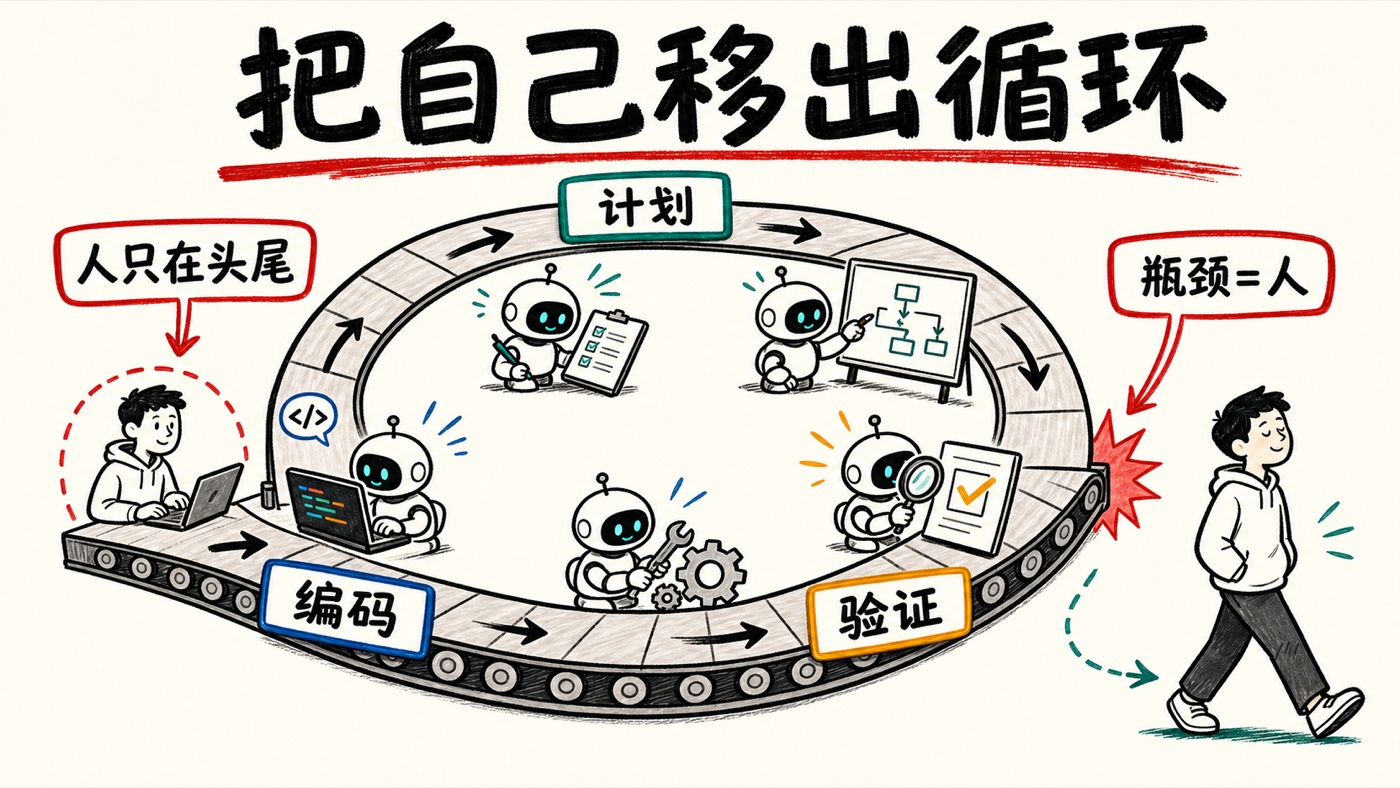
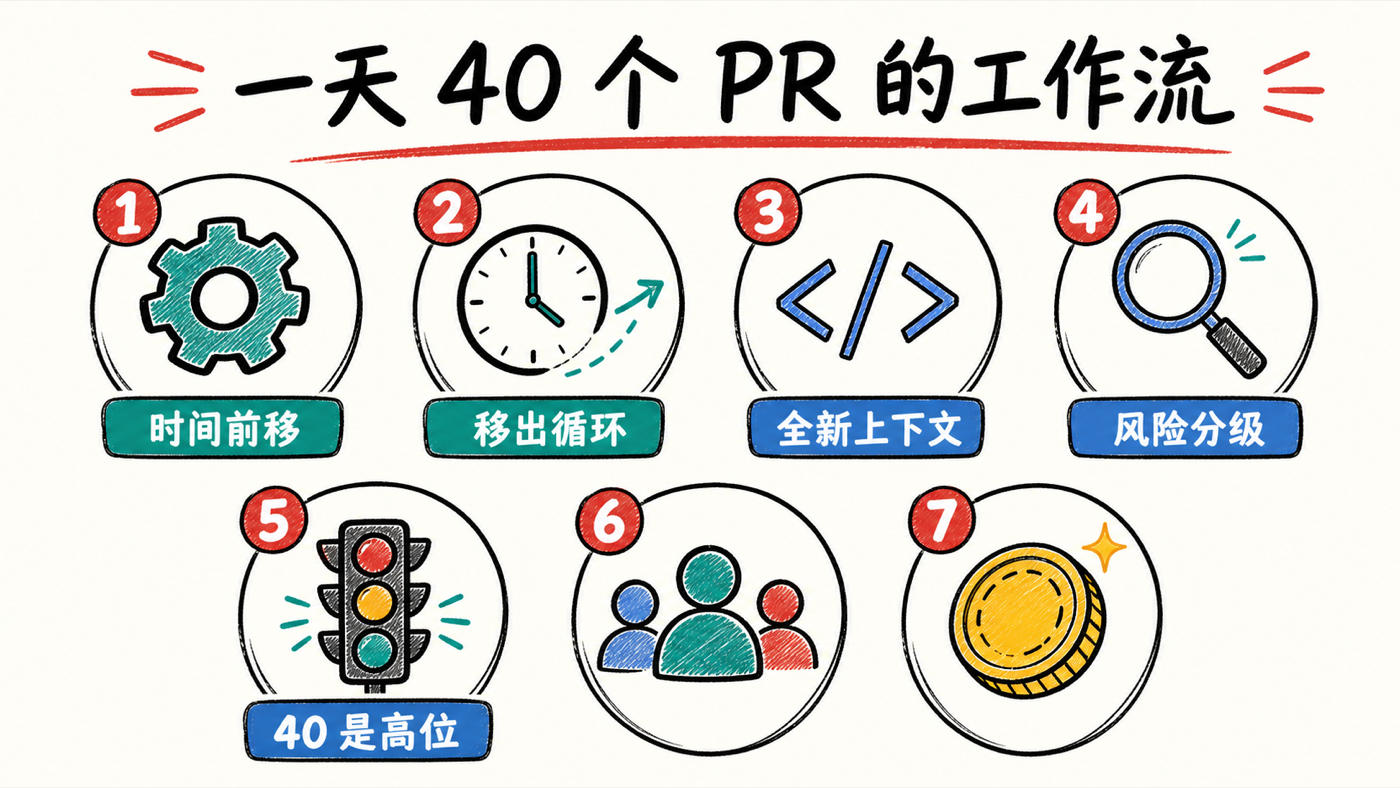
一,他的工作流一点都不新,新的是时间分配。还是 plan(计划)—code(编码)—validate(验证)老三段,但他把大部分人力压在计划阶段,编码几乎全交智能体,验证也主要靠智能体——人只在最前和最后出现。
二,整套方法只服务于一个目标:把人移出循环。冷开场那句"如果你逐行审每一行代码,你就成了瓶颈"就是全篇主旨。他自造的三个工具 Lavish、Treehouse、No Mistakes,本质都是在削减人停留在关键路径上的时间。
三,计划阶段投入多少,决定智能体能自主跑多久。一行提示词,智能体很快做完又回来找你;一份详细规格加一个可度量的目标,它能长时间自己试错。为此他宁可让模型多写十几倍 token,也要用 HTML 而不是 markdown 来做计划。
四,他确实不逐行审代码,但他仍然会看 PR。这个区别被视频标题抹掉了:他不读代码差异(diff),但会读智能体生成的风险评估、意图摘要和测试证据,再按风险高低决定看多细。
五,No Mistakes 的命门是"全新的上下文"。在原会话里让智能体自审,它会被自己之前的每一步带偏,倾向相信自己做对了;开一个干净的上下文窗口、只喂一份意图摘要、让它以挑刺的心态重审,能多抓出大量边界情况。
六,40 是高位,不是常态。他原话是一天 20 到 40 个 PR,图表上的均值是 26、14、27、30;而且他自己承认,他做的项目"大多没有真实用户,就我一个人用"。这套极限速度的工作流,尚未在有真实用户的场景里被检验过。
七,"把 token 用满"不是消费指标,是一种倒逼机制。他和彼得都承认烧 token 这件事已经成了一个梗;他真正的主张是用"必须跑更多并行智能体"当作强制函数,逼自己重构工作流,别再一次只盯着一个智能体。
【1】同样的 plan-code-validate,他把时间全搬到了最前面
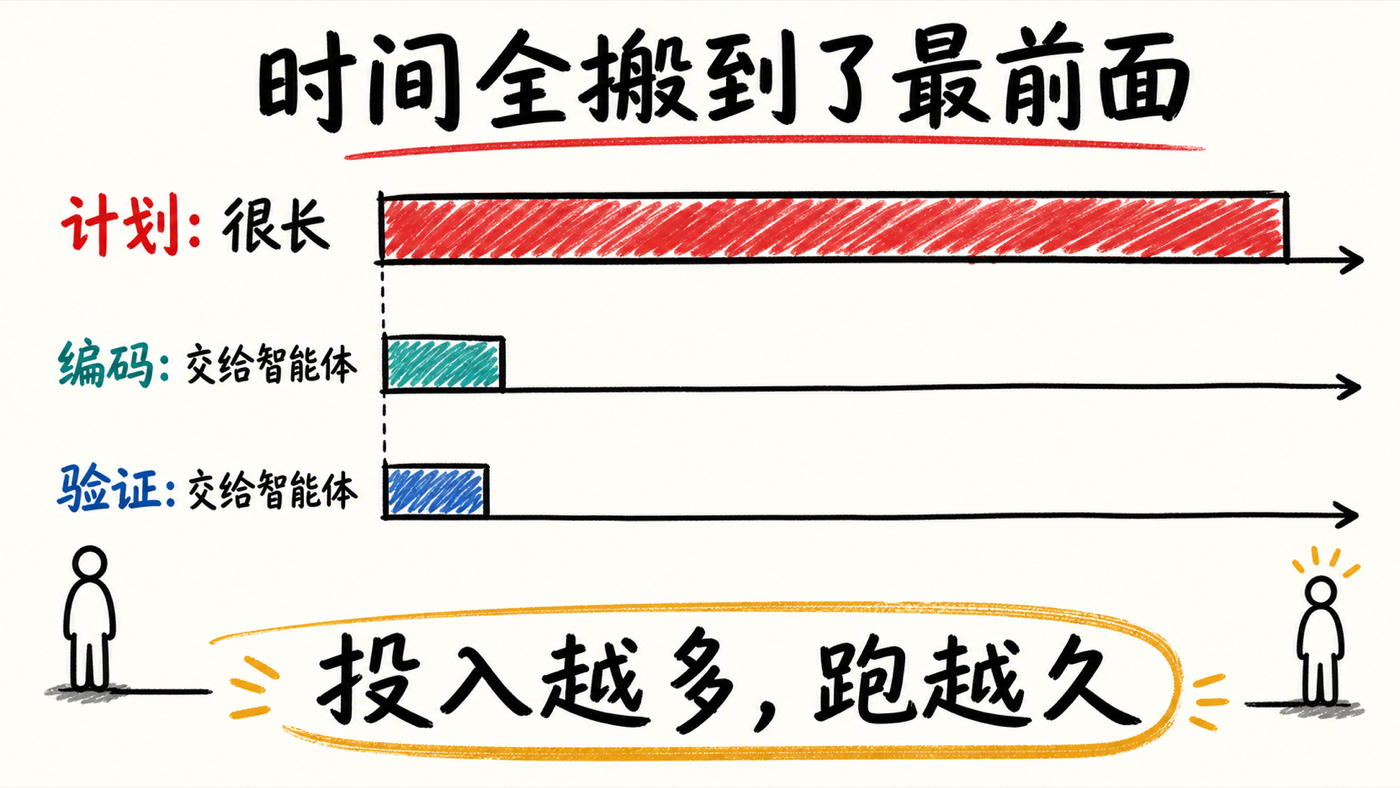
陈坤一上来就先泼了盆冷水:他的高层工作流"和大家没什么不一样",就是计划、编码、验证三段。真正不一样的,是他在每一段花的时间。
计划阶段,主要是他自己在做,智能体打下手;编码阶段,几乎完全交给智能体;验证阶段,也是智能体干大部分活,只在事情模糊时由他来拍板。一旦把编码这件事大幅交给智能体,他思考的问题就变成了:"怎么让智能体替我做得更多?"答案是:尽量拉长智能体能自主连续工作的那一段时间——因为那一段完全是智能体在跑,它跑得越久,他就收获越多。
这里藏着一个被很多人忽略的杠杆:计划阶段投入的时间,直接决定智能体能跑多久。彼得当场认领了自己的坏习惯——他对智能体越来越懒,"就丢一行提示词过去",结果当然跑不了几个小时。陈坤点破了原因:提示词只交代"下一步该干什么",智能体很快做完就回来找你,你立刻又变成瓶颈;而如果你把需求写成一份详尽的规格(spec),甚至进一步打磨成一个可度量的目标,智能体就能放开手脚去做大量试错,而不必频繁回头请示。
还有一个维度是并行。他指着自己脑海里那条时间轴说:需要"我"的地方,其实只有最开头和最末尾。中间那一大段,他会同时铺开很多个会话,让自己始终在做有产出的事,而不是干等某一个智能体。两人都感慨:他们都是从大厂出来的,过去的"上下文切换"是在一个个会议之间跳;现在变成在一个个线程之间跳,反而更快。陈坤把这种状态比作"一个负责很大业务范围的人"——总有不同的事在发生、不同的事在向你升级,你得判断此刻哪里最需要你,然后跳进去。
【2】他宁可让模型多写十几倍 token,也要用 HTML 而不是 markdown 做计划
演示从一个真实项目开始:Hibits(拼写以视频字幕为准,可能有出入),他给自己儿子做的 AI 家教应用,是一个面向孩子的智能体外壳。他刚改完一个新界面,"很乱,今早赶出来的,根本不是我想要的样子"。他的标准动作是:截一张图,丢给智能体。
他常用的智能体是 OpenCode——理由很实在:开源、能随时切换不同模型,新模型一出就能马上试。他把截图贴进去,指出两个明显问题:技术细节太多、对孩子不友好;还有一大块没用上的留白。然后他让智能体"提几个改进方案"。
智能体很快给了回应:最佳方向、方案一、方案二……但问题来了——这是一大段文字墙,读起来很费劲。"我会花特别多时间去读这堆字。"于是他换了个会话,加了一句关键的指令:"用 Lavish 来跟我讨论,把你的疑问也一起列出来。"
Lavish 是他自己造的可视化编辑器。他坦白,最初读到那篇"HTML 优于 markdown"的文章时,他是不信的——HTML 那么啰嗦,模型得多写一大堆,token 效率肯定差。可一旦真上手,他发现出奇地好用:HTML 作为一种产物,能承载远比文字墙丰富的人机协作。它不再是一堵需要逐字读的墙,而是一份可以直接用眼睛扫、用手去点的东西。他造 Lavish 的逻辑很简单——"每次工作流里遇到摩擦,又找不到现成的东西能解决,我就自己造一个"。
Lavish 解决的核心痛点是"来回迭代"。你当然可以让智能体直接生成一个 HTML 文件,在浏览器里打开,它能用;但一旦你看到里面有不满意的地方,想让智能体改某一处,就很难精确地把"改这里、迭代那个方面"说清楚。Lavish 让这件事变成:你在 HTML 产物上直接圈注、点击、给反馈,智能体立刻收到——你不用在终端和浏览器之间反复横跳,也不用大段复制粘贴。
现场效果很直观:智能体把改版方案写成了一份可视化文档,一眼就能看懂"现在的布局问题在哪、新方案长什么样"。它给了四个方向,A、B、C、D,每个方向下面还配了按钮——他看中了简洁的方案 C,直接点一下按钮,"我选 C"这条反馈就发回给了智能体,全程不用打一个字。用他的话说,这种交互"太容易了"。安装也简单:在它的 GitHub 仓库 lavish-axi 里,只要告诉你的智能体"用 npx lavish-axi 来写技术方案",它自己就会去调用,而且不需要你额外配 API key——Lavish 跑在你已经在用的那个智能体会话里,不会另起一个智能体。
从零做一个新项目时,他用的还是同一个 Lavish:先告诉智能体"我想跟你头脑风暴一个新点子",把自己对核心部分的初步想法讲一遍,然后让智能体去批评它、挑出他没想到的风险和弱点,再把意见以 HTML 产物的形式返回来。两人这么一来一回地打磨,把一个粗糙的想法逼成一份规格。如果他对技术栈已有偏好,就直接写进去,但永远会补一句"如果你觉得哪里不对,可以反驳我"——他要的是更多选项,而不是一个只会点头的智能体。这些最佳实践,他干脆都内建进了 Lavish,智能体一旦用 Lavish 跟他协作,就已经知道这些规矩。(视觉设计他另外重度依赖 Claude 的设计能力,配额面板上单列一条,本期一句带过。)

【3】工作树太累,所以他造了个"树屋"把这事变成无脑操作
并行多个智能体有个老问题:如果两个会话在同一个目录里干活,它们会互相踩脚。业界的常规解法是 git 工作树(worktree)——你可以把它理解成把当前仓库克隆到另一个目录,两边互不干扰。
但陈坤觉得工作树的认知负担太重。第一,每开一个工作树你都得起名字,"有人能花五分钟纠结叫什么";下次再回到这个工作树,你还得想"它当时在干嘛、还在用吗、能不能清掉",很难追踪。第二,新建的工作树里依赖没装——像 node_modules 这种是临时下载的,新工作树里根本不存在,你得全部重装一遍。
于是他造了 Treehouse,一个"无脑到极点"的工作树管理工具。每次要开新工作树,他不用想"我有没有现成的能复用、要不要新建",直接敲一个 treehouse,它就替他把工作树建好、并把他丢进去。关键在于,这个目录来自一个被托管的工作树池——因为他之前用过,依赖已经装好了,不用每次重装、重新构建项目,省时间也省脑子。"我什么都不用想,每次想开新会话,敲一下 treehouse 就行。"
【4】二三十个智能体同时跑,子智能体是用来"省上下文"的
到底同时有多少个智能体在替他干活?他说,录这期之前他已经尽量关掉了一批,但平时至少有 5 个会话在活跃运行,每个会话里又通常有一堆子智能体(sub agent)或不同智能体在干活,"我从没认真数过,估计平均下来有 20 到 30 个智能体在跑"。
彼得追问:子智能体是你专门让它跑的,还是它自己决定的?陈坤的判断很清醒:今天大多数模型和框架,并不擅长主动用子智能体。只有少数情况会主动用——比如 Claude Code 或 Codex 内置的探索(explore)能力,你问一个复杂问题,它会主动起一个探索子智能体去翻代码库、带回调查结果。除此之外,因为模型还没被训练到能在各种场景里灵活调用子智能体,你常常得明确提示它去用。
那他自己什么时候会主动上子智能体?核心理由只有一个:避免主会话的上下文窗口被撑爆。当他意识到接下来要做的事会消耗大量上下文、而且这些上下文大多是"调查、探索"性质、对主会话本身意义不大时,他就把这些活切出去交给子智能体,只让它们带回结论。另一类场景是批量实验:他有十个互相独立的实验想法,就直接说"起十个子智能体分别去做"——如果全塞进主智能体,上下文窗口会爆,既慢又费 token。
他现场翻出一个没舍得关的实验:在 ProgramBench 上做评测。前面提到,ProgramBench 让智能体从零重建 ffmpeg 这类程序、跑通全部测试用例。陈坤觉得这个基准不光能评模型,还能用来评不同的框架技巧和不同的编程语言——他强制 Codex 分别用 TypeScript、JavaScript、Python 等语言去做同一批任务,看换了语言后,智能体完成的需求数、通过的测试数、消耗的 token 会不会不一样。粗算一下是 200 个任务乘以 8 种语言,量很大,所以他靠子智能体来铺开;要是全在一个主智能体里跑,光是不停做上下文压缩就效率低下。

【5】把手动操作写进 agents.md:他不再亲手开 app 验证
智能体跑着一堆测试时,彼得问:是模型自己知道要测,还是你写了指令?陈坤的答案是后者,而且这是他认为"超级有用"的一招。
每个项目里他都在 agents.md 里写好"怎么测试"的指令。以前他不写、让智能体自己决定,结果智能体只做最低限度的事——它们被训练得会跑些基础测试,但不够全面。所以他把端到端测试的指令明确写进去。对前端和带界面的项目尤其重要:以 Hibits 这个带图形界面的应用为例,它是个 Electron 桌面应用,他就告诉智能体"这是个 Electron 应用,你可以用浏览器来驱动它、这样这样测"。有了这条指令,智能体干完活会自动替他做端到端验证——截图、用浏览器点一遍、看有没有报错、再对照之前商定的样子检查,省下他自己开应用、肉眼一项项核对的时间。
这里有个容易被忽略的坑:默认情况下,智能体偏爱写纯代码层面的单元测试,而这些单元测试往往验证不了端到端的行为。即便是 Codex,默认也倾向用它内置的应用内浏览器;但 Hibits 是个桌面应用,需要的是另一套验证设施。所以他写进 agents.md 的那套指令,本质上就是"我自己会怎么手动测这个东西"。
由此他给出一条对非技术背景的人也成立的高层原则:如果你发现自己在手动做某件事,就试着把它变成智能体替你做的事。用今天的模型,你很可能只要直接让智能体"把我刚才手动做的这事自动化掉",它就能琢磨出"哦,我该这么做、那么做"。他自己就是这么干的——越是发现某件能交出去的活,他就越把它沉淀成指令,而不是自己一遍遍手动操作应用。
【6】他不审代码,他让一个"没见过现场"的智能体来挑刺
智能体说"做完了"——然后呢?怎么知道这是个好改动、没埋 bug?陈坤说,验证阶段正是他看到很多人耗费大量时间的地方:默认做法是打开 IDE、开始逐行审代码差异。
但他的判断很硬:AI 能写的代码量太大了,你要是逐行审每一行,你自己就成了瓶颈。所以他干脆不审智能体的第一版代码,而是用另一个自造工具——No Mistakes。他做了个别名,每次智能体改完代码,敲一个 nm 就走完整条流水线。
第一步,它让智能体替他建分支——连分支名、提交信息他都不想操心,"这些事就是在浪费时间"。接着进入意图(intent)阶段:No Mistakes 去读他刚才那个工作会话,理解他原本想干什么。然后它把改动变基(rebase)到远端最新的主分支上,免得之后产生合并冲突;再来就是评审改动。
而这一步,是他做了大量提示词工程的地方——他把智能体调教得会非常非常狠地审查改动,任何边界情况、bug、逻辑错误都要揪出来,做成一个高召回(尽量不漏)的环节。当初造 No Mistakes 时,他做了大量并行对照实验:让智能体审、自己也审同一个改动,看自己能抓到多少智能体没抓到的东西,再拿这个差距去迭代提示词和流程。"最后我到了一个境界:我再也抓不到任何智能体抓不到的东西。"这一版演示里,智能体没发现什么实质问题,直接放行;但如果发现了问题,它会分两类处理——明显的 bug,它自己自动修,根本不烦你;而一旦修复会牵动产品层面的影响,它就停下来升级给你,让你来判断到底要不要这么改、还是要别的。
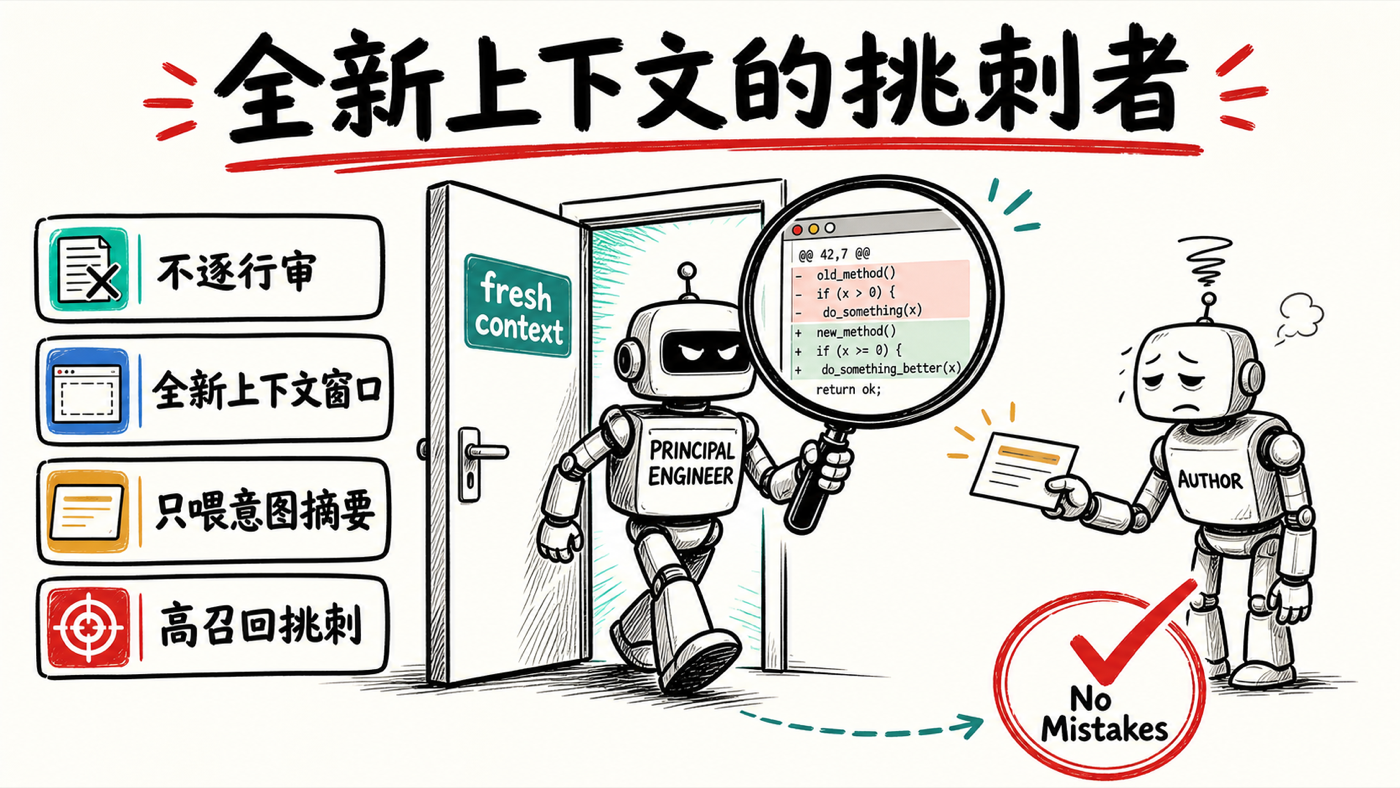
这里有个被彼得反复确认、也是整套方法里最关键的设计:No Mistakes 跑在一个全新的上下文窗口里,是一个没参与过现场的新智能体来看你刚才的对话。这是他刻意为之的。很多人的做法是在同一个会话里直接说"帮我审一下这个改动"——可这么做时,智能体被已经发生的一切严重带偏:它看过每一步,于是先入为主地相信"做出来的东西是对的",因此常常漏掉问题。他测过很多次,换成全新上下文窗口,能多抓出大量边界情况。
那新智能体怎么理解这个应用是干嘛的?这正是意图阶段的作用——它分析你的工作会话,提炼出你最初的意图和周边背景,但并不是把整个会话原样复制进新上下文。彼得打了个贴切的比方:就像一个资深工程师做完一个功能,你请一位首席工程师带着全新的眼睛来通审一遍;但通常你会让那个资深工程师先把背景简单讲两句给首席听。意图阶段,就是那"讲两句背景"。
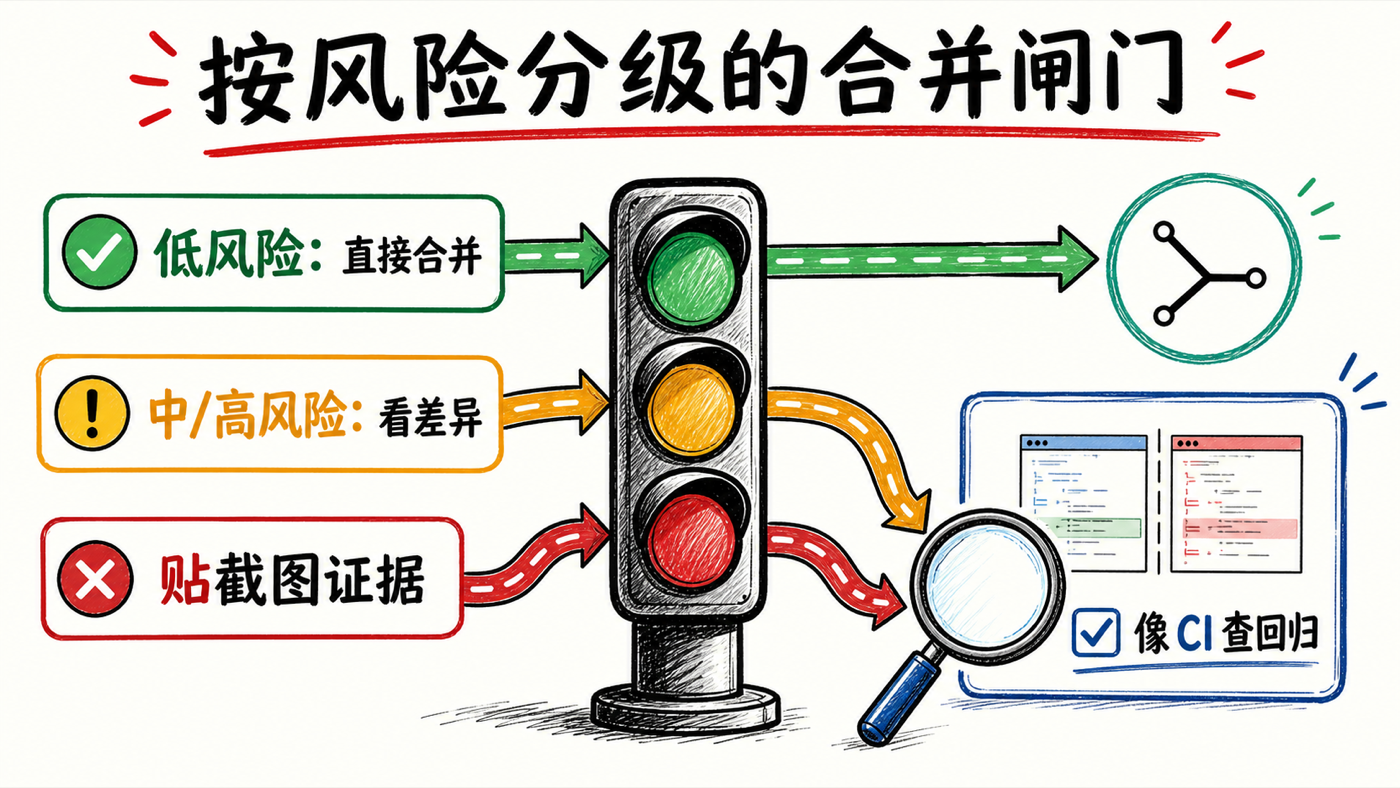
【7】像 CI 一样跑测试,再按风险高低决定自己看多细
No Mistakes 后面还有几段。评审之后是测试,但这里的测试阶段和智能体默认做的很不一样:默认的测试只是在本地跑一跑、验证"这次改动测过了、能用";而这一段更像持续集成(CI),它要验证的是"这次改动有没有把别的东西搞回归"。更妙的是,测试阶段会给出改动真实生效的证据——它会贴截图、有时是一段视频,把"这东西确实能用"捕捉下来,让他扫一眼产物就放心。彼得当场共鸣:他用 Codex 发的东西,本身是好的,但常常会把应用里另一条核心流程搞坏——而这个测试阶段会把这些一并查掉,再以容易消化的产物呈现给他。
对于"每次改动都要重测的几条核心流程",他的做法是让智能体把它们变成自动化的端到端测试,这样每次跑起来都很省事;底层往往就是用 Playwright 这类端到端浏览器测试工具,像真用户一样把流程点一遍,看有没有东西坏掉。你不必手动定义框架,直接让智能体"给这条用户流程写个端到端测试、确保它端到端能用",它通常能自己判断该用什么工具。
这条流水线最后会做文档检查、推送、建 PR。演示里它在文档阶段真抓到一处不一致——设计系统的示例文案没跟着更新。这正是他和智能体都常常忘记自动做的事:"你做了个改动,能不能把文档里所有会被这个改动影响的地方都找出来?"
PR 建好后,长什么样?它总结了从原始会话里理解到的意图、罗列了改了什么、还做了风险评估。风险评估对他很有用——看到低风险改动他就少花时间,看到智能体标的中风险或高风险,他就在这个 PR 上多花时间,从而更聪明地分配自己的注意力。所以遇到刚才那种低风险改动,他根本不进去看差异,直接合并;只有中风险、高风险,他才进去看差异、自己动手查。
但请注意他和彼得在这里的对比。彼得自爆了自己的毛病:"我有时候根本不看 PR,直接让它合并。"陈坤则说自己始终会看一眼这个 PR——因为通读风险评估、看智能体到底做了什么、改的是什么,这些仍然有用。所以"我不审代码"准确的含义是"我不逐行审代码差异",而不是"我什么都不看"。这个区别,恰恰是视频标题没说清楚的地方。
至于产量,他翻出图表笑着念了串数字:"26、14、27、30……差不多就是均值,大多数时候一天 20 到 40 个 PR,有时更多。"彼得调侃:"我一眼就能看出你哪天失业的——三月份左右,图上特别明显。"
【8】"我们的流程,是为'人写代码'的时代设计的"——它正在崩
彼得抛出一个更大的问题:在大厂里你推个改动,有同事来审你的 PR、跑些测试;现在就你一个人,你是觉得解放了,还是有点想念队友?
陈坤说两者都有,但总体上他感到的是解放。他想念的是头脑风暴阶段的队友——就他一个人时,视角不够多元,可能想不周全、看不到别人能看到的问题;AI 能帮一些,但还没到能替代一个真正聪明、能一起构思的团队的程度。他不想念的那部分是:每个人都很忙,如果他一天写 20 个 PR,没人会去审。事实上,早在他离开上一家公司之前,这事就已经发生了——他被迫少写 PR、把时间花在别处,因为瓶颈其实落在团队其余人身上。
由此他给出本期最有分量的一段判断:我们的工作流和团队协作方式,是在"大部分时间都在写代码"的年代建立起来的。一个普通软件团队,一名工程师平均一个月写 10 到 15 个 PR(节目中给出的数字)——在这个速度下,让别人来做代码评审、走那一整套流程,是没问题的。但当你开始写十倍于此的 PR,我们的流程、人力团队的构成、所有这些都不是按这个假设搭建的,于是东西开始崩。很多团队已经在改打法:一些小团队、初创团队基本上停掉了 PR 评审——还是会建 PR,但更多是走个形式、留个记录,不再真的等同行来审,有时直接合并,出了问题再回头修。
彼得补了一刀:他们其实是让智能体来审,"我确实觉得这会让产品更不稳定一些"。陈坤笑着把球挡了回去:"那是因为他们没用 No Mistakes。"——这句玩笑,恰恰把整套方法论里最大的那个未决问题,轻轻盖了过去。

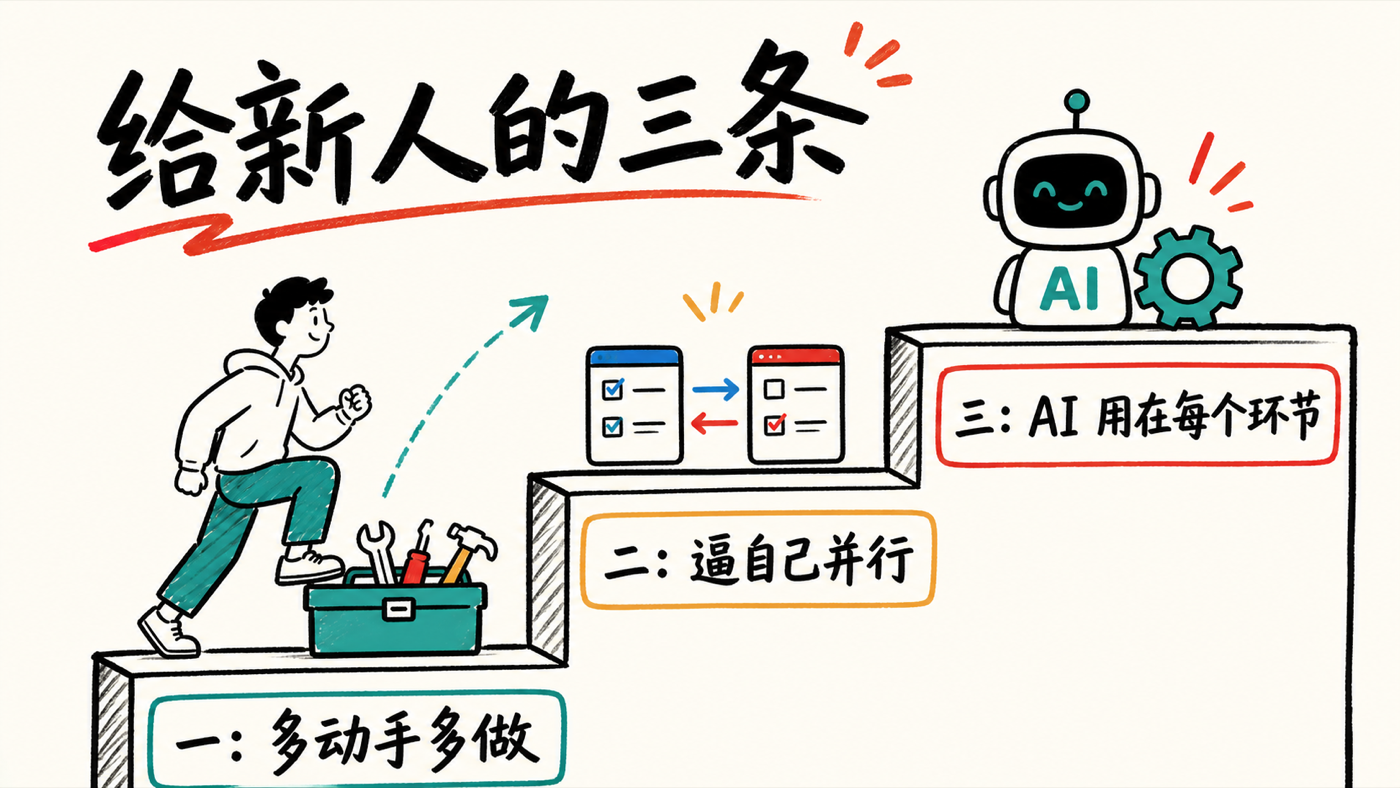
【9】给新人的三条:多动手、逼自己并行、别只让 AI 写代码
作为一个"干这行很久的 L8",他给想入场的人三条建议。
第一,多玩、多做。哪怕是个一次性的玩具,也把它做出来——在这个过程里你常会发现"哪里能做得更好"、"智能体哪里没做好",然后开始反思。他见过一些人卡在另一种状态:花大量时间纠结到底该做什么,然后只做了一件事,那件事没成,就停了。他鼓励的心态是:你有的每一个想法都把它做出来——一有灵感就把提示词丢给智能体,看它能跑出什么,学习就是从这个过程里长出来的。
第二,逼自己用更多 token、跑更多并行智能体。他把这当成一个升级工作流的强制函数:默认一次只跟一个智能体打交道时,我们仍然是瓶颈,把自己太深地塞进了循环里;要真正放大能从智能体身上拿到的产出,就得尽可能把自己移出循环——而"必须跑更多并行智能体"这件事,会倒逼你去想办法做到这一点。
第三,把 AI 用在工作流的每一个环节,而不只是写代码。这一期里你能看到,AI 替他做了验证、文档、建 PR——这些他都不用碰。每当在一个项目里发现自己还在手动做某件事,就想想能不能也交给智能体;顺着这条路,人能找到更多能自动化、能减负的工作流。
他还现场提了一个工具:Claude Code 有个叫 /insights 的斜杠命令(节目中演示,我未能独立证实该命令),能分析你的会话历史、生成一份报告,告诉你哪里能做得更好、该加什么技能、该调哪些记忆文件,让 Claude Code 替你跑得更顺。"很酷,但很费 token,我额度已经用光了,今天不演示了。"
关于"把 token 用满",两人都点破这是个梗。彼得自嘲:"我从小作为一个亚洲人有匮乏心态,老想着省钱,烧 token 这事感觉就是不对劲。"陈坤的真实主张其实更克制:我们不该为了烧 token 而烧 token,要的是真把活干成;第二条建议的重点,是逼自己想办法规模化、真正用智能体多做事,而不是把自己卡在循环里一次只做一件。"大多数人作为个人都有订阅,至少把订阅的额度吃满。"
代表性短摘与中文转述
一,"If you review every single line of code, you become the bottleneck.":这是整期的题眼。他的全部工具和方法,都是从这句判断推出来的——人审查的速度跟不上 AI 写代码的速度,所以与其当那个瓶颈,不如把审查本身也设计成智能体来做。
二,"Eventually I got to a point where I find myself never catching anything the agents don't catch.":他在描述 No Mistakes 的评审环节被调校到什么程度。注意这句的前提是他做过大量人机并行对照、反复迭代提示词——这是一个 L8 用资深判断力标定出来的结果,不是装上工具就自动到手的境界。
三,"Our workflows and how our teams work were built at a time when we spend most of our time coding.":他对行业的判断。一名普通工程师一个月 10 到 15 个 PR 的旧节奏,撑起了"同行评审"这套流程;当产量翻十倍,流程、团队结构、协作假设全都跟不上,于是开始断裂。
四,"That's because they are not using No Mistakes.":当彼得指出"跳过 PR 评审会让产品更不稳定"时,他用这句玩笑作答。它好笑,但也正好是这套方法论里最该被追问的地方——把人移出循环之后,质量到底靠什么兜底。
五,"Largely speaking I feel liberated.":被问到离开大厂、没有队友的感受时他的回答。他想念的是头脑风暴时多元的视角,不想念的是"我写 20 个 PR、没人来审"的那种被团队速度拖住的状态。
注
- 陈坤(Kun Chen):前 Meta、微软、Atlassian 的 L8 工程师(Meta 体系里 L8 对应首席/Principal Engineer),做过 Bing、MSN,当过 Facebook Games 的主程,参与过 Atlassian 的软件工程智能体 Rovo Dev;现为独立开发者。X、YouTube、GitHub、LinkedIn 全平台统一用户名是 kunchenguid。其中文名"陈坤"为依罗马字推断,姓"陈"基本确定,名"坤"为常见对应字,未必与本人用字一致。
- 彼得·杨(Peter Yang):本期主持人,《Behind the Craft》播客与 creatoreconomy.so 时事通讯的作者,长期做产品与创作者经济内容。
- Lavish(仓库 lavish-axi)、Treehouse、No Mistakes:均为陈坤自造并开源的工具,分别解决可视化计划、并行工作树管理、AI 代码审查兜底。Lavish 通过
npx lavish-axi在你已有的智能体会话里调用,不另起智能体、不需单独配 API key。No Mistakes 是一道本地闸门,把改动依次过一遍意图、变基、评审、测试、文档、检查、推送、建 PR、持续集成等阶段后才放行上游。 - "HTML 优于 markdown"的文章:陈坤说 Lavish 是他读了这篇文章后才造的——主张用 HTML 产物而非 markdown 承载人机协作。本期未点出文章作者与出处,故不在此妄断。
- OpenCode:开源的智能体命令行工具,支持自由切换多种模型,这也是陈坤选它的原因。
- ProgramBench:SWE-bench 同一团队(John Yang 等)于 2026 年 5 月发布的基准(arXiv 2605.03546)。给智能体一个编译好的可执行文件加文档,要求在断网条件下从零重建出行为一致的程序,覆盖 200 个任务、24.8 万余条行为测试,难度从小型命令行工具到 ffmpeg、SQLite、PHP 解释器不等。发布时榜上前沿模型全部 0 分,约一周后 GPT-5.5 成为首个攻下单个任务的模型;最强模型也仅在 3% 的任务上通过了 95% 的测试。陈坤的实验是在它之上再叠加"8 种编程语言"做对照,故有约 200×8 的实验量。
- 产量数字:视频标题里的"40"是高位说法;他原话是一天 20 到 40 个 PR,现场图表念出的均值是 26、14、27、30。"普通工程师一个月 10 到 15 个 PR""十倍 PR"等数字均为节目中给出,未独立核验。
- Claude 的设计能力 /
/insights命令:前者陈坤称作"Claude design"、在其配额面板上单列一条,本文按其口径转述;后者为他现场所提的 Claude Code 斜杠命令,我未能独立证实该命令的存在与具体行为,均以"节目所述"为准。 - Hibits:陈坤给儿子做的 AI 家教 Electron 应用,拼写以视频字幕为准,可能有出入。
最后
这期节目最该被记住的,不是"40 个 PR"这个数字,而是它和那个数字之间所有没说透的缝隙。
第一道缝:他到底审不审代码。 标题说"从不审代码",正文里他却始终会看 PR——看风险评估、看意图摘要、看测试证据,只是不读逐行差异。真正的对照组是彼得:彼得直接让智能体合并、连 PR 都不看,结果"一天后总会发现别的东西坏了"。所以同一句"不审代码",在陈坤那里是"把审查升级成了一道精心设计的智能体闸门",在彼得那里是"省掉了审查"。这两件事被一个标题缝在了一起,而它们的工程后果完全相反。
第二道缝:把人移出循环的前提,是先有一个能把循环设计对的人。 No Mistakes 之所以能让他"再也抓不到智能体抓不到的东西",靠的是他做过大量人机并行对照、反复迭代提示词——这是一个 L8 首席工程师用十几年判断力标定出来的结果。一个普通人 npx 装上同一个工具,未必能复现那个召回率,因为最难的部分(知道哪些边界情况重要、知道修复会不会牵动产品、知道测试该测什么)恰恰不在工具里,而在他脑子里。"把自己移出循环"是结论,但它的隐含前提是"你得先有能力把这个循环设计对"——这一层,对正在入场的新人最危险,也最容易被这期节目的轻松语气盖过去。
第三道缝:这套极限速度,还没在有真实用户的地方被检验过。 他自己承认,他做的东西"大多没有真实用户,就我一个人用"。一个只服务自己的项目,"快速改动"和"确保不出错"之间的权衡,可以大幅偏向前者——坏了,代价只是他自己的几分钟。可一旦有了真实用户、有了 SLA,这个权衡就完全不同。他也看到了行业里小团队"停掉评审、直接合并、出问题再回滚"的趋势,并且默认这会让产品"更不稳定",但他用"那是因为他们没用 No Mistakes"一句玩笑挡了过去——而这恰恰是整套方法论最该被压力测试的命题:当所有人都把人移出循环,质量的最终责任落在哪里?他没有给出一个带真实用户、真实事故率的验证案例。
值得继续追的信号有两个。一个是他在 ProgramBench 上跑的"编程语言 × 框架技巧"实验(200×8):如果真有某种语言能让智能体多过测试、少烧 token,那是一条可迁移的硬结论,比"一天 40 个 PR"有用得多——他说会在 X 和 YouTube 上分享。另一个是"token maxing"这个梗的真实内核:他和彼得都不信"为烧而烧",但他把"必须跑更多并行智能体"当成倒逼自己重构工作流的强制函数——这个区别(消费指标 vs 倒逼机制)很可能是普通人学这套打法时,最先学歪的地方。
